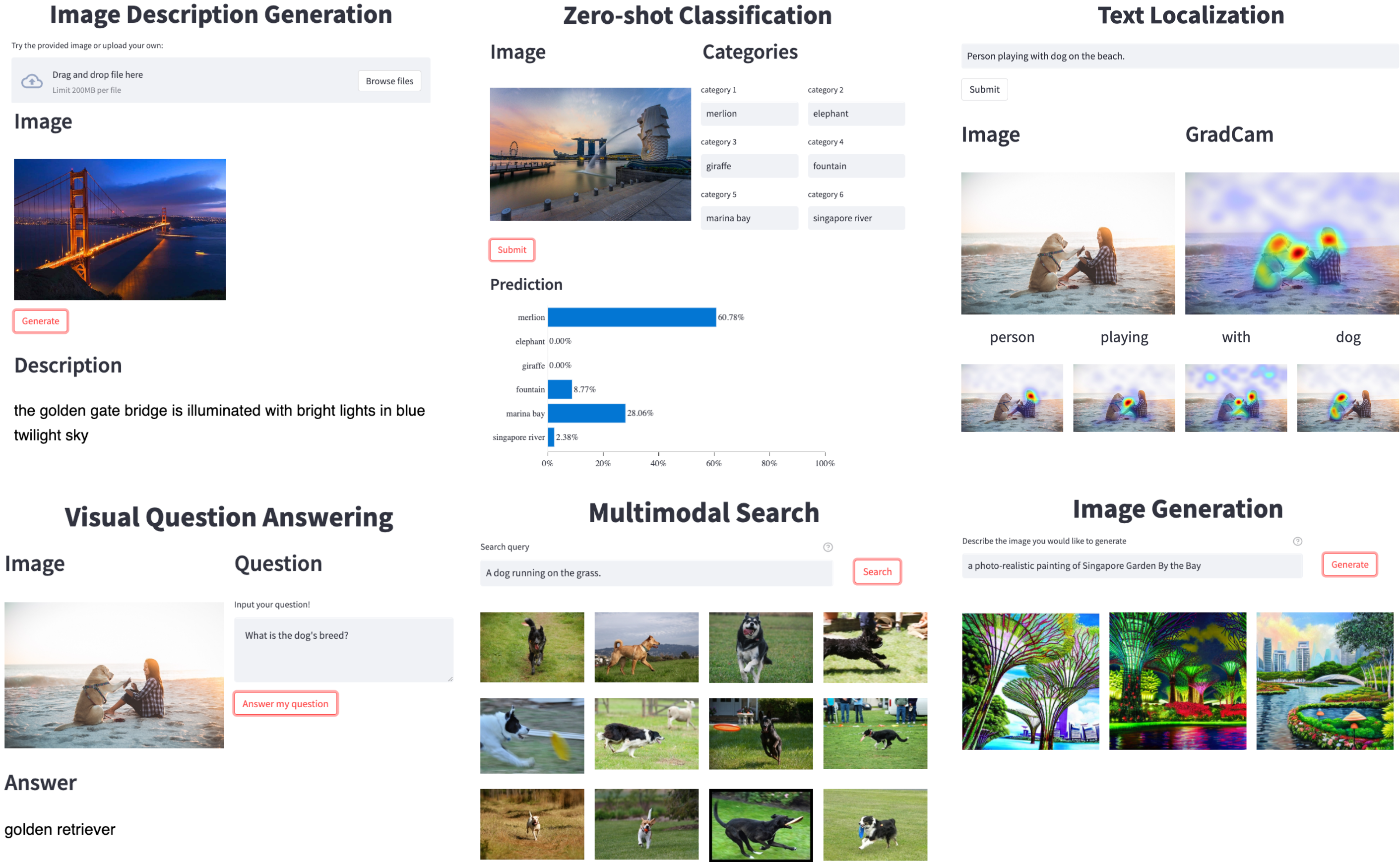
Saleforce发布最新的开源语言-视觉处理深度学习库LAVIS
Salesforce的研究人员开发了LAVIS(LAnguage-VISION的缩写),这是一个开源的库,用于在丰富的常见任务和数据集系列上训练和评估最先进的语言-视觉模型,并用于在定制的语言-视觉数据上进行现成的推理。
聚焦人工智能、大模型与深度学习的精选内容,涵盖技术解析、行业洞察和实践经验,帮助你快速掌握值得关注的AI资讯。
Salesforce的研究人员开发了LAVIS(LAnguage-VISION的缩写),这是一个开源的库,用于在丰富的常见任务和数据集系列上训练和评估最先进的语言-视觉模型,并用于在定制的语言-视觉数据上进行现成的推理。
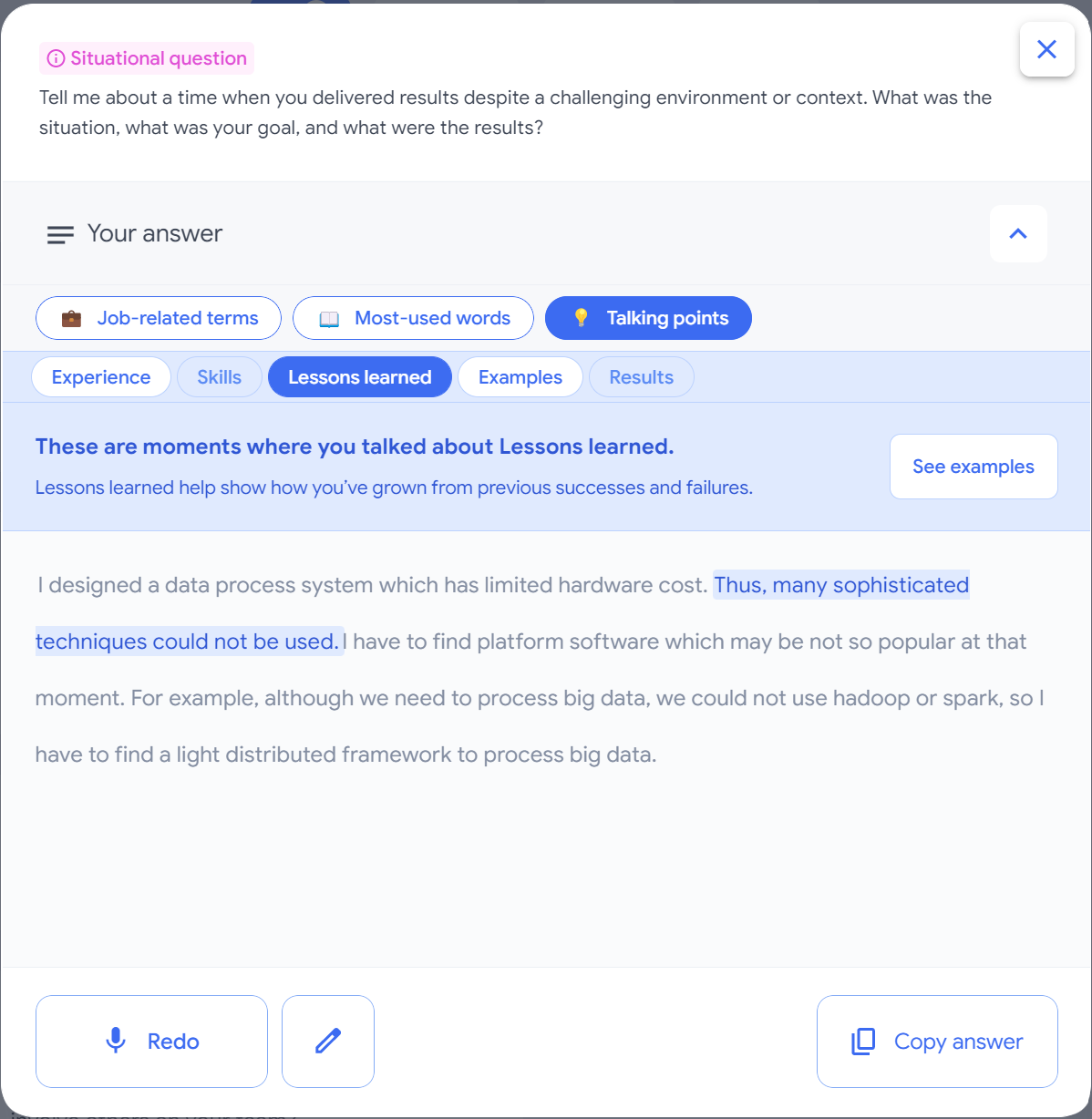
最近,谷歌发布了一项新的工具:Google Interview Warmup,让你练习回答由行业专家选定的问题,并使用机器学习来转录你的答案,帮助你发现改进面试的回答。
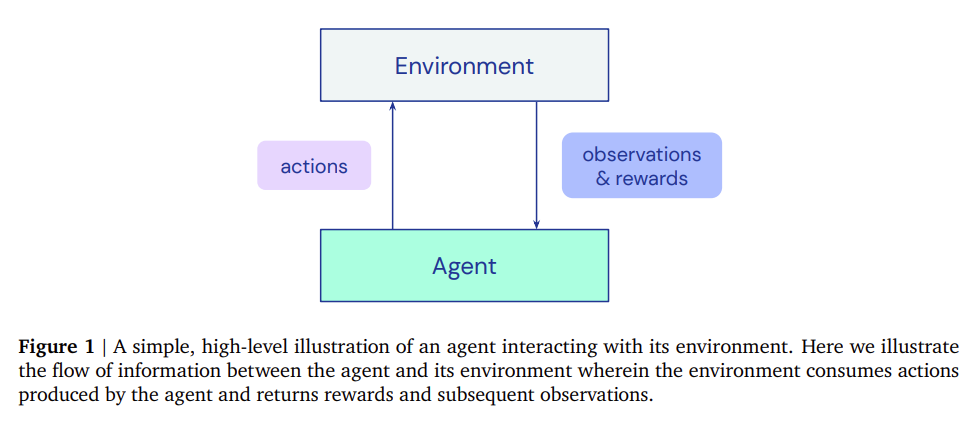
深度强化学习(RL)导致了许多最近的和突破性的进展。然而,强化学习的实施并不容易,与使深度学习拥有PyTorch这样简单的框架支持不同,强化学习的训练缺少强有力的工具支撑。为了解决这些问题,DeepMind发布了Acme,一个用于构建新的RL算法的框架,该框架是专门为实现代理而设计的

今天Google发布了TensorStore,这是一个开源的C++和Python软件库,设计用于存储和操作大规模n维数据。TensorStore已经被用来解决科学计算中的关键工程挑战(例如,管理和处理神经科学中的大型数据集,如石油级的三维电子显微镜数据和神经元活动的 "4d "视频)。TensorStore还被用于创建大规模的机器学习模型,如PaLM,解决了分布式训练期间管理模型参数(检查点)的问题。

Stable Diffusion是最近很火的Text-to-Image预训练模型(详细信息:https://www.datalearner.com/ai-resources/pretrained-models/stable-diffusion )。而现在,相关的视频教程已经出现。fast.ai的团队宣布了一门新的深度学习课程《From Deep Learning Foundations to Stable Diffusion》上线!
最近一段时间Text-to-Image模型十分火热。OpenAI的DALL·E2模型的效果十分惊艳。不过,由于Open AI现在的不Open策略,大家还无法使用这个模型,业界只开放了一个小版本的DALL·E mini。不过,前段时间,Stability AI发布的Stable Diffusion其效果明显好于现有模型,且免费开放使用,让大家都开心了一把。不过原有模型是Torch实现的,而现在,基于Tensorflow/Keras实现的Stable Diffusion已经开源。

LAION全称Large-scale Artificial Intelligence Open Network,是一家非营利组织,成员来自世界各地,旨在向公众提供大规模机器学习模型、数据集和相关代码。他们声称自己是真正的Open AI,100%非盈利且100%Free。在九月份,他们公布了一个全新的图像-文本对(image-text pair)数据集。该数据集包含4亿条数据。
昨天,Meta的Zuckerberg宣布,将PyTorch由Meta AI移交给Linux Foundation托管。这意味着PyTorch从今天起从Meta独立,并作为Linux Foundation下的一个项目。
强化学习(Reinforcement Learning)是近年来十分火热的一种机器学习研究领域。随着DeepMind(谷歌旗下的研究机构)的AlphaGo在围棋界战胜人类之后,这类方法开始被人们广泛关注。但是,强化学习并不是突然出现,也不是DeepMind的首创,在很久之前,这种方法已经开始发展,但是近年来,随着AI相关的软硬件能力的提升,强化学习的实用价值也开始显现。本文不涉及强化学习本身的技术细节,仅仅记录这种方法的历史由来。

随着安全隐私被大家所重视,网站开启HTTPS访问已经是不可阻挡的趋势。HTTPS协议就是借助SSL/TLS证书实现http的加密传输的协议(HTTP Over SSL/TLS)。本文将记录如何使用第三方库申请Let's Encrypt证书,并在tomcat中开启相关的功能。

原来直接用root账户授权远程访问失败,最新的MySQL8不允许直接创建并授权用户远程访问权限,必须先让自己有GRANT权限,然后创建用户,再授权。
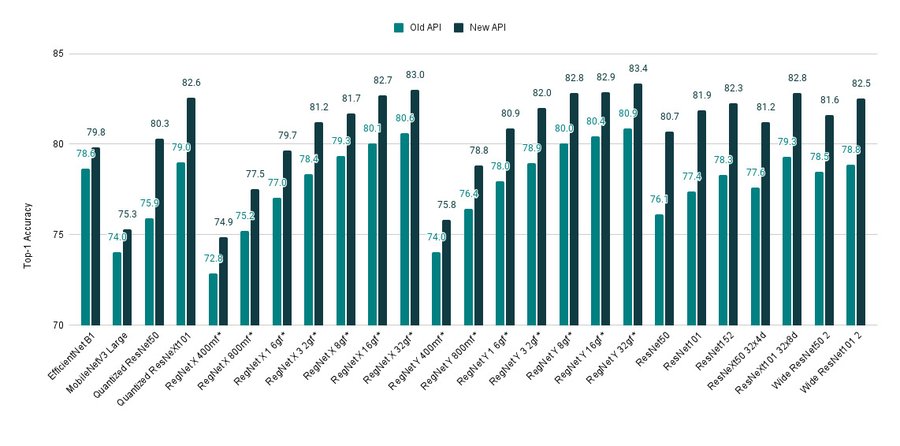
PyTorch最新的1.12版本已经在前天发布。而其中TorchVision是基于PyTorch框架开发的面向CV解决方案的一个PyThon库,其最主要的特点是包含了很多流行的数据集、模型架构以及预训练模型等。本次也随着PyTorch1.12的发布更新到了v0.13。此次发布包含几个非常好的提升,值得大家关注。
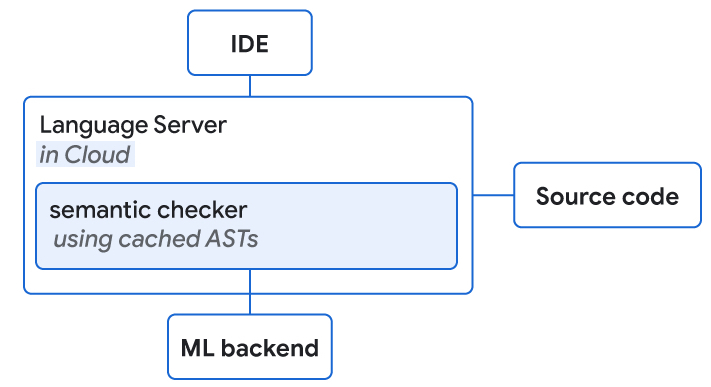
我们将介绍如何将ML和SE结合起来,开发一种新的基于Transformer的混合语义ML代码补全,现在可供内部谷歌开发人员使用。我们讨论了如何通过(1)使用ML对SE单标记建议重新排序,(2)使用ML应用单行和多行补全并使用SE检查正确性,或(3)使用单标记语义建议的ML的单行和多行延拓来组合ML和SE。

重磅福利,斯坦福大学在去年秋季开设了应该是全球第一个transformers相关的课程,授课人员来自OpenAI、Google Brain、Facebook人工智能实验室、DeepMind甚至是牛津大学的业界与学术界的一线大牛。而这两天,这门课相关视频也都公开了,大家可以去观看学习了!

《Python for Data Analysis: Data Wrangling with pandas, NumPy, and Jupyter》是由Wes McKinney撰写的Python数据分析专业工具书籍。很容易理解,这本书就是教大家如何使用Pandas、NumPy以及Jupyter分析数据的。
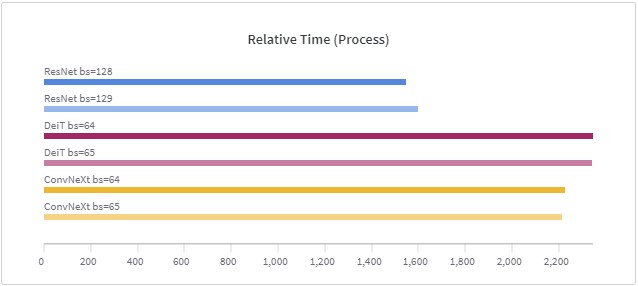
在深度学习训练中,由于数据太大,现在的训练一般是按照一个批次的数据进行训练。批次大小(batch size)的设置在很多论文或者教程中都提示要设置为$2^n$,例如16、32等,这样可能会在现有的硬件中获得更好的性能。但是,目前似乎没有人进行过实际的测试,例如32的batch size与33的batch size性能到底有多大差别?德国的Thomas Bierhance做了一系列实验,以验证批次大小设置为2的幂次方是不是真的可以加速。
指标(metrics)和损失函数(loss function)在深度学习和机器学习里面非常常见,很多时候他们的公式都似乎是一样的,在编写程序的时候,二者的区别好像也不是很大。那为什么还会有这两种不同的概念出现呢?本文将简单介绍一下二者的区别和应用。
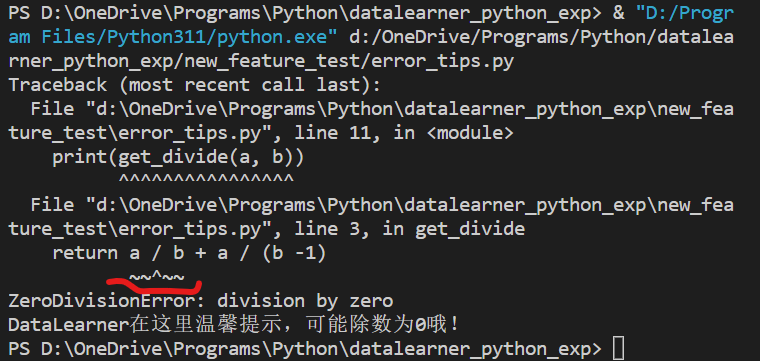
上个月Python的3.11版本发布了第一个beta版本,3.11带来了很多非常棒的新特性,例如错误提示更加具体,可以定位到具体代码位置等,十分友好,建议大家关注。这里简单为大家介绍一下。

昨天,卡地夫大学的NLP研究小组CardiffNLP发布了一个全新的NLP处理Python库——TweetNLP,这是一个完全基于推文训练的NLP的Python库。它提供了一组非常实用的NLP工具,可以做推文的情感分析、emoji预测、命名实体识别等。

亚马逊近线性大规模模型训练加速库MiCS来了!
前几天初创AI企业Nebuly开源了一个AI加速库nebulgym,它最大的特点是不更改你现有AI模型的代码,但是可以将训练速度提升2倍。
大规模的text-to-image模型没有公开预训练结果,OpenAI的意思就是我这玩意太厉害,随便放出来可能会被你们做坏事,而谷歌训练这个应该就是为了云服务挣钱,所以都没有公开可用的版本供大家玩耍。虽然业界有基于论文的实现,但是训练模型需要耗费大量的资源,没有开放的预训练结果,我们普通个人也很难玩起来。但是,大神Sahar提供了一个免费使用开源实现的text-to-image预训练模型的方式。

最近开始学习新的前端技术。以前开发网站直接使用jQuery+Bootstrap组合,感觉非常容易和方便。但是,现在前端貌似都开始转向基于构建的方式去开发。由于初学者进入一个项目看很多内容也不如上手启动一个项目感受好,本文抛弃原理,直接教大家上手创建一个vue项目。

就在儿童节前一天,Hugging Face发布了一个最新的深度学习模型评估库Evaluate。对于机器学习模型而言,评估是最重要的一个方面。但是Hugging Face认为当前模型评估方面非常分散且没有很好的文档。导致评估十分困难。因此,Hugging Face发布了这样一个Python的库,用以简化大家评估的步骤与时间。