
Text-to-Video来临!——Meta AI发布最新的视频生成预训练模型
DALLE·2的出现,让大家认识到原来文本生成图片可以做到如此逼真效果,此后Stable Diffusion的开源也让大家把Text-to-Image玩出花了。而现在,Meta AI的研究人员让这个工作继续往前一步,发布了Text-to-Video的预训练模型:Make-A-Video。
探索人工智能与大模型最新资讯与技术博客,涵盖机器学习、深度学习、自然语言处理等领域的原创技术文章与实践案例。
DALLE·2的出现,让大家认识到原来文本生成图片可以做到如此逼真效果,此后Stable Diffusion的开源也让大家把Text-to-Image玩出花了。而现在,Meta AI的研究人员让这个工作继续往前一步,发布了Text-to-Video的预训练模型:Make-A-Video。
Vicuna是开源领域最强最著名的大语言模型,是UC伯克利大学的研究人员联合其它几家研究机构共同推出的一系列基于LLaMA微调的大语言模型。这个系列的模型因为极其良好的表现以及官方提供的匿名评测而广受欢迎。今天,LM-SYS发布Vicuna 1.5版本,包含4个模型,全部基于LLaMA2微调,最高支持16K上下文输入,最重要的是基于LLaMA2的可商用授权协议!免费商用授权!
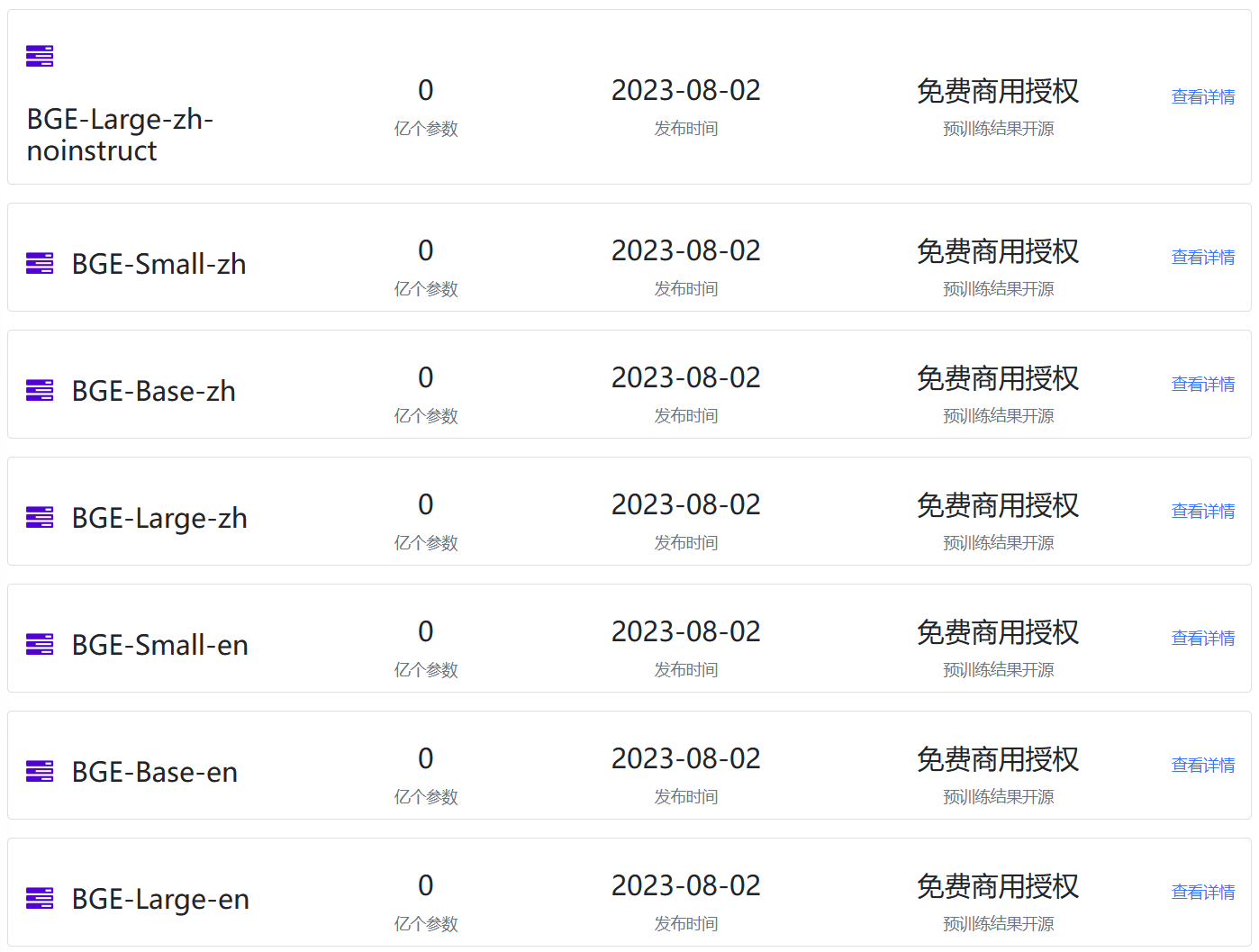
Embedding模型作为大语言模型(Large Language Model,LLM)的一个重要辅助,是很多LLM应用必不可少的部分。但是,现实中开源的Emebdding模型却很少。最近,北京智源人工智能研究院(BAAI)开源了BGE系列Embedding模型,不仅在MTEB排行榜中登顶冠军,还是免费商用授权的大模型,支持中文,应该可以满足相当多人的需要。
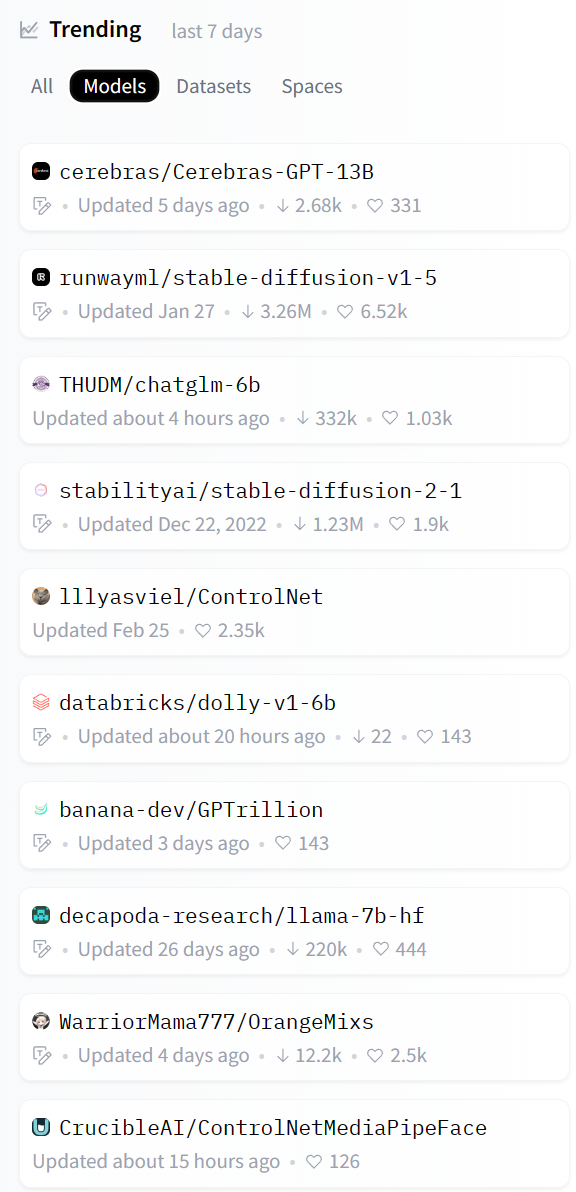
HuggingFace是目前最火热的AI社区(HuggingFace简介:https://www.datalearner.com/blog/1051636550099750 ),很多人称之为AI模型的GitHub。包括Google、微软等很多知名企业都在上面发布模型。而HuggingFace上提供的流行的模型也是大家应当关注的内容。本文简单介绍一下2023年4月初的七天(当然包括3月底几天)的最流行的9个模型(为什么9个,因为我发现第10个是一个数据集!服了!)。让大家看看地球人都在关注和使用什么模型。

目前开源领域已经有一些模型宣称支持了8K甚至是更长的上下文。那么这些模型在长上下文的支持上表现到底如何?最近LM-SYS发布了LongChat-7B和LangChat-13B模型,最高支持16K的上下文输入。为了评估这两个模型在长上下文的表现,他们对很多模型在长上下文的表现做了评测,让我们看看这些模型的表现到底怎么样。
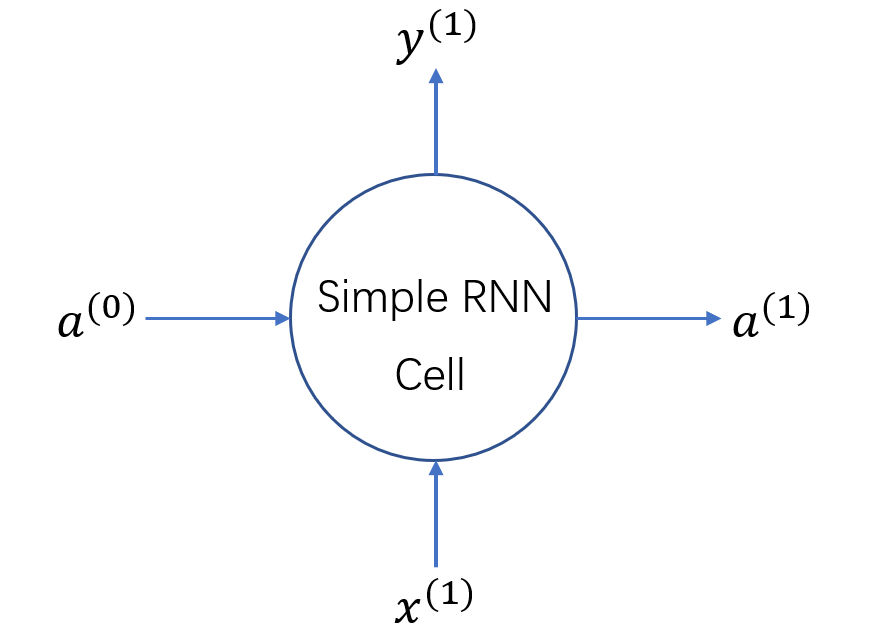
RNN的应用有很多,尤其是两个RNN组成的Seq2Seq结构,在时序预测、自然语言处理等方面有很大的用处,而每个RNN中一个节点是一个Cell,它是RNN中的基本结构。本文从如何使用RNN建模数据开始,重点解释RNN中Cell的结构,以及Keras中Cell相关的输入输出及其维度。我已经尽量解释了每个变量,但可能也有忽略,因此可能对RNN之前有一定了解的人会更友好,本文最主要的目的是描述Keras中RNNcell的参数以及输入输出的两个注意点。如有问题也欢迎指出,我会进行修改。
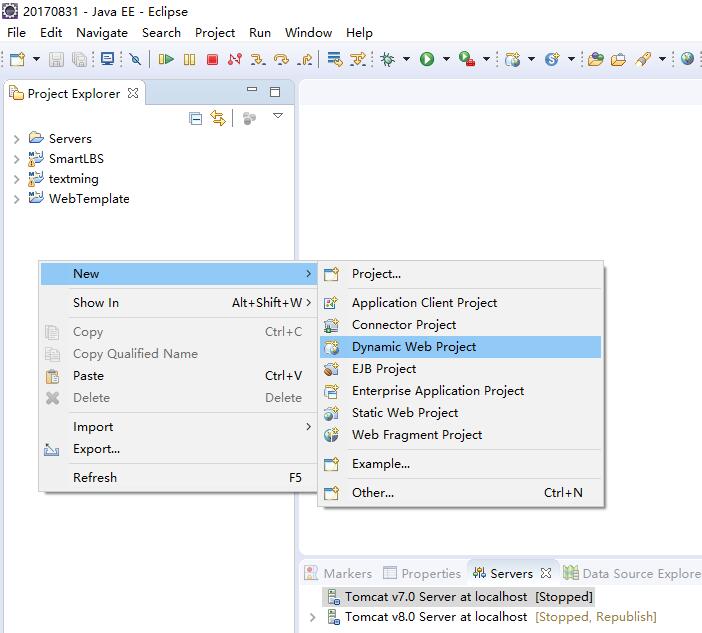
使用SpringMVC框架搭建Web项目工程是目前非常流行的web项目创建方式。同时Spring Security也为我们提供了登录验证和权限控制等内容。


NumPy是Python中非常优秀的一个数据科学工具包,使用Python做数据分析的童鞋几乎是必备的工具。NumPy的提供了非常丰富的计算能力,但是底层是C语言实现的,因此既有Python语法的低门槛,速度上却依然非常好。NumPy本身也和Pandas、SciPy一起成为一种生态了。今天,NumPy发布了1.20.0最新版本,这个版本的改动很大。值得童鞋们关注~

有的时候使用Python遇到内存溢出的问题,但其实机器剩余内存很多。需要注意Python版本是否正确

大模型虽然效果很好,但是对资源的消耗却非常高。更麻烦的其实不是训练过程慢,而是峰值内存(显存)的消耗直接决定了我们的硬件是否可以来针对大模型进行训练。最近LightningAI官方总结了使用Fabric降低大模型训练内存的方法。但是,它也适用于其它场景。因此,本文总结一下相关的方法。

AI Agent被很多人认为是未来大模型的发展方向。此前,OpenAI安全团队负责人人Lilian Weng也发布了一篇详细介绍AI自动代理机器人的博客,引起了很多人的关注。7月份发布的MetaGPT是一个全新的AI Agent项目,它基于GPT-4提供了专注于软件开发的自动代理框架,几乎可以理解为配备了产品经历、系统设计师、程序员的一个小团队,可以基于原始的需求直接生成最后的代码项目。本文主要介绍一下这个项目,并分析一下背后的实现方式。

今天,OpenAI官方宣布GPT接口新增一个能力:即支持以更加精确的JSON视图格式返回大模型的结果。比去年的单纯的让GPT输出JSON更加强大,它可以确保模型生成的输出能够完全匹配开发者提供的JSON模式。这种能力是在官方的API接口中增加了`return_format={"type":"json_schema","json_schema": {...}}`参数实现的。但是仅支持最新的模型版本,但这可能是未来的趋势!
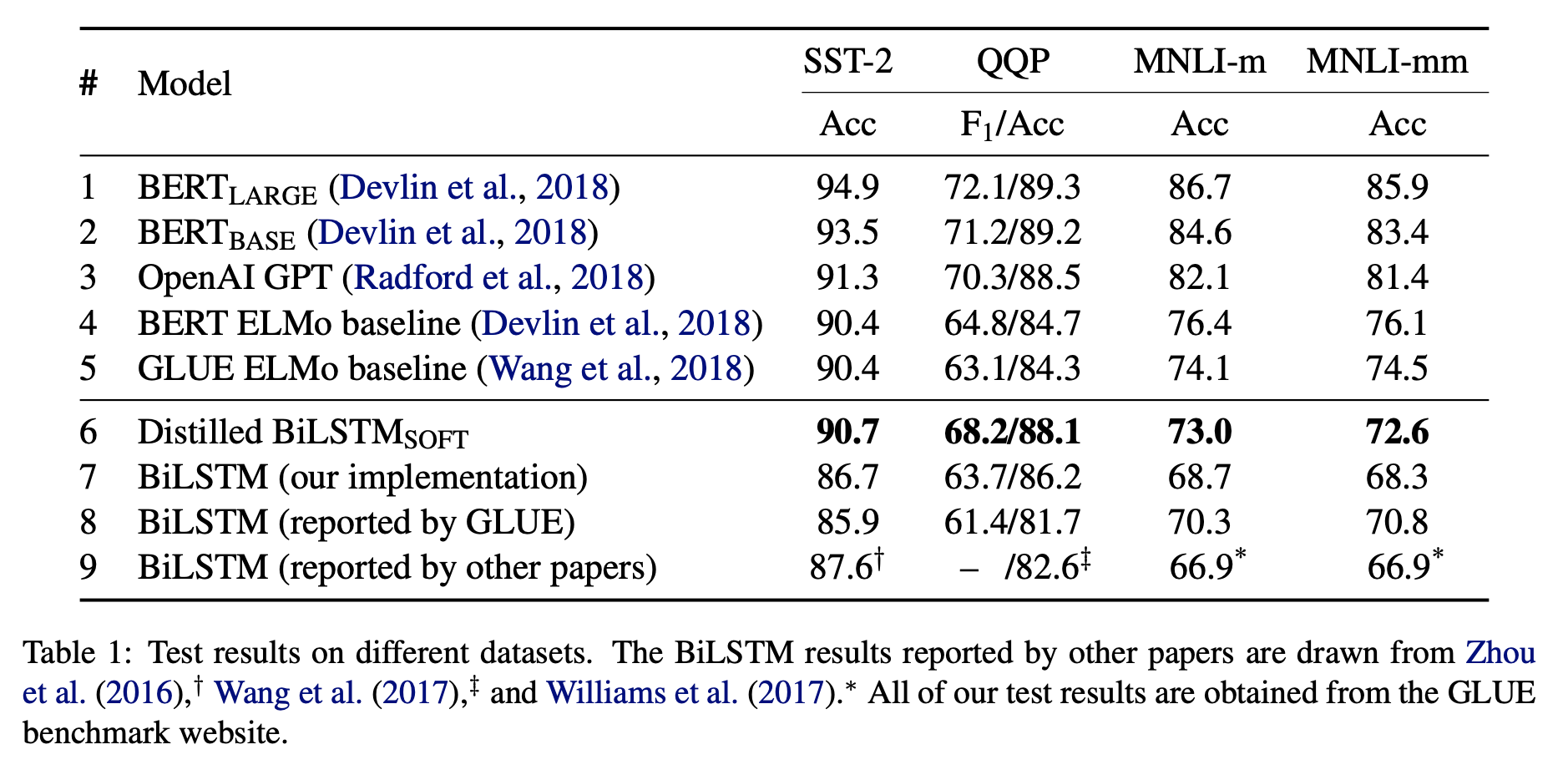
BERT是很好的模型,但是它的参数太大,网络结构太复杂。在很多没有GPU的环境下都无法部署。本文讲的是如何利用BERT构造更好的小的逻辑回归模型来代替原始BERT模型,可以放入生产环境中,以节约资源。
随着ChatGPT的火爆,Prompts概念开始被大家所熟知。早期类似如BERT模型的微调都是通过有监督学习的方式进行。但是随着模型越来越大,冻结大部分参数,根据下游任务做微调对模型的影响越来越小。大家开始发现,让下游任务适应预训练模型的训练结果有更好的性能。而ChatGPT的火爆让大家知道,虽然ChatGPT的能力很强,但是需要很好的提问方式才能让它为你所服务。

LiveCodeBench 由加州大学伯克利分校、麻省理工学院和康奈尔大学的研究人员开发,是一个先进的评测基准套件,专门用于严格评估大语言模型 (LLMs) 在代码处理方面的能力,并解决现有基准测试的局限性。通过引入实时更新的问题集和多维度评估方法,LiveCodeBench 确保对 LLM 进行公平、全面和稳健的评估。
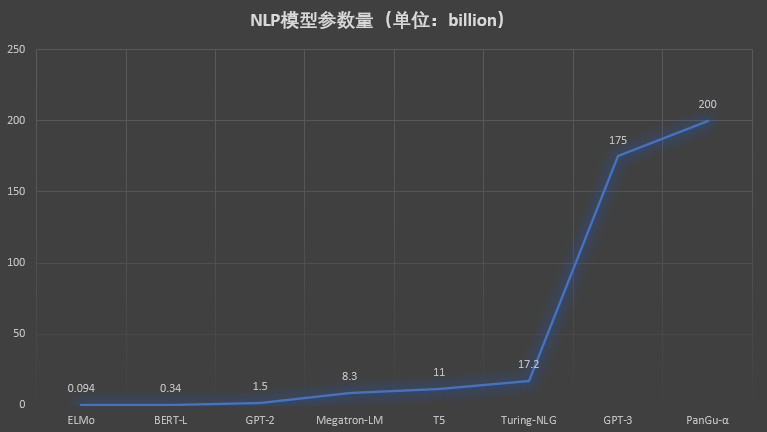
这几年深度学习的发展给人工智能相关应用的落地带来了很大的促进。随着NLP、CV相关领域的算法的发展,算法层面的创新已经逐渐慢了下来,但是工程方面的研究依然非常火热。从底层的硬件的创新,到平台框架的发展,为支撑超大规模模型训练与移动端小规模算法推断而创造的软硬件体系也在飞速革新。本文将总结深度学习平台框架软件及下层的硬件支撑系统。

随着预训练大模型技术的发展,基于prompt方式对模型进行微调获得模型输出已经是一种非常普遍的大模型使用方法。但是,对于同一个问题,使用不同的prompt也会获得不同的结果。为了获得更好的模型输出,对prompt进行调整,学习prompt工程技巧是一种必备的技能。
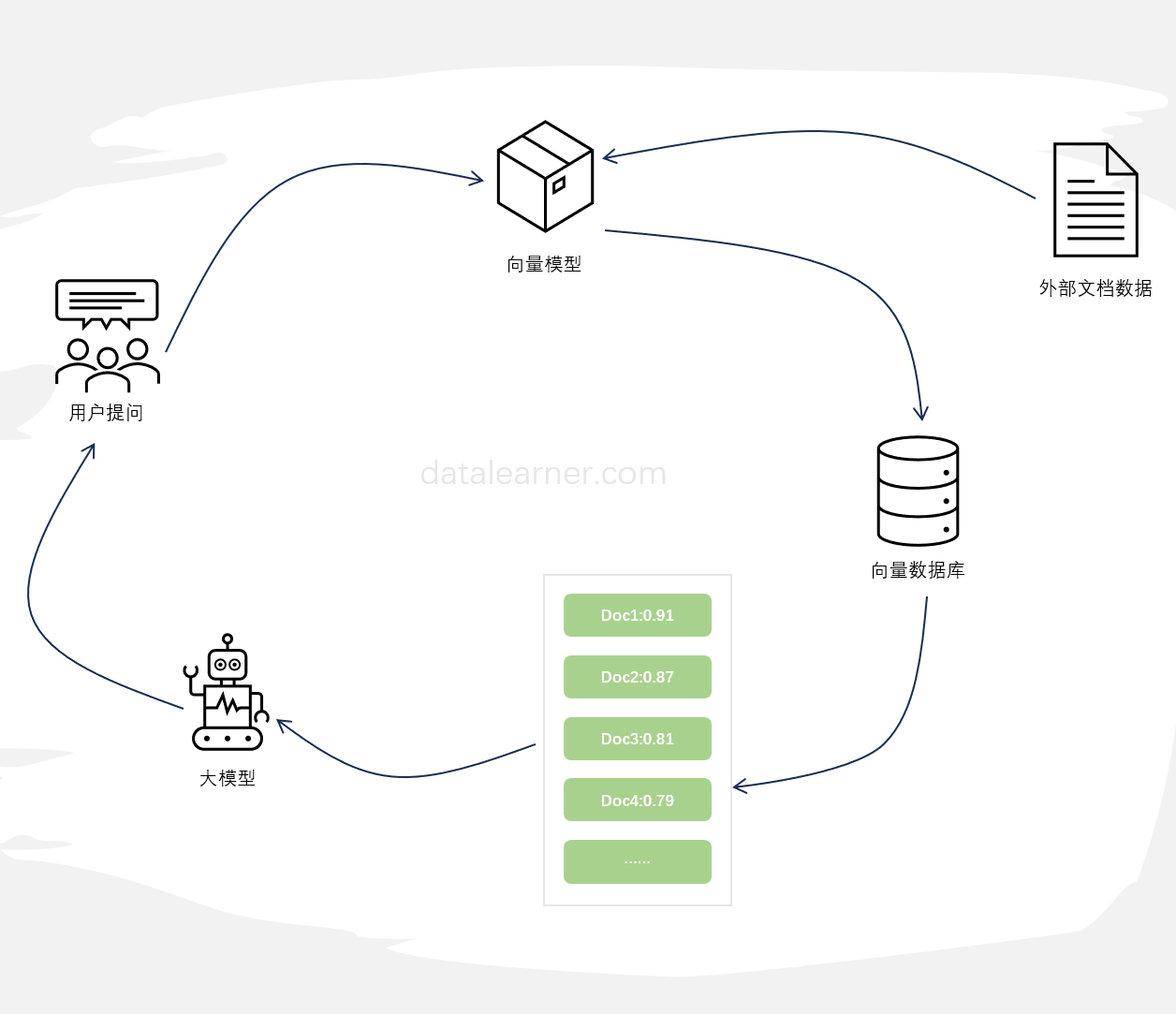
检索增强生成(Retrieval-augmented generation,RAG)是一种将外部知识检索与大型语言模型生成相结合的方法,通常用于问答系统。当前使用大模型基于外部知识检索结果进行问答是当前大模型与外部知识结合最典型的方式,也是检索增强生成最新的应用。然而,近期的研究表明,这种方式并不总是最佳选择,特别是当检索到的文档数量较多时,这种方式很容易出现回答不准确的情况。为此,LangChain最新推出了LongContextReorder,推出了一种新思路解决这个问题。