
2023年4月25日的AI技术新进展快报:Chatbot Arena、Track Anything、600+AI工具、RedPajama 7B进展、科大讯飞大模型内测等
最近两天,关于AI技术和产品的进展依然很快。所以,我们本次直接给出一个AI技术进展快报。与大家分享一下最新的AI技术情况。
探索人工智能与大模型最新资讯与技术博客,涵盖机器学习、深度学习、自然语言处理等领域的原创技术文章与实践案例。
最近两天,关于AI技术和产品的进展依然很快。所以,我们本次直接给出一个AI技术进展快报。与大家分享一下最新的AI技术情况。
HuggingFace是近几年最火热的AI社区,在短短几年时间里已经称为AI模型的GitHub。目前,HuggingFace上已经托管了18万多的模型、3万多的数据集以及4万多的模型demo(spaces)。今天,HuggingFace发布了HuggingChat,声称要做最好的开源AI Chat项目,并且对所有人开放。
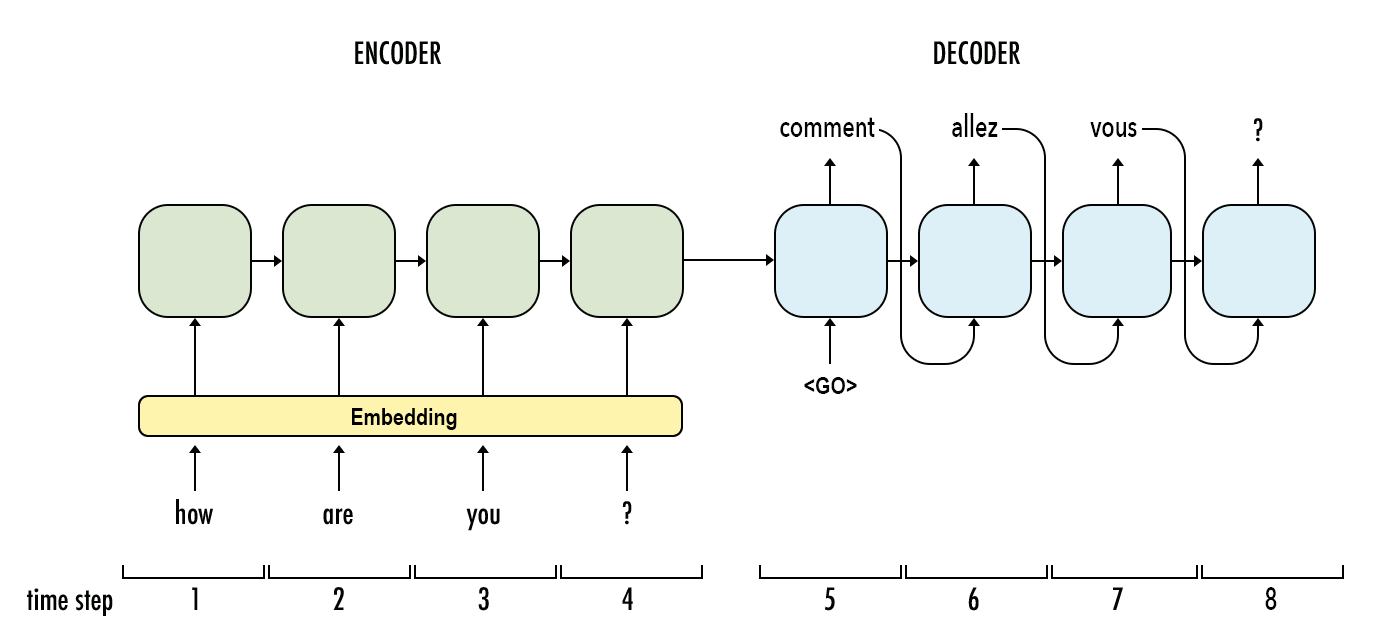
大语言模型(Large Language Model,LLM)是近几年进展最大的AI模型。早期的深度学习架构语言模型以RNN为主,现在则基本上转成了Transformer的架构。尽管如此,Transformer本身也是有着不同的区别。而本文是大语言模型系列中的一篇,主要介绍RNN模型与Transformer之间的区别。
大语言模型(Large Language Model,LLM)是近几年进展最大的AI模型。早期的深度学习架构语言模型以RNN为主,现在则基本上转成了Transformer的架构。尽管如此,Transformer本身也是有着不同的区别。而本文是大语言模型系列中的一篇,主要介绍RNN模型与Transformer之间的区别。
昨天,吴恩达宣布与OpenAI联合推出了一个新的面向开发者的ChatGPT的Prompt课程。课程主要教授大家如何使用Prompt做ChatGPT的应用开发、使用ChatGPT的新方法、建立自己的个性化的Chatbot,以及最重要的,基于OpenAI的API来练习Prompt工程技巧!

2023年3月23日OpenAI官方宣布ChatGPT即将支持Plugin模式。这是一种用插件的方式来解锁ChatGPT的能力,包括让ChatGPT可以浏览网页、从本地商店订购食材等。今天,沃顿商学院教授Ethan Mollick在推特上公布了自己收到了ChatGPT内测邀请,并使用它的代码解释器(Python Interpreter)插件让ChatGPT针对一份excel数据完成了非常专业的数据分析的工作。
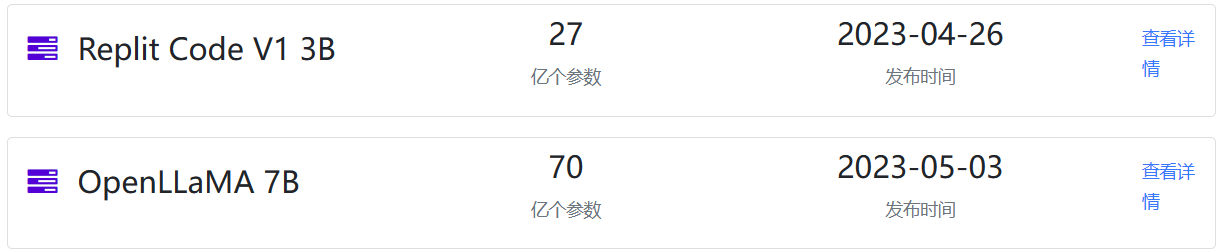
五一长假最后一天,AI技术的发展依然火热。今天有2个重磅的开源模型发布:一个是前几天提到的Replit的代码补全大模型Replit Code V1 3B,一个是UC Berkeley的博士生Hao Liu发起的一个开源LLaMA复刻项目。
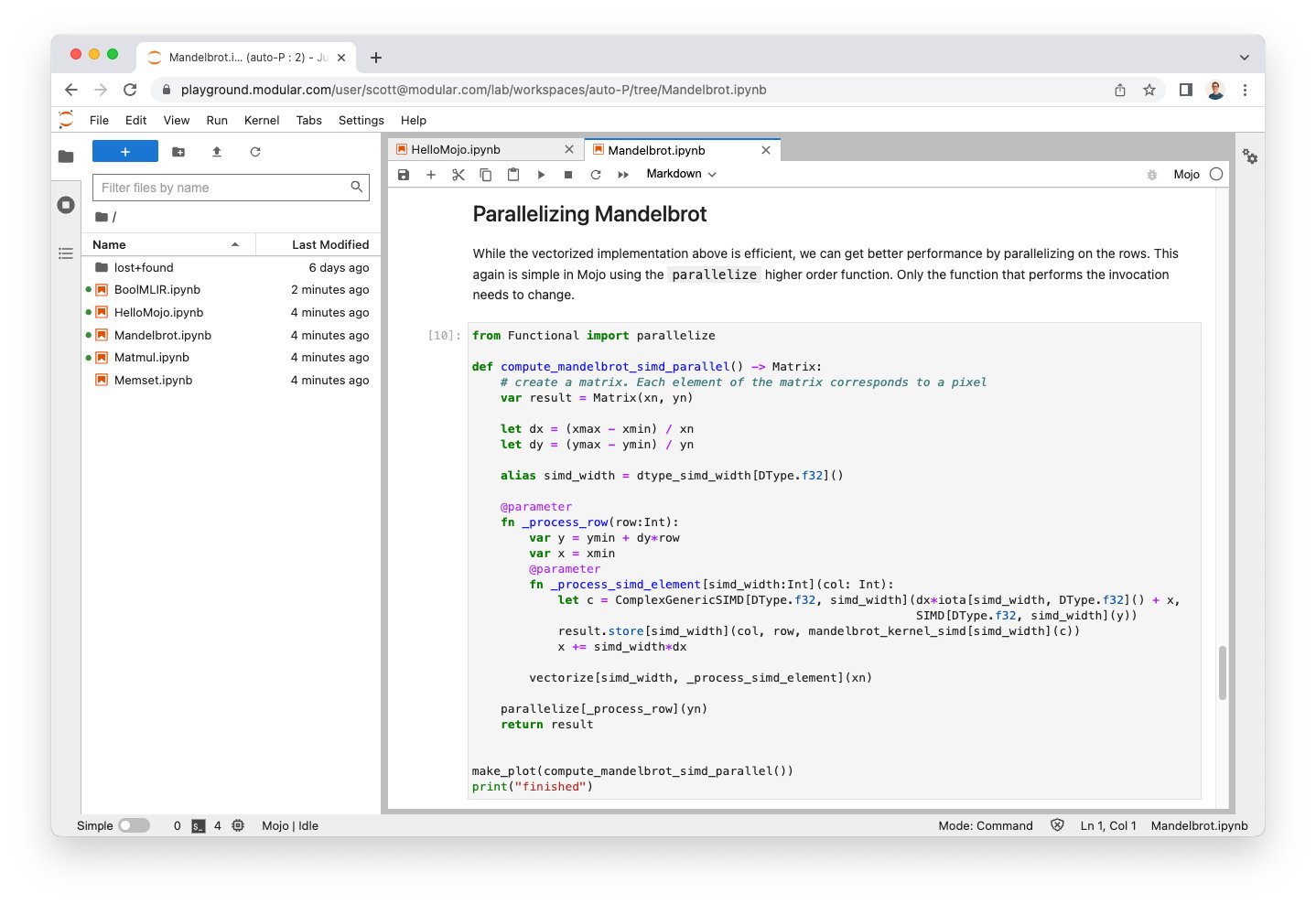
昨天,前苹果工程师、swift编程语言创建者Chris Lattner创立的ModularAI发布了一个新的编程语言Mojo。根据测试,该语言比Python最高提速35000倍!本文将简单介绍一下这个Mojo编程语言。

5月4日,网络流传了一个所谓Google内部人员写的内部信,表达了Google和OpenAI这样的公司可能并不能在AI领域获得胜利的焦虑。里面说明了开源的AI模型发展迅速,不管是Google还是OpenAI都没有很好的护城河。
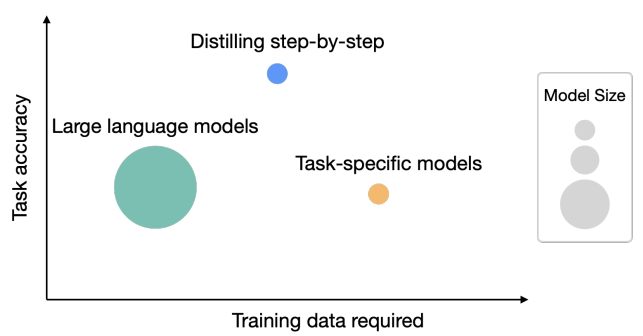
华盛顿大学研究人员与Google的研究人员一起在5月3日公布了一个新的方法,即逐步蒸馏(Distilling step-by-step),这个方法最大的特点有2个:一是需要更少的数据来做模型的蒸馏(根据论文描述,平均只需要之前方法的一半数据,最多只需要15%的数据就可以达到类似的效果);而是可以获得更小规模的模型(最多可以比原来模型规模小2000倍!)

昨天,开源AI模型领域迎来一个重磅玩家,MosaicML发布MPT-7B系列模型,根据官方宣布的测试结果,MPT-7B的水平与MetaAI发布的LLaMA-7B水平差不多,属于当前开源领域最强大的模型。最重要的是,MPT-7B系列中有一个可以支持最多65k上下文输入的开源模型,比GPT-4的32k还高!应该是目前最长的!

大语言模型中一个非常重要的内容就是关于代码的支持。通常,基于代码数据训练的模型不仅在代码补全方面有着更好地支持,也可能是大语言模型逻辑能力的部分来源。本文将总结目前业界专门针对代码补全(生成)方面而做的8个大模型。
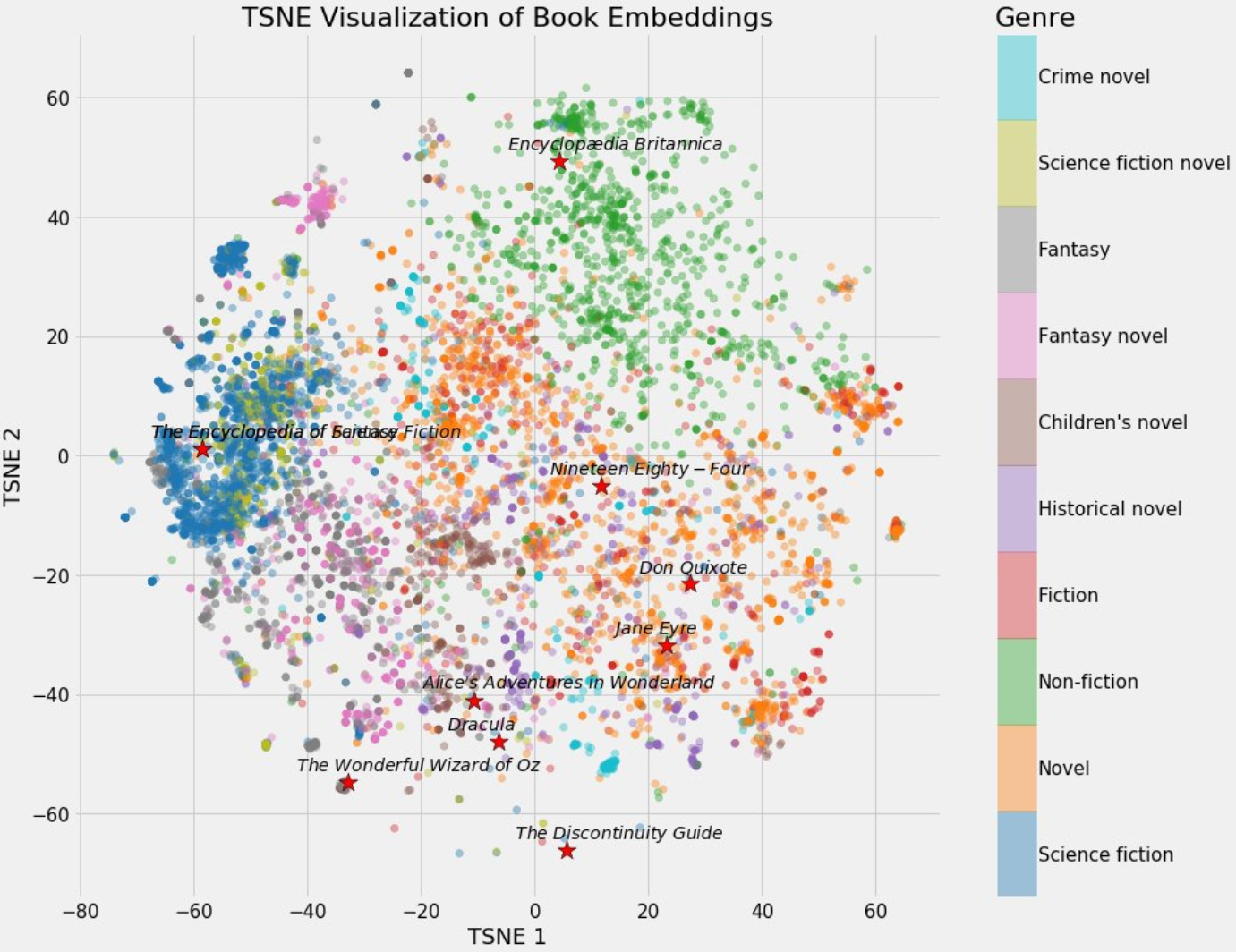
今天,推特上一位科技博主SullyOmarr分享了一个关于embedding的内容十分火爆。主要介绍为什么embedding对于在目前的AI大模型中很重要。这是一个十分不错的关于embedding知识的介绍。本文将根据SullyOmarr的内容也对embedding做一个简单的介绍,并解释为什么它在大语言模型中十分重要。
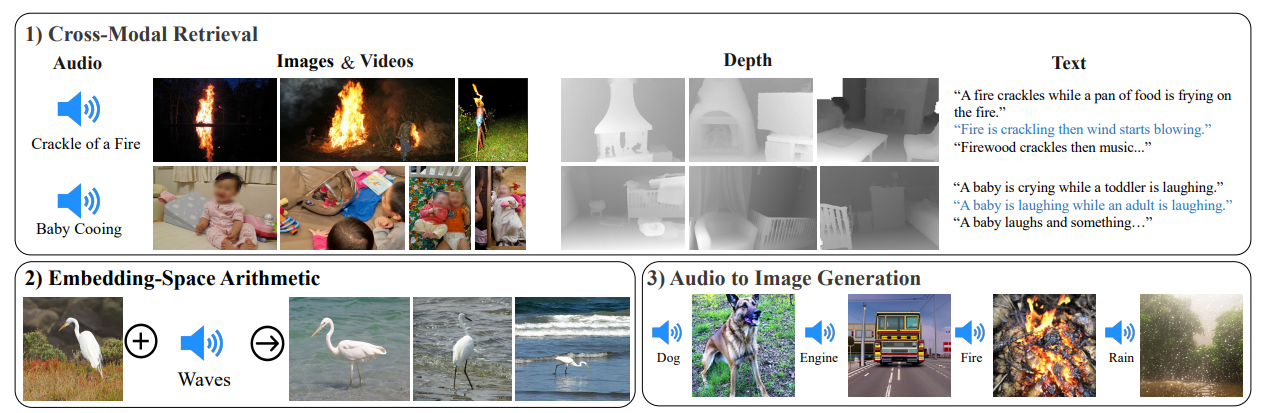
当前,大语言模型主要是基于生成式自然语言处理模型为主。少部分多模态模型可以处理文本、图片和视频信息。但是,AI模型目前还无法像人类一样接受周围的多模态信息进行处理,如图像、文本、声音等。但是,昨天MetaAI发布了一个可以听说读写的AI大模型ImageBind,它可以同时处理6种数据,并输出。本文将简单介绍一下这个模型。

今天,OpenAI官方宣布了一个非常有意思的论文,他们使用GPT-4模型来自动解释GPT-2中每个神经元的含义,试图让语言模型来对语言模型本身的原理进行解释。
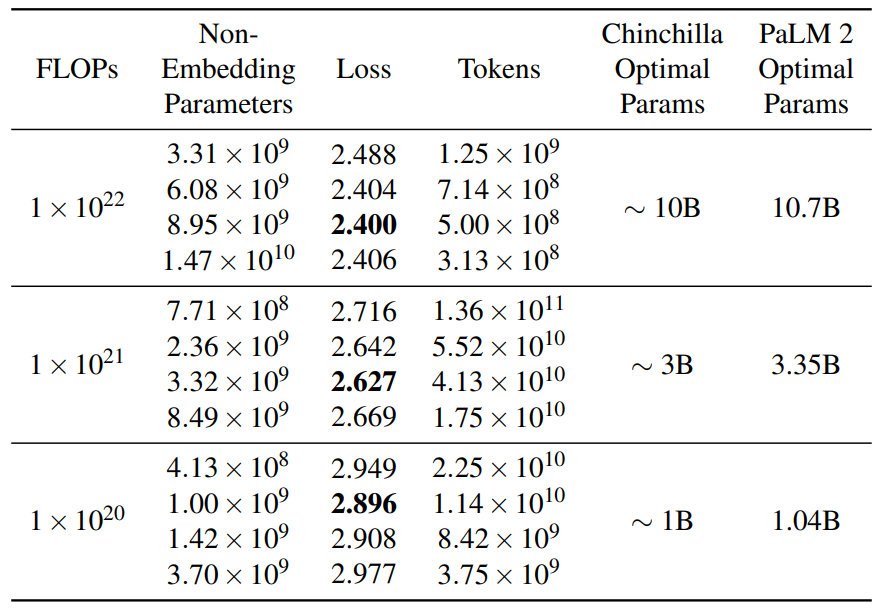
作为PaLM的继任者,PaLM2的发布被谷歌寄予厚望。与OpenAI类似,谷歌官方没有透露很多关于模型的技术细节,虽然发布了一个92页的技术报告,但是,正文内容仅仅27页,引用和作者14页,剩余51页都是展示大量的测试结果。而前面的27页内容中也没有过多的细节描述。尽管如此,这里面依然有几个十分重要的结论供大家参考。

今天,HuggingFace官方宣布了Transformers最大胆的功能:Transformers Agents。这是继AutoGPT开创性发布之后,AI Agent被业界接受的另一个重要的里程碑。

Cornell Tech开源了LLMTune,这是一个可以在消费级显卡上微调大模型的框架,经过测试,可以在48G显存的显卡上微调4bit的650亿参数的LLaMA模型!
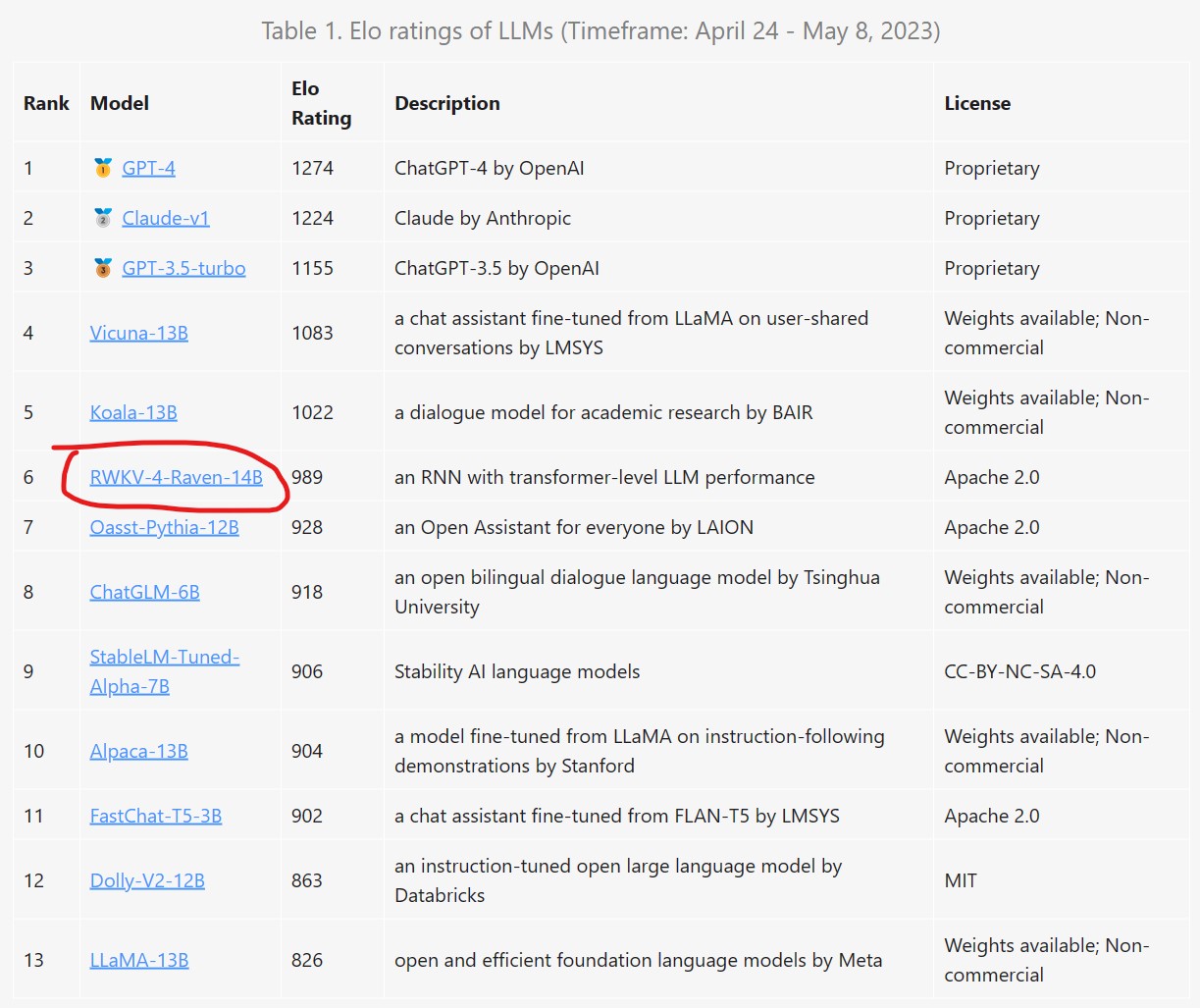
RWKV是一个结合了RNN与Transformer双重优点的模型架构。由香港大学物理系毕业的彭博首次提出。简单来说,RWKV是一个RNN架构的模型,但是可以像transformer一样高效训练。今天,HuggingFace官方宣布在transformers库中首次引入RNN这样的模型,足见RWKV模型的价值。
2022年11月底,OpenAI发布ChatGPT,2023年3月14日,GPT-4发布。这两个模型让全球感受到了AI的力量。而随着MetaAI开源著名的LLaMA,以及斯坦福大学提出Stanford Alpaca之后,业界开始有更多的AI模型发布。本文将对4月份发布的这些重要的模型做一个总结,并就其中部分重要的模型进行进一步介绍。

德国的一位博士生开源了一个使用LoRA(Low Rank Adaptation)技术和PEFT(Parameter Efficient Fine Tuning)方法对Whisper模型进行高效微调的项目。可以让大家在消费级显卡(显存8GB)上对OpenAI开源的WhisperV2模型进行微调!
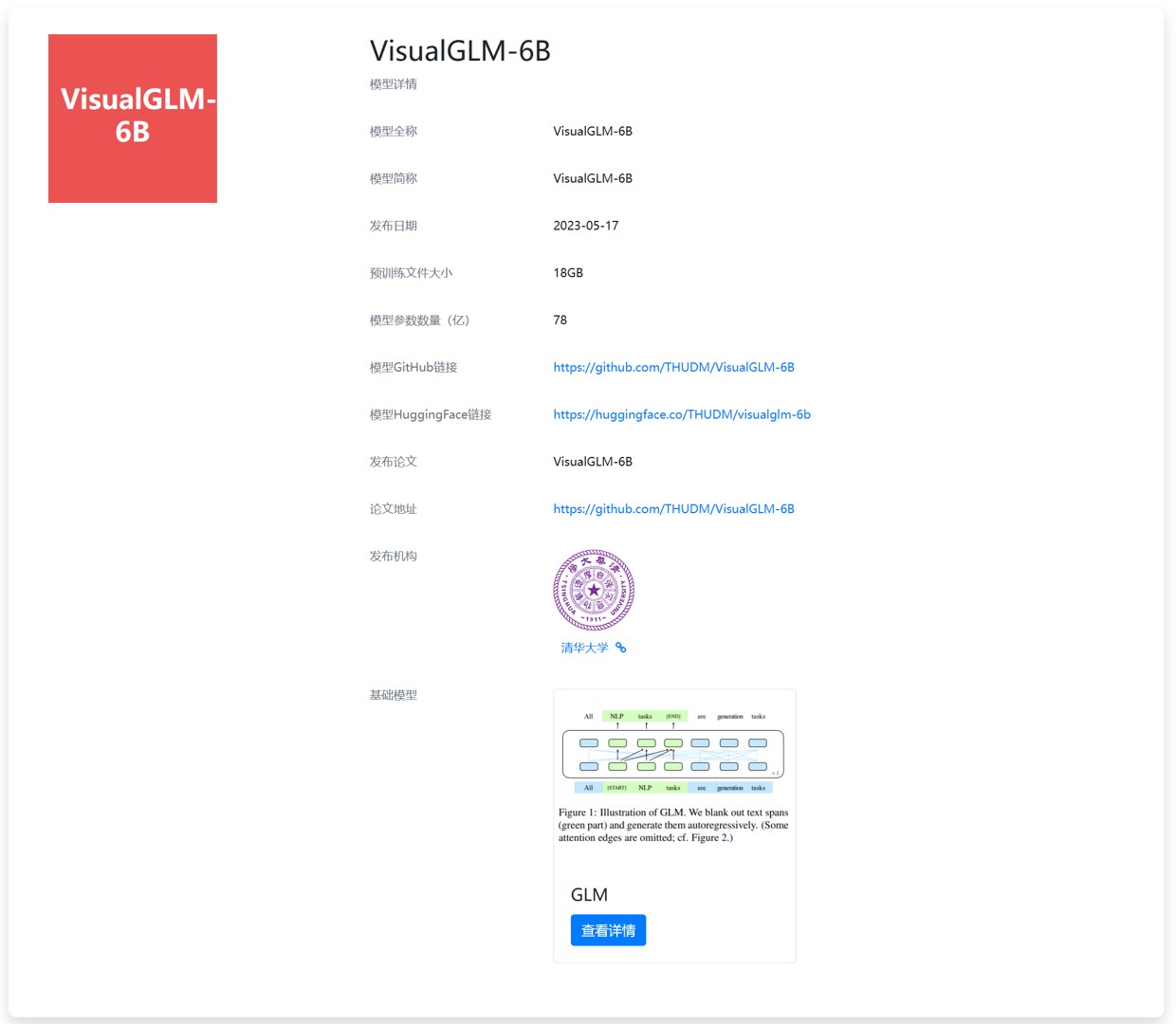
今天,THUDM开源了ChatGLM-6B的多模态升级版模型VisualGLM-6B。这是一个多模态对话语言模型,支持图像、中文和英文。VisualGLM-6B的特别之处在于它能够整合视觉和语言信息。可以用来理解图片,解析图片内容。
如今,不支持https的网站基本都无法访问,https网站需要在服务端保存ssl证书才可以建立。这个原理本文不多说。目前,各大云服务厂商也提供ssl证书的发放和管理,但都是收费的。对于个人网站来说,基于第三方的服务申请免费证书其实是合适的。但是,国内申请证书并不好用。本文主要记录一个最简单的免费证书申请安装方法。
ChatGLM-6B是清华大学知识工程和数据挖掘小组发布的一个类似ChatGPT的开源对话机器人,由于该模型是经过约1T标识符的中英文训练,且大部分都是中文,因此十分适合国内使用。本文将详细记录如何在Windows环境下基于GPU和CPU两种方式部署使用ChatGLM-6B,并说明如何规避其中的问题。