
ClawdBot:最新火爆网络的AI的桌面助手简介
ClawdBot 是一款开源AI代理工具,旨在帮助用户在本地设备上处理各种任务,在科技社区中迅速获得关注。它于2025年底由开发者Peter Steinberger(@steipete)推出,基于Anthropic的Claude模型,名称结合了“Claw”(龙虾钳子)和“Claude”,并以龙虾作为吉祥物,象征其适应性和本地运行特性。该工具强调本地优先的设计,用户可以完全控制数据和过程,避免对云服务的依赖。
聚焦人工智能、大模型与深度学习的精选内容,涵盖技术解析、行业洞察和实践经验,帮助你快速掌握值得关注的AI资讯。
ClawdBot 是一款开源AI代理工具,旨在帮助用户在本地设备上处理各种任务,在科技社区中迅速获得关注。它于2025年底由开发者Peter Steinberger(@steipete)推出,基于Anthropic的Claude模型,名称结合了“Claw”(龙虾钳子)和“Claude”,并以龙虾作为吉祥物,象征其适应性和本地运行特性。该工具强调本地优先的设计,用户可以完全控制数据和过程,避免对云服务的依赖。

2026 年 1 月初,原名 MetaGPT 的 AI 开发框架完成了一次重大升级,将其核心产品 MGX 正式更名为 Atoms。这一消息由 DeepWisdom 团队在 X(原 Twitter)等平台发布,标志着该项目从单纯的“AI 编程助手”正式转向“AI 构建真实生意”的全新定位。

就在刚刚,阿里开源了全新的语音合成大模型Qwen3-TTS系列!本次开源的语音合成模型共5个版本,最小的仅0.6B参数规模,最大的模型参数也就1.7B,基本上手机端都可以运行。此次发布不仅在性能上宣称超越了许多商业级闭源模型(如 OpenAI 的 GPT-4o-Audio 和 ElevenLabs),更重要的这应该是阿里通义千问团队首次开源语音合成系列大模型。

就在大家还在争论 AI 编程上限的时候,Cursor 团队发布了一份非常值得大家关注的内部测试报告,展示了当我们将 Agent 的规模和运行时间推向极致时,会发生什么。这不仅仅是简单的代码生成,而是让 AI 像人类团队一样协作,构建百万行级别的项目。这项实验为我们揭示了 AI 在编码领域的潜力与局限,值得每位开发者关注。

Anthropic 于 2026 年 1 月 12 日发布了 Cowork,这是一款基于 Claude 模型的新型 AI Agent工具,作为 Claude 桌面应用的 macOS 版本研究预览版推出。目前仅限 Claude Max 订阅者使用,未来计划扩展到 Windows 和跨设备同步。Cowork 继承了 Claude Code 的核心代理能力,但更注重非开发者用户的日常生产力任务,例如访问用户指定的文件夹,读取、编辑或创建文件,帮助整理杂乱下载、从截图生成电子表格,或从笔记起草报告。

MMEB(Massive Multimodal Embedding Benchmark)是一个用于评估多模态嵌入模型的基准测试框架。该基准最初聚焦于图像-文本嵌入,并在后续版本中扩展到文本、图像、视频和视觉文档输入。MMEB通过收集多样化数据集,提供一个统一的评估平台,用于测试模型在分类、检索和其他任务上的性能。

就在刚刚,阿里巴巴正式免费开源了两款全新的多模态模型——Qwen3-VL-Embedding(多模态向量模型)和 Qwen3-VL-Reranker(多模态重排序模型),首次在开源体系中系统性补齐了多模态 RAG 在“向量化检索 + 精排重排”两个关键环节上的能力空白。这两个模型是基于强大的Qwen3-VL基础模型构建的专用多模态向量与重排(Reranking)模型。
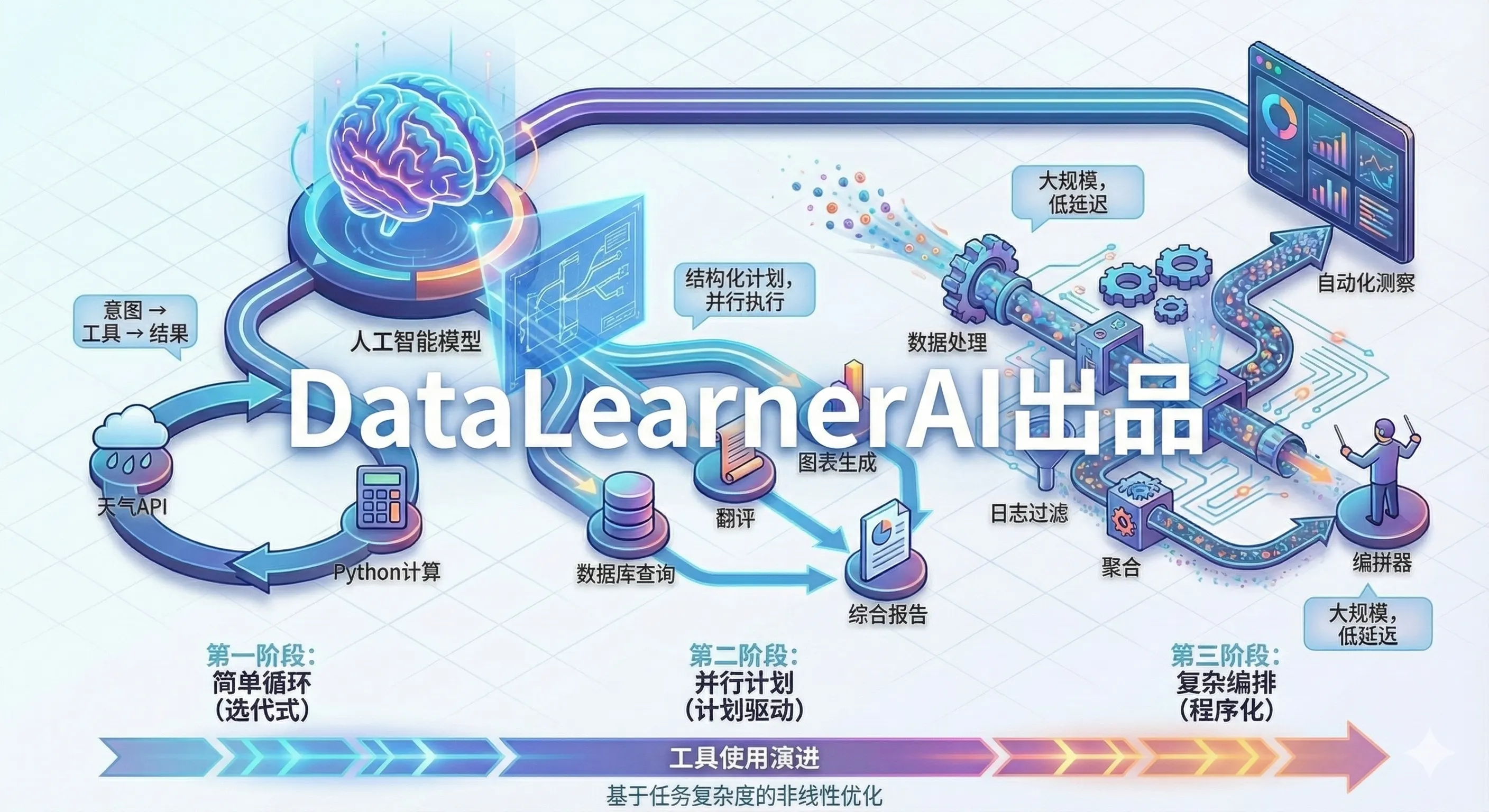
本文系统梳理了大模型工具使用(Tool Use)的三个演进阶段:循环式工具选择(Function Calling)、计划驱动执行(Plan-then-Execute)和程序化工具编排(Programmatic Tool Calling)。从 OpenAI Function Calling 的单次调用模式,到支持并行调度的计划-执行范式,再到最新的代码驱动编排方式,工具使用正在从"逐步决策"走向"计划驱动、代码驱动"。

AI Agent 的一个关键趋势正在浮现:从“快速回答问题”转向“长时间稳定执行复杂任务”。本文系统梳理了为什么 Anthropic、OpenAI 等企业开始强调“长时运行 Agent”,并解释其真实含义并非模型一直思考,而是通过作业化、异步执行、可恢复运行和动态上下文管理,实现跨会话完成复杂目标。文章深入对比了长时 Agent 与传统脚本化 LLM Loop 的本质差异,分析其在自治能力、上下文工程、耐久执行与治理上的核心价值,并总结构建长时运行 AI Agent 所需的关键技术等。

今天,Claude Code 的创建者 Boris 发了一条很长的 thread,第一次比较完整地讲了他自己是怎么使用 Claude Code 的。共13条总结,我们这里总结一下,供大家参考。
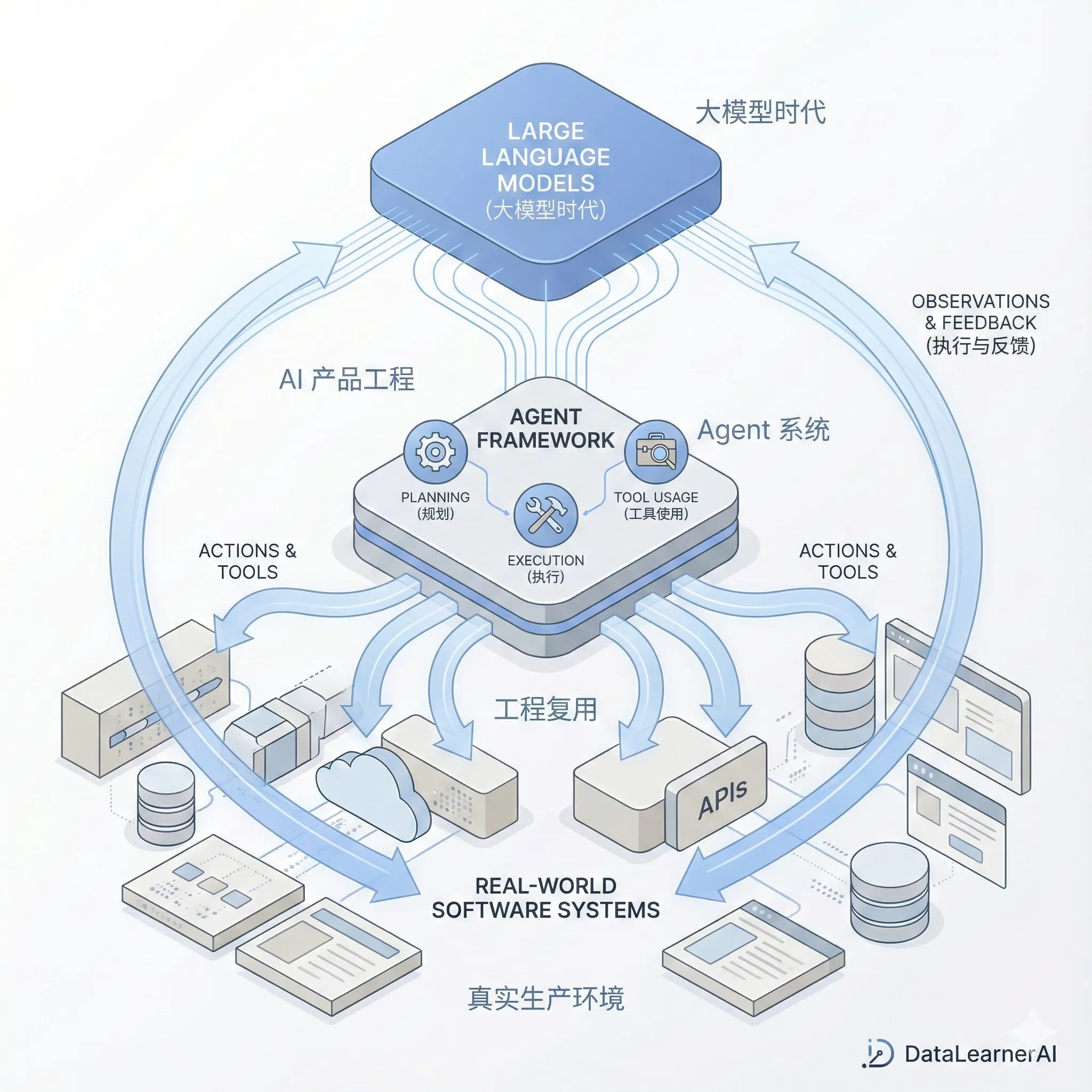
本文基于 Manus 一线工程成员的真实实践,总结并分析了 大模型时代 AI 产品在工程与复用层面发生的关键变化。文章并不关注模型参数或算法细节,而是聚焦于真实生产环境中的工程问题:功能交付的责任边界如何变化、为何原型验证比完整规划更重要,以及在 Agent 系统中个人角色与系统边界如何被重新定义。这些经验揭示了一个趋势——在大模型具备“执行能力”之后,AI 产品的可用性越来越依赖工程体系本身,而非模型能力本身。本文适合关注 AI 工程实践、Agent 架构以及大模型落地问题的技术读者参考。
Context Arena 是一个专注于评估大语言模型长上下文处理能力的基准平台。它基于 OpenAI 发布的 Multi-Round Coreference Resolution (MRCR) 数据集,提供交互式排行榜,用于比较不同模型在复杂长对话中的信息检索和理解性能。该基准强调模型在长上下文下的实际表现,避免单纯依赖训练数据记忆。
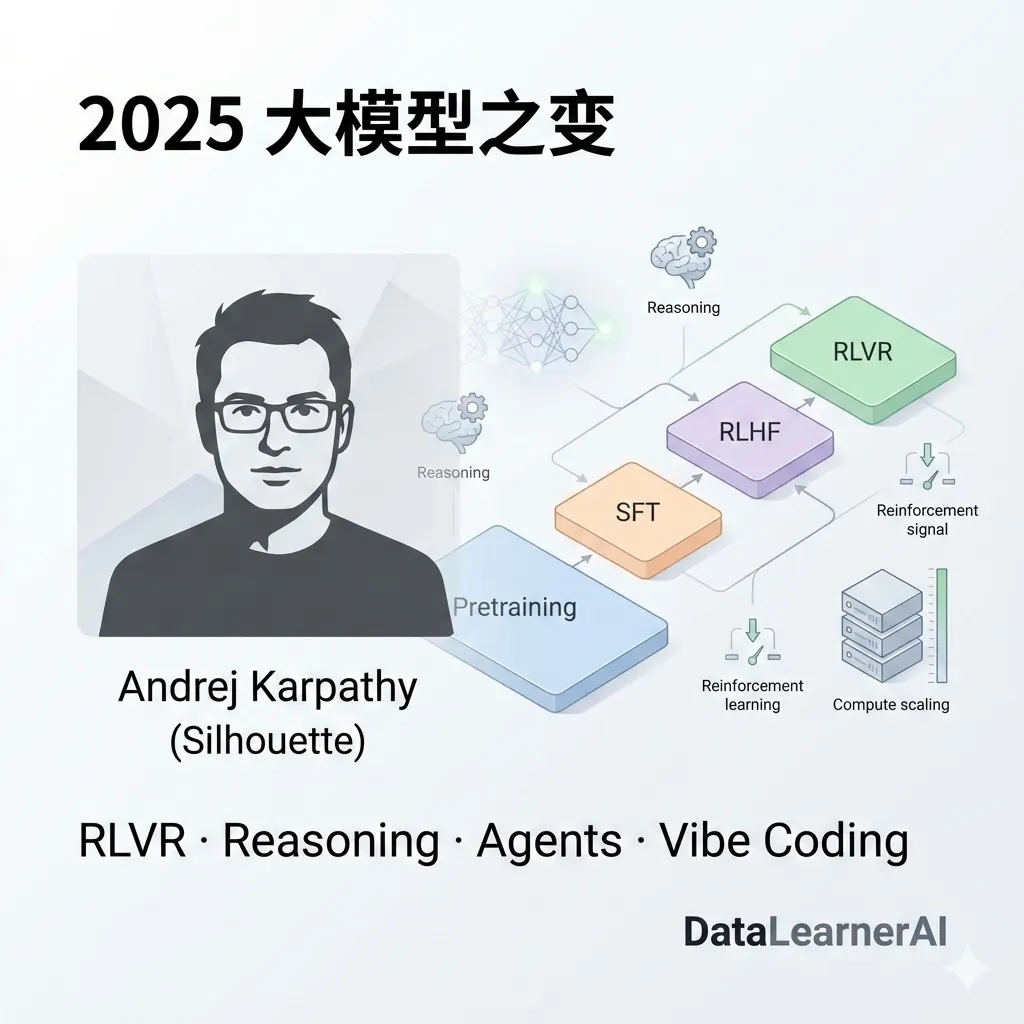
昨天,Karpathy 发布了《2025 LLM Year in Review》,对过去一年大模型领域发生的结构性变化进行了深度复盘。在这篇总结中,他不再纠结于具体的模型参数,而是将目光投向了推理范式的演进、Agent 的真实形态以及一种被称为“Vibe Coding”的新型开发模式。

在今年的Microsoft Build 2023大会上,来自OpenAI的研究员Andrej Karpathy在5月24日的一场汇报中用了40分钟讲解了ChatGPT是如何被训练的,其中包含了训练一个能支持与用户对话的GPT的全流程以及涉及到的一些技术。信息含量丰富,本文根据这份演讲总结。
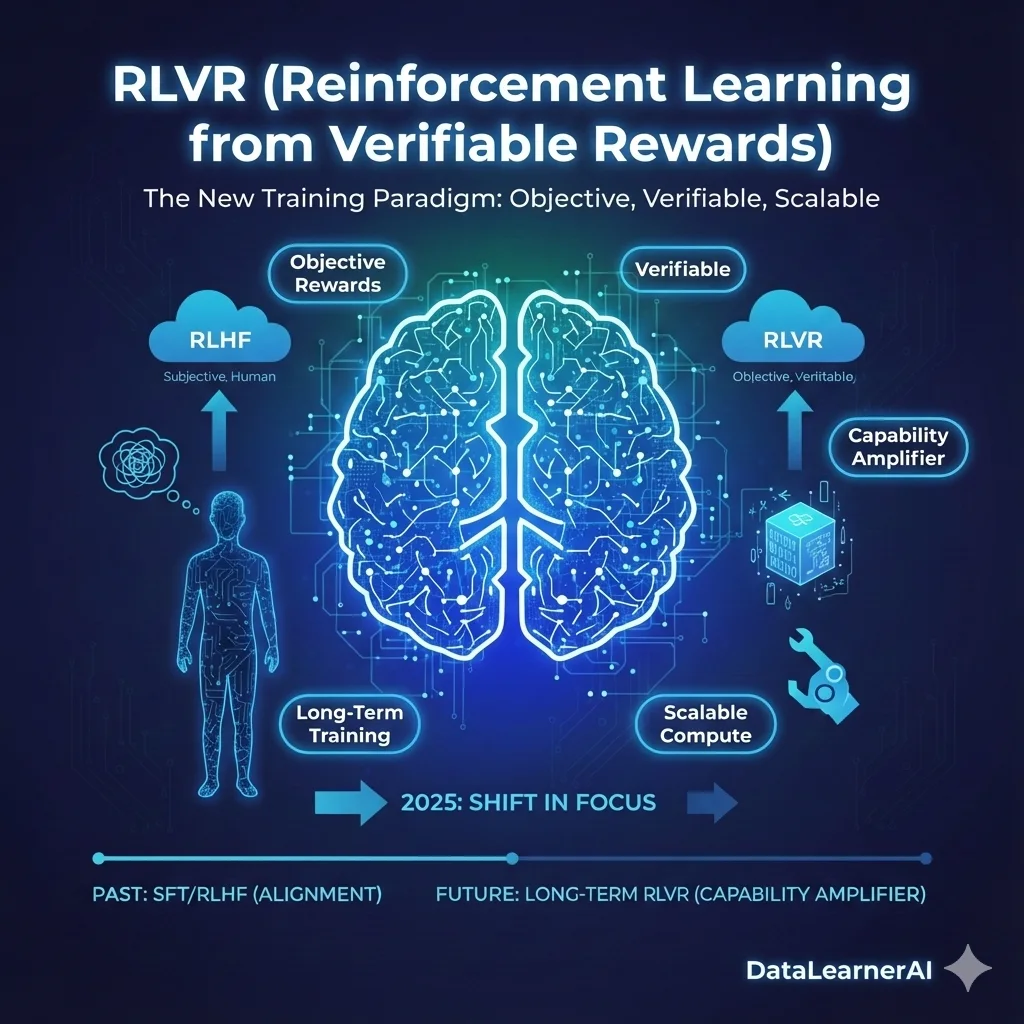
过去几年,大语言模型的训练路线相对稳定:更大的模型、更长的预训练、更精细的指令微调与人类反馈对齐。这套方法在很长一段时间内持续奏效,也塑造了人们对“模型能力如何提升”的基本认知。但在 2025 年前后,一种并不算新的训练思路突然被推到台前,并开始占据越来越多的计算资源与工程关注度,这就是**基于可验证奖励的强化学习(Reinforcement Learning from Verifiable Rewards,RLVR)**。
2025 年 12 月 17 日,Google 正式发布了 Gemini 3 Flash 模型。 这是 Gemini 3 系列中的一款高性能轻量模型,目前已经在 Gemini App 以及 Google 搜索的 AI Mode 中作为默认模型上线。
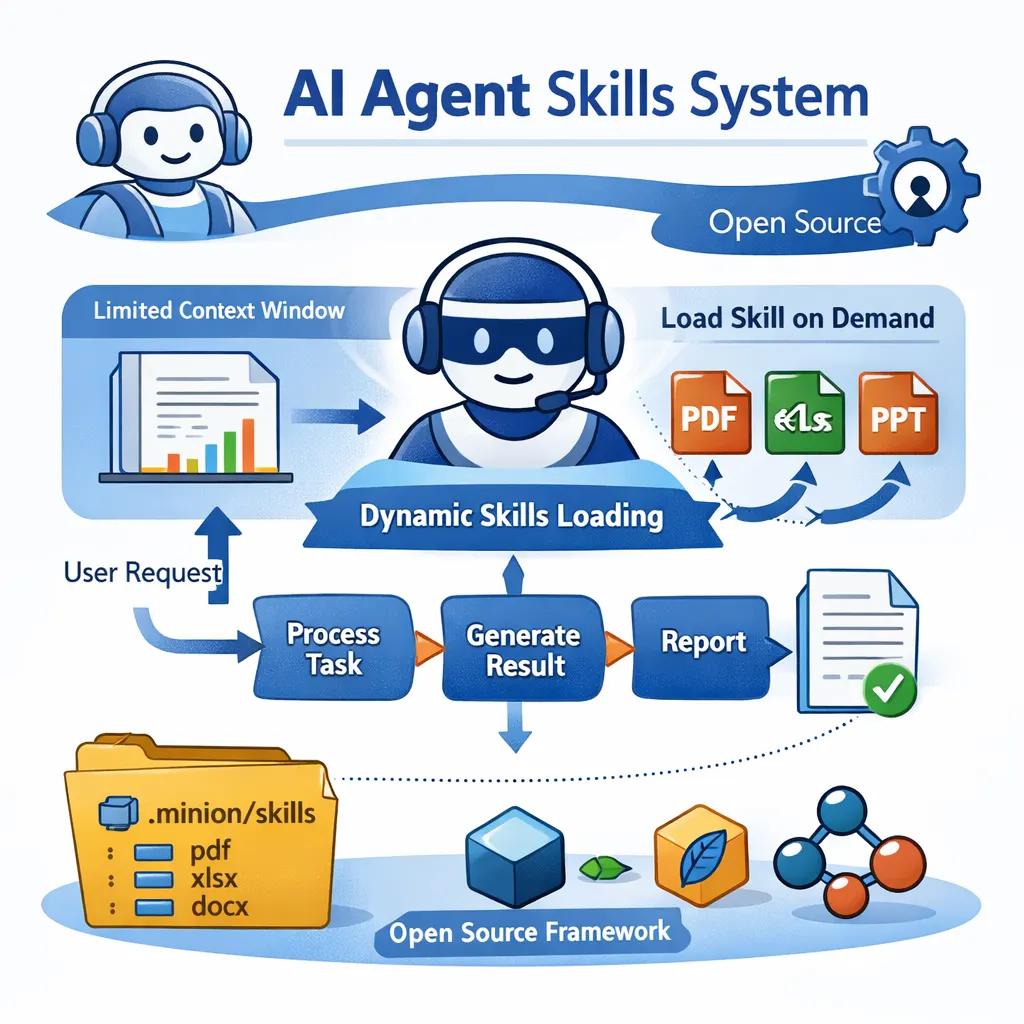
本文介绍了 Claude 最近推出的 Skills 系统,以及作者在 Minion 框架中实现的一个完全开源的版本。Skills 的核心思路是让 AI Agent 在需要时再加载对应的专业能力,而不是一开始就把所有工具和知识都塞进上下文,从而缓解上下文窗口有限、成本高、响应慢的问题。
OpenAI 刚刚把 GPT-5.2 推上来了。我们在 DataLearnerAI 上把它和 Claude Opus 4.5、Gemini 3.0 Pro(Preview) 放到同一个对比页里,拉齐公开评测与基础规格,做一个“站在真实选择角度”的快速判断。

2025年11月24日,Anthropic正式发布了Programmatic Tool Calling (PTC)特性,允许Claude通过代码而非单次API调用来编排工具执行。这一创新被认为是Agent开发的重要突破,能够显著降低token消耗、减少延迟并提升准确性。 然而,作为minion框架的创建者,我想分享一个有趣的事实:minion从一开始就采用了这种架构理念。在PTC概念被正式提出之前,minion已经在生产环境中证明了这种方法的价值。

就在刚才,智谱推出了两个语音识别模型:闭源的 GLM-ASR 和开源的 GLM-ASR-Nano-2512。与过去他们更多关注通用大模型或多模态模型不同,这次聚焦的是语音转文字(ASR)任务,尤其面向中文语境、方言与复杂环境。以下是对这两款模型已知公开资料的整理与分析。

大模型究竟能否真正提升工程师的编码效率?Anthropic 最近发布的一份重量级内部研究给出了少见的、基于真实工程环境的数据答案。研究覆盖 132 名工程师、53 场深度访谈,以及 20 万条 Claude Code 使用记录,展示了 AI 在软件工程中的实际作用:从生产力显著提升(人均合并 PR 数同比增长 67%)、任务空间扩张(27% 的 Claude 工作原本不会被执行),到工程师技能版图、协作方式与职业路径的深刻变化。与此同时,研究也揭示了技能萎缩、监督负担、工作流变化等新挑战。这是一份罕见的“

这篇文章基于 Dwarkesh Patel 对 SSI 创始人、前 OpenAI 首席科学家 Ilya Sutskever 的长访谈,系统梳理了他对模型泛化、人类智能结构、持续学习、RL 与预训练局限、超级智能路径、对齐策略,以及 AI 未来经济与治理的整体判断。文章不仅整理了核心观点,也结合具体原文展开解读,呈现 Ilya 如何从“人类为何能泛化”这一根问题出发,重新思考下一代智能系统应当如何构建。
Tool Decathlon(简称 Toolathlon)是一个针对语言代理的基准测试框架,用于评估大模型在真实环境中使用工具执行复杂任务的能力。该基准涵盖32个软件应用和604个工具,包括日常工具如 Google Calendar 和 Notion,以及专业工具如 WooCommerce、Kubernetes 和 BigQuery。它包含108个任务,每个任务平均需要约20次工具交互。该框架于2025年10月发布,旨在填补现有评测在工具多样性和长序列执行方面的空白。通过执行式评估,该基准提供可靠的性能指

几个小时前,DeepSeek 突然发布了两款全新的推理模型:DeepSeek V3.2 正式版与DeepSeek V3.2-Speciale。前者已经全面替换官方网页、App 与 API 成为新的默认模型;后者则以“临时研究 API”的方式开放,被定位为极限推理版本。