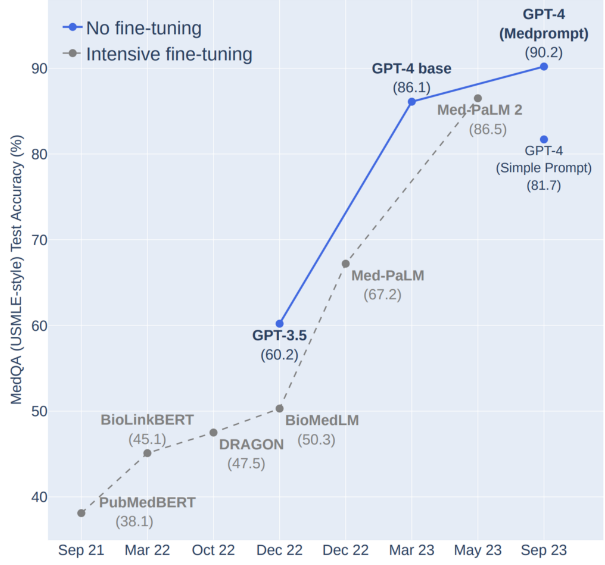
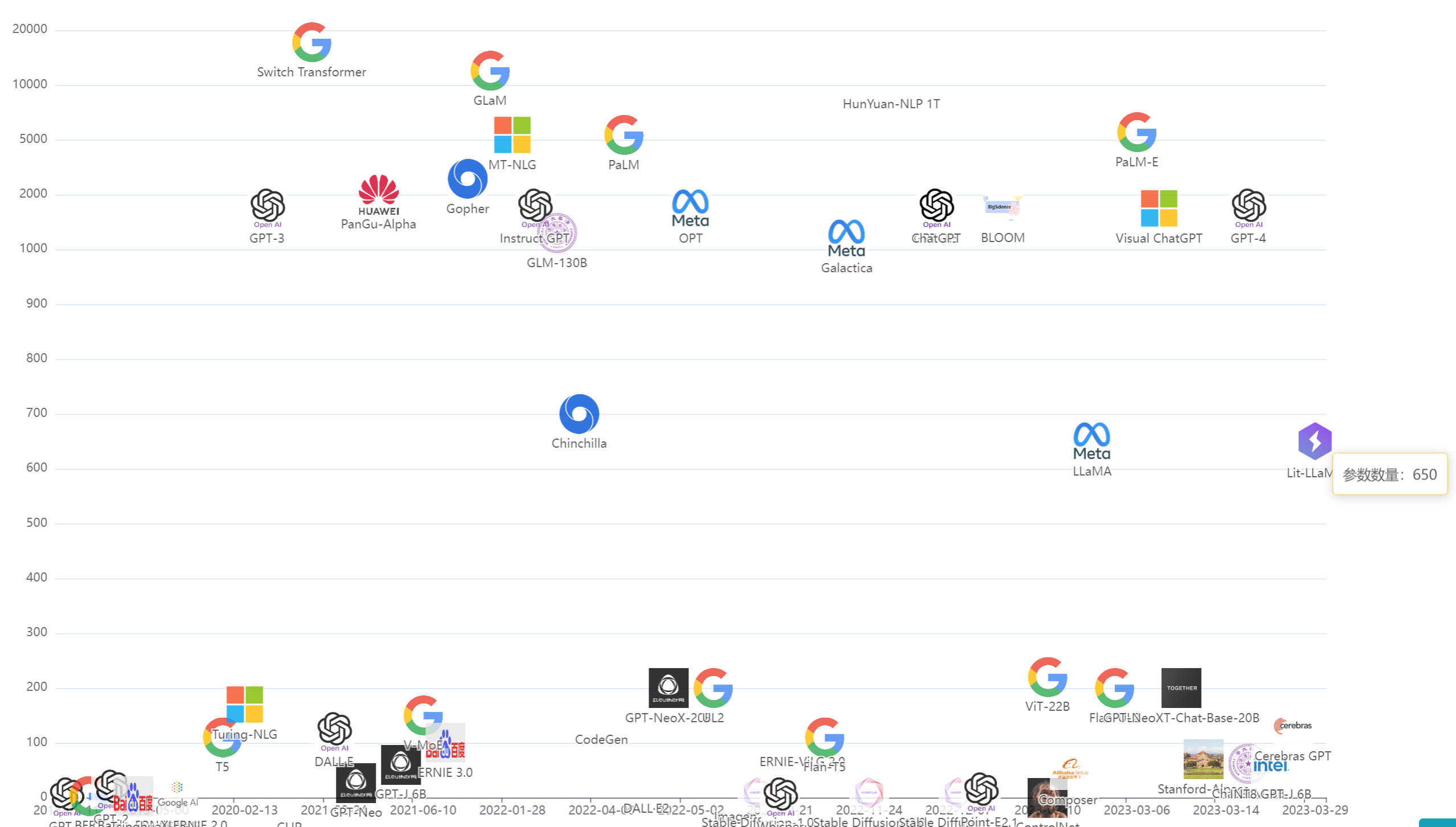
如何基于Gradio构建生成式AI的应用:吴恩达联合HuggingFace推出最新1小时短课
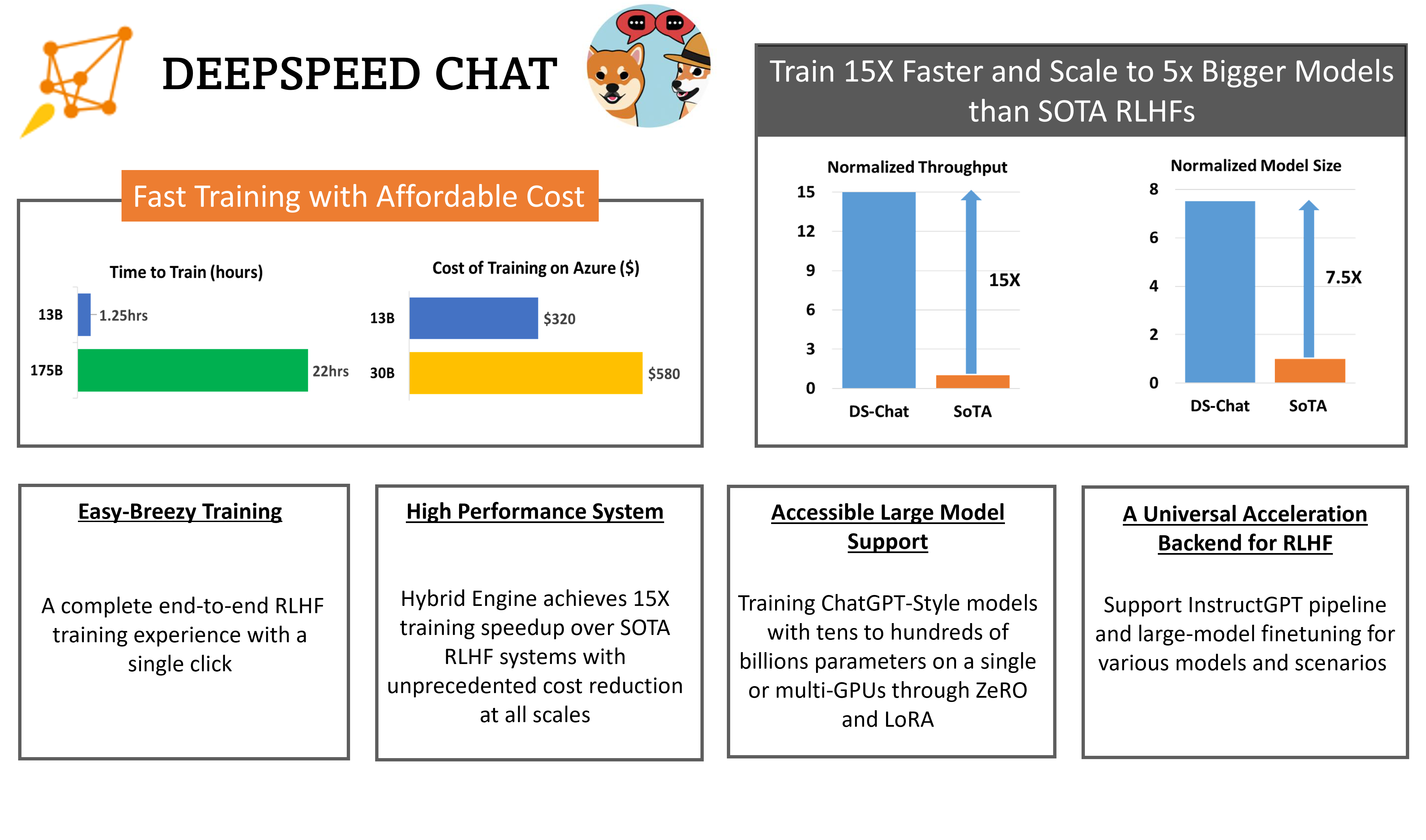
ChatGPT是属于生成式AI的一种应用。由于其强大的效果已经变成了当前最主流的一种AI方案。而构建生成式AI应用的一个重要方向是构建友好的web形态的demo让用户能快速体验。Gradio就是这样一种开源方案,也是当前最流行的一种快速构建AI Web应用的方案。昨天吴恩达的DeepLearningAI与HuggingFace共同推出了最新的一期短课程《Building Generative AI Applications with Gradio》,教大家如何使用Gradio快速构建生成式AI的应用。