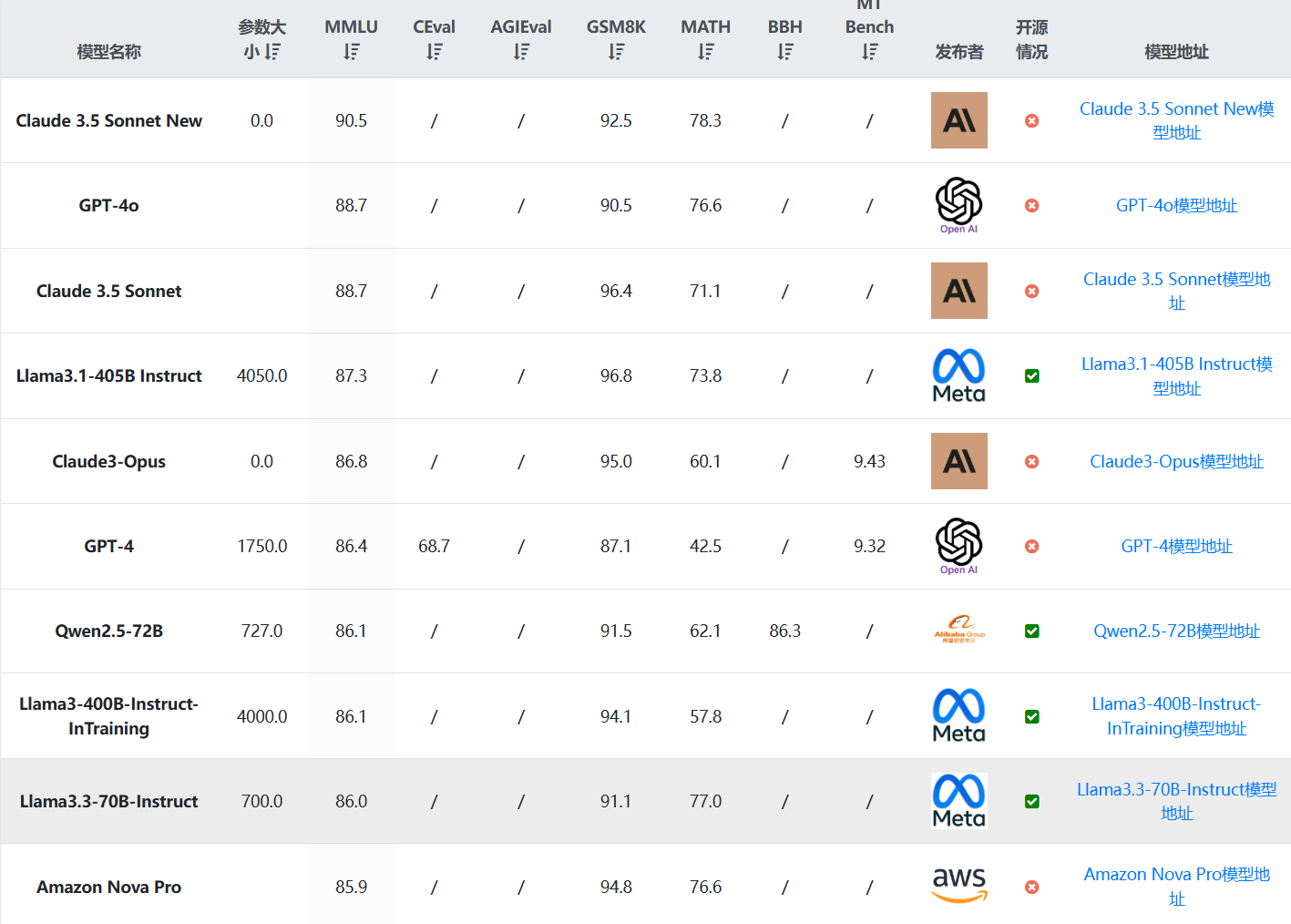
Meta开源Llama3.3-70B-Instruct模型:大模型后训练的佳作,性能超越4050亿参数规模的Llama3.1-405B大模型!
Llama系列大语言模型一直是开源领域的大模型标杆,Llama3系列大模型自从开源之后一直在不断更新。最早的Llama3模型于2024年4月开源,此后,几乎每个三个月都有一个新版本发布。就在昨天,Meta开源了最新的Llama3.3-70B模型,这是Llama3.3系列目前唯一开源的模型。尽管该模型的参数规模仅仅700亿,但是在多项评测基准上已经超过了4050亿参数规模的Llama3.1-405B,后者是Llama系列模型中参数规模最大的一个,也是业界开源模型中参数规模最高的模型之一。