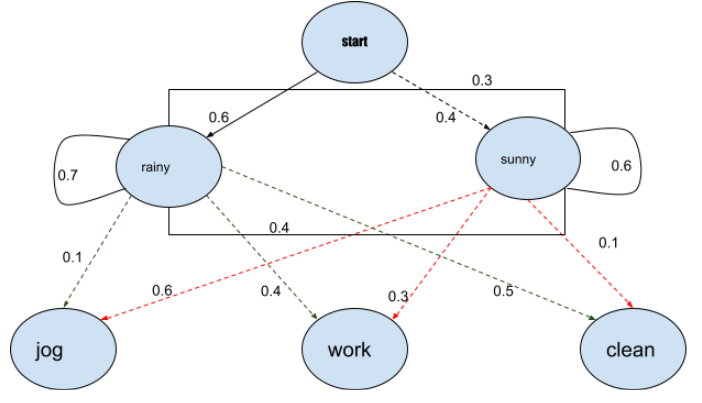
隐马尔科夫模型及其在NLP中的应用指南
隐马尔可夫模型(HMM)是一种统计模型,也用于机器学习。它可以用来描述取决于内部因素的可观察事件的演变,而这些因素是无法直接观察到的。这是一类概率图形模型,允许我们从一组观察到的变量中预测一串未知的变量。在这篇文章中,我们将详细讨论隐马尔可夫模型。我们将了解它可以使用的背景,我们也将讨论它的不同应用。我们还将讨论HMM在PoS标签中的使用和python的实现。文章中所涉及的主要内容如下。
聚焦人工智能、大模型与深度学习的精选内容,涵盖技术解析、行业洞察和实践经验,帮助你快速掌握值得关注的AI资讯。
隐马尔可夫模型(HMM)是一种统计模型,也用于机器学习。它可以用来描述取决于内部因素的可观察事件的演变,而这些因素是无法直接观察到的。这是一类概率图形模型,允许我们从一组观察到的变量中预测一串未知的变量。在这篇文章中,我们将详细讨论隐马尔可夫模型。我们将了解它可以使用的背景,我们也将讨论它的不同应用。我们还将讨论HMM在PoS标签中的使用和python的实现。文章中所涉及的主要内容如下。

基于java的网络爬虫框架
pandas的使用

今天,时隔一年后,OpenAI发布了第二代的DALL·E模型。相比较第一代的模型,DALL·E 2,以4倍的分辨率生成更真实和准确的图像。
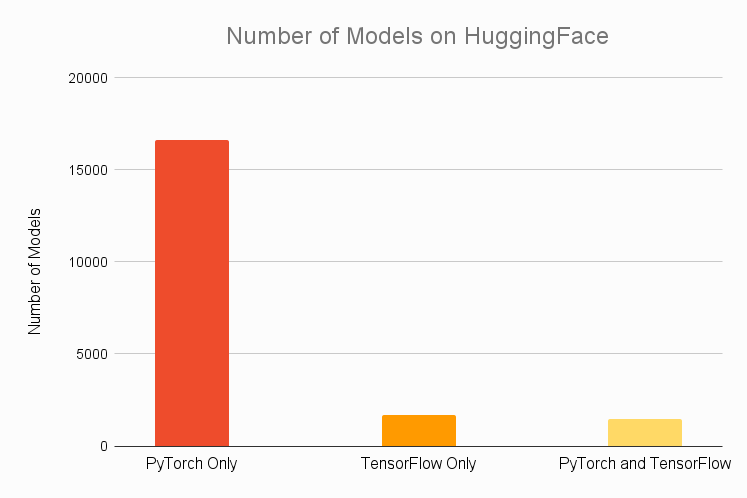
Tensorflow和PyTorch是深度学习最流行的两个框架,二者都有坚定的支持者。一般认为由于Google的支持,TensorFlow的社区支持比较好,在工业应用广泛。但是尽管有keras加持,但易用性方面依然被认为不如PyTorch。而后者最早由Facebook人工智能团队开发。由于其易用性,被认为在科学研究中有广泛使用。那么,最近几年二者发展如何,是否实际还如之前的观点一样,这里AssemblyAI的一个作者做了一些对比。
SQL语句优化
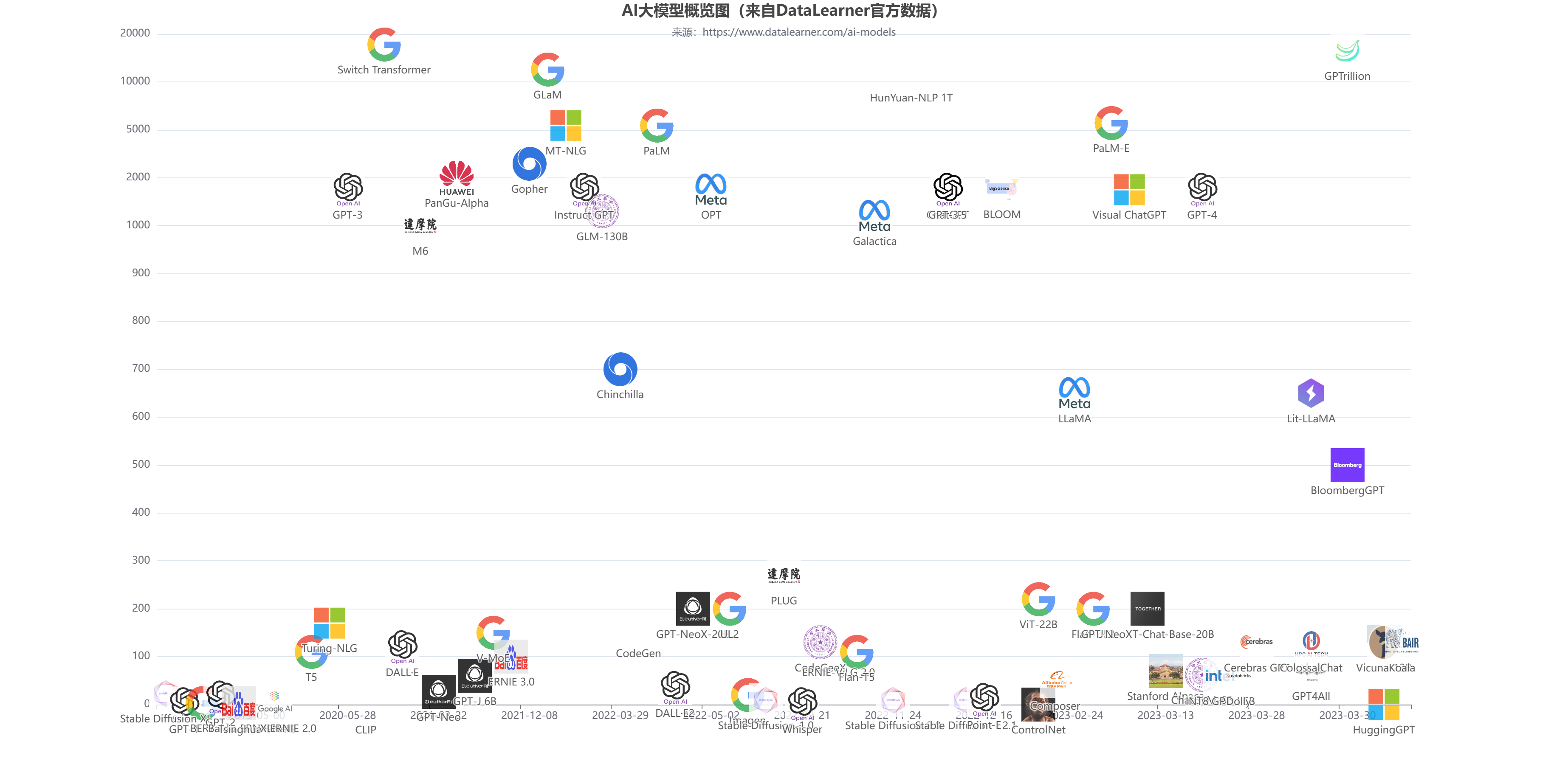
本文主要描述了阿里眼中国内各家企业的大模型水平以及一些硬件算力的判断,同时结合部分其它信息整理。里面涉及到当前国内各大企业模型水平判断(如百度文心一言、华为盘古等)以及算力储备信息。
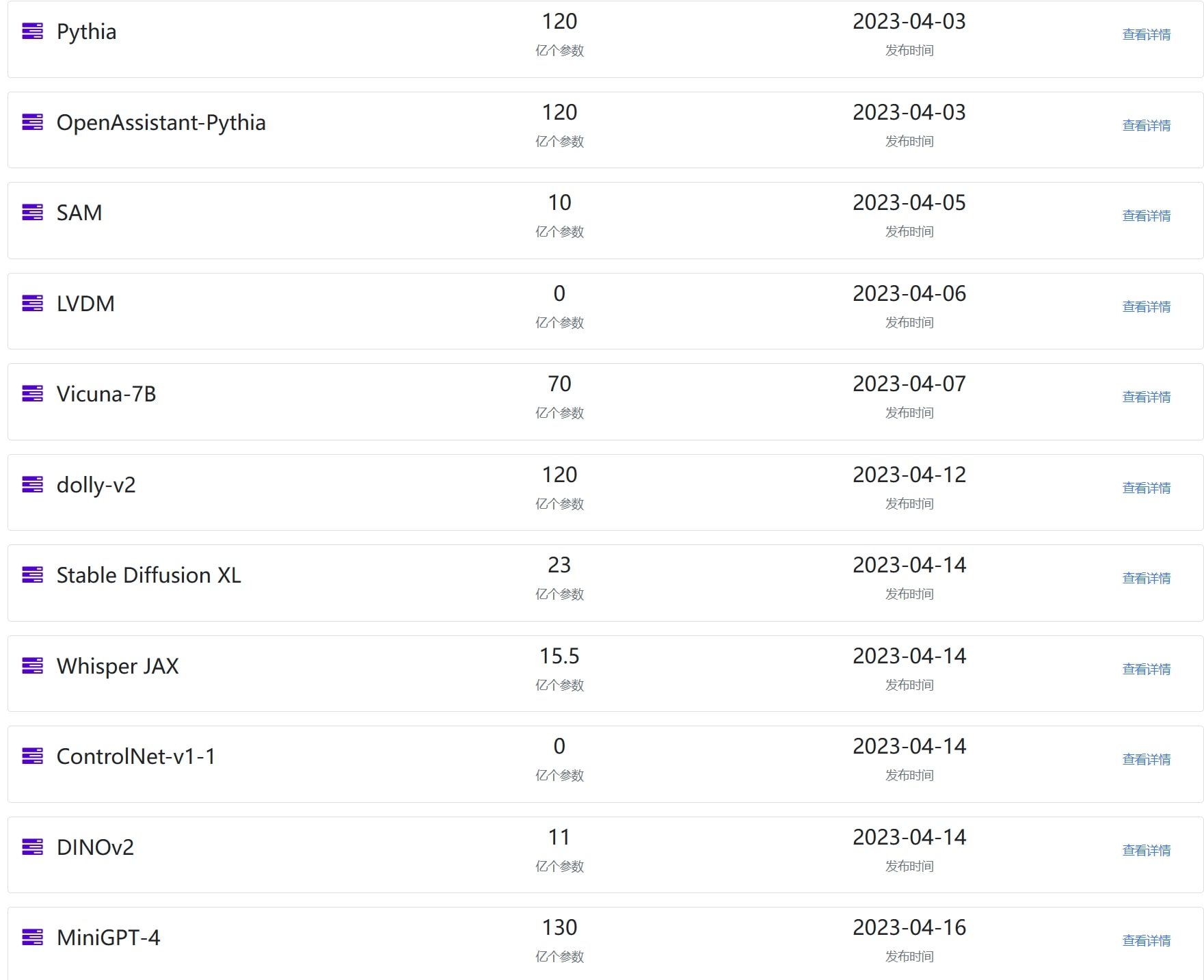
2022年11月底,OpenAI发布ChatGPT,2023年3月14日,GPT-4发布。这两个模型让全球感受到了AI的力量。而随着MetaAI开源著名的LLaMA,以及斯坦福大学提出Stanford Alpaca之后,业界开始有更多的AI模型发布。本文将对4月份发布的这些重要的模型做一个总结,并就其中部分重要的模型进行进一步介绍。
网络爬虫指按照一定的规则(模拟人工登录网页的方式),自动抓取网络上的程序。

为初学者、中级和有经验的开发者提供70多个python项目, 10000, 小木, PythonHub今天在推上给大家分享了一个非常棒的项目,就是这个为为初学者、中级和有经验的开发者提供70多个python项目。 亲自动手实践一些项目可以增加我们的实际的编程技巧。每一次都做一点将会得到很多。很多人都在GitHub、Reddit或者是Quera上搜索过哪些项目可以让Python初学者、中级者增加经验的Python项目。这次它来了。
网络爬虫之httpclient的使用
本文是Effective Java第三版笔记的第七个之消除过期的对象引用,Item 7: Eliminate obsolete object references
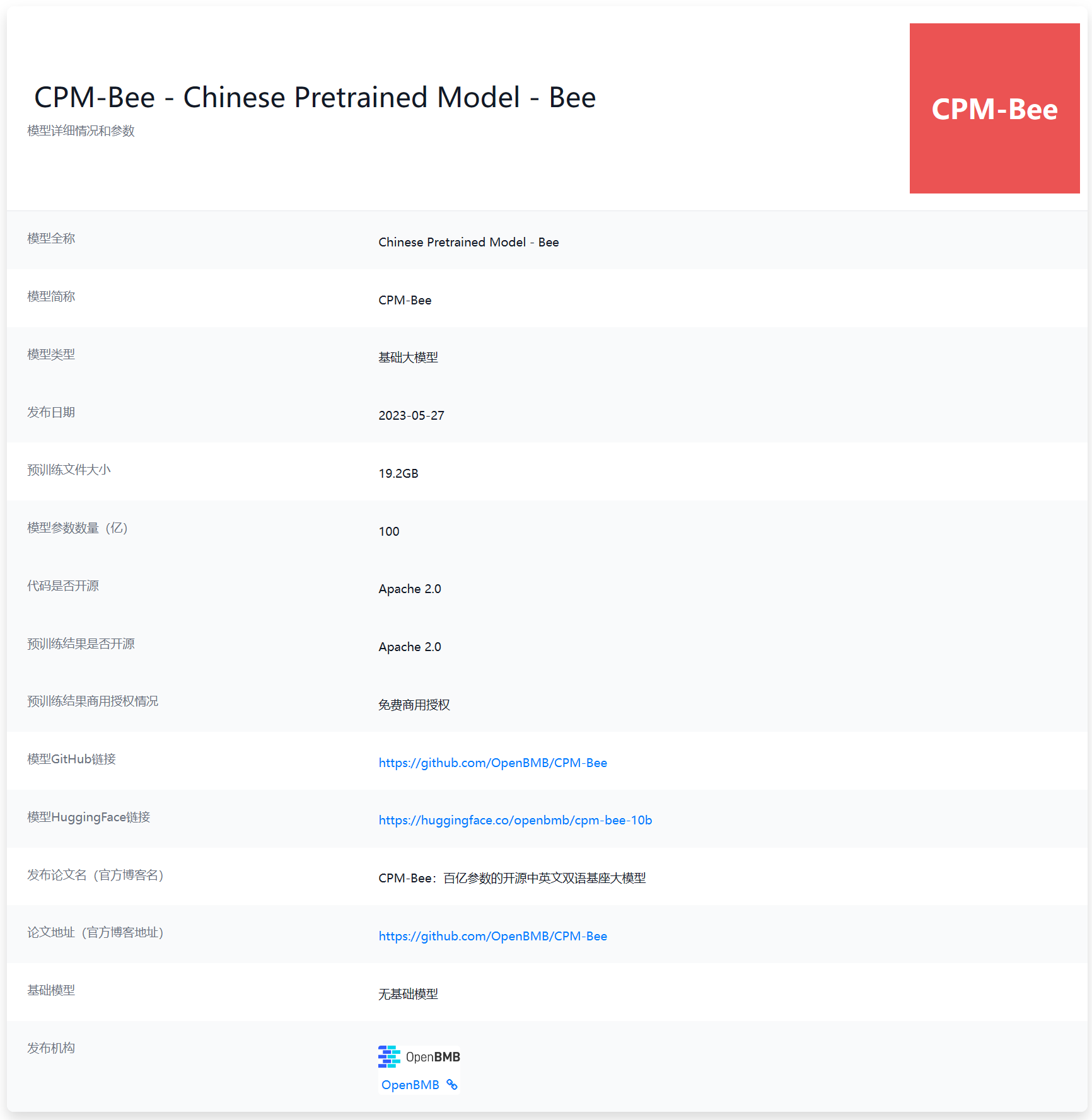
最近几个月,国产大语言模型进步十分迅速。不过,大多数企业发布的大模型均为商业产品,少数开源的LLM则有较高的商业授权费用或者商用限制。对于希望使用LLM能力的中小企业以及个人来说都不是很合适。本次给大家介绍的是目前国产开源领域里面一个十分优秀且具有潜力的大语言模型CPM-Bee 10B。该模型来自清华大学NLP实验室,参数规模100亿,最重要的是对个人和企业用户均提供免费商用授权,十分友好!
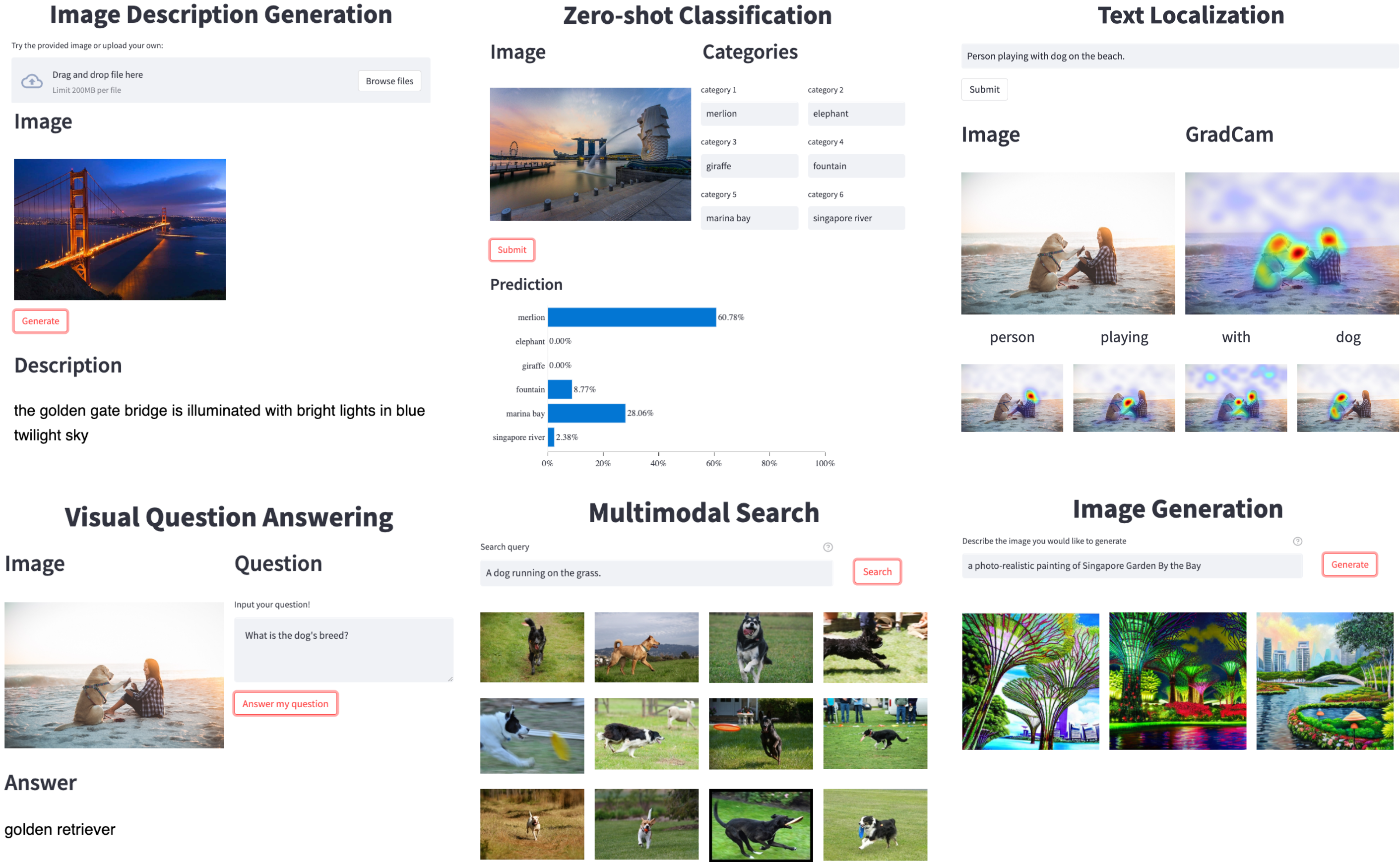
Salesforce的研究人员开发了LAVIS(LAnguage-VISION的缩写),这是一个开源的库,用于在丰富的常见任务和数据集系列上训练和评估最先进的语言-视觉模型,并用于在定制的语言-视觉数据上进行现成的推理。
正则表达式非常有用,非常强大,但也并不容易写,在这里我们总结一些常用的正则表达式写法

大模型的微调是当前很多人都在做的事情。微调可以让大语言模型适应特定领域的任务,识别特定的指令等。但是大模型的微调需要的显存较高,而且比较难以估计。与推理不同,微调过程微调方法的选择以及输入序列的长度、批次大小都会影响微调显存的需求。本文根据LLaMA Factory的数据总结一下大模型微调的显存要求。

现代软件企业中,SaaS服务提供商是最值得注意的企业。因为SaaS行业规模大利润高,也是最有前景的一类企业。但是,国内市场因为很多因素导致SaaS的规模和空间都比较低。本文梳理一下全球最大的10个SaaS服务提供商,供大家参考。
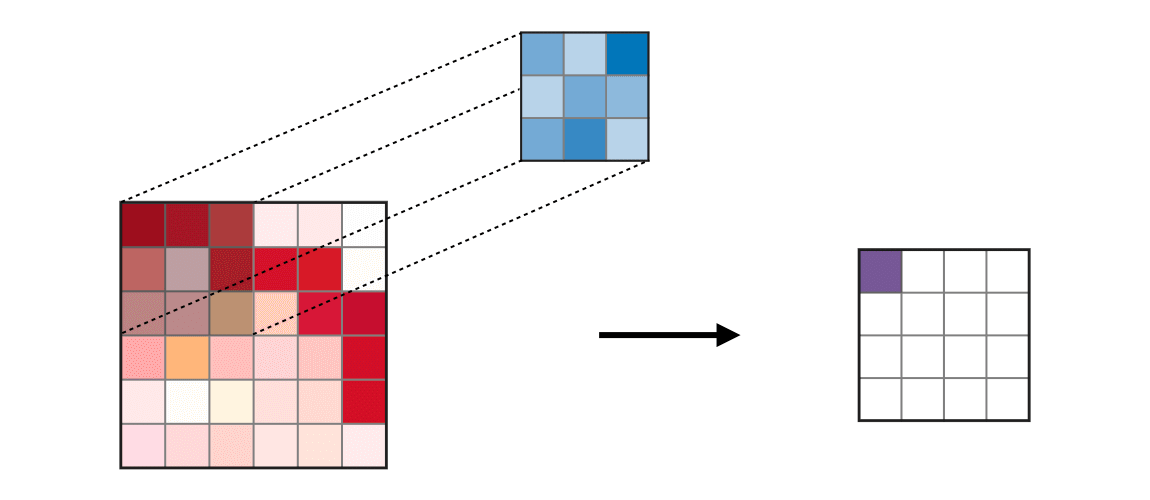
CS 230 ― Deep Learning是斯坦福大学视觉实验室(Stanford Vision Lab)的Shervine Amidi老师开设的深度学习课程,他在课程网站上挂了一个关于深度学习示意图的网站,这里面包含了各种深度学习相关概念的示意图和动图,十分简单明了。
腾讯AI Lab去年四月成立,今年是首次参加ICML,共计四篇文章被录取,位居国内企业前列。此次团队由机器学习和大数据领域的专家、腾讯AI Lab主任张潼博士带领到场交流学习,张潼博士还担任了本届ICML领域主席。在本次130人的主席团队中,华人不超过10位,内地仅有腾讯AI Lab、清华大学和微软研究院三家机构。