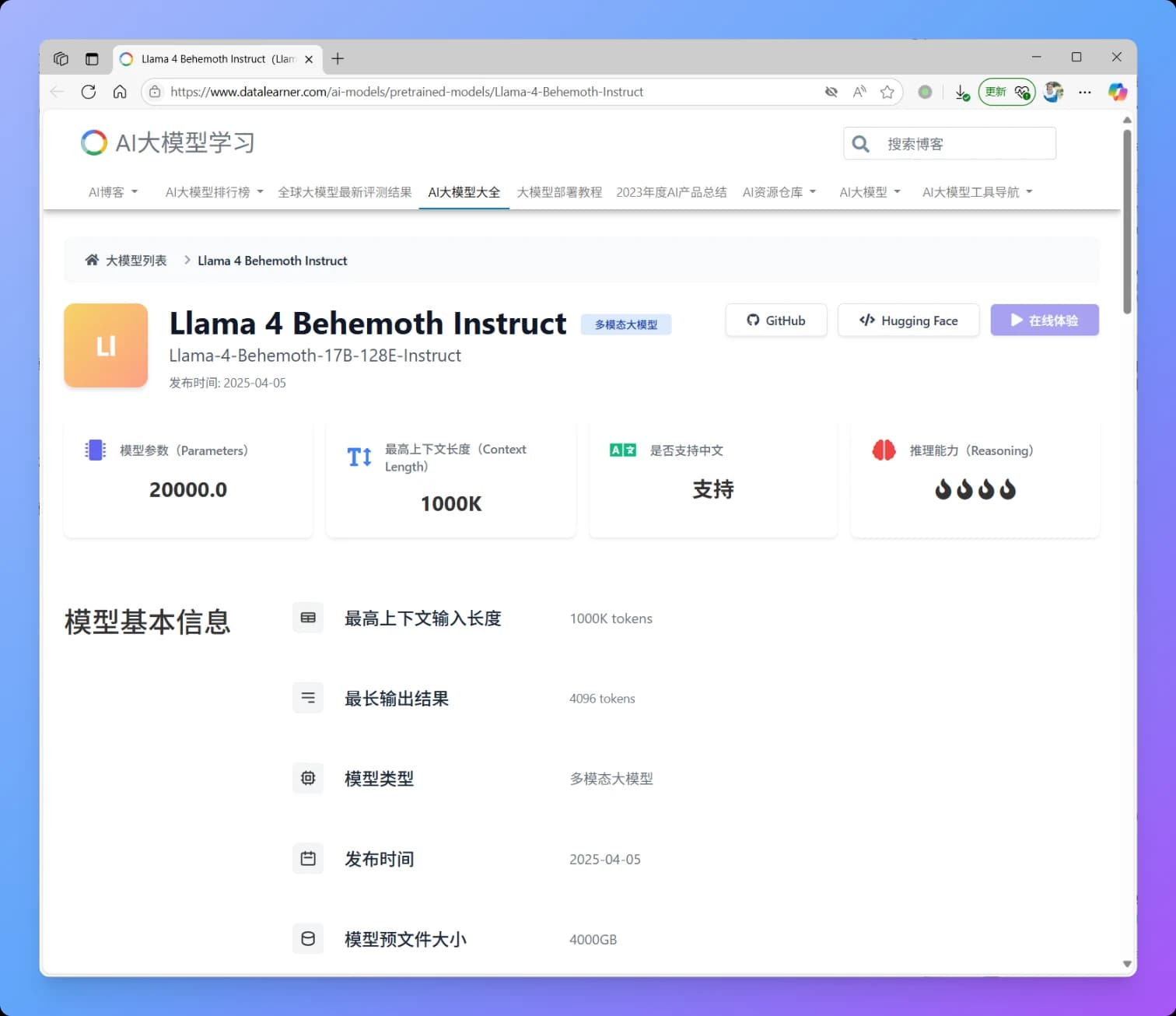
大模型可以运营自动售货机吗?Anthropic的Project Vend实验:Claude能成功经营一家小店吗?答案是亏损严重还会免费赠送商品!
昨天,Anthropic公布了一项引人注目的实验——Project Vend。他们让旗下的大模型Claude Sonnet 3.7在一个真实的办公环境中,自主经营一家小型自动化商店,为期约一个月。这个实验的目标是探索,在不久的将来,AI模型在真实经济体中自主运行任务的可行性、潜在的成功模式以及那些出人意料的失败方式。实验结果非常强大,也充满了令人深思的细节!