
OpenAI发布最新Embedding模型——可惜又是一个收费API
嵌入(Embedding)是深度学习方法处理自然语言文本最重要的方式之一。它将人类的自然语言和文本转换成一个浮点型的向量。向量之间的距离代表了它们的关系。今天,OpenAI宣布了他们的Embedding新模型——text-embedding-ada-002。官方宣称这是目前OpenAI最强的嵌入模型,可以将任意文本转换成一个向量,且效果好于目前所有OpenAI的模型。
聚焦人工智能、大模型与深度学习的精选内容,涵盖技术解析、行业洞察和实践经验,帮助你快速掌握值得关注的AI资讯。
嵌入(Embedding)是深度学习方法处理自然语言文本最重要的方式之一。它将人类的自然语言和文本转换成一个浮点型的向量。向量之间的距离代表了它们的关系。今天,OpenAI宣布了他们的Embedding新模型——text-embedding-ada-002。官方宣称这是目前OpenAI最强的嵌入模型,可以将任意文本转换成一个向量,且效果好于目前所有OpenAI的模型。
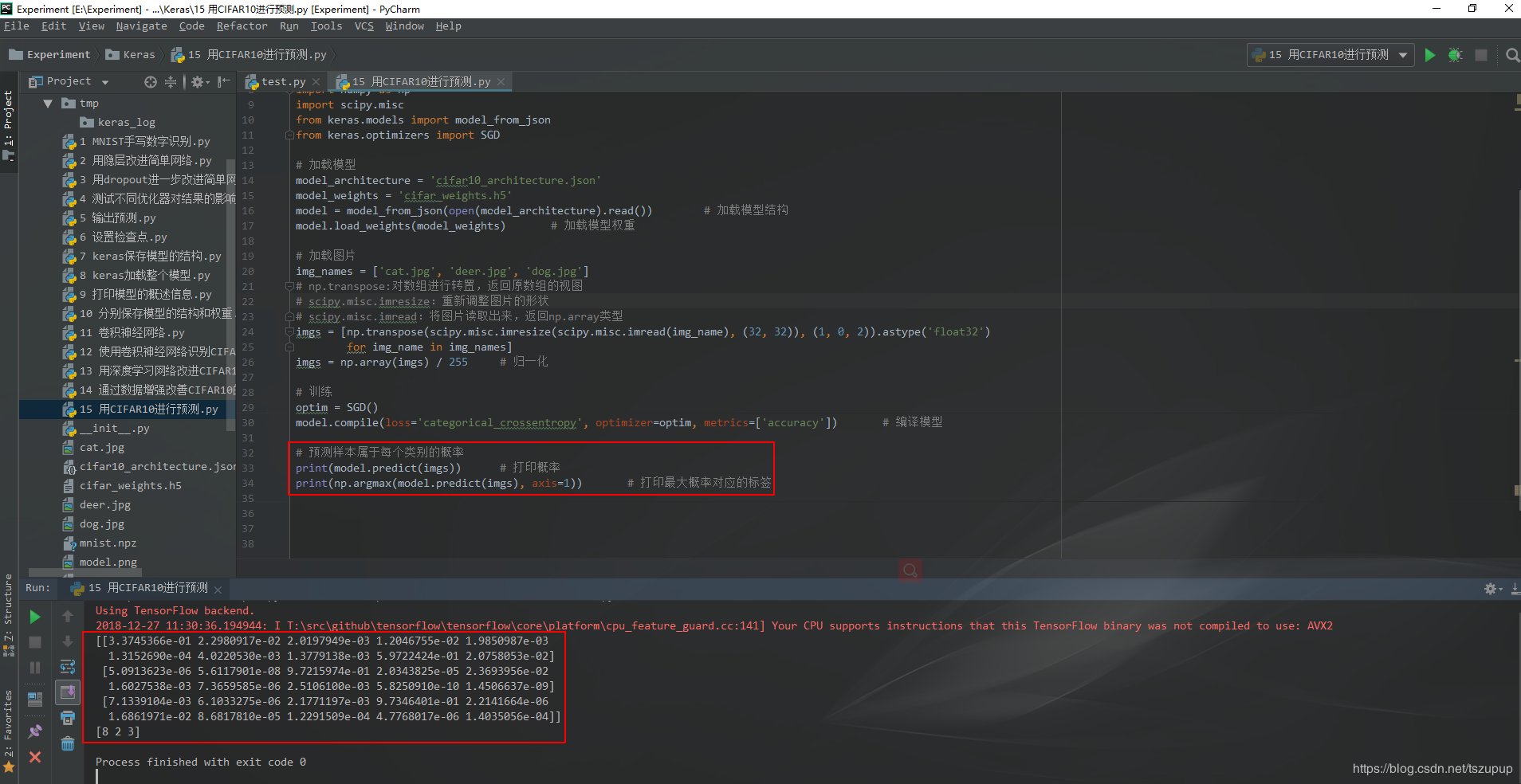
Keras中predict()方法和predict_classes()方法的区别
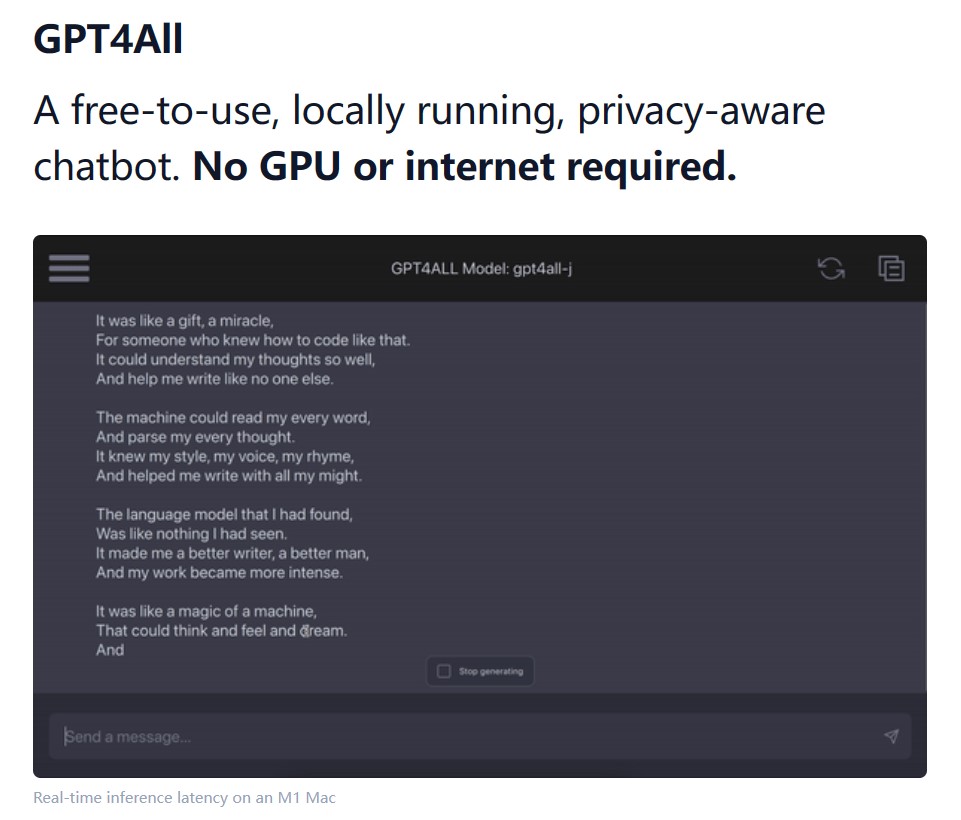
NomicAI推出了GPT4All这款软件,它是一款可以在本地运行各种开源大语言模型的软件。GPT4All将大型语言模型的强大能力带到普通用户的电脑上,无需联网,无需昂贵的硬件,只需几个简单的步骤,你就可以使用当前业界最强大的开源模型。
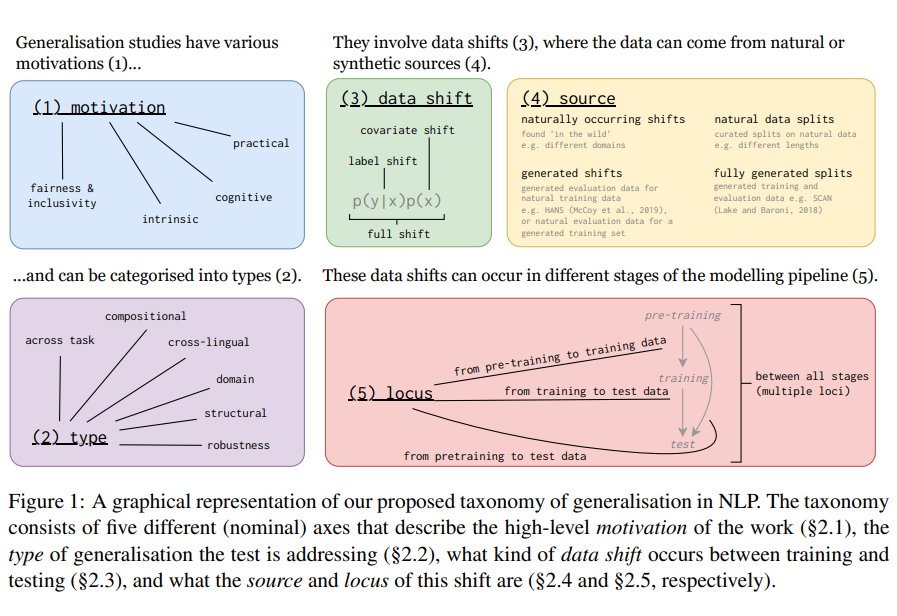
关于什么是好的泛化、存在哪些类型的泛化以及在不同的场景中哪些应该被优先考虑,人们对此了解甚少且意见不一。而MetaAI等机构的研究人员最近发布了一篇关于大模型泛化能力的综述,详细总结了大模型泛化能力的分类等。本篇论文详细总结一下大模型的泛化能力分类以及什么样的泛化是未来的中的重点等问题。
贝叶斯分析在概率模型中有非常重要的作用,这些年以来比较有影响力的模型如LDA、非参数贝叶斯模型等都是基于贝叶斯分析的。贝叶斯分析有一些非常基础性的知识,在这里我们描述了贝叶斯分析里面的一些基本表示和一些分析准则等内容。
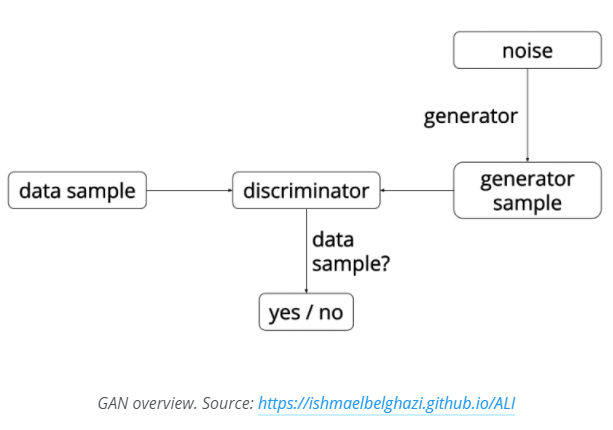
这篇博客是AYLIEN上的一篇关于生成对抗网络的简单介绍,包含非常简洁的代码示例。是入门非常好的材料。
这个系列的博客来自于 Bayesian Data Analysis, Third Edition. By. Andrew Gelman. etl. 的第五章的翻译。实际中,简单的非层次模型可能并不适合层次数据:在很少的参数情况下,它们并不能准确适配大规 模数据集,然而,过多的参数则可能导致过拟合的问题。相反,层次模型有足够的参数来拟合数据,同 时使用总体分布将参数的依赖结构化,从而避免过拟合问题。本节将讲述互换性并建立层次模型
目前,业界开源的大语言模型越来越多,性能也越来越强大。然而,这些开源模型大多数由国外的机构贡献,对于英文的支持没有任何问题。但是,对于中文的支持则是有好有坏。本文将基于主流的开源大模型进行分析,介绍当前支持中文的开源大模型,并对其使用方式和主要能力进行总结。

开源大语言模型的发展非常迅速,其强大的能力也吸引了很多人的尝试与体验。尽管预训练大语言模型的使用并不复杂,但是,因为其对GPU资源的消耗很大,导致很多人并不能很好地运行加载模型,也做了很多浪费时间的工作。其中一个比较的的问题就是很多人并不知道自己的显卡支持多大参数规模的模型运行。本文将针对这个问题做一个非常简单的介绍和估算。
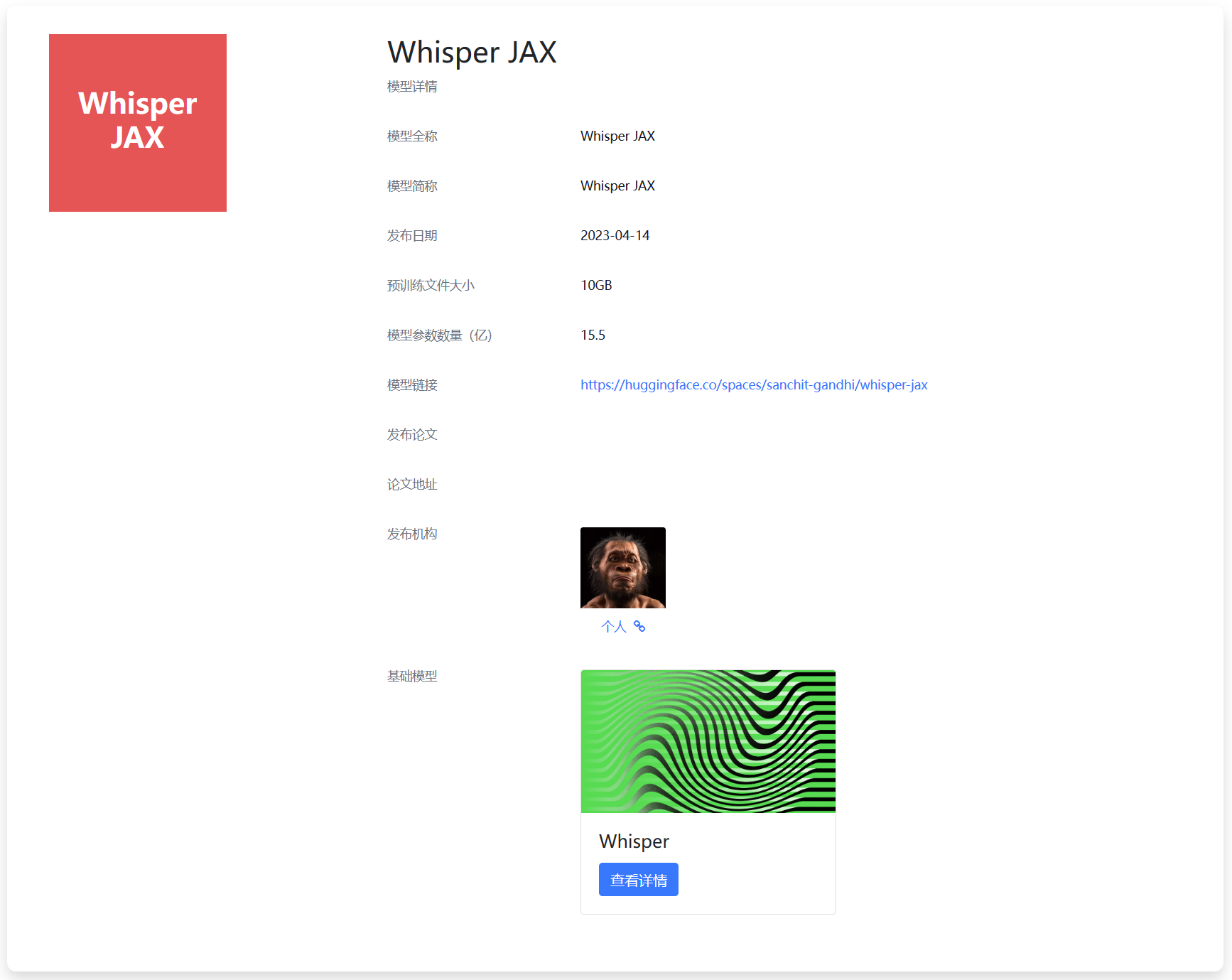
Whisper是OpenAI在2022年9月份开源的自动语音识别模型。官方宣传其英语的识别水平与人类接近。而2个月后,官方就发布了Whisper V2版本,是第一个版本继续训练2.5倍得到,且加了正则化技术。而今天,一位网友Sanchit Gandhi发布了Whisper JAX,这是对原有版本的优化结果,识别速度最高达到原始模型的70倍!
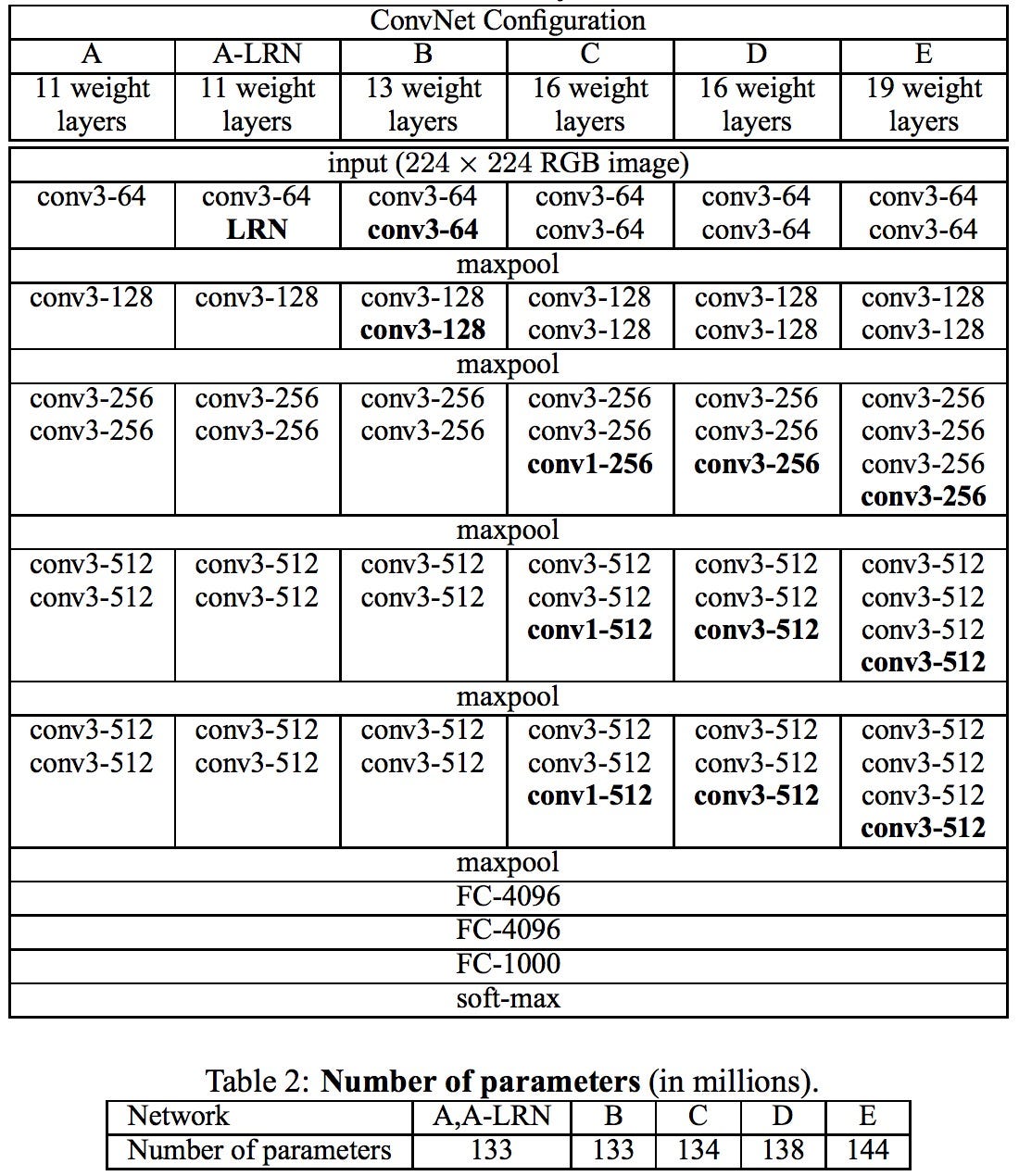
VGGNet(Visual Geometry Group)是2014年又一个经典的卷积神经网络。VGGNet最主要的目标是试图回答“如何设计网络结构”的问题。随着AlexNet提出,很多人开始利用卷积神经网络来解决图像识别的问题。一般的做法都是重复几层卷积网络,每个卷积网络之后接一些池化层,最后再加上几个全连接层。而VGGNet的提出,给这些结构设计带来了一些标准参考。
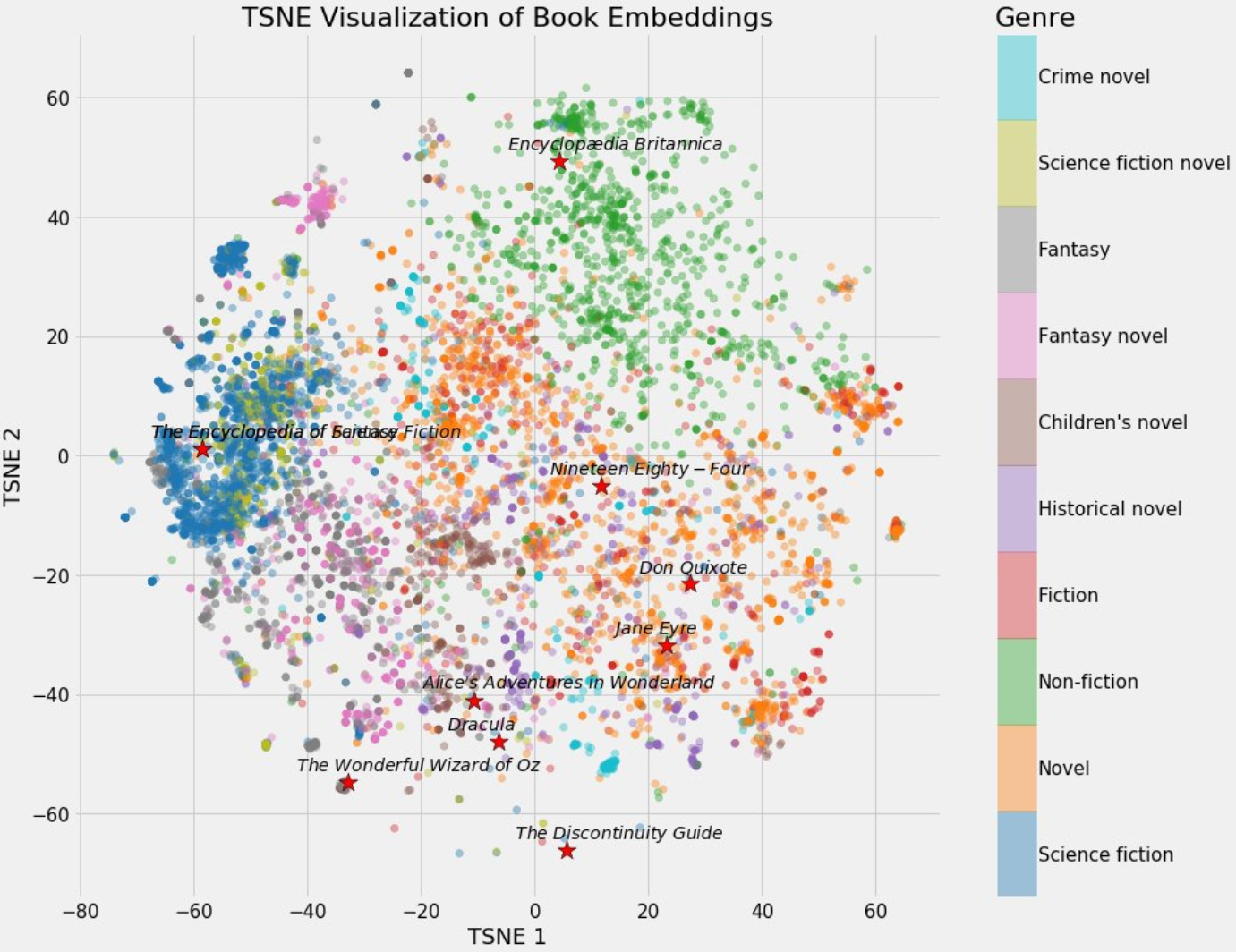
今天,推特上一位科技博主SullyOmarr分享了一个关于embedding的内容十分火爆。主要介绍为什么embedding对于在目前的AI大模型中很重要。这是一个十分不错的关于embedding知识的介绍。本文将根据SullyOmarr的内容也对embedding做一个简单的介绍,并解释为什么它在大语言模型中十分重要。
吉布斯抽样是贝叶斯推断中非常常用的方法。本文来自Cross Validated中一个人的回答。
Pandas中的DataFrame选择某些行和某些列是有很多中操作和选择的,不太容易记,这里整理一下。

这是OpenAI官方的cookebook最新更新的一篇技术博客,里面说明了为什么我们需要使用embeddings-based的搜索技术来完成问答任务。
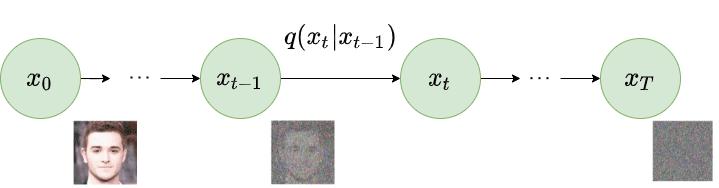
随着DALL·E2的发布,大家发现Text-to-Image居然可以取得如此好的效果。也让diffusion模型变得非常受欢迎。扩散模型虽然火热,但是背后的数学原理可能很多人也不太了解。这篇博客不仅介绍了扩散模型背后的数学原理,也讲述了如何训练扩散模型以及提高扩散模型训练效率的种种技巧,十分值得大家钻研。
今天,OpenAI公布了最新的一个基于AI的对话系统ChatGPT,是基于GPT3.5微调的结果,试用显示效果惊人!
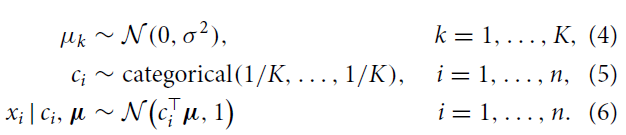
变分推断以及高斯混合模型应用

我们对层次贝叶斯推断的策略与一般的多参数问题一样,但由于在实际中层次模型的参数很多,所以比较困难。在实际中,我们很难画出联合后验概率分布的图形。但是,我们可以使用近似的基于仿真的方法。 在这个部分,我们提出一个联合了分析的和数值的方法从联合后验分布p(θ, φ|y)中获取仿真结果,以 小鼠肿瘤实验的beta-binormial模型为例,总体分布是p(θ|φ),与似然函数p(y|θ)是共轭的。对于很多非共轭层次模型,更高级的算法将在后面叙述。即使针对更复杂的问题,使用共轭分布来获取近似估计也是很有用的。
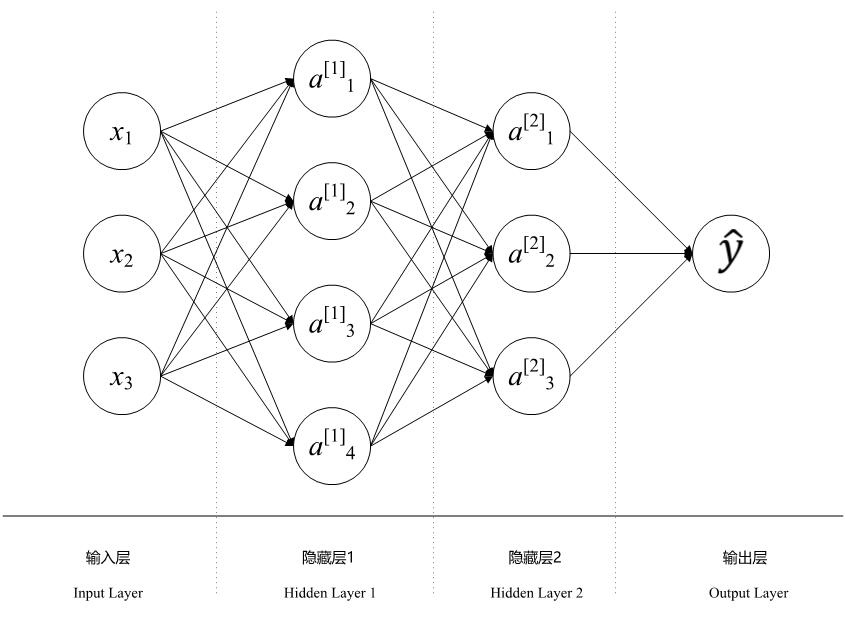
深度学习中的符号很多,但是大多数情况下,大家都使用同一套符号来表示。这篇博客主要以一个简单的神经网络为例,说明深度学习的标准符号以及相关的维度表示。主要来源是吴恩达的coursera课程。
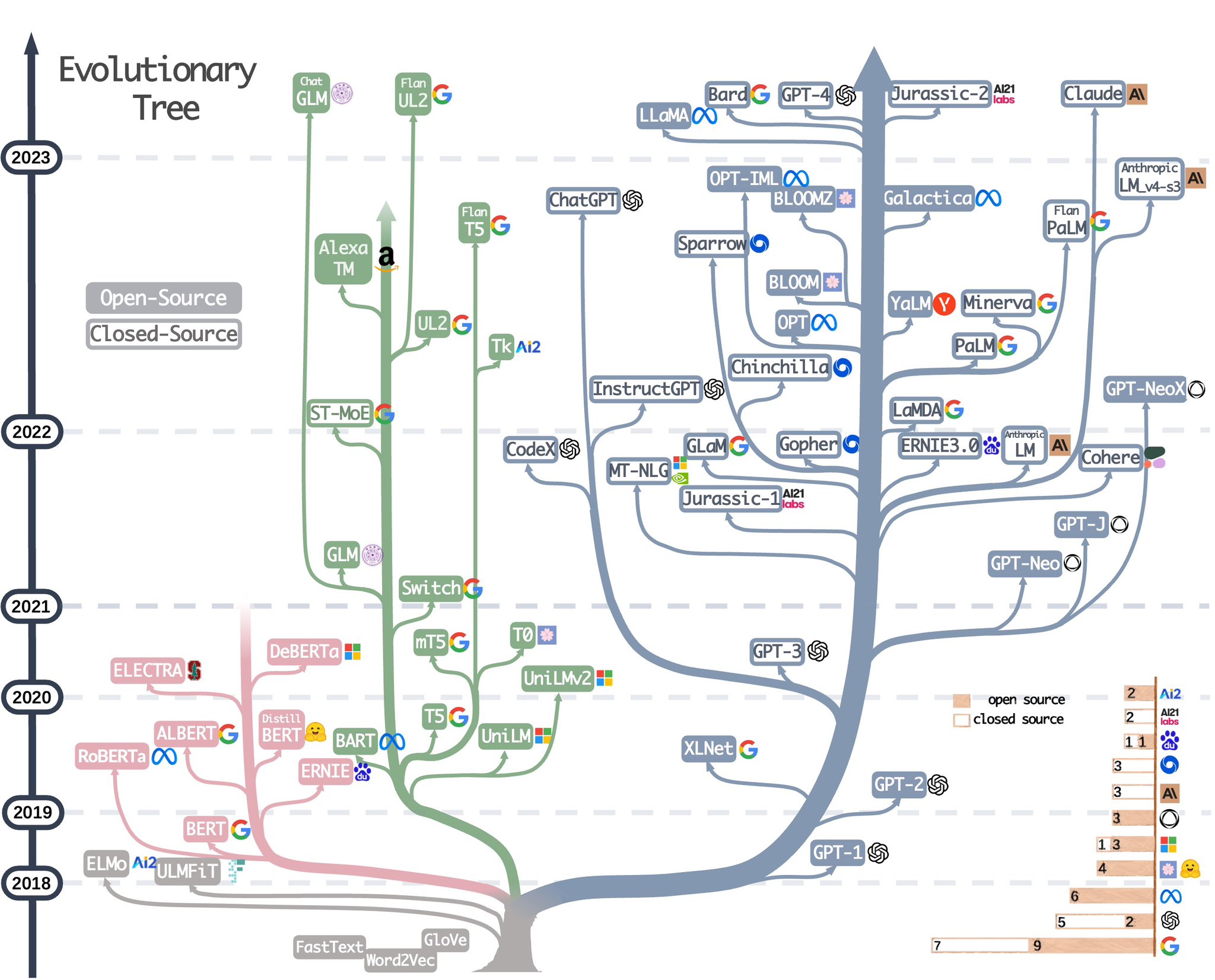
4月26日,亚马逊联合其它高校科研人员发表了一篇关于如何使用ChatGPT完成下游论文。里面使用了一个非常直观明了的大语言模型进化图总结了目前当前大语言模型的技术架构分类和开源现状,十分受欢迎。因此,4月30日,作者再次更新这幅图,增加了更多的大语言模型。
日常绘图时,会使用都origin,其是一款非常强大的制图工具
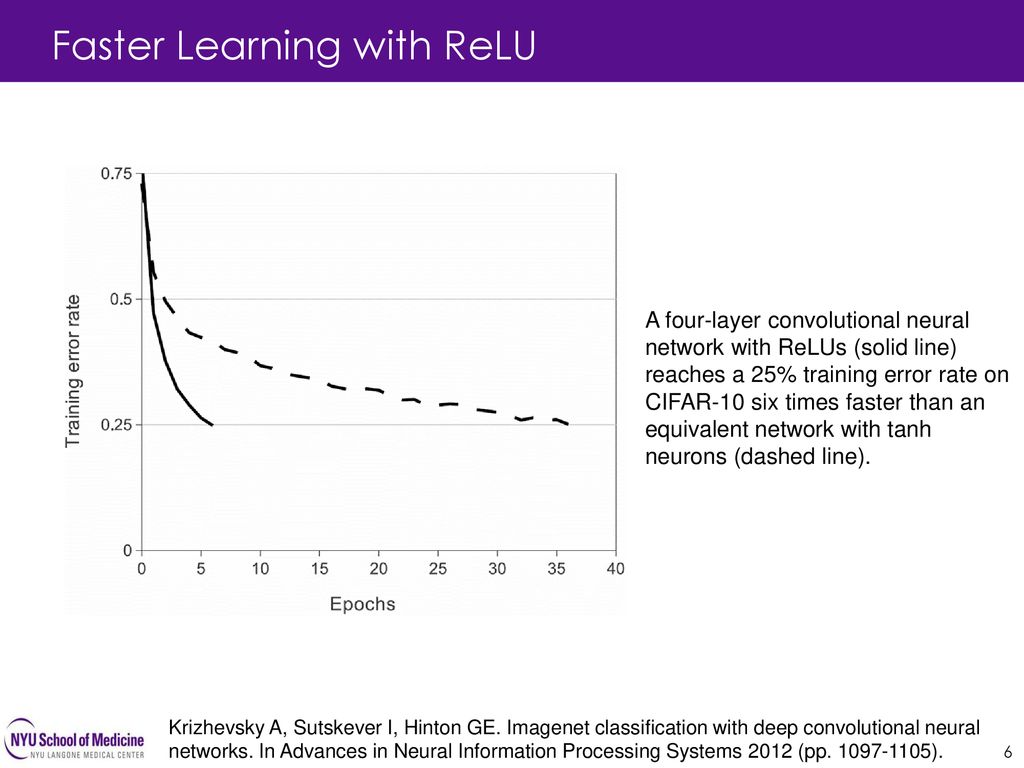
2012年发表的AlexNet可以算是开启本轮深度学习浪潮的开山之作了。由于AlexNet在ImageNet LSVRC-2012(Large Scale Visual Recognition Competition)赢得第一名,并且错误率只有15.3%(第二名是26.2%),引起了巨大的反响。相比较之前的深度学习网络结构,AlexNet主要的变化在于激活函数采用了Relu、使用Dropout代替正则降低过拟合等。本篇博客将根据其论文,详细讲述AlexNet的网络结构及其特点。