
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~




预测在全球决策中发挥着关键作用。例如,关于COVID-19扩散的预测为国家封锁提供了信息,而经济预测则影响了利率的制定。这些预测通常依赖于人类专家的仔细判断,他们必须考虑来自各种来源的数据。由于人工智能系统能够处理大量的数据,它们在这个领域有可能非常有用。 为此,ML Safety举办了一个关于AI预测的竞赛,比赛的目的是建立一个机器学习模型,做出准确和校准的预测。
深圳的元象科技开源了一个最高上下文256K的大语言模型XVERSE-13B-256K,可以一次性处理25万字左右,是目前上下文长度最高的大模型,而且这个模型是以Apache2.0协议开源,完全免费商用授权。

GPTs是OpenAI推出的用户自定义的GPT功能,这里的GPTs可以认为是specific GPT。用户创建GPTs主要是通过OpenAI提供的GPT Builder完成。GPT Builder提供的最基本的能力就是基于对话的方式来帮助用户创建GPTs。那么,这个对话式的GPT背后的指令是什么?官方设置了什么样的Prompt来让GPT帮助普通用户建立GPTs呢?本文基于官方最新的博客介绍一下。
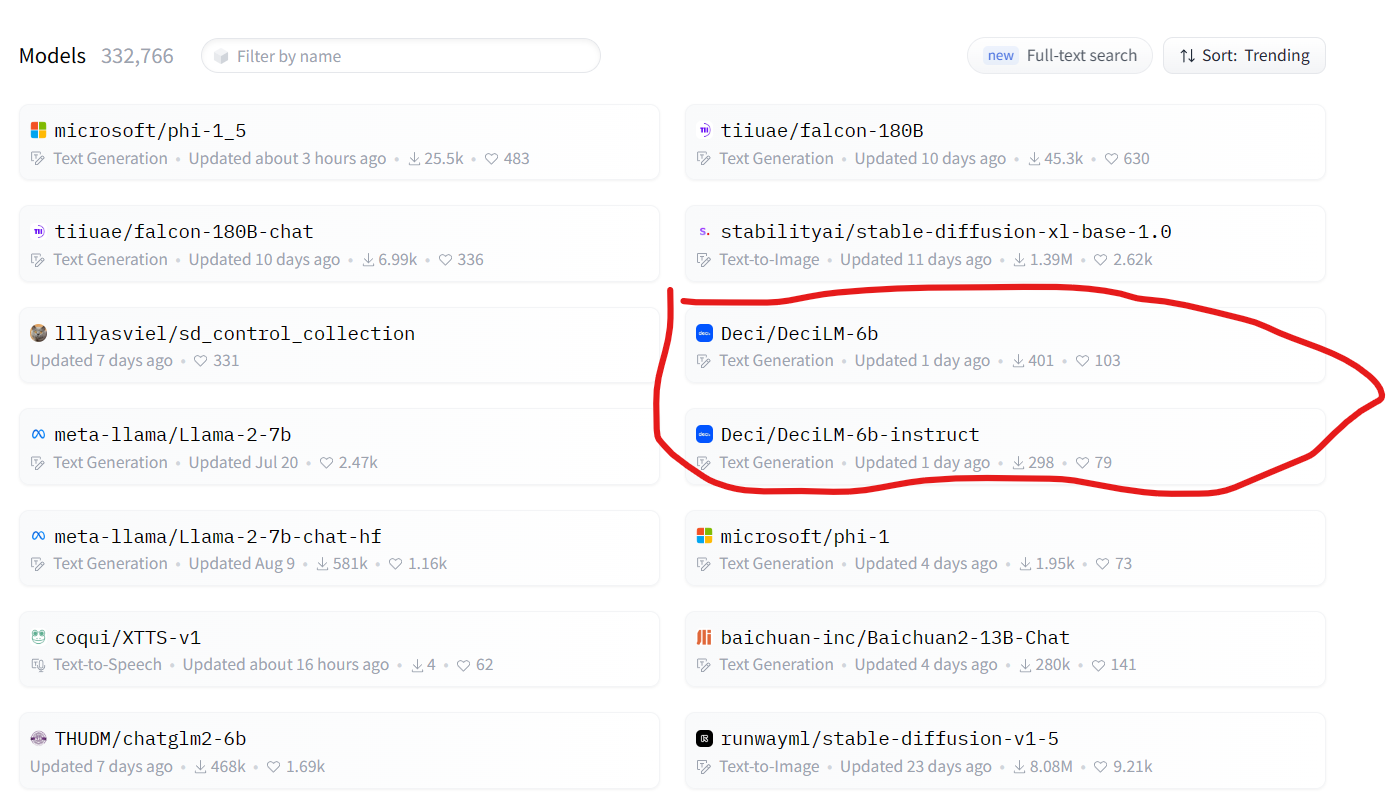
随着大型语言模型(LLMs)的不断发展,它们在训练和推理方面的计算需求已经呈指数级增长。这一趋势不仅带来了高昂的成本和能源消耗,还引入了模型部署和可伸缩性方面的障碍。为此,DeciLM开源了2个全新的DeciLM-6B和DeciLM-6B-Instruct大模型,参数比LLaMA2 7B略低,性能相当,但是推理速度却超过LLaMA2 7B的15倍。
Hugging Face一直在努力支持深度学习,但是,这只是深度学习的一部分。传统统计机器学习领域里面最重要的工具Scikit-learn如今终于和深度学习的开源标杆工具Hugging Face联手。

Phi系列大语言模型是微软开源一个小规模参数的语言模型。第一代和第二代的Phi模型参数规模都不超过30亿,但是在多个评测结果上都取得了非常亮眼的成绩。今天,微软发布了第三代Phi系列大模型,最高参数规模也到了140亿,其中最小的模型参数38亿,评测结果接近GPT-3.5的水平。

OpenAI发布的模型中最主要的是大语言模型GPT系列。而且GPT系列模型也在朝着多模态的方向发展。尽管OpenAI有自己的TTS和ASR大模型,但是此前从未正式宣布过。就在今天,OpenAI正式宣布了他们首个语音合成大模型VoiceEngine,该模型也将提供API访问。OpenAI官方的声明中说,现有的基于声音的认证系统应该被淘汰掉!因为已经不安全了!
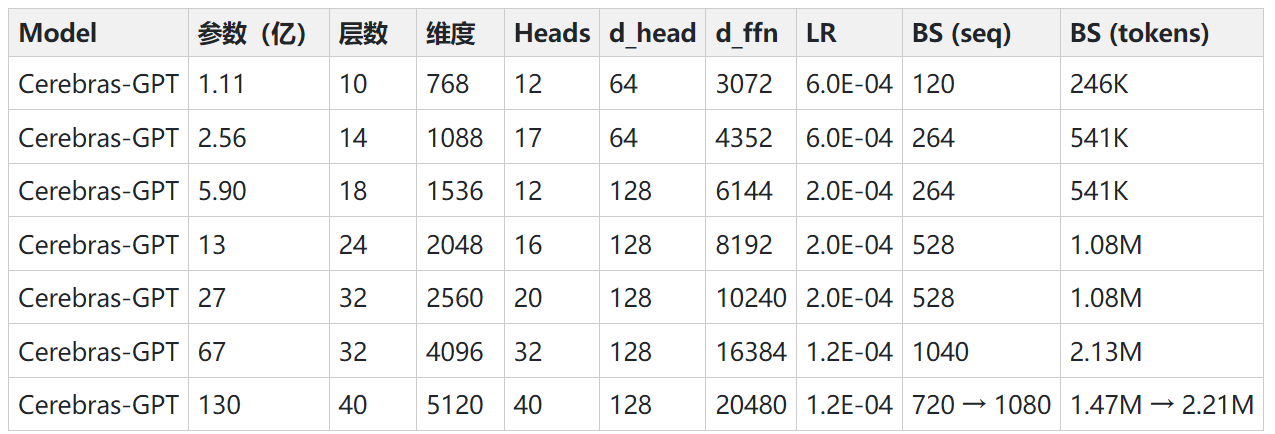
在最近的24个小时内,有2个开源的自然语言处理领域的开源预训练大模型发布。这两个模型都是类似GPT的Transformer模型,可以完成和ChatGPT类似的能力。最重要的是这2个模型完全开源!

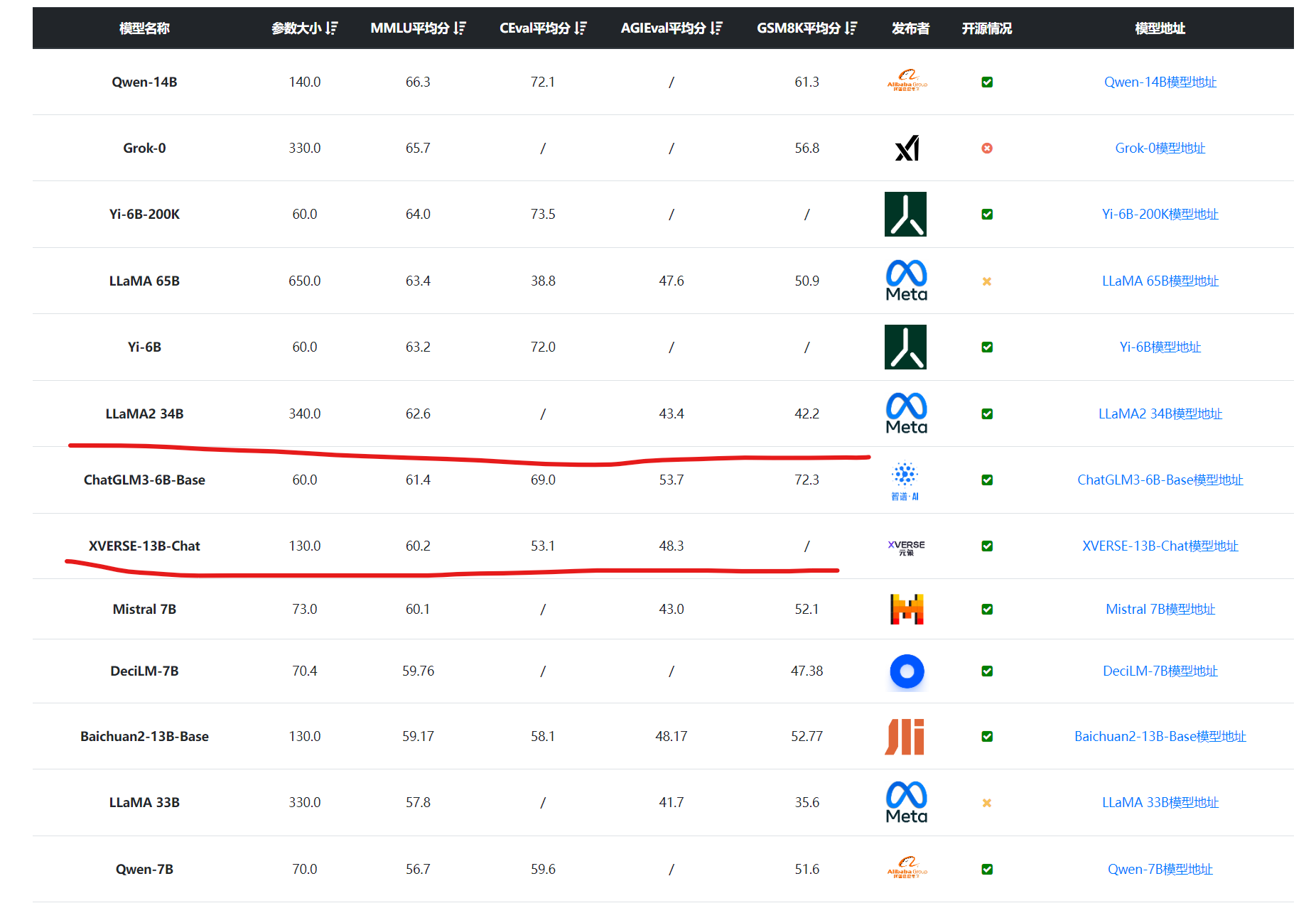
国产大语言模型的开源领域一直是很多企业或者科研机构都在卷的领域。最早,智谱AI开源ChatGLM-6B之后,国产大模型的开源就开始不断发展。早期大模型开源的参数规模一直在60-70亿参数规模,随着后续阿里千问系列的140亿参数的模型开源以及智源340亿参数模型开源之后,元象科技开源650亿参数规模的大语言模型XVERSE-65B,将国产开源大模型的参数规模提高到新的台阶。

最近开始学习新的前端技术。以前开发网站直接使用jQuery+Bootstrap组合,感觉非常容易和方便。但是,现在前端貌似都开始转向基于构建的方式去开发。由于初学者进入一个项目看很多内容也不如上手启动一个项目感受好,本文抛弃原理,直接教大家上手创建一个vue项目。

今天,OpenAI官方宣布了一个非常有意思的论文,他们使用GPT-4模型来自动解释GPT-2中每个神经元的含义,试图让语言模型来对语言模型本身的原理进行解释。

在当今的人工智能领域,大型语言模型(LLM)已成为备受瞩目的研究方向之一。它们能够理解和生成人类语言,为各种自然语言处理任务提供强大的能力。然而,这些模型的训练不仅仅是将数据输入神经网络,还包括一个复杂的管线,其中包括预训练、监督微调和对齐三个关键步骤。本文将详细介绍这三个步骤,特别关注强化学习与人类反馈(RLHF)的作用和重要性。
OpenAI发布了ChatGPT的企业版,这是一个专为企业设计的聊天机器人。这个版本不仅提供了企业级的安全和隐私保护,还具有更高的处理速度和更多的自定义选项。相比较个人版的ChatGPT,企业版主要是提升了性能、强调了安全等。
Qwen2.5-Omni-7B是阿里巴巴发布的一款端到端全模态大模型,支持文本、图像、音频、视频(无音频轨)的多模态输入与实时生成能力,可同步输出文本与自然语音的流式响应。目前,该模型在HuggingFace以Apache2.0协议开源,可以免费商用授权。
今日推荐
MistralAI开源240亿参数的多模态大模型Mistral-Small-3.1-24B:评测结果与GPT-4o-mini与Gemma 3 27B有来有回,开源且免费商用,支持24种语言
预训练大模型时代必备技巧——提示工程指南(Prompt Engineering Guide)
tokens危机到来该怎么办?新加坡国立大学最新研究:为什么当前的大语言模型的训练都只有1次epoch?多次epochs的大模型训练是否有必要?
在线广告的紧凑分配方案(Optimal Online Assignment with Forecasts)
MetaGPT技术全解析:另一个AutoGPT,一个可以替代小型软件开发团队的配备齐全的软件开发GPT,产品经理、系统设计、代码实现一条龙