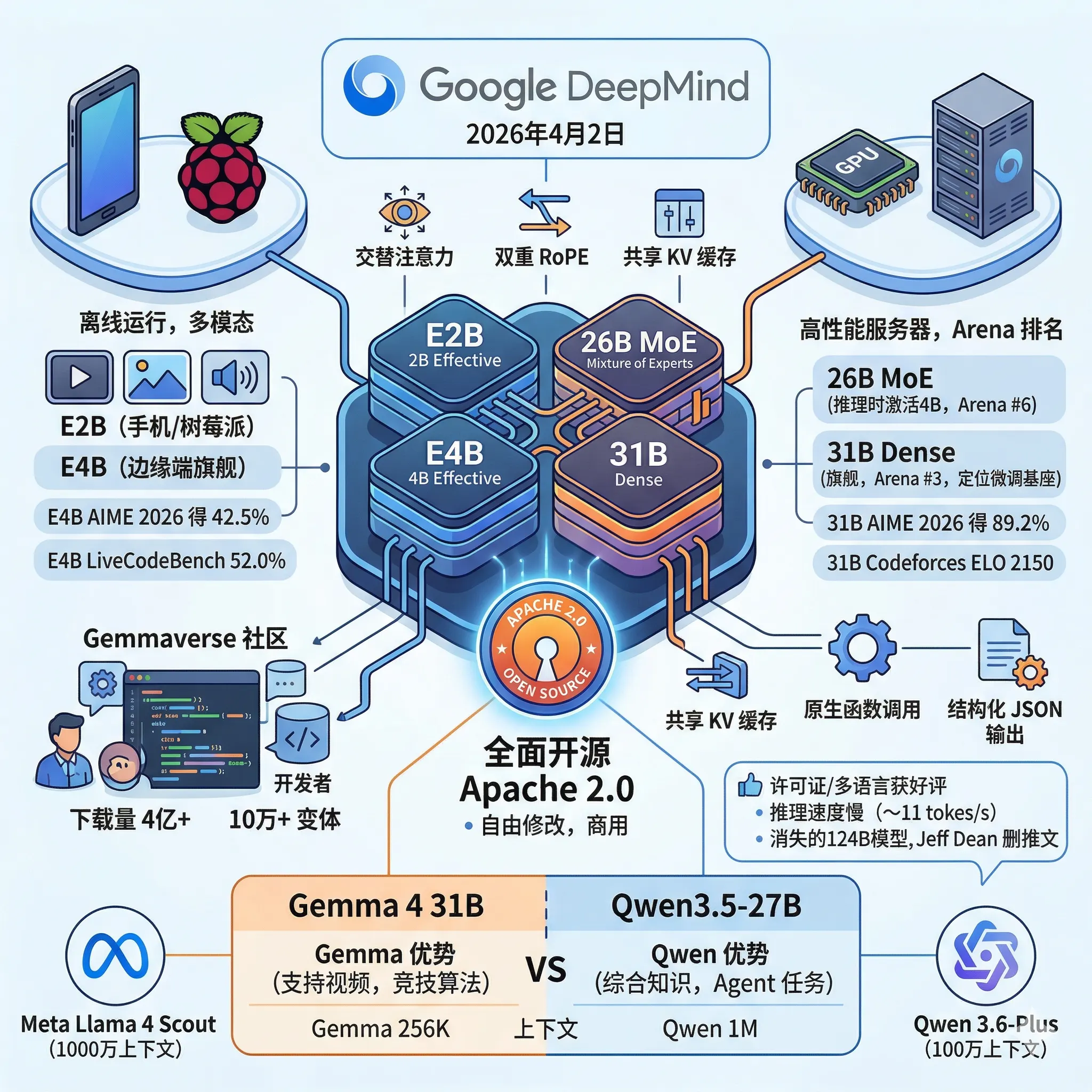
Gemma 4 全面解读:首个 Apache 2.0 的 Google 开源模型,实测数学推理优秀,实测部分评测甚至好于 Qwen3.5-27B
2026年4月2日,Google DeepMind 正式发布了 Gemma 4 系列模型。自2024年首代 Gemma 发布以来,开发者已经累计下载超过4亿次,并在此基础上衍生出超过10万个变体版本,形成了所谓的"Gemmaverse"社区生态。这次的 Gemma 4,Google 不只是做了常规的性能升级,而是在许可证、模型架构和部署覆盖范围上同时迈出了一大步。