
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



在2023年的9月26日,MetaAI发布了一个Emu大模型,这是一个文本生成图像大模型,基于28亿参数的U-Net进行预训练得到,然后使用几千张高质量图像进行质量微调(Quality-Tuning)来提高模型的效果。不过,Emu模型并没有开源。但是,上周,Meta官方发布了一个全新的独立的文本生成图像系统Imagine,可以免费创作图像,质量很高。
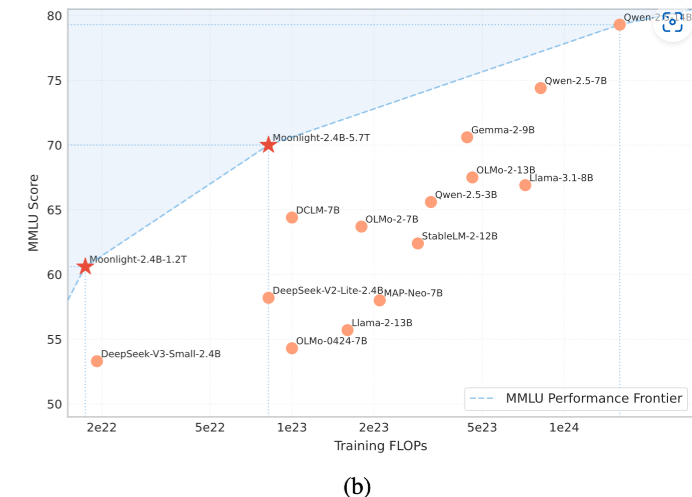
月之暗面(Moonshot AI)是此前中国大模型企业中非常受关注的一家企业。旗下的Kimi大模型和产品因为强悍的性能、超长的上下文以及非常快速的响应引起了广泛的关注。不过,此前MoonshotAI的策略一直是闭源模型,但是产品免费。也许是受到了DeepSeek的压力,月之暗面在2025年2月23日首次开源了旗下的一个小规模参数的大语言模型Moonlight-16B。

Gemma系列是谷歌开源的与Gemini同源的小规模参数版本的大语言模型,此前只有70亿参数和20亿参数的Gemma大语言模型。而现在,Google又开源了2个系列的新的大模型:一个是编程大模型CodeGemma系列,一个是基于RNN架构新型大模型RecurrentGemma。

Kimi K2是由Moonshot AI最新推出的旗舰级大模型,首次将开放Agentic Intelligence(自主代理智能)与强大工具调用能力有机整合。它不仅在知识推理、数学、代码等传统“非思维模型”任务上展现出全球领先的能力,还特别针对一系列实际Agentic(自动决策与操作型)任务进行了深度优化。在业内,这代表AI模型正从“只会答题”向“能自主完成复杂任务”转变。K2模型完全开源,可免费商用授权。

万众瞩目的GPT-4即将来临!3月9日晚上在德国举办的一个AI会议。微软德国的员工参与了讨论,在介绍微软云的AI能力的时候,微软德国CTO Andreas Braun透露了GPT-4将在下周发布。

Assistant API是OpenAI提供的一个大模型助手类的接口,可以让开发者更加自由、准确地构建类AI Assitant系统。一个AI Assistant可以利用大模型、工具和文件来响应用户的问题。

MistralAI开源的混合专家模型Mistral-7B×8-MoE在本周吸引了大量的关注。这个模型不仅是稍有的基于混合专家技术开源的大模型,而且有较高的性能、较低的推理成本、支持法语、德语等特性。昨天MistralAI发布的不仅仅是这个混合专家模型,还有他们的平台服务La plateforme。在这里他们透露了MistralAI还有更加强大的模型。

就在刚刚,马斯克在推特上宣布本周会开源Grok大语言模型。xAI是马斯克在2023年3月份创办的一家大模型初创企业。因为ChatGPT过于火爆,离开OpenAI之后马斯克又再次开始推出大模型,就是这个Grok。
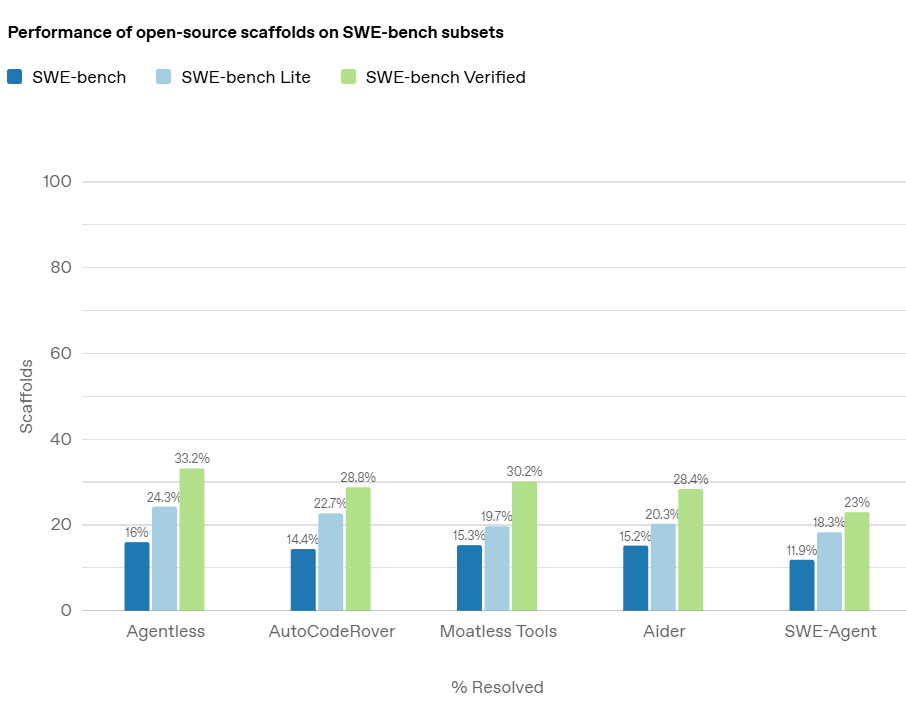
在人工智能领域,随着大型语言模型(LLMs)在各类任务中的表现不断提升,评估这些模型的实际能力变得尤为重要。尤其是在软件工程领域,AI 模型是否能够准确地解决真实的编程问题,是衡量其真正应用潜力的关键。而在这方面,OpenAI 推出的 *SWE-bench Verified* 基准测试,旨在提供一个更加可靠和精确的评估工具,帮助开发者和研究者全面了解 AI 模型在处理软件工程任务时的能力。
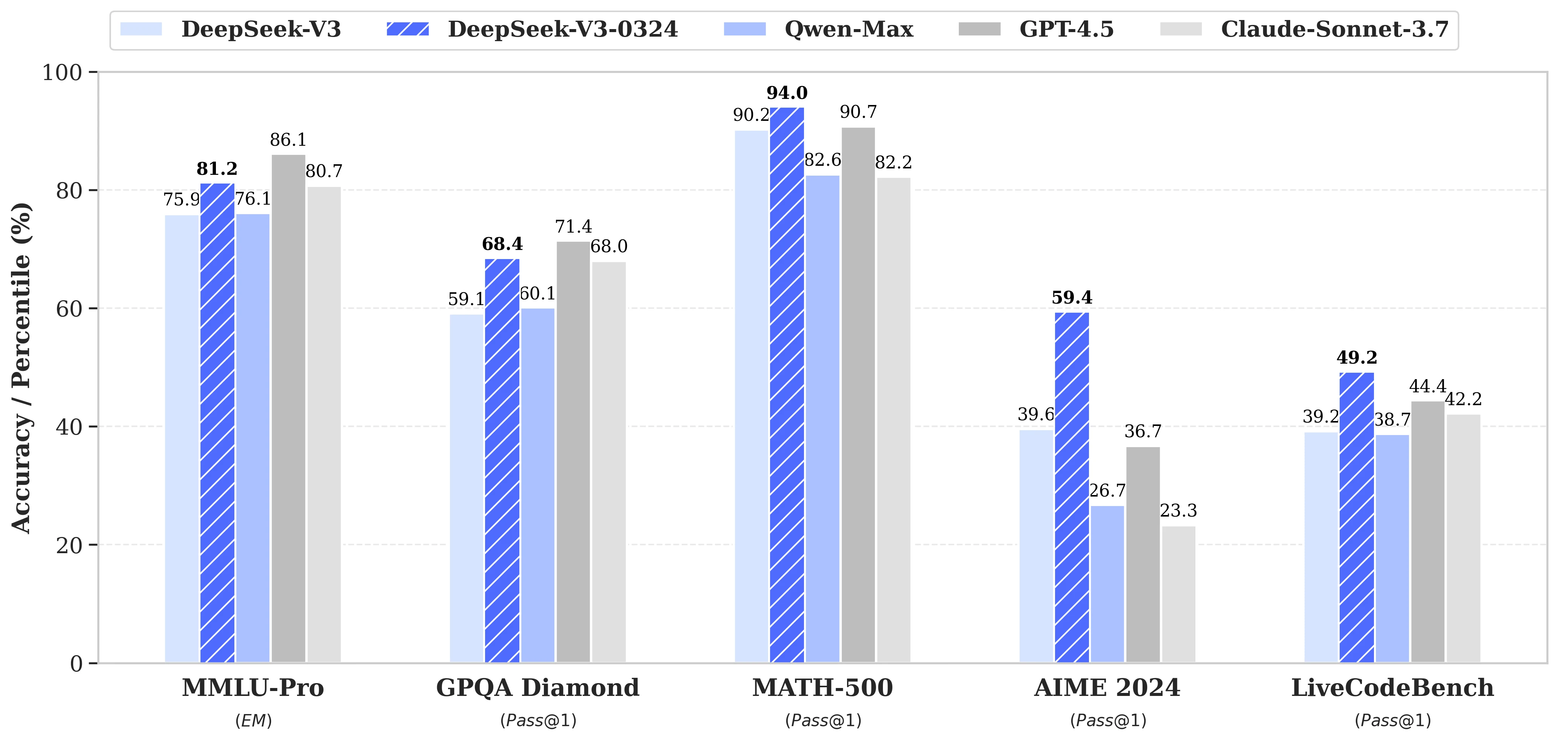
2025年3月25日,DeepSeekAI低调开源了DeepSeek-V3-0324大模型。作为DeepSeek-V3的重要升级版本,该模型在推理能力、中文写作、前端开发以及功能调用等多个关键领域实现了显著提升。在MMLU Pro等评测上,已经成为了非推理大模型中最强的模型,部分评测结果超过GPT-4.5模型。

尽管各家大模型技术进展神速,但是在复杂任务的推理上,大模型目前依然较弱。在去年底,各方消息透露,OpenAI内部有一个称为Q\*的项目取得了重大的突破,可以大幅提高大模型的推理能力。但是,几个月过去了,这个当时吸引了大量讨论的项目没有任何信息。直到昨天,Reuters披露了Q\*项目的进展,这个项目已经变为Strawberry!并且距离发布时间更近了!

今天,Google为全球开发者社区带来了一款激动人心的新工具——**Gemini CLI**。这是一款免费、开源的AI智能体,它将Google当前最强大的模型Gemini 2.5 Pro的能力,直接集成到了开发者最熟悉的命令行界面(CLI)中。对于那些视终端为“家”的开发者来说,这无疑是一个重大的升级。它不仅擅长编码,更是一个可以处理内容生成、问题解决、深度研究和任务管理的多功能本地实用工具。它的发布,旨在为个人开发者提供前所未有的便捷AI体验,非常强大!

Grok4是马斯克旗下大模型初创企业xAI的第四代代码,在五月份的时候,马斯克就透露他们马上要发布Grok 3.5模型,六月份的时候说这个模型效果很好,版本号就直接改为4,这中间经过多次波折,最终马斯克说Grok 4将在7月4日之后发布。截止目前,虽然xAI官方没有正式宣布Grok 4,但是目前Grok 4已经透露了很多的消息。本文将对这些信息做总结和分析。
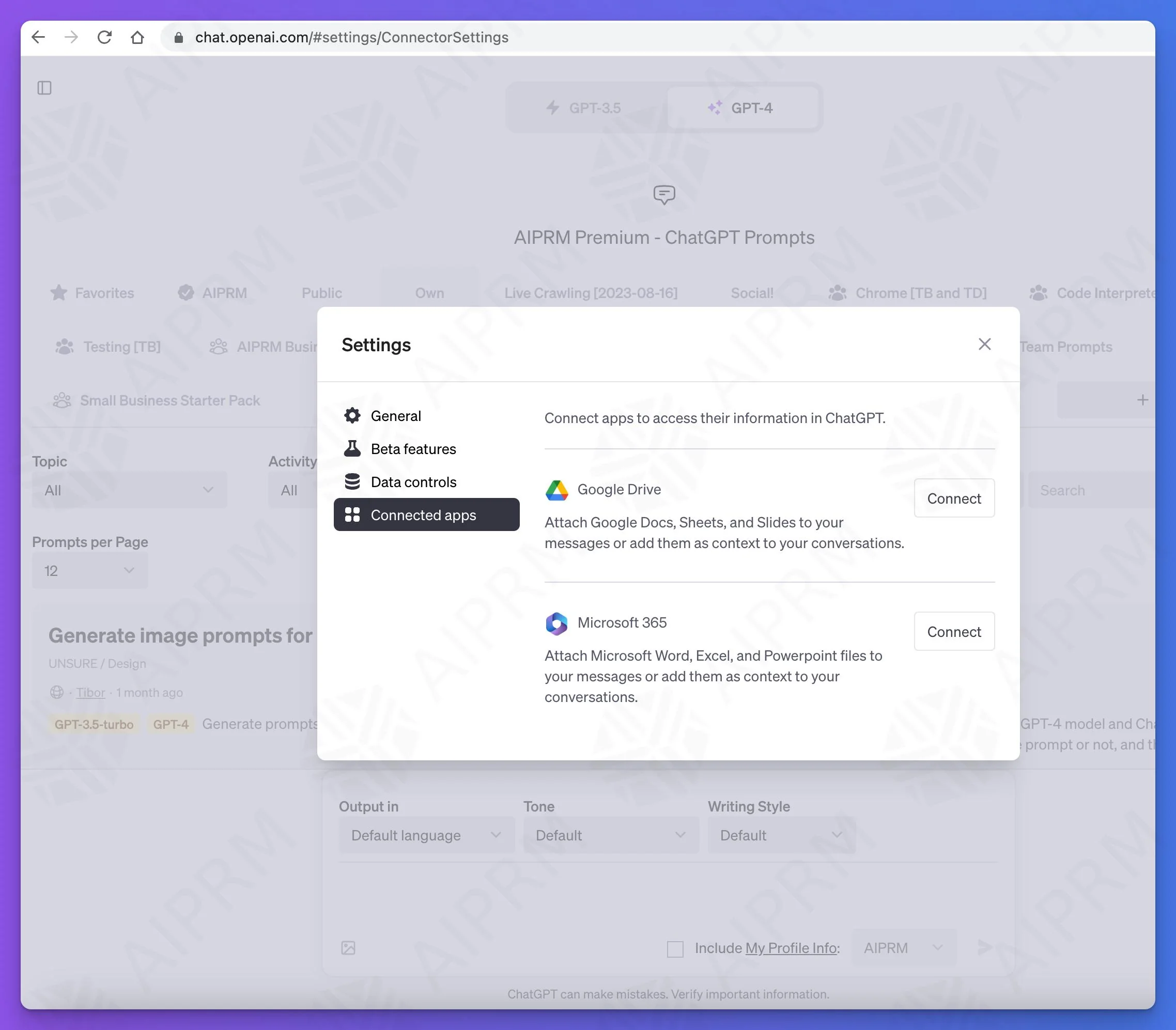
ChatGPT的发展速度很快,在前面已经介绍过ChatGPT即将推出的Team订阅计划和新界面,包括对接自定义数据和自定义接口等。此外,DataLearnerAI还发现ChatGPT即将推出关联APP的能力,截图显示,目前已经测试了对接Google Drive和Microsoft 365两个。

马斯克旗下的xAI公司正式发布Grok4大模型,包含Grok 4和Grok4 Heavy版本,其中Grok4 Heavy是一个Agent系统,在AIME2025(美国的数学邀请赛)得分满分,超过了所有大模型。此前透露的Grok 4 Code和视频生成能力都没有发布。
今日推荐
6种大模型的使用方式总结,使用领域数据集持续做无监督预训练可能是一个好选择
IOI(International Olympiad in Informatics):从世界顶级算法竞赛到大语言模型的新基准
最强SQL代码生成开源大模型发布:DefogAI开源超过gpt-3.5-turbo的SQL生成大模型SQLCoder,免费商用授权~
GPT-4o再度更新:OpenAI发布GPT-4o(2025-03-26)版本模型,大幅提升复杂指令遵循能力,在LM Arena评测超过GPT-4.5,所有类别评测仅次于Gemini 2.5 Pro
最强AI对话系统ChatGPT不完全使用指南——已发掘功能展览!
即将发布的装备了ChatGPT模型的新版bing都有哪些功能?