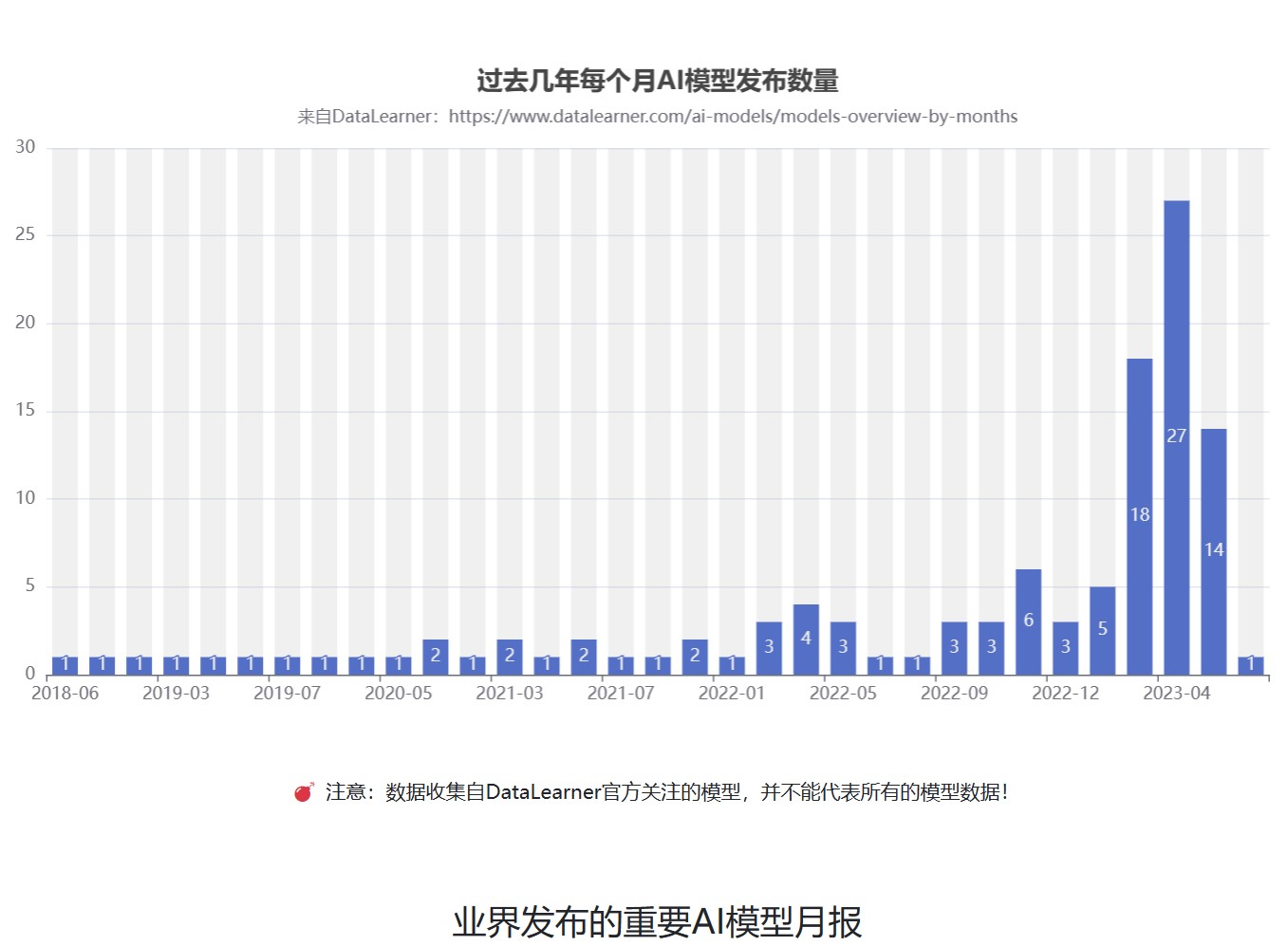
目前业界支持中文大语言模型开源和商用许可协议总结
目前,业界开源的大语言模型越来越多,性能也越来越强大。然而,这些开源模型大多数由国外的机构贡献,对于英文的支持没有任何问题。但是,对于中文的支持则是有好有坏。本文将基于主流的开源大模型进行分析,介绍当前支持中文的开源大模型,并对其使用方式和主要能力进行总结。
探索人工智能与大模型最新资讯与技术博客,涵盖机器学习、深度学习、自然语言处理等领域的原创技术文章与实践案例。
目前,业界开源的大语言模型越来越多,性能也越来越强大。然而,这些开源模型大多数由国外的机构贡献,对于英文的支持没有任何问题。但是,对于中文的支持则是有好有坏。本文将基于主流的开源大模型进行分析,介绍当前支持中文的开源大模型,并对其使用方式和主要能力进行总结。
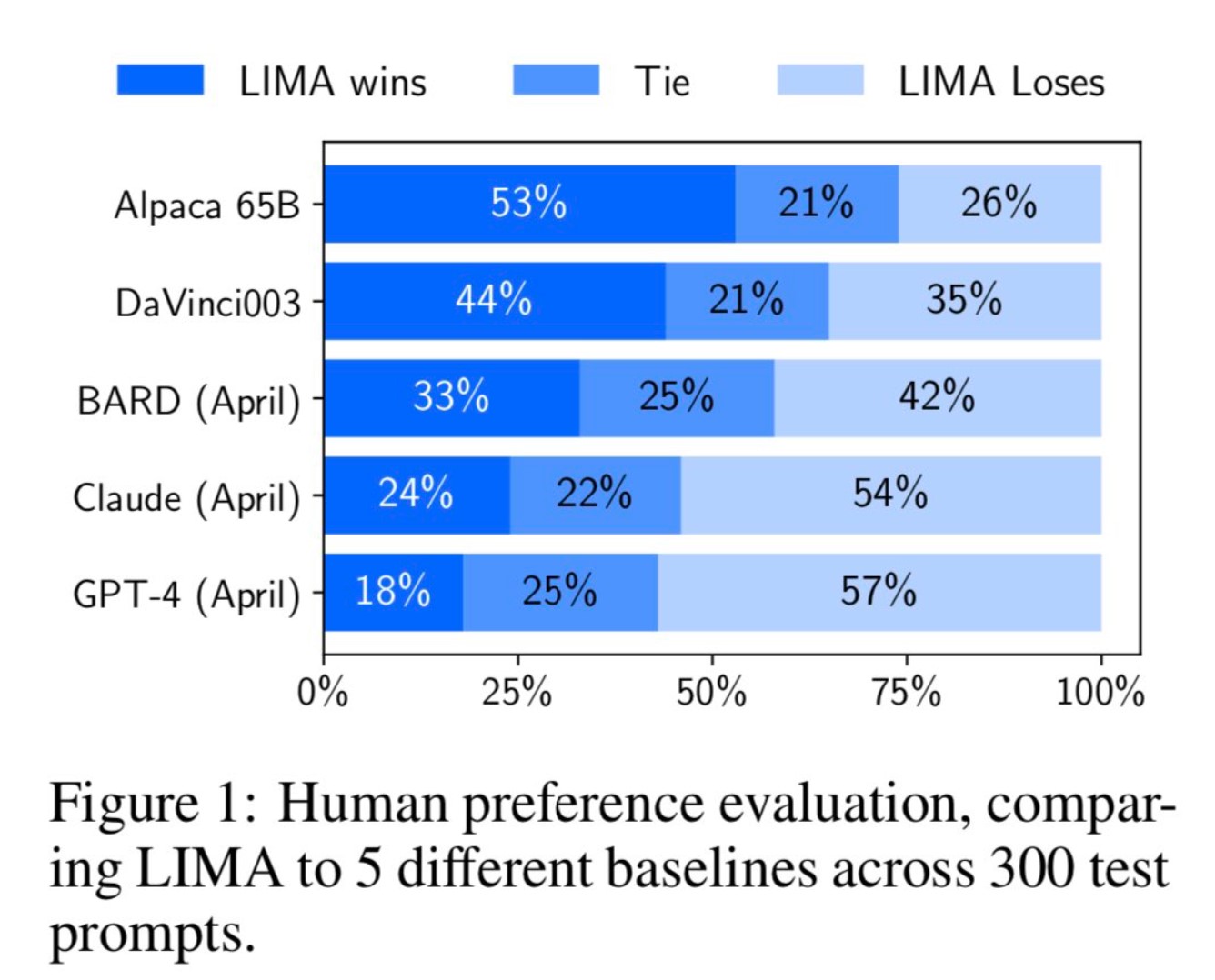
MetaAI最近公布了一个新的大语言模型预训练方法(LIMA: Less Is More for Alignment)。它最大的特点是不使用ChatGPT那样的(Reinforcement Learning from Human Feedback,RLHF)方法进行对齐训练。而是利用1000个精选的prompts与response来对模型进行微调,但却表现出了极其强大的性能。能够从训练数据中的少数几个示例中学习遵循特定的响应格式,包括从规划旅行行程到推测关于交替历史的复杂查询。
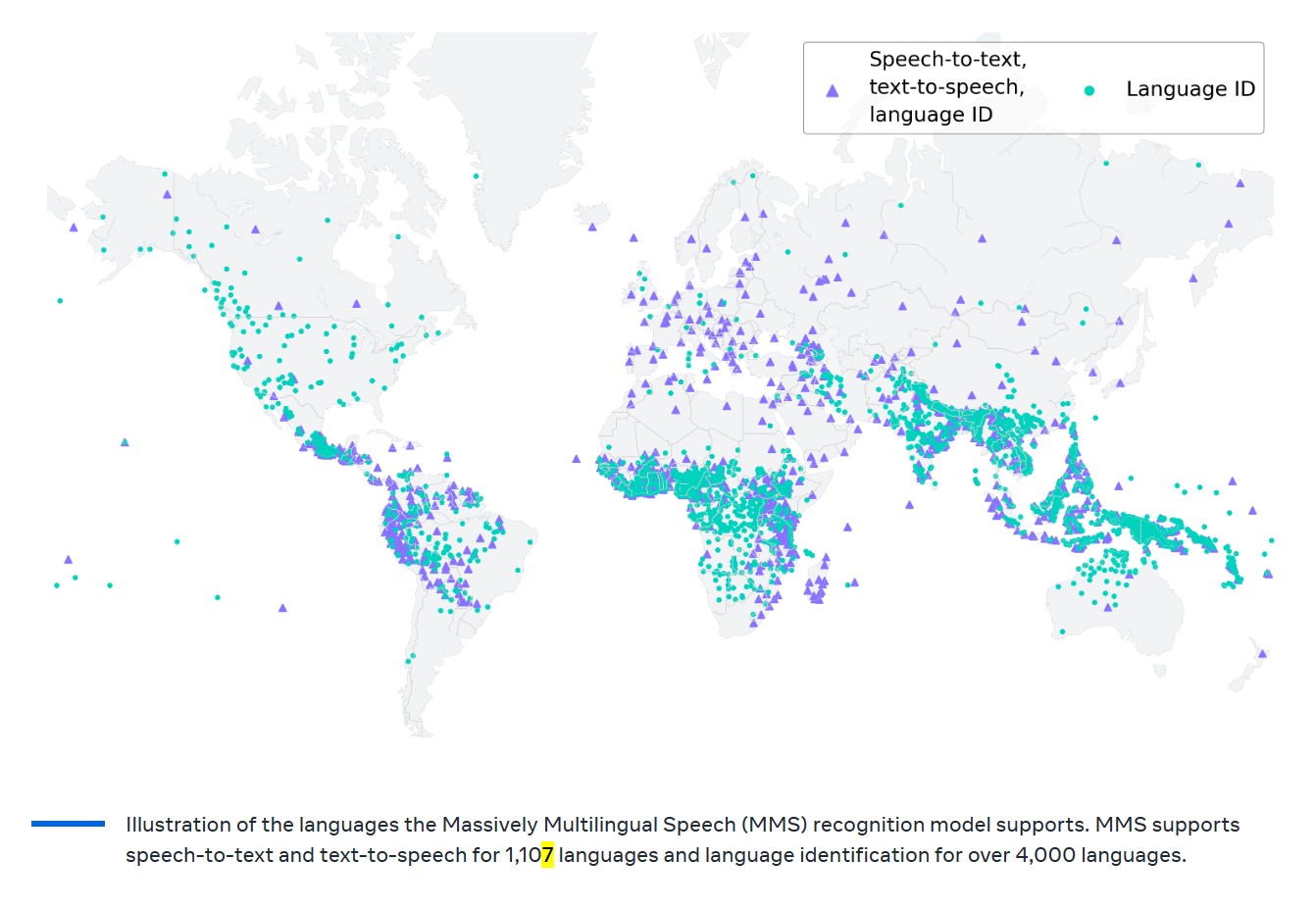
今天,Meta的首席AI科学家Yann LeCun在推特上宣布了MetaAI的最新研究成果:MMS,一个支持1107种语言的自动语音识别模型和语音合成模型,该模型自动语音识别的单词错误率只有OpenAI开源的Whisper的一半!但是支持的语言却有1107种,是Whisper的11倍!代码与预训练结果已开源,不过不可以商用哦~

虽然LLM在很多任务上很好用,但是实际应用中我们常见的文本分类、文本标注等工作目前却依然缺少一个可以利用LLM能力的好方法。LLM的强大并没有在工程落地上比肩传统的机器学习处理框架。上周,一个叫Scikit-LLM新的开源项目发布,将传统优秀的Scikit-learn框架与LLM结合,带来了LLM落地的新方法。
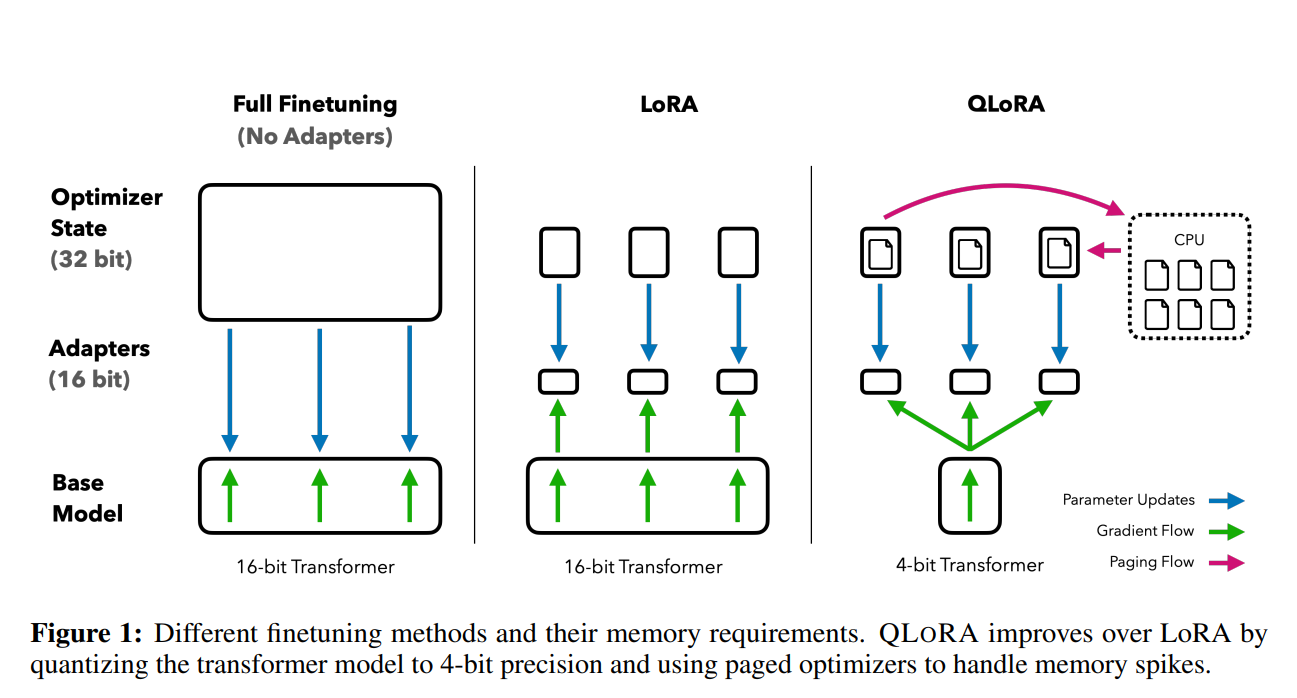
前段时间,康奈尔大学开源了LLMTune框架(https://www.datalearner.com/blog/1051684078977779 ),这是一个可以在48G显存的显卡上微调650亿参数的LLaMA模型的框架,不过它们采用的方法是将650亿参数的LLaMA模型进行4bit量化之后进行微调的。今天华盛顿大学的NLP小组则提出了QLoRA方法,依然是支持在48G显存的显卡上微调650亿参数的LLaMA模型,不过根据论文的描述,基于QLoRA方法微调的模型结果性能基本没有损失!

昨天,HuggingFace的大语言模型排行榜上突然出现了一个评分超过LLaMA-65B的大语言模型:Falcon-40B,引起了广泛的关注。本文将简要的介绍一下这个模型。截止2023年5月27日,Falcon-40B模型(400亿参数)在推理、理解等4项Open LLM Leaderloard任务上评价得分第一,超过了之前最强大的LLaMA-65B模型。
今天,一位年仅20岁的小哥willdepue 开源了230万arXiv论文的标题和摘要的embedding向量数据集,完全开源。该数据集包含截止2023年5月4日的所有arXiv上的论文标题和摘要的embedding结果,使用的是开源的Instructor XL抽取。未来将开放更多其它相关数据的embedding结果
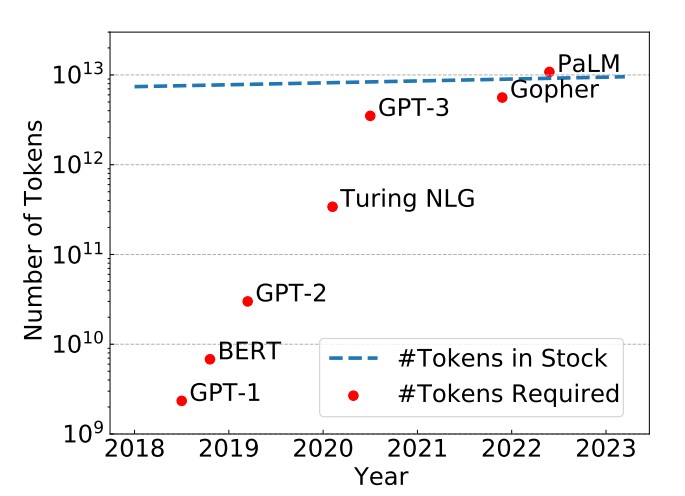
epoch是一个重要的深度学习概念,它指的是模型训练过程中完成的一次全体训练样本的全部训练迭代。然而,在LLM时代,很多模型的epoch只有1次或者几次。这似乎与我们之前理解的模型训练充分有不一致。那么,为什么这些大语言模型的epoch次数都很少。如果我们自己训练大语言模型,那么epoch次数设置为1是否足够,我们是否需要更多的训练?
5月27日,OpenBMB发布了一个最高有100亿参数规模的开源大语言模型CPM-BEE,OpenBMB是清华大学NLP实验室联合智源研究院成立的一个开源组织。该模型针对高质量中文数据集做了训练优化,支持中英文。根据官方的测试结果,其英文测试水平约等于LLaMA-13B,中文评测结果优秀。

今天,吴恩达在推特上宣布和OpenAI、LangChain以及Lamini三家公司共同推出了3门短视频课程,分别是《使用ChatGPT API构建系统》、《基于LangChain的大语言模型应用与开发》和《Diffusion模型是如何工作的》。三门课程都是1个小时的短视频课程,而且配有详细的Jupyter Notebook使用方法。

前段时间,OpenAI的CEO Sam Altman与二十多位开发者一起聊了很多关于OpenAI的API和产品的规划问题。Sam Altman透露了一些非常重要的OpenAI的发展方向,包括GPT产品功能的未来规划等。目前这份原始博客内容已经应OpenAI的要求被删除,这里我们简单总结一下这些内容。

RedPajama模型是TOGETHER发布的一个开源可商用的大模型。2023年6月6日,TOGETHER在官方宣布该模型完成训练,经过测试,该模型目前超过所有7B规模的大模型,比LLaMA-7B和Falcon-7B的效果还要好!

大模型微调依然是针对大量私有数据或者特定领域不可缺少的方法。就在前不久,LightningAI发布了一个轻量级大模型微调库Lit-Parrot,仅需一行代码即可微调当前开源大模型。
大语言模型训练的一个重要前提就是高质量超大规模的数据集。为了促进开源大模型生态的发展,Cerebras新发布了一个超大规模的文本数据集SlimPajama,SlimPajama可以作为大语言模型的训练数据集,具有很高的质量。除了SlimPajama数据集外,Cerebras此次还开源了处理原始数据的脚本,包括去重和预处理部分。官方认为,这是目前第一个开源处理万亿规模数据集的清理和MinHashLSH去重工具。

BAAI全称北京智源人工智能研究院(Beijing Academy of Artificial Intelligence),是国内非常重要的一个人工智能研究机构。此前发布了悟道系列数据集和大模型。在最近,他们开源了一个全新的国产开源大语言模型Aquila系列模型。该模型基于大量的中英文数据集训练,是一个完全开源可商用国产大语言模型。
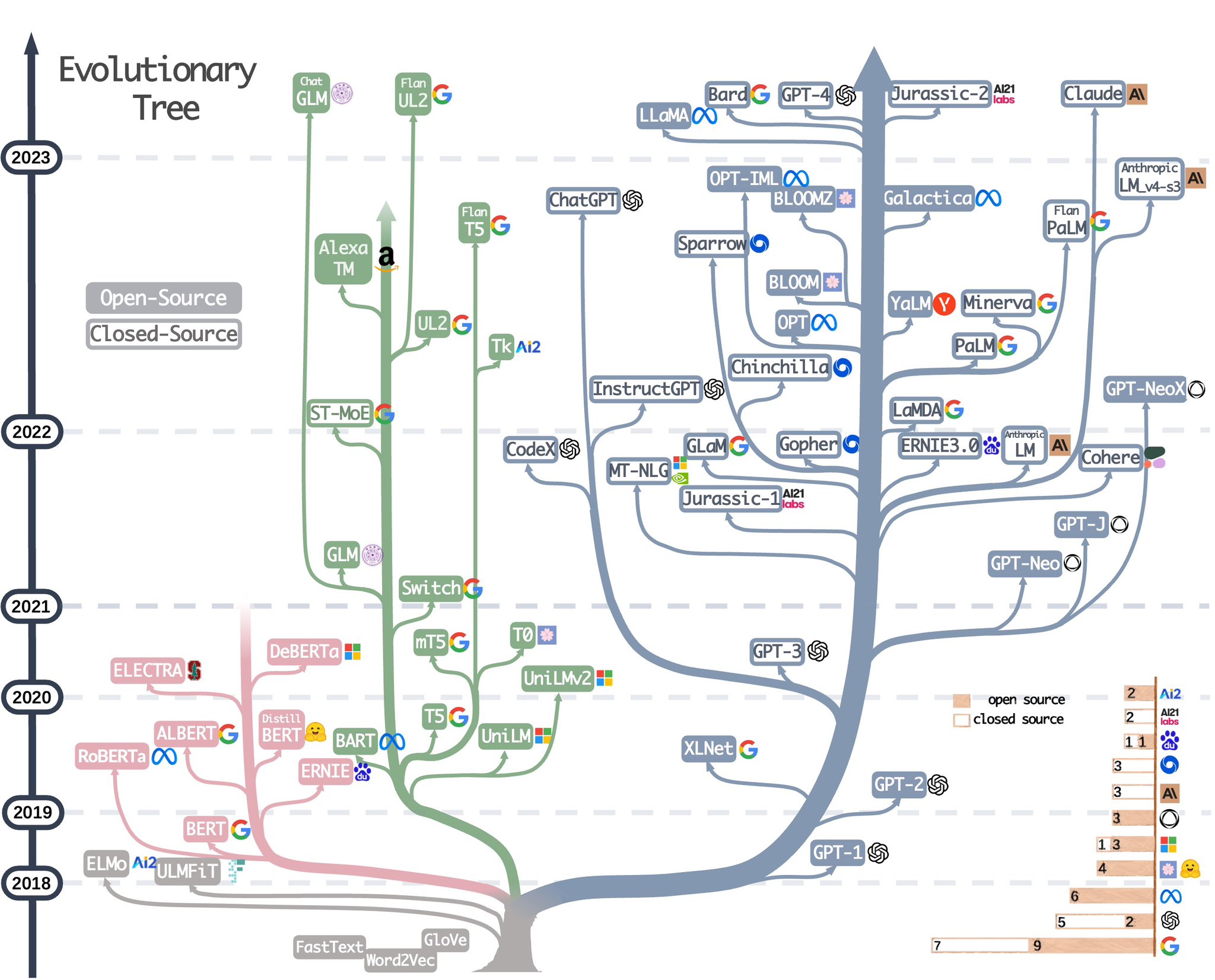
4月26日,亚马逊联合其它高校科研人员发表了一篇关于如何使用ChatGPT完成下游论文。里面使用了一个非常直观明了的大语言模型进化图总结了目前当前大语言模型的技术架构分类和开源现状,十分受欢迎。因此,4月30日,作者再次更新这幅图,增加了更多的大语言模型。
今天,MetaAI发布了一个新的语音处理领域的生成式大模型Voicebox,可以像GPT那样用生成式的方式处理语音(speech)数据的相关任务,包括语音编辑、跨风格语音生成等语音数据处理相关的很多任务。这可能就是语音处理领域的GPT时刻!
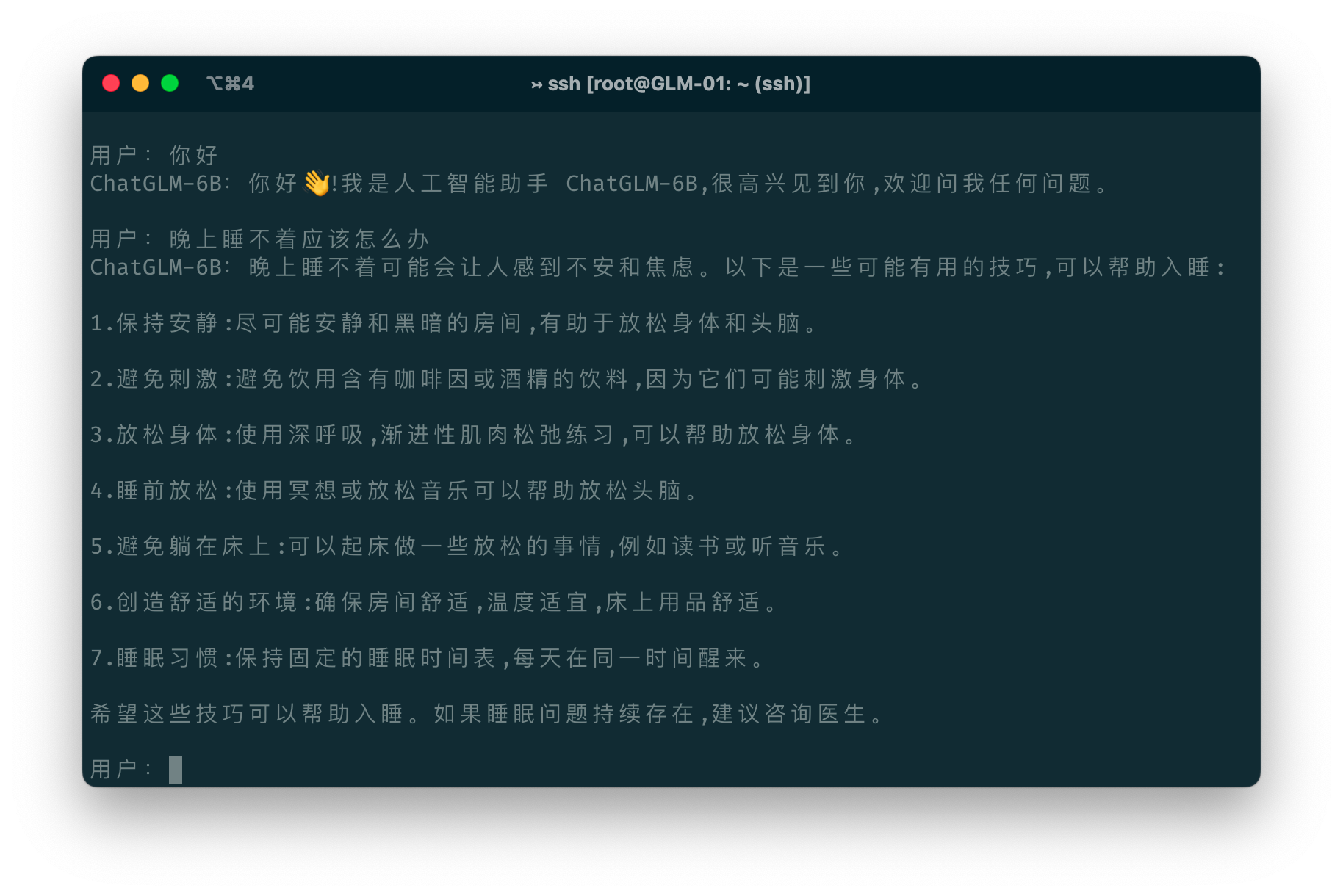
ChatGLM-6B是国产开源大模型领域最强大的的大语言模型。因其优秀的效果和较低的资源占用在国内引起了很多的关注。2023年6月25日,清华大学KEG和数据挖掘小组(THUDM)发布了第二代ChatGLM2-6B。
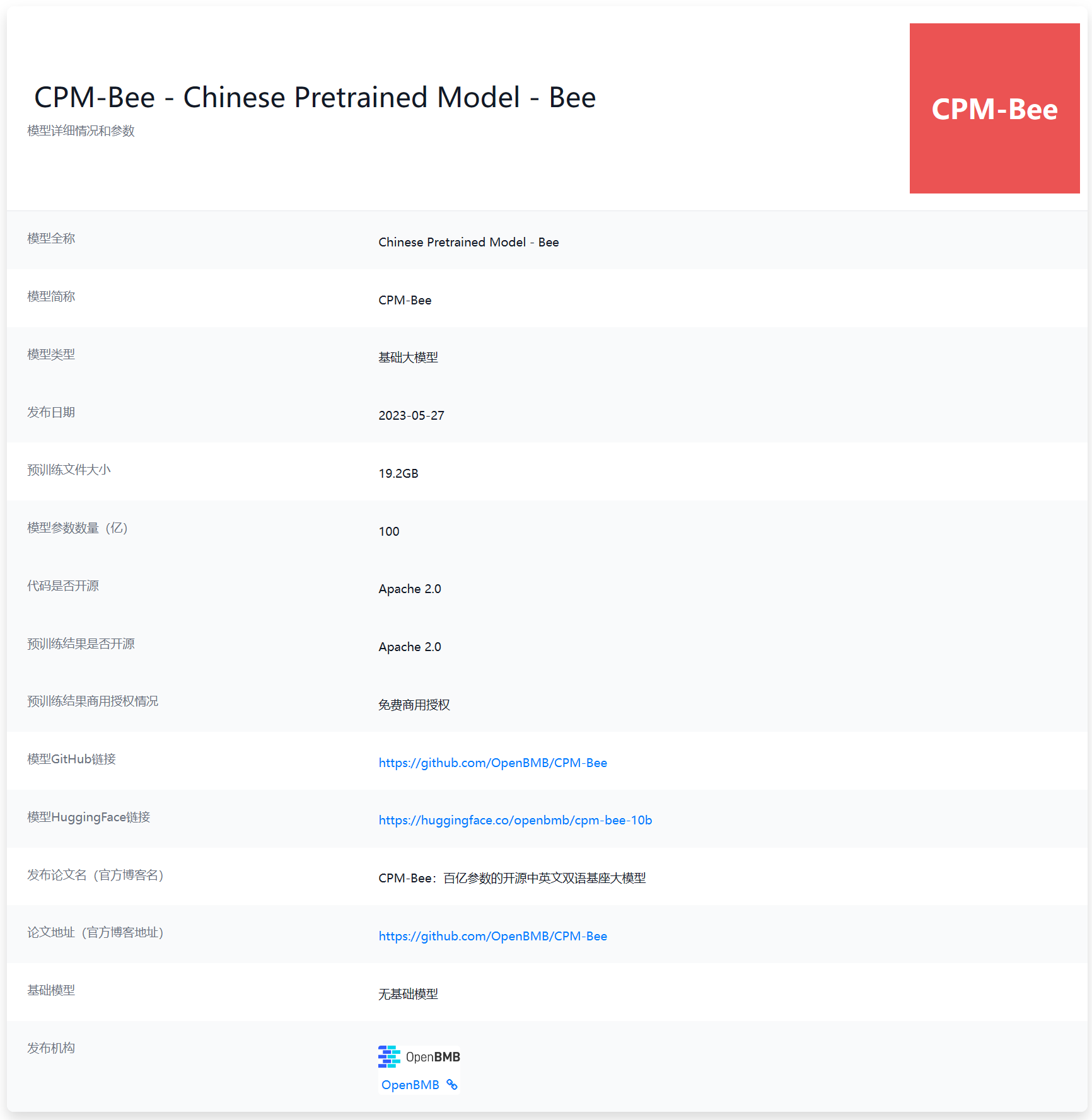
最近几个月,国产大语言模型进步十分迅速。不过,大多数企业发布的大模型均为商业产品,少数开源的LLM则有较高的商业授权费用或者商用限制。对于希望使用LLM能力的中小企业以及个人来说都不是很合适。本次给大家介绍的是目前国产开源领域里面一个十分优秀且具有潜力的大语言模型CPM-Bee 10B。该模型来自清华大学NLP实验室,参数规模100亿,最重要的是对个人和企业用户均提供免费商用授权,十分友好!

吴恩达创办的DeepLearning.AI一直在提供各种面向AI领域的精品课程。在上个月,他们发布的四门AI短课程(包含了ChatGPT的使用、ChatGPT Prompt工程技术、面向LLM应用的LangChain教程和Diffusion工作原理)受到了广泛的欢迎。今天,吴恩达宣布与AWS的研究人员一起推出了全新的长课程《Generative AI with Large Language Models》,这门课程的主要内容是讲授生成式AI的工作原理以及如何部署面向真实世界应用的生成式AI模型。
Salesforce是全球最大的CRM企业,但是在开源大模型领域,它也是一个不可忽视的力量。今天,Salesforce宣布开源全新的XGen-7B模型,是一个同时在文本理解和代码补全任务上都表现很好的模型,在MMLU任务和代码生成任务上都表现十分优秀。最重要的是,它的2个基座模型XGen-7B-4K-Base和XGen-7B-8K-Base都是完全开源可商用的大模型。
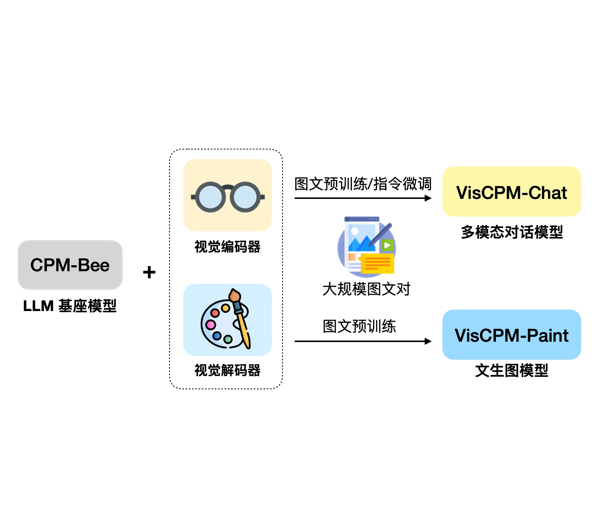
大模型的发展正在从单纯的语言模型向多模态大模型快速发展。尽管GPT-4号称也是一个多模态大模型,但是受限于GPU资源,GPT-4没有开放任何多模态的能力(参考:https://www.datalearner.com/blog/1051685866651273 )。目前大家所能接触到的多模态大模型很少。今天,清华大学NLP小组带来了新的选择,发布了VisCPM系列多模态大模型。VisCPM系列包含2类多模态大模型,分别针对多模态对话和文本生成图片进行优化。

目前开源领域已经有一些模型宣称支持了8K甚至是更长的上下文。那么这些模型在长上下文的支持上表现到底如何?最近LM-SYS发布了LongChat-7B和LangChat-13B模型,最高支持16K的上下文输入。为了评估这两个模型在长上下文的表现,他们对很多模型在长上下文的表现做了评测,让我们看看这些模型的表现到底怎么样。
大语言模型的训练和微调的硬件资源要求很高。现行主流的大模型训练硬件一般采用英特尔的CPU+英伟达的GPU进行。主要原因在于二者提供了符合大模型训练所需的计算架构和底层的加速库。但是,最近苹果M2 Ultra和AMD的显卡进展让我们看到了一些新的希望。