
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



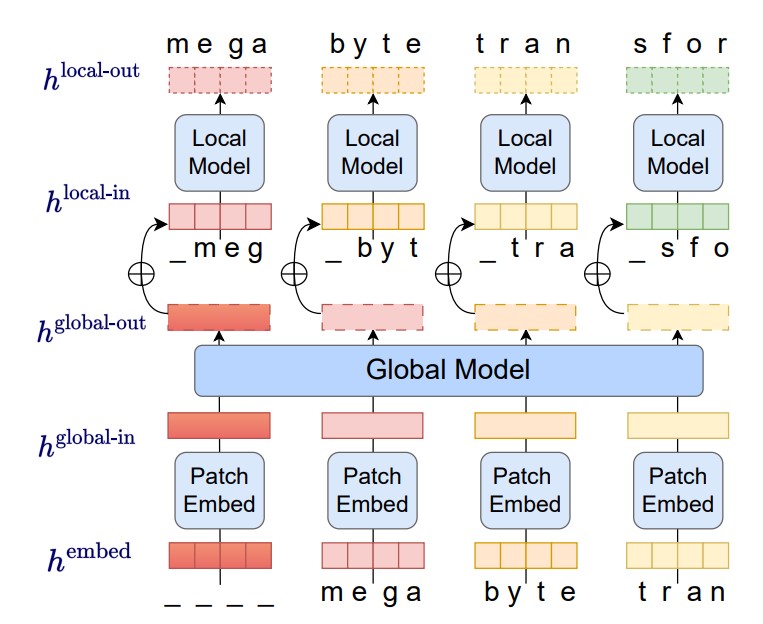
尽管OpenAI的ChatGPT很火爆,但是这类大语言模型有一个非常严重的问题就是对输入的内容长度有着很大的限制。例如,ChatGPT-3.5的输入限制是4096个tokens。MetaAI在前几天提交了一个论文,提出了MegaByte方法,几乎可以让模型接受任意长度的限制!

大模型的发展一个重要的基础条件是底层硬件计算能力的大幅提高,特别是GPU的发展,与transformer架构的大模型训练非常契合。当前全球最大的GPU供应商英伟达系列的显卡几乎垄断了大模型训练与推理的所有GPU芯片市场。除了英伟达显卡本身算力强悍外,基于英伟达GPU之上构建的CUDA、PyTorch等平台软件生态也是非常重要的一环。而最新的PyTorch2.1版本发布的一个beta特性中包含了对华为昇腾芯片的原生支持,这也是大模型生态多样性发展的一个很重要的信号。

几分钟之前,OpenAI宣布ChatGPT支持多模态,目前已经支持语音的输入、语音的输出、理解图片的输入!不过目前似乎仅限于客户端~官方说的是未来2周内企业和Plus用户可以使用,后面会普及到其它用户!
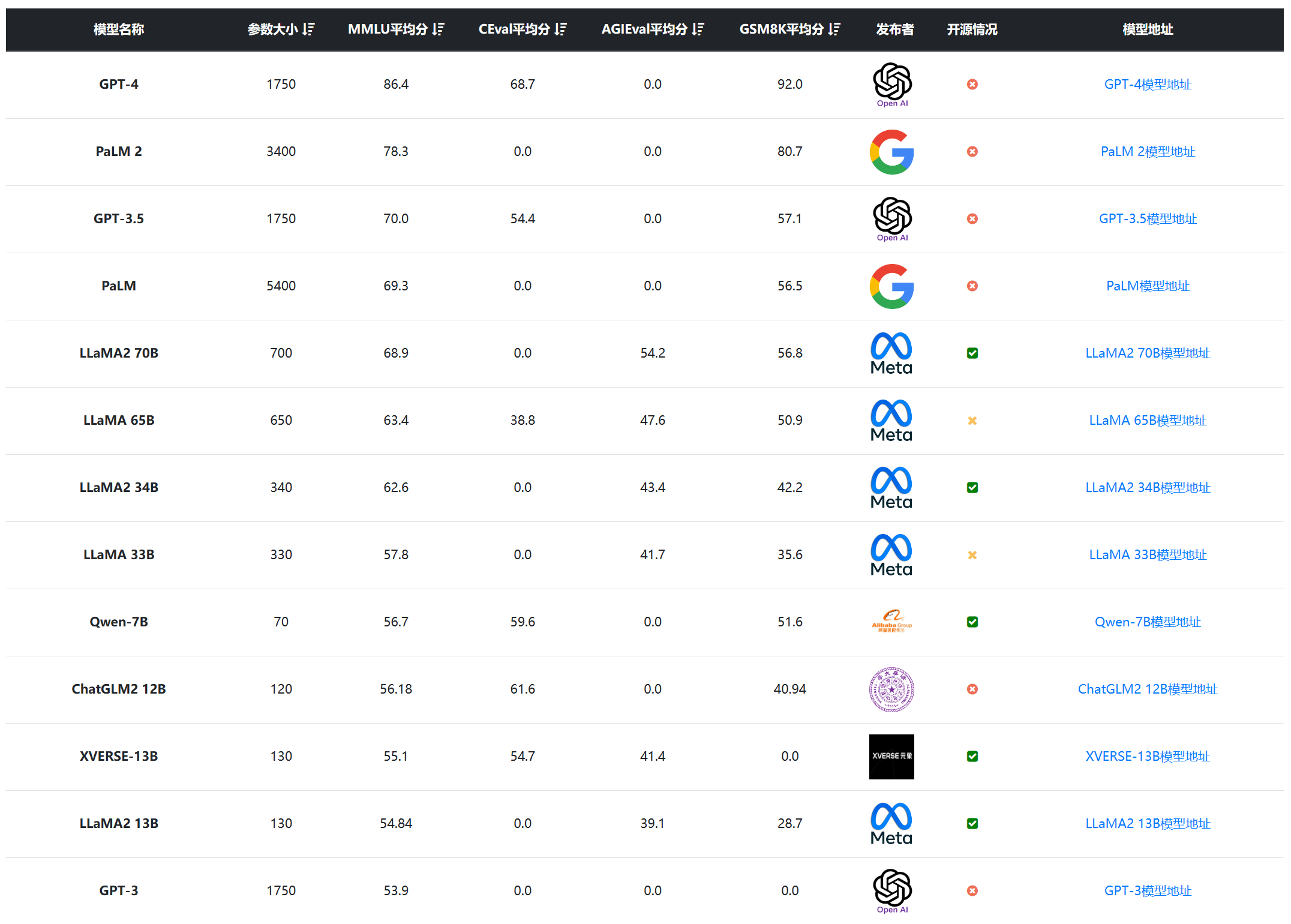
随着各种AI模型的快速发展,选择合适的模型成为了研究和开发的一大挑战。最近一段时间,国产模型不断涌现,让人应接不暇。尽管开源的繁荣提供了更多的选择,实际上也造成了选型的困难,尽管业界提供了很多评测基准,但是,**很多模型在公布的评测结果中对比的模型基准和选择的测试基准都很少,甚至只选择对自己有利的结果**。为了更加方便大家对比相关的结果,DataLearner上线了大模型评测综合排行对比表,给大家提供一个更加清晰的对比结果。我们主要关注的是国内开源大模型和一些全球主流模型的对比结果。
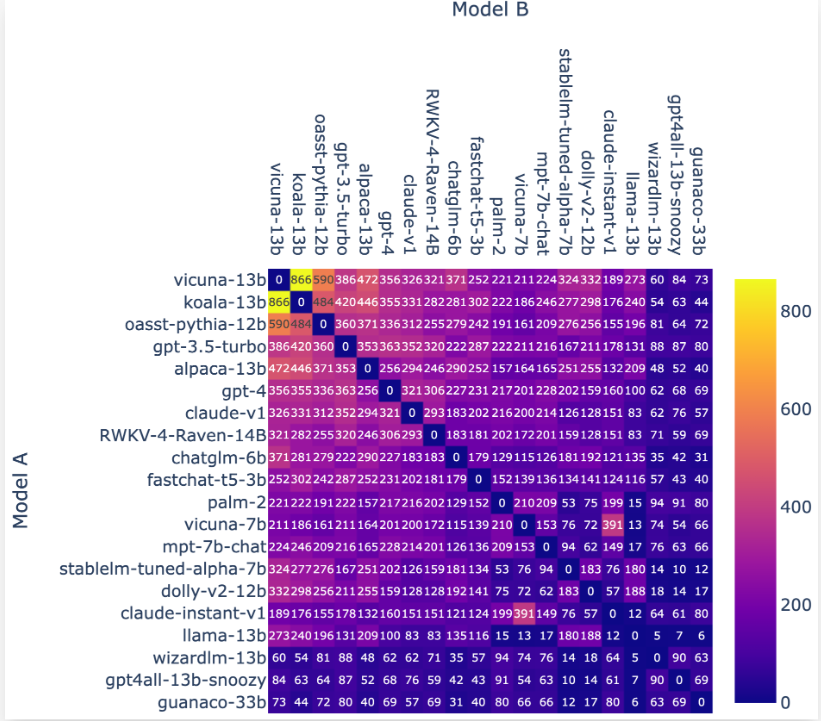
LM-SYS全称Large Model Systems Organization,是由加利福尼亚大学伯克利分校的学生和教师与加州大学圣地亚哥分校以及卡内基梅隆大学合作共同创立的开放式研究组织。该团队在2023年3月份成立,目前的工作是建立大模型的系统,是聊天机器人Vicuna的发布团队。今天开源 了包含3.3万包含真实人类偏好的对话数据集和3000条专家标注的对话数据集:Chatbot Arena Conversation Dataset和MT-bench人工注释对话数据集。

OpenAI最新发布了GPT-3.5-Turbo-Instruct,这是一款强大的指令遵循大模型。尽管官方没有发布官方博客介绍,但我们将在本文中详细探讨这一模型的特点以及其在人工智能领域的价值。
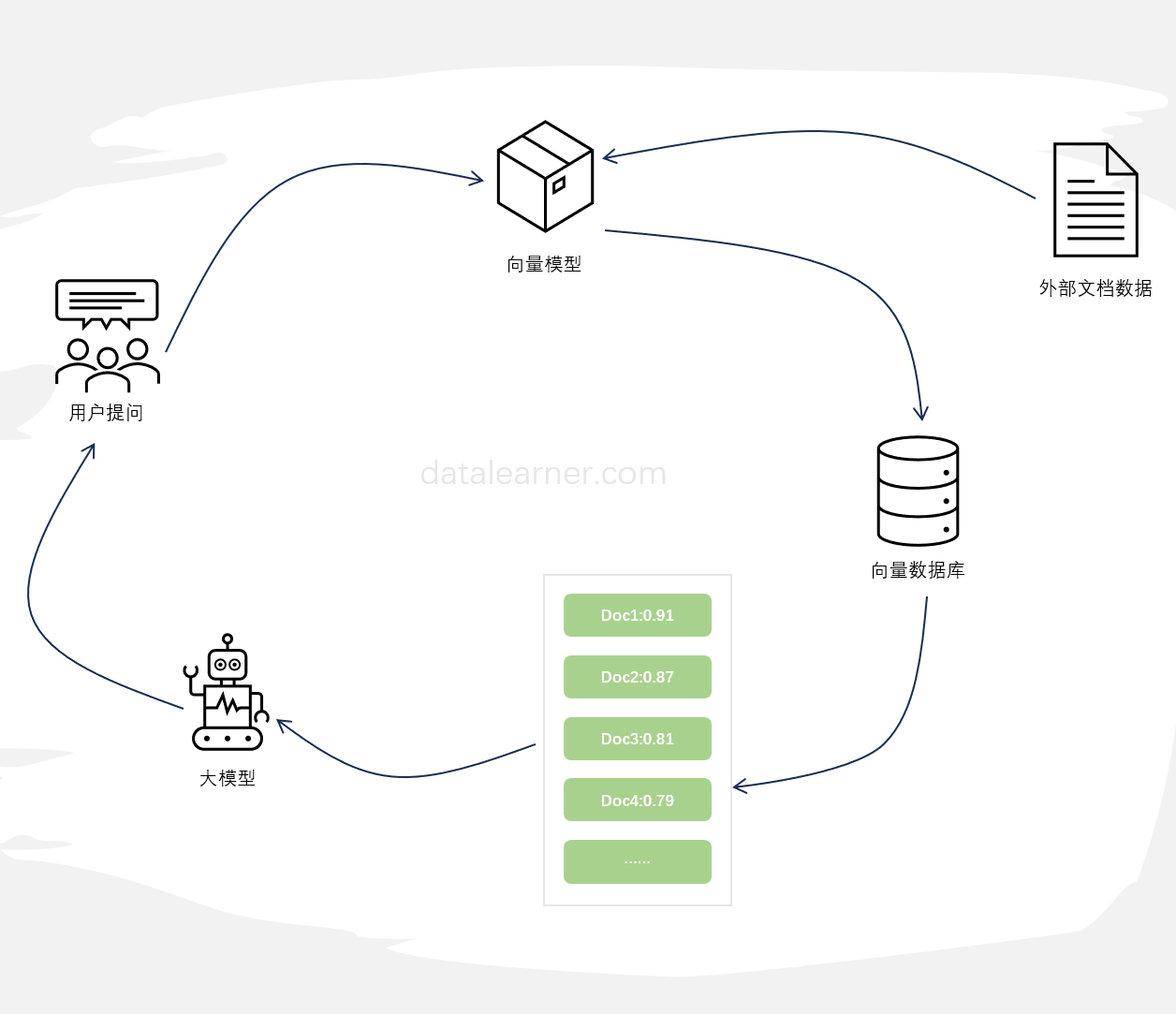
检索增强生成(Retrieval-augmented generation,RAG)是一种将外部知识检索与大型语言模型生成相结合的方法,通常用于问答系统。当前使用大模型基于外部知识检索结果进行问答是当前大模型与外部知识结合最典型的方式,也是检索增强生成最新的应用。然而,近期的研究表明,这种方式并不总是最佳选择,特别是当检索到的文档数量较多时,这种方式很容易出现回答不准确的情况。为此,LangChain最新推出了LongContextReorder,推出了一种新思路解决这个问题。

大模型的长输入在很多场景下都有非常重要的应用,如代码生成、故事续写、文本摘要等场景,支撑更长的输入通常意味着更好的结果。昨天,斯坦福大学、加州伯克利大学和Samaya AI的研究人员联合发布的一个论文中有一个非常有意思的发现:当相关信息出现在输入上下文的开始或结束时,大模型的性能通常最高,而当大模型必须访问长上下文中间的相关信息时,性能显著下降。本文将简单介绍一下这个现象。
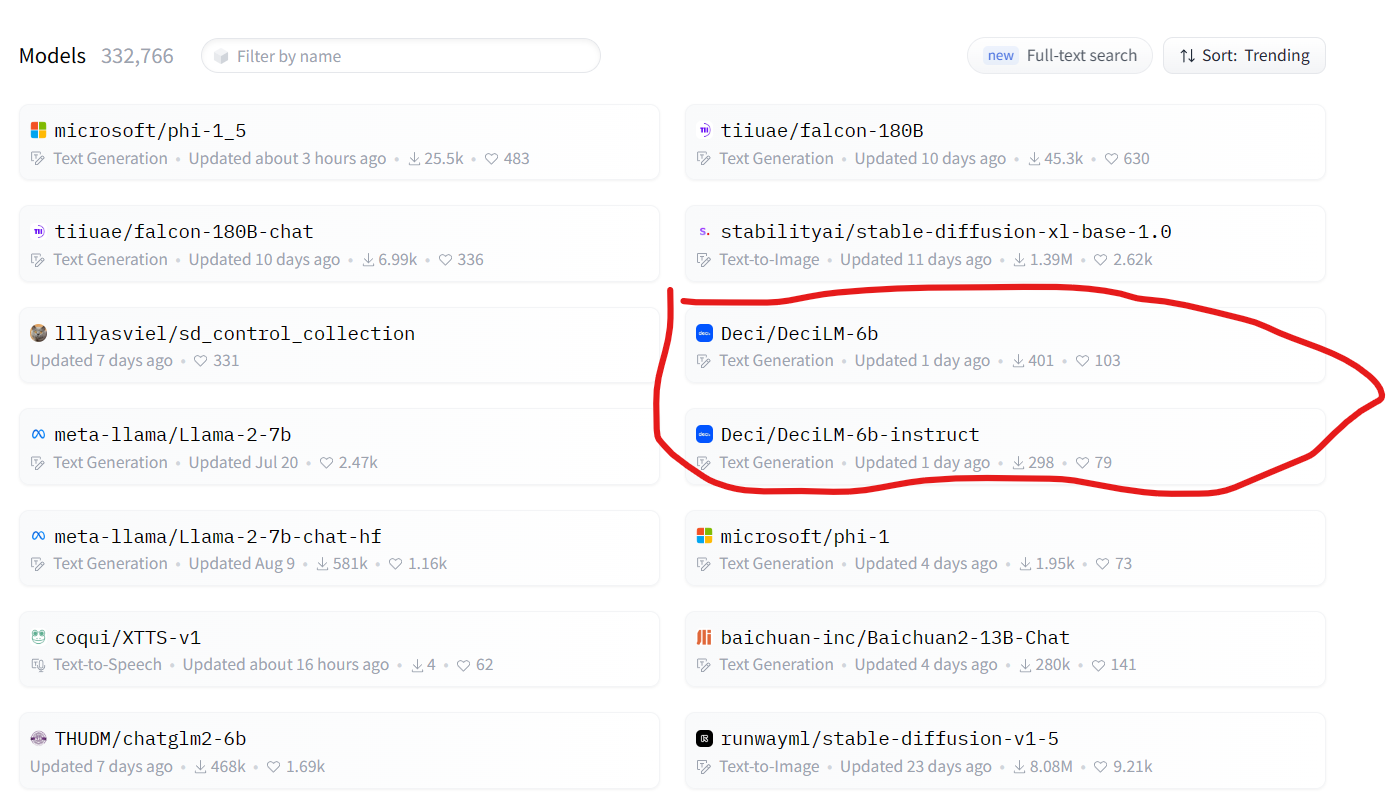
随着大型语言模型(LLMs)的不断发展,它们在训练和推理方面的计算需求已经呈指数级增长。这一趋势不仅带来了高昂的成本和能源消耗,还引入了模型部署和可伸缩性方面的障碍。为此,DeciLM开源了2个全新的DeciLM-6B和DeciLM-6B-Instruct大模型,参数比LLaMA2 7B略低,性能相当,但是推理速度却超过LLaMA2 7B的15倍。
百川智能是前搜狗创始人王小川创立的一个大模型创业公司,主要的目标是提供大模型底座来提供各种服务。虽然成立很晚(在2023年4月份成立),但是三个月后便发布开源了Baichuan系列开源模型,并上架了Baichun-53B的大模型聊天服务。这些模型受到了广泛的关注和很高的平均。而2个月后,百川智能再次开源第二代baichuan系列大模型,其能力提升明显。
Anthropic公司宣布,其开发的智能助手Claude推出收费订阅服务,命名为Claude Pro,定价20美元一个月(或者18英镑)。免费用户依然可以使用,但是有发送频率限制。本篇博客将解释一下ClaudeAI的Claude服务是否收费以及收费之后的ClaudePro提供的服务等。

大模型对显卡资源的消耗是很大的。但是,具体每个模型消耗多少显存,需要多少资源大模型才能比较好的运行是很多人关心的问题。此前,DataLearner曾经从理论上给出了大模型显存需求的估算逻辑,详细说明了大模型在预训练阶段、微调阶段和推理阶段所需的显存资源估计,而HuggingFace的官方库Accelerate直接推出了一个在线大模型显存消耗资源估算工具Model Memory Calculator,直接可以估算在HuggingFace上托管的模型的显存需求。

Prompt技巧一直是提升ChatGPT等大语言模型使用效率的最重要方法之一。为此,OpenAI官方也在不断地分享官方的Prompt技巧。2023年的8月31日,OpenAI官方最新分享了一个教室使用的Prompt来帮助老师授课的案例。尽管这是针对老师的Prompt教程,但是其中的设计思路其实也可以广泛运用在客服、问答系统、编程等领域。

MetaAI在2023年8月31日开源了一个全新的图像数据集,FACET(FAirness in Computer Vision EvaluaTion),FACET数据集包含32,000张图片和50,000人,这些图片由专家进行了详细的标注,包括人口统计属性(如感知性别表达和感知年龄组)和其他物理属性(如感知肤色和发型)。这样的设计使得研究人员可以更全面、更深入地评估模型在不同人群中的表现,从而更准确地识别和解决模型的不公平性问题。
OpenAI发布了ChatGPT的企业版,这是一个专为企业设计的聊天机器人。这个版本不仅提供了企业级的安全和隐私保护,还具有更高的处理速度和更多的自定义选项。相比较个人版的ChatGPT,企业版主要是提升了性能、强调了安全等。