
重磅!OpenAI发布GPT-4o mini,这是GPT-3.5的替代升级版,价格下降60%,但是更快更强!编程能力甚至超过GPT-4!
就在刚才,OpenAI官方宣布即将推出GPT-4o mini模型,这是一个成本很低的AI大模型,是GPT-3.5的替代版本。OpenAI官方说,该模型最大的特点是很便宜,但是能力更强,因此可以极大提高AI在不同领域的应用。
聚焦人工智能、大模型与深度学习的精选内容,涵盖技术解析、行业洞察和实践经验,帮助你快速掌握值得关注的AI资讯。
就在刚才,OpenAI官方宣布即将推出GPT-4o mini模型,这是一个成本很低的AI大模型,是GPT-3.5的替代版本。OpenAI官方说,该模型最大的特点是很便宜,但是能力更强,因此可以极大提高AI在不同领域的应用。

近几年语言模型的发展速度很快,各种大语言预训练模型的推出让算法在各种NLP的任务中都取得了前所未有的成绩。其中2017年谷歌发布的Attention is All You Need论文将transformer架构推向了世界,这也是现在最流行的语言模型结构。威斯康星大学麦迪逊分校的统计学教授Sebastian Raschka总结了6中Language Transformer的使用方法。值得一看。

微软在去年4月份的时候推出了一个构建虚拟助手的指南:《构建人工智能应用的开发者指南·第二版》。这份报告帮助我们借助微软的工具构建一个虚拟助手,本文将简要描述一下这份报告,文末有相关资源下载。

这是一篇来自Sayak Paul的预测,这个哥们长期混迹于各个开源社区,积极参与各大公司的开发者大会。目前在一家初创企业工作,简历非常丰富,非常积极在社区推广自己。但是不管怎么说,他在计算机视觉领域也是一直在一线工作。他对未来计算机视觉的发展方向有五个预测,虽然不一定准确,但是我们可以借助这个进行思考。
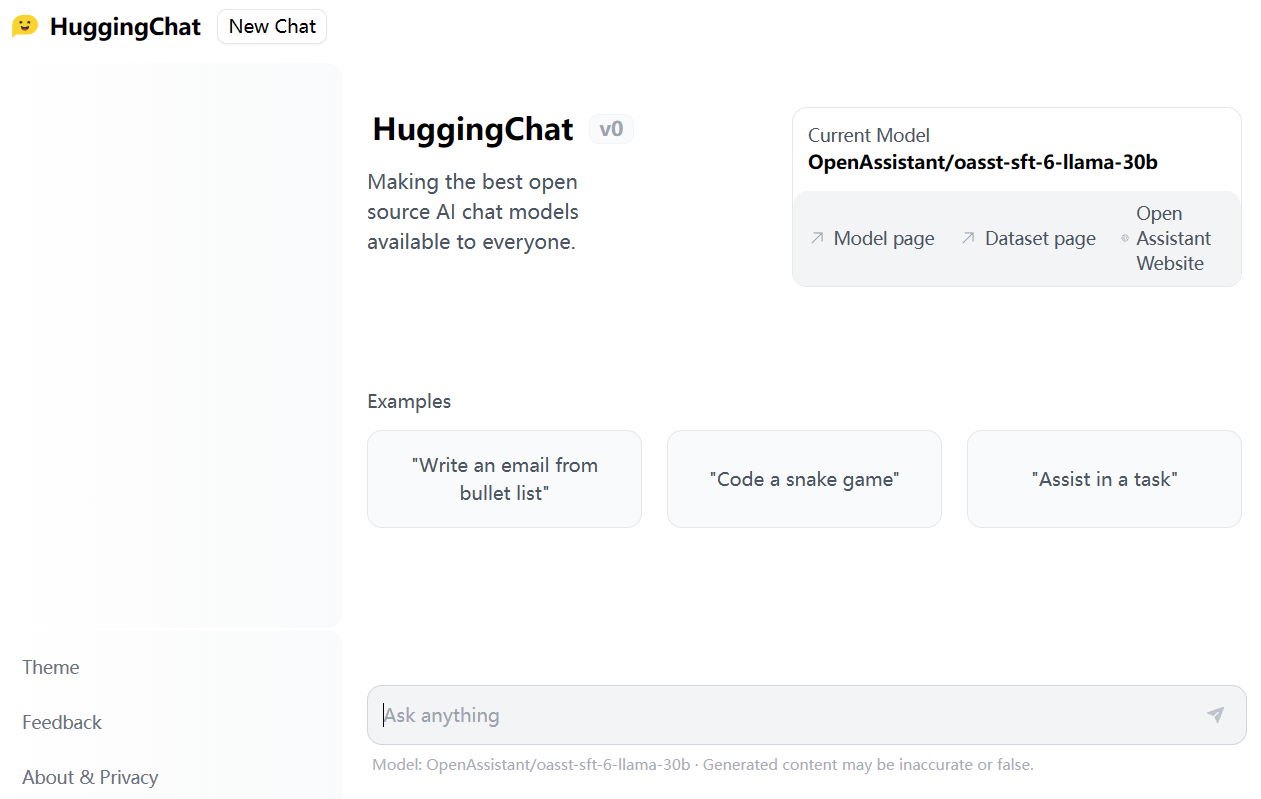
HuggingFace是近几年最火热的AI社区,在短短几年时间里已经称为AI模型的GitHub。目前,HuggingFace上已经托管了18万多的模型、3万多的数据集以及4万多的模型demo(spaces)。今天,HuggingFace发布了HuggingChat,声称要做最好的开源AI Chat项目,并且对所有人开放。
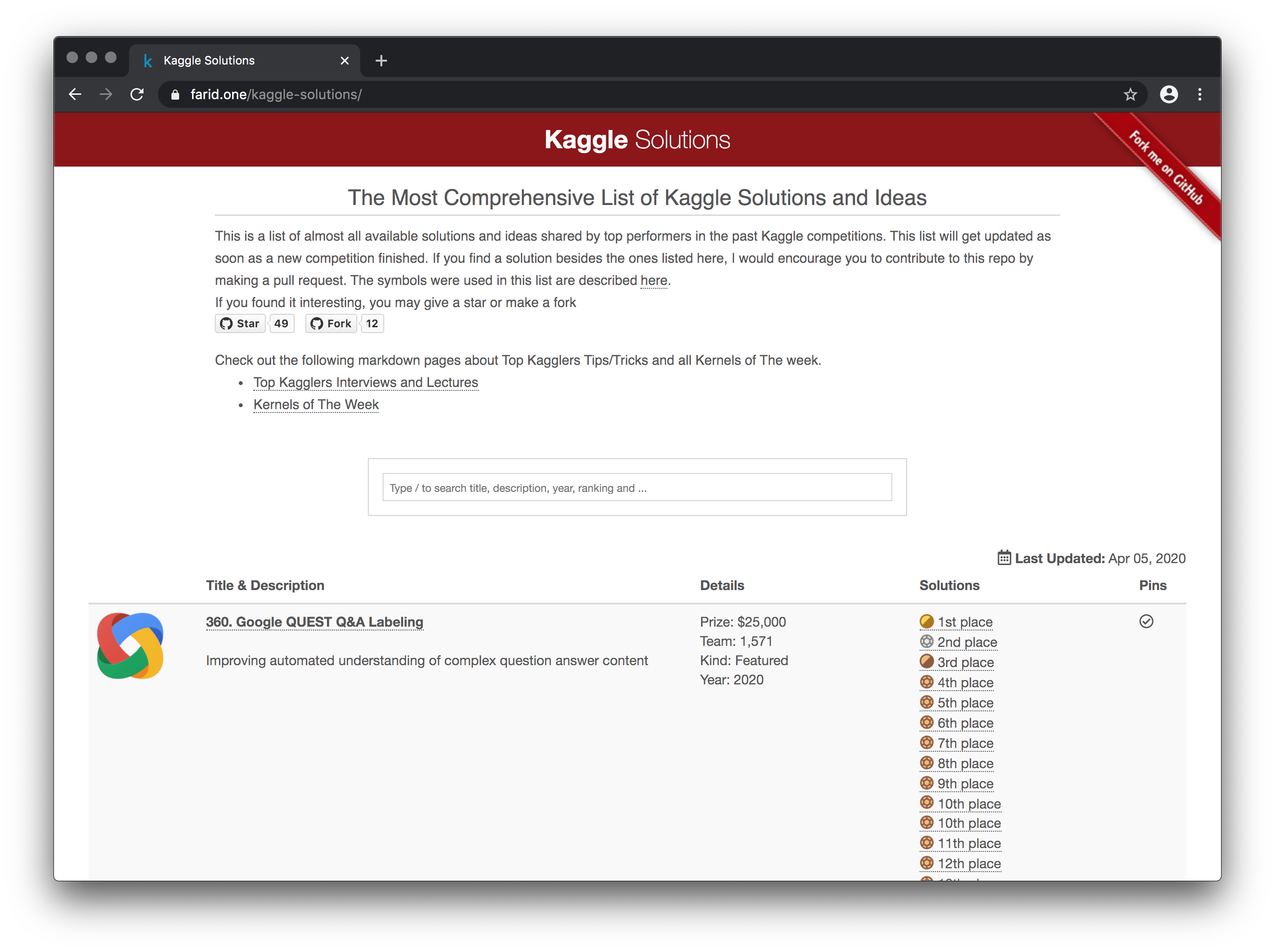
这是一位热心网友(faridrashidi)收集的Kaggle竞赛的解决方案。这是在过去的Kaggle竞赛中表现最好的选手所分享的几乎所有可用的解决方案和想法的列表。一旦有新的比赛结束,这个列表就会更新。

最近一段时间Text-to-Image模型十分火热。OpenAI的DALL·E2模型的效果十分惊艳。不过,由于Open AI现在的不Open策略,大家还无法使用这个模型,业界只开放了一个小版本的DALL·E mini。不过,前段时间,Stability AI发布的Stable Diffusion其效果明显好于现有模型,且免费开放使用,让大家都开心了一把。不过原有模型是Torch实现的,而现在,基于Tensorflow/Keras实现的Stable Diffusion已经开源。

最近两天,关于AI技术和产品的进展依然很快。所以,我们本次直接给出一个AI技术进展快报。与大家分享一下最新的AI技术情况。
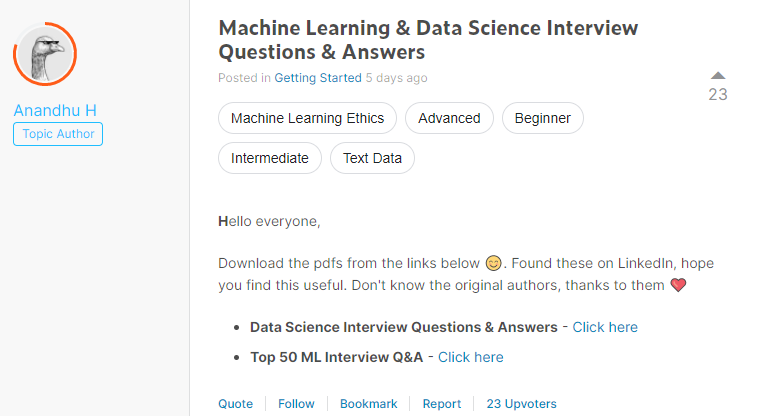
这是来自Kaggle上网友的分享,是关于数据科学和机器学习的面试题集锦。都是英文的题目,不过应该不影响,大家也可以根据题目自己去寻找答案,我看了一下,并不是所有的答案都非常准确,但问题的确可以帮助我们思考总结。
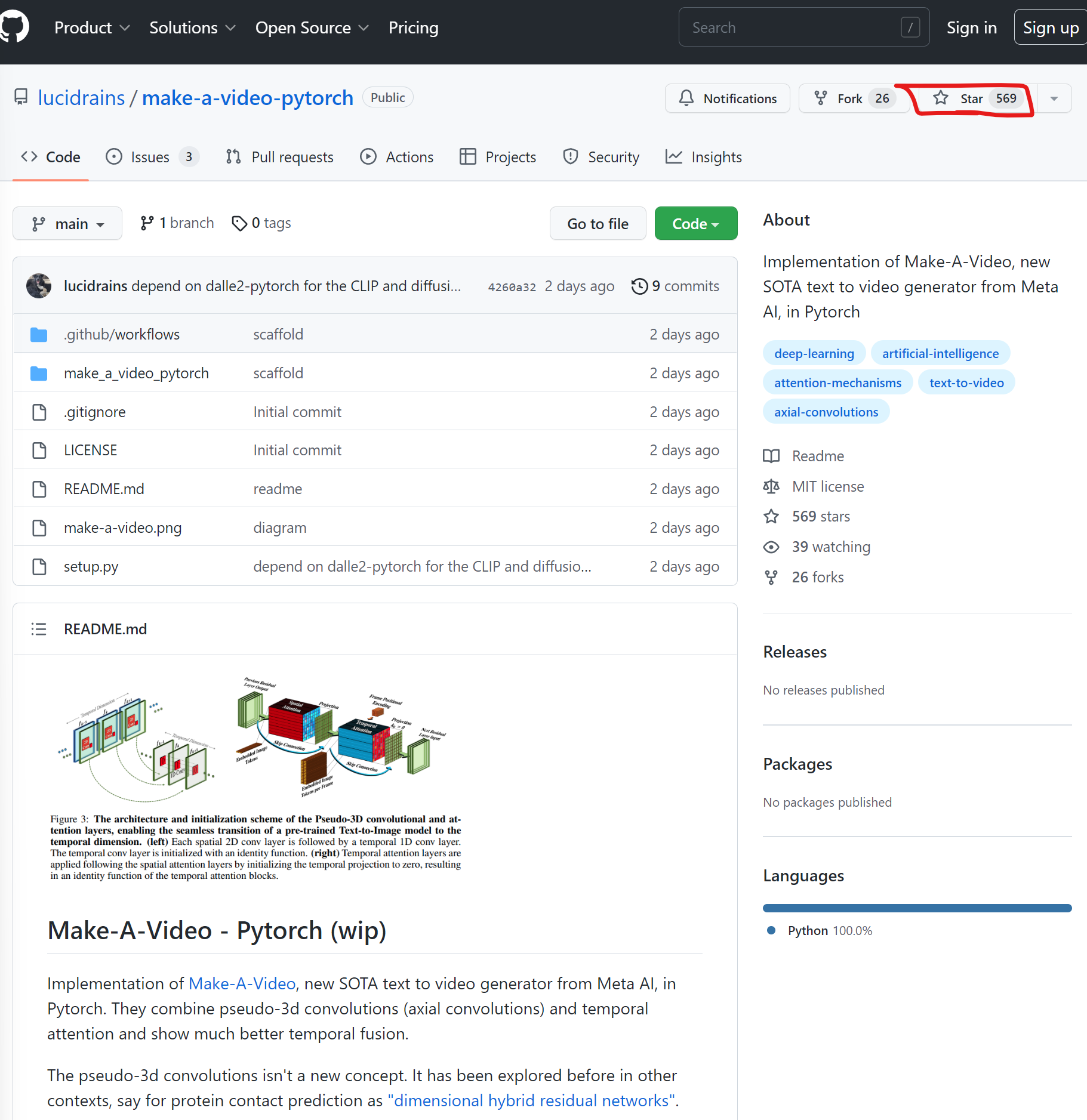
MetaAI在2天前刚发布了一个最新的Text-to-Video模型,让生成模型从逼真的图片生成往前推进到视频生成。当然,官方还是希望将其当作一种SaaS服务提供。但是,才2天,业界基于论文的开源PyTorch实现就已经准备公开,且获得了569个Star!卷到家了!

Stable Diffusion是一种功能强大的开源文本到图像(Text-to-Image)生成模型。虽然目前有多个开源项目可以实现基于文本提示(prompt)创建图像,但Stable Diffusion性能极其强大,其结果甚至可以媲美DALL·E2。而现在KerasCV提供了这个模型的官方实现!

重磅新论文!北京人工智能研究员与清华大学、腾讯、华为、字节等公司一起发表了一篇关于大规模预训练模型路线图的论文。

PerplexityAI是通过搜索引擎检索互联网的内容,然后使用大模型总结答案。产品形态有点像Bing的Bing Chat。圣诞节前夕,PerplexityAI提供了一个优惠代码,可以免费使用他们的2个月的Pro版本订阅服务。PerplexityAI的Pro版本提供GPT-4、Claude-2.1等大模型服务,支持生成图片和基于很长的PDF问答,这2个月的服务十分划算!
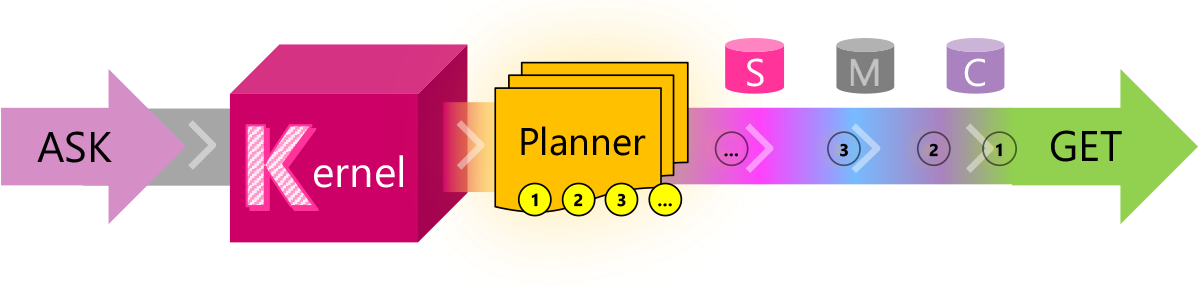
目前的LLM有很多限制,有很多问题并不能很好的解决,例如文本输入长度有限、无法记住很早之前的信息等。而这些问题目前也都缺少合适的解决方案。它们所依赖的技术:如任务规划、提示模板、向量化内存等需要的是编程的智慧。Semantic Kernel就是微软在这个背景下推出的一个结合LLM与传统编程技术的编程框架。

在去年12月2日的PyTorch大会上(参考链接:[重磅!PyTorch官宣2.0版本即将发布,最新torch.compile特性说明!](https://www.datalearner.com/blog/1051670030665432

本篇是《阿里云天池大赛赛题解析-机器学习篇》的第一部分工业蒸汽量预测的第三章-特征工程的内容,并附带了一些知识点的网页链接。内有数据预处理、特征降维等内容。
随着华为被美国多轮制裁,大家忽然发现原来国内在半导体硬件方面的差距居然如此之大。半导体硬件相关方面的关注度前所未有,为了更好地理解计算机运行的原理,本文翻译自耶鲁大学的PCLT网站,旨在介绍关于计算机运行的一些原理知识。
最近,随着ChatGPT的火爆,大语言模型(Large language model)再次被大家所关注。当年BERT横空出世的时候,基于BERT做微调风靡全球。但是,最新的大语言模型如ChatGPT都使用强化学习来做微调,而不是用之前大家所知道的有监督的学习。这是为什么呢?著名AI研究员Sebastian Raschka解释了这样一个很重要的转变。大约有5个原因促使了这一转变。
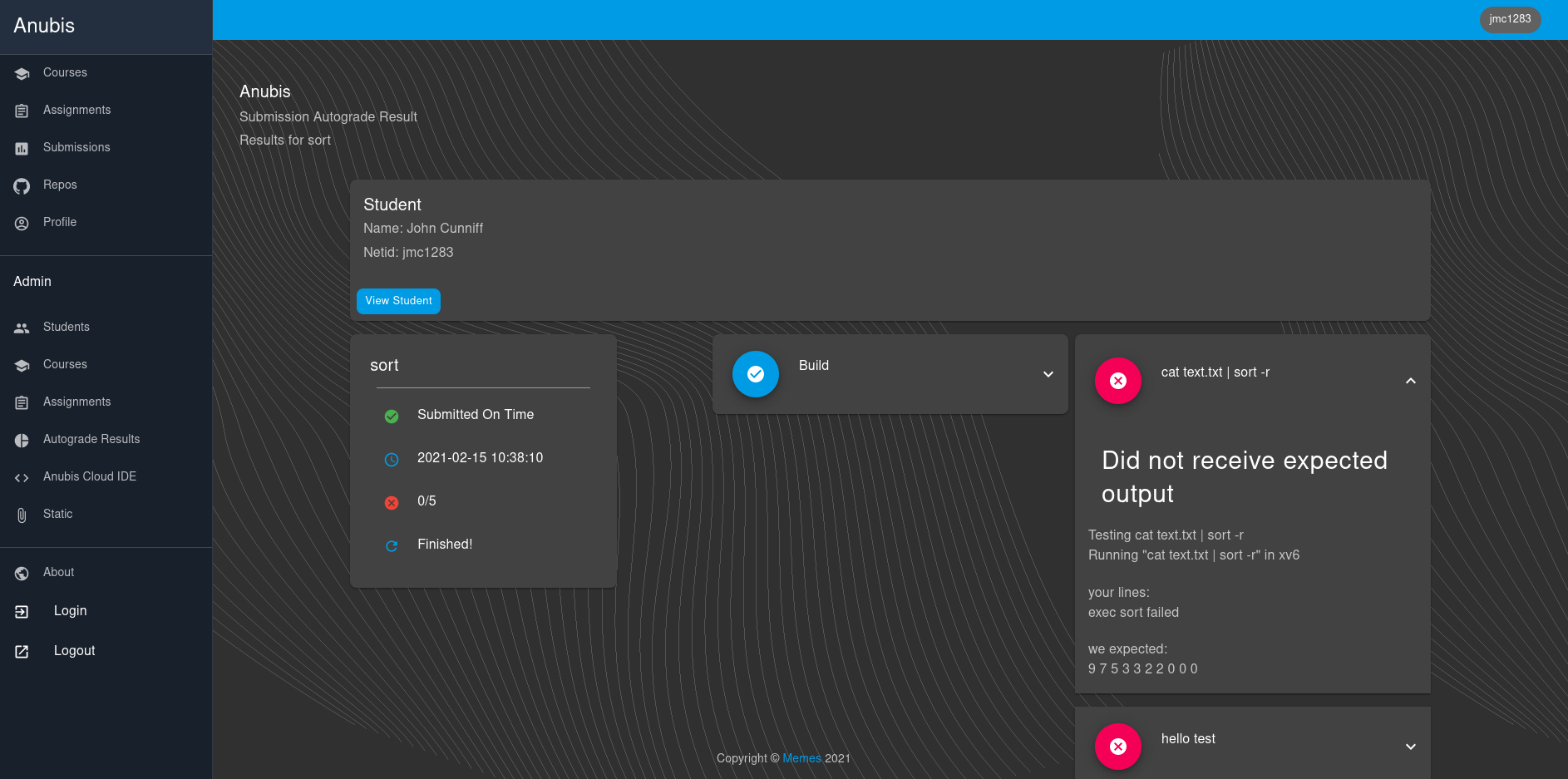
Anubis是一个分布式LMS(学习管理系统),由John Cunniff创建,专门为CS课程的自动化而设计。Anubis已经在纽约大学坦登分校使用并经过了几个学期的测试。这个系统的主要目的是自动为提交的作业评分,并提供了一个云IDE解决方案,以简化学生的体验。

Mistral-7B是由MistralAI开源的一个73亿参数规模的大语言模型,最早在2023年9月底开源。因为其良好的性能和友好的开源协议被很多人使用。今天,这个模型升级到来v0.2版本Mistral-7B-v0.2。基于Mistral-7B-v0.2进行指令微调的模型 Mistral-7B-Instruct-v0.2在2023年11月11日公布,而这个基座模型则是在2023年3月24日开源。

在深度学习和计算机视觉的发展历程中,视频生成技术一直是一个极具挑战和创新的领域。而发布了一系列开源领域最强图像生成模型Stable Diffusion系列模型背后的企业StabilityAI最近又开源了一个的文本生成视频大模型Stable Video Diffusion模型,这个模型可以生成最多20帧的视频。测试效果,这个模型普通版本与runway差不多,20帧版本则超过了runway!
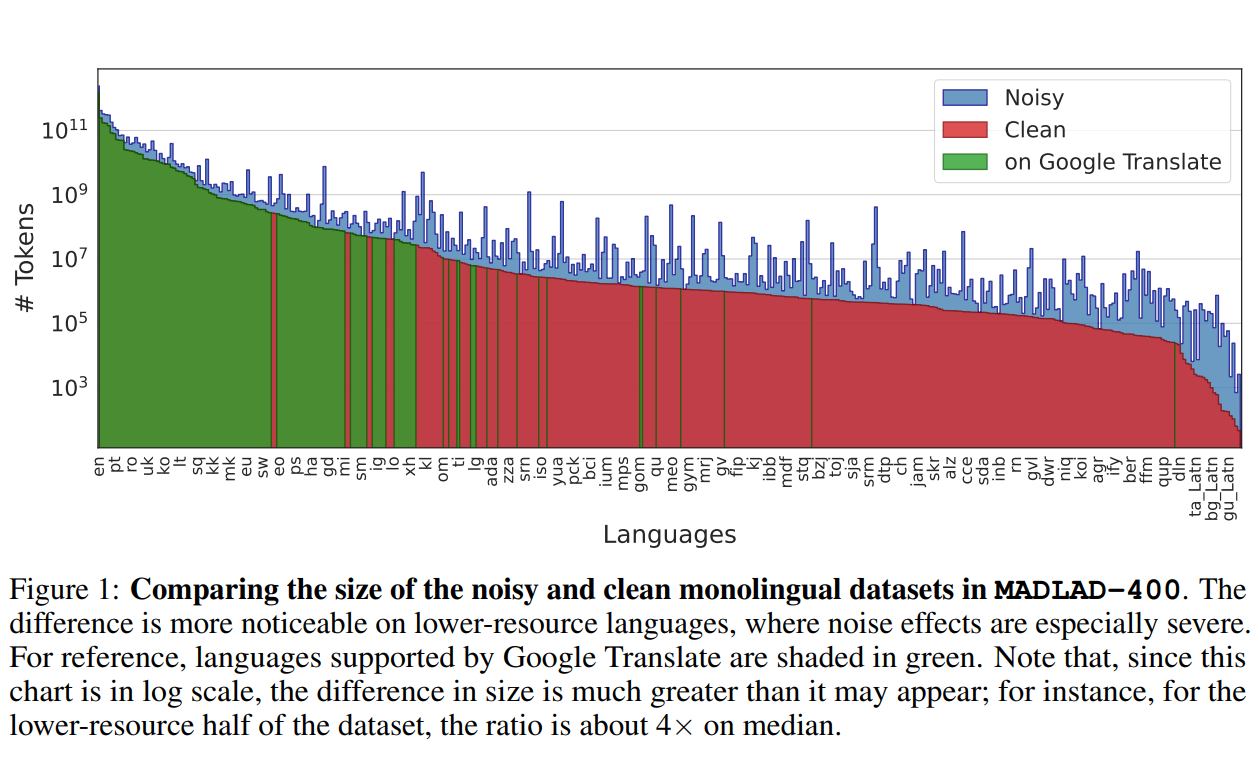
Google DeepMind与Google Research的研究人员推出了一个全新的多语言数据集——MADLAD-400!这个数据集汇集了来自全球互联网的419种语言的大量文本数据,其规模和语言覆盖范围在公开可用的多语言数据集中应该是最大的。研究人员从Common Crawl这个庞大的网页爬虫项目中提取了大量数据,并进行了人工审核,删除了许多噪音,使数据集的质量得到了显著提升。
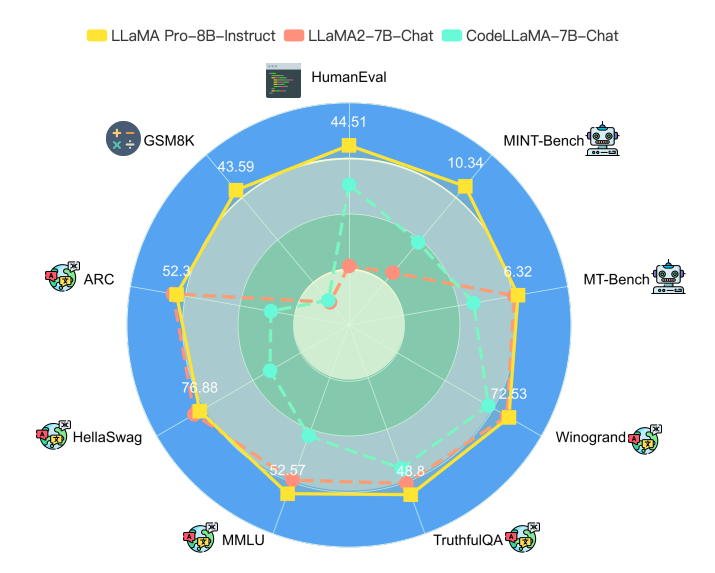
大语言模型一个非常重要的应用方式就是微调(fine-tuning)。微调通常需要改变模型的预训练结果,即对预训练结果的参数继续更新,让模型可以在特定领域的数据集或者任务上有更好的效果。但是微调一个严重的副作用是可能会让大模型遗忘此前预训练获得的知识。为此,香港大学研究人员推出了一种新的微调方法,可以保证模型原有能力的基础上提升特定领域任务的水平,并据此开源了一个新的模型LLaMA Pro。