
重磅!Scikit-learn与Hugging Face强强联手了!
Hugging Face一直在努力支持深度学习,但是,这只是深度学习的一部分。传统统计机器学习领域里面最重要的工具Scikit-learn如今终于和深度学习的开源标杆工具Hugging Face联手。
聚焦人工智能、大模型与深度学习的精选内容,涵盖技术解析、行业洞察和实践经验,帮助你快速掌握值得关注的AI资讯。
Hugging Face一直在努力支持深度学习,但是,这只是深度学习的一部分。传统统计机器学习领域里面最重要的工具Scikit-learn如今终于和深度学习的开源标杆工具Hugging Face联手。
预测在全球决策中发挥着关键作用。例如,关于COVID-19扩散的预测为国家封锁提供了信息,而经济预测则影响了利率的制定。这些预测通常依赖于人类专家的仔细判断,他们必须考虑来自各种来源的数据。由于人工智能系统能够处理大量的数据,它们在这个领域有可能非常有用。 为此,ML Safety举办了一个关于AI预测的竞赛,比赛的目的是建立一个机器学习模型,做出准确和校准的预测。

2024年10月22日,Anthropic发布了两个新模型:升级版的Claude 3.5 Sonnet和全新的Claude 3.5 Haiku。升级版的Claude 3.5 Sonnet在保持原有价格和速度的基础上,实现了全面性能提升,尤其在编码领域取得了显著进步。新推出的Claude 3.5 Haiku则以与Claude 3 Haiku相同的成本和类似的速度,在多个评测中达到了与Claude 3 Opus相当的性能水平。

国产大语言模型的开源领域一直是很多企业或者科研机构都在卷的领域。最早,智谱AI开源ChatGLM-6B之后,国产大模型的开源就开始不断发展。早期大模型开源的参数规模一直在60-70亿参数规模,随着后续阿里千问系列的140亿参数的模型开源以及智源340亿参数模型开源之后,元象科技开源650亿参数规模的大语言模型XVERSE-65B,将国产开源大模型的参数规模提高到新的台阶。

2025年2月5日,Google官方宣布Gemini 2.0 Pro版本上线,Gemini系列是谷歌最新一代大模型的品牌名称。Google最早在2024年12月中旬发布了Gemini 2.0系列的第一个模型Gemini 2.0 Flash,当时试用的人都普遍反应这个模型速度又快,结果友好,让Google摆脱了此前大模型很落后的印象。今天,Gemini 2.0 Pro上线,其能力更强。

在当今的人工智能领域,大型语言模型(LLM)已成为备受瞩目的研究方向之一。它们能够理解和生成人类语言,为各种自然语言处理任务提供强大的能力。然而,这些模型的训练不仅仅是将数据输入神经网络,还包括一个复杂的管线,其中包括预训练、监督微调和对齐三个关键步骤。本文将详细介绍这三个步骤,特别关注强化学习与人类反馈(RLHF)的作用和重要性。
随着大型语言模型(LLMs)的不断发展,它们在训练和推理方面的计算需求已经呈指数级增长。这一趋势不仅带来了高昂的成本和能源消耗,还引入了模型部署和可伸缩性方面的障碍。为此,DeciLM开源了2个全新的DeciLM-6B和DeciLM-6B-Instruct大模型,参数比LLaMA2 7B略低,性能相当,但是推理速度却超过LLaMA2 7B的15倍。

GPTs是OpenAI推出的用户自定义的GPT功能,这里的GPTs可以认为是specific GPT。用户创建GPTs主要是通过OpenAI提供的GPT Builder完成。GPT Builder提供的最基本的能力就是基于对话的方式来帮助用户创建GPTs。那么,这个对话式的GPT背后的指令是什么?官方设置了什么样的Prompt来让GPT帮助普通用户建立GPTs呢?本文基于官方最新的博客介绍一下。

全球知名AI基准测试机构Artificial Analysis最新发布的2025年第一季度报告揭示了一个引人注目的重要趋势:在大语言模型领域,全球正在形成中美双极主导的新格局。这份权威报告通过严谨的技术指标评测体系,首次以数据量化的方式确认了中国AI技术水平的跨越式发展,特别是在顶尖大模型的研发领域,中国已经实质性地跻身全球第一梯队。本文根据报告的主要内容,为大家总结他们的一些观点和数据。
平时很多时候需要用到SQL,一些常见常用的SQL语句总结,后面可以拷贝使用
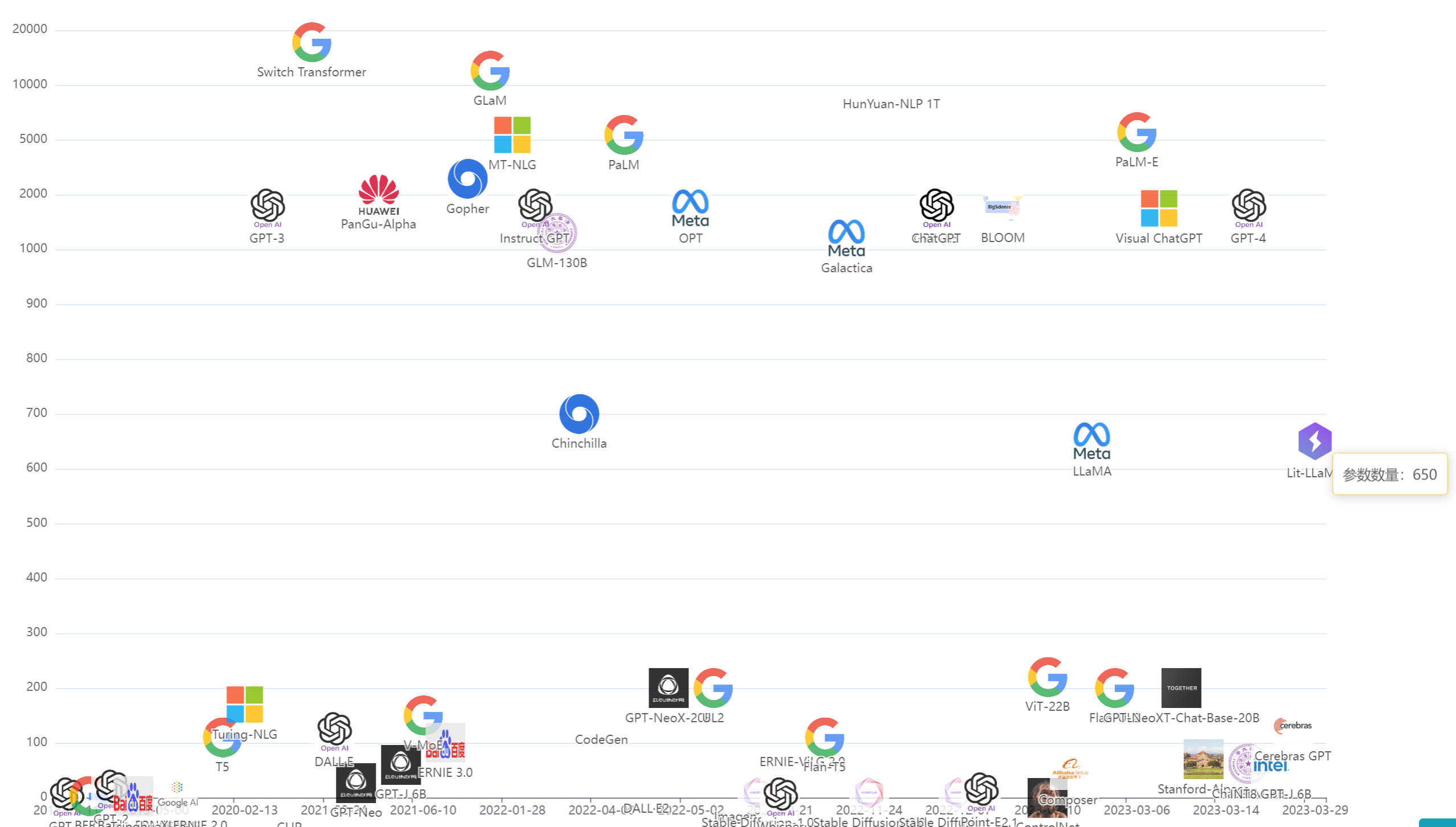
斯坦福大学发布的基础大模型追踪图谱Ecosystem Graphs,用图谱的方式给大家呈现了模型之间的联系,让人非常清楚明白追踪不同模型之间的关系。
彭博社今天发布了一份研究论文,详细介绍了BloombergGPT的开发,这是一个新的大规模生成式人工智能(AI)模型。这个大型语言模型(LLM)经过专门的金融数据训练,支持金融业内的多种自然语言处理(NLP)任务。

OpenAI发布的模型中最主要的是大语言模型GPT系列。而且GPT系列模型也在朝着多模态的方向发展。尽管OpenAI有自己的TTS和ASR大模型,但是此前从未正式宣布过。就在今天,OpenAI正式宣布了他们首个语音合成大模型VoiceEngine,该模型也将提供API访问。OpenAI官方的声明中说,现有的基于声音的认证系统应该被淘汰掉!因为已经不安全了!
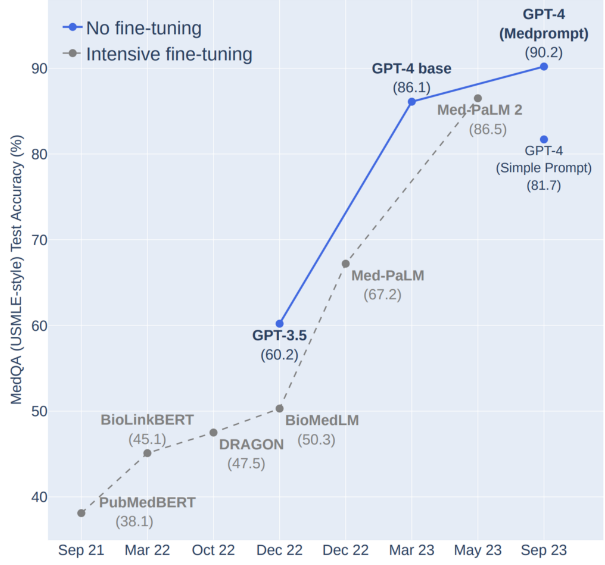
在GPT-4这种超大基座模型发布之后,一个非常活跃的方向是专有模型的发展。即一个普遍的观点认为,基座大模型虽然有很好的通用基础知识,但是对于专有的领域如医学、金融领域等,缺少专门的语料训练,因此可能表现并不那么好。如果我们使用专有数据训练一个领域大模型可能是一种非常好的思路,也是一种非常理想的商业策略。但是,微软最新的一个研究表明,通用基座大模型如果使用恰当的prompt,也许并不比专有模型差!同时,他们还提出了一个非常新颖的动态prompt生成策略,结合了领域数据,非常值得大家参考。
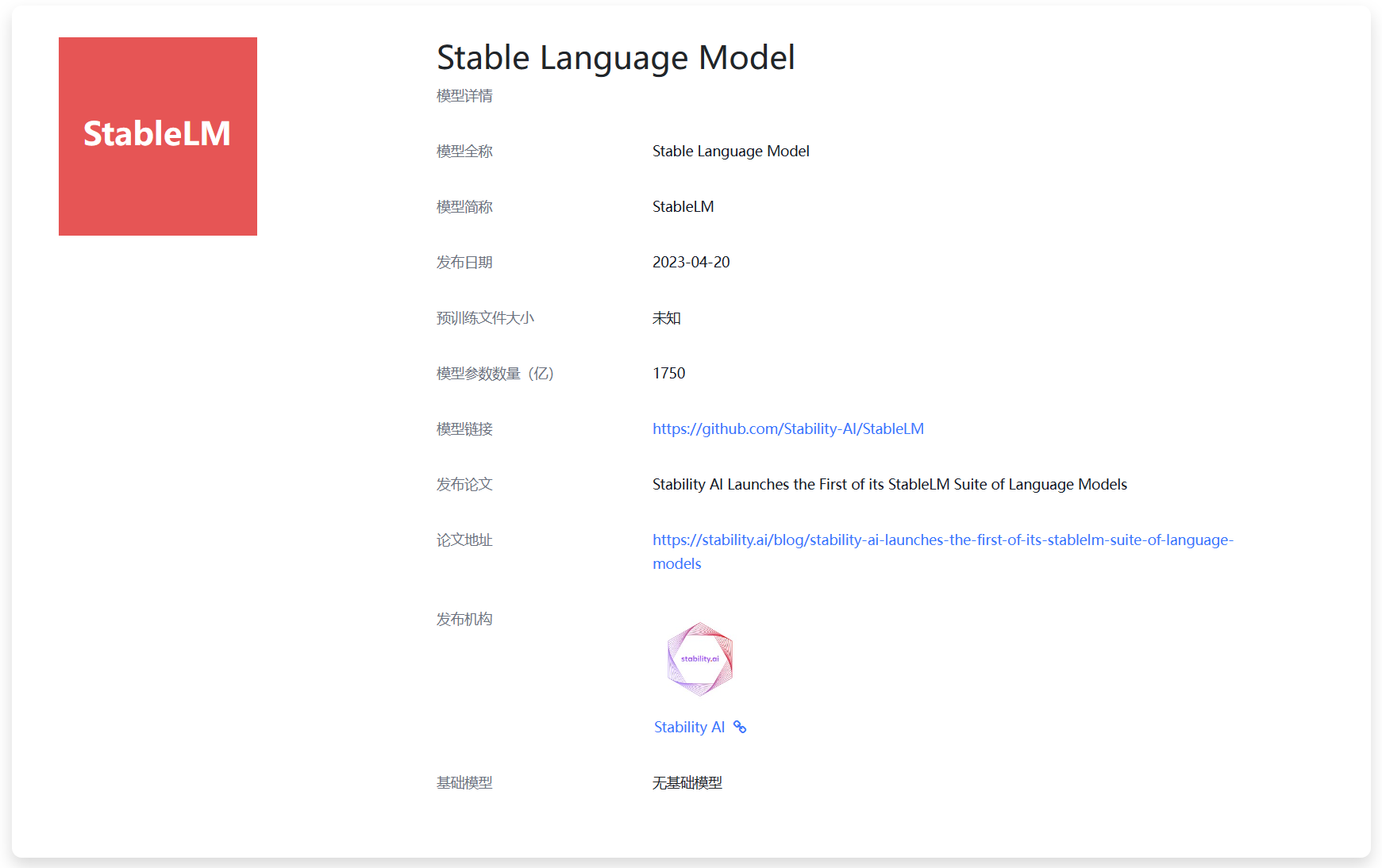
今天,Stability宣布开源StableLM计划,这是一个正在开发过程的大语言模型,但是它是开源可商用的模型。本文将对该模型做简单的介绍!
本表是Zeta Alpha收集的2022年AI领域被引次数最多的论文列表。
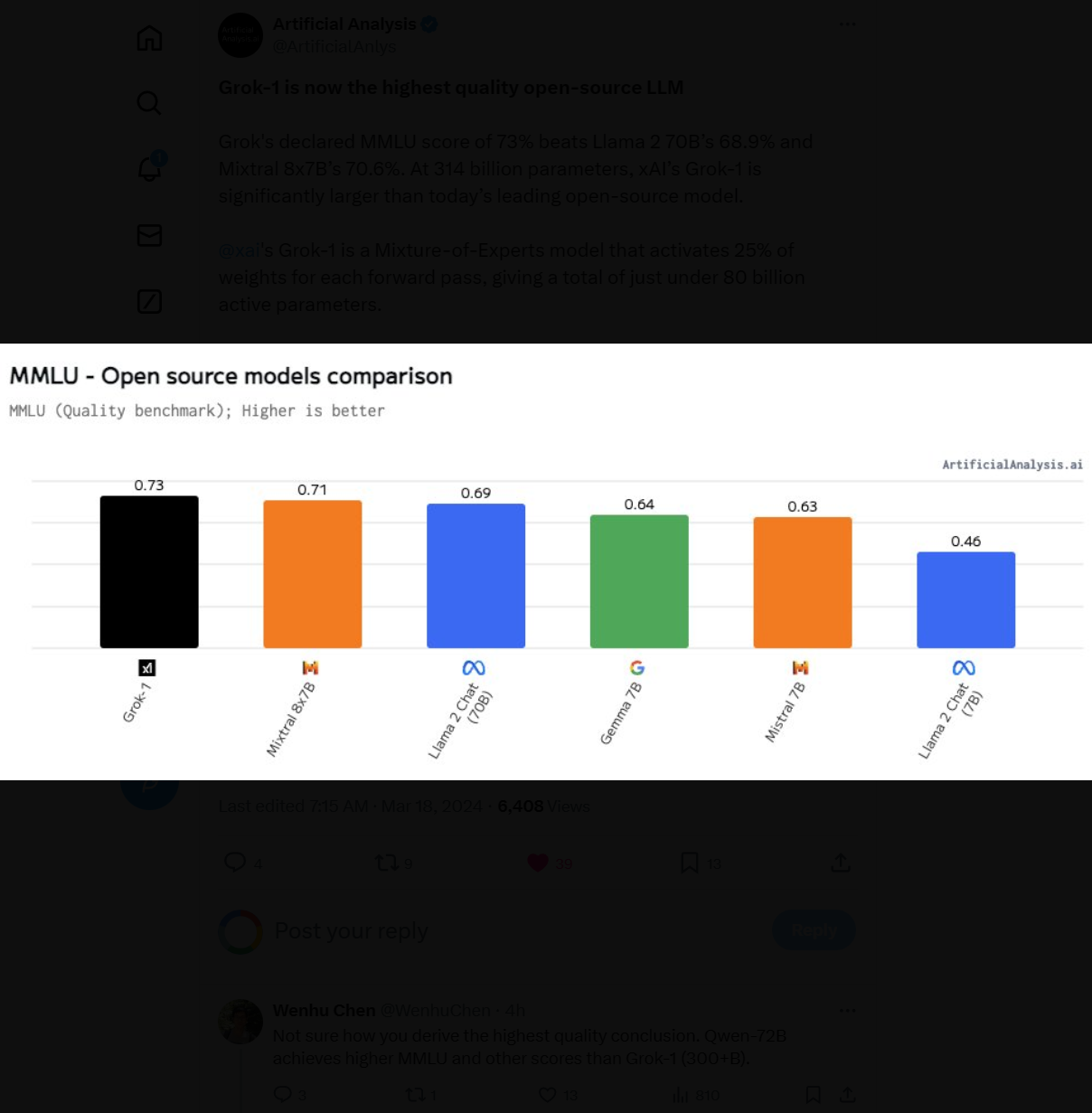
此前,马斯克在推特上宣布要开源旗下大模型公司开发的Grok-1大语言模型。一周后的现在,这个模型Grok-1正式宣布以Apache2.0开源协议开源,本文将针对Grok-1的技术部分进行介绍。

Gemini是谷歌发布的一系列大模型的名称,是谷歌前期大模型Bard产品的替代品。从Gemini 1.0发布开始,每一次发布都获得了不错的反响。今天,Google发布了最新一代的Gemini 2.0模型,首个产品是其参数规模较小的Gemini 2.0 Flash,它的推理速度是Gemini 1.5 Pro的2倍,但是各项评测结果上的表现却超过了Gemini 1.5 Pro。该模型完全免费提供给大家使用。
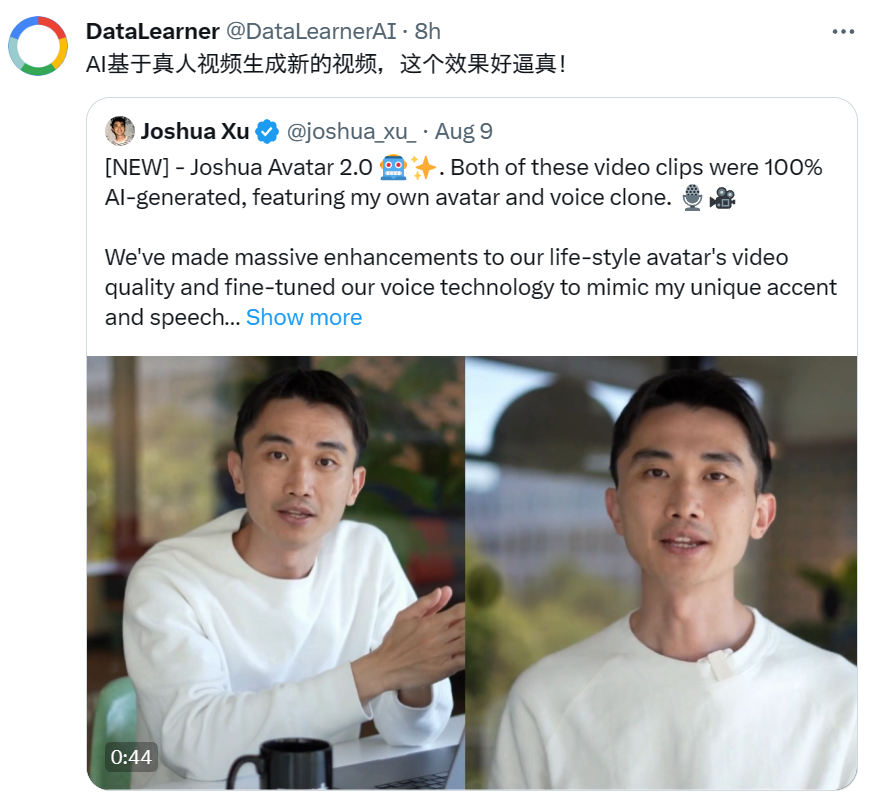
电影《流浪地球2》里面一个非常重要的情节就是数字生命计划。将人类的意识上传到计算机之后,可以通过AI技术让人类以数字化的形式在计算机中存活。而今天HeyGen官方宣布的即将推出的真人视频生成技术,可以根据真人的照片生成非常逼真的数字人视频,其动作、表情、声音等全部由AI技术生成,而几乎无法分辨是真人拍摄的视频还是AI生成的视频。

今天BusinessInsider发布了一个消息,说根据最新的消息,OpenAI目前还在训练GPT-5,但是有一些企业客户最近已经获得了该最新模型及其对ChatGPT工具的相关增强功能的演示。

仅仅使用来自人类数据集的机器学习,在短短9个小时内,日本研究人员让一个机器人学会了如何拿起和剥开香蕉。

大模型的进展非常快,但是如何在移动端部署和使用依然是一个非常大的挑战。今天,CerebrasAI联合Opentensor一起开源了一个30亿参数规模的模型BTLM-3B-8K,官方宣称其性能接近70亿参数规模的大模型,但是运行的资源却很低,最低量化版本只需要不到4GB显存即可。
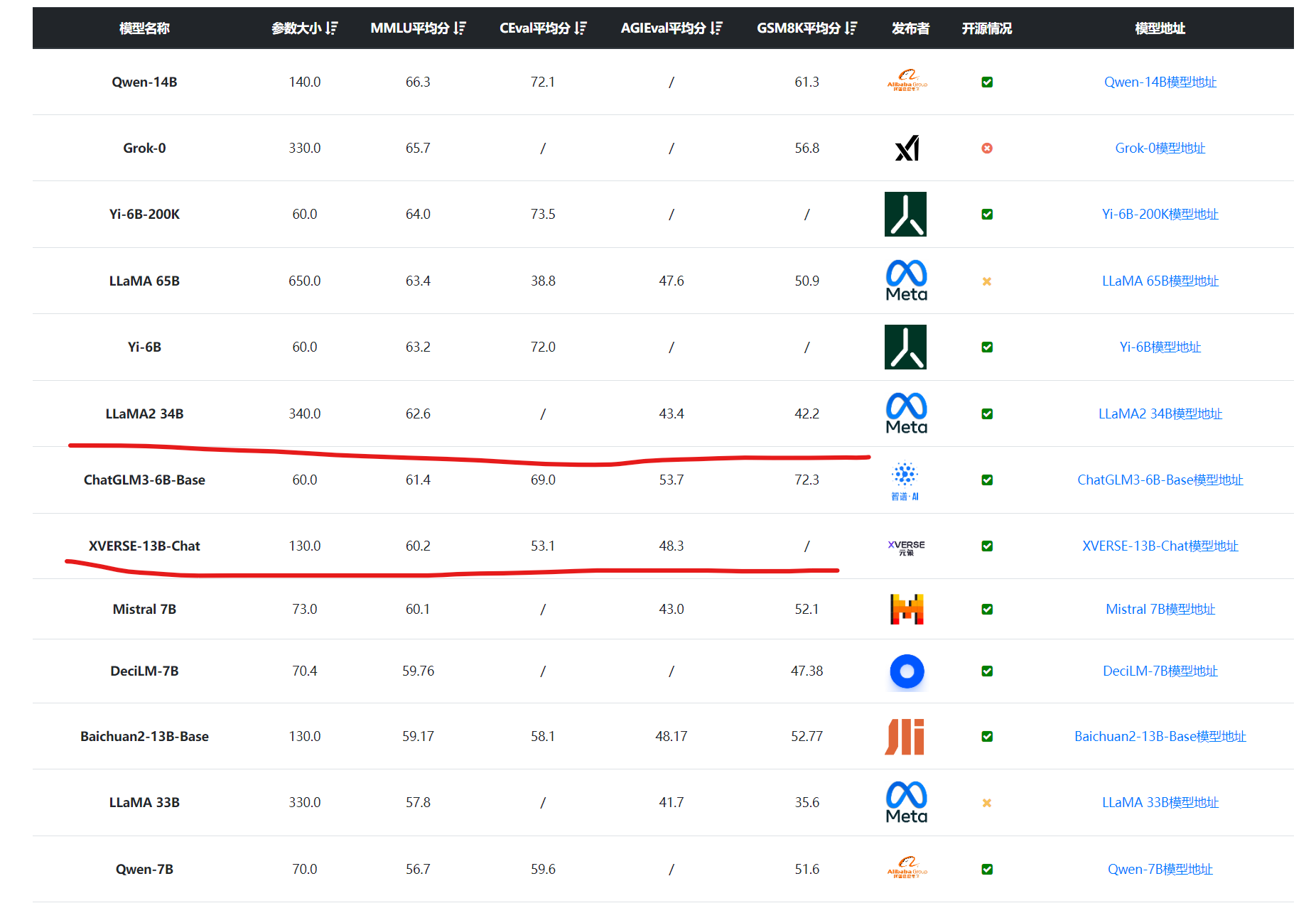
深圳的元象科技开源了一个最高上下文256K的大语言模型XVERSE-13B-256K,可以一次性处理25万字左右,是目前上下文长度最高的大模型,而且这个模型是以Apache2.0协议开源,完全免费商用授权。