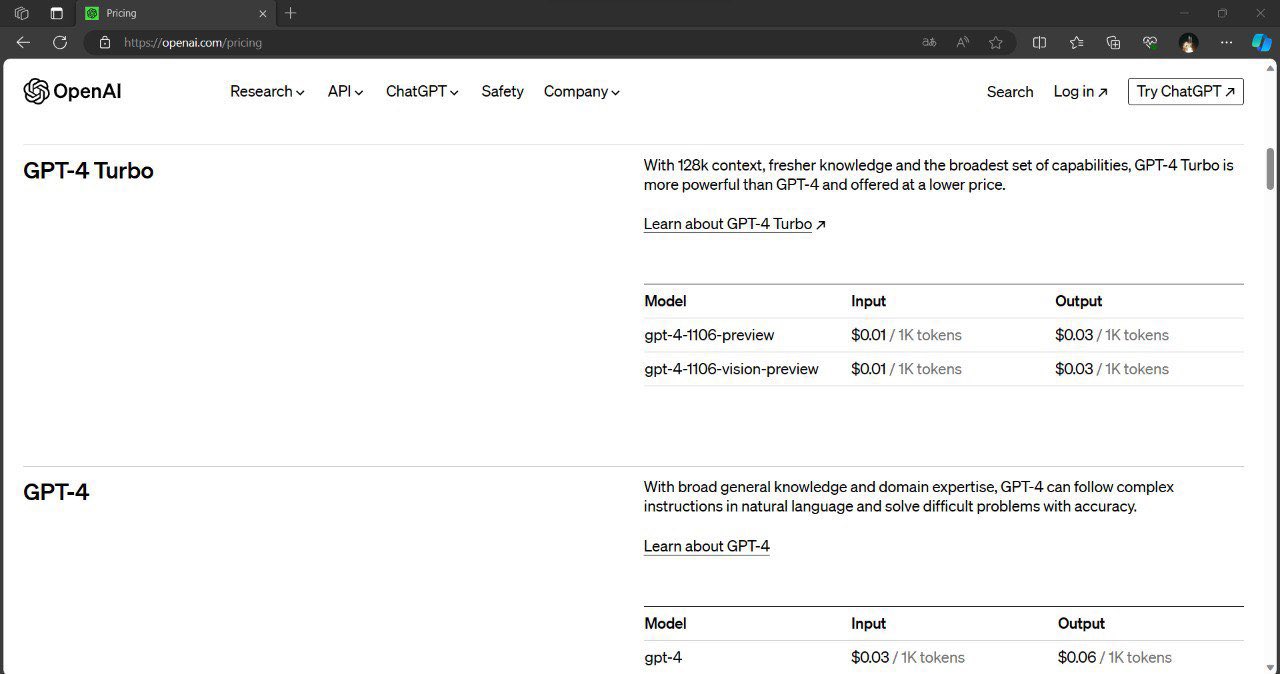
OpenAI再度泄露重磅更新,GPT-4即将发布128K的超长上下文版本以及多模态版本,价格下降一大半!
就在刚刚,有网友发现OpenAI的官方的文档接口更新中增加了128K的超长上下文版本,命名为GPT-4-128K-Turbo!
探索人工智能与大模型最新资讯与技术博客,涵盖机器学习、深度学习、自然语言处理等领域的原创技术文章与实践案例。
就在刚刚,有网友发现OpenAI的官方的文档接口更新中增加了128K的超长上下文版本,命名为GPT-4-128K-Turbo!

华为盘古大模型一直是国内大模型领域比较早的先行者,不过由于该模型并不针对个人开放,因此很少有人可以体验到该模型的效果。但是,盘古大模型一直在不断发展。2023年7月27日,华为发布最新的论文,展示了新一代盘古大模型的编程能力。该模型名字为PanGu-Coder2,论文的数据显示该模型目前超越所有开源编程大模型的效果,也超过GPT-3.5,接近GPT-4。
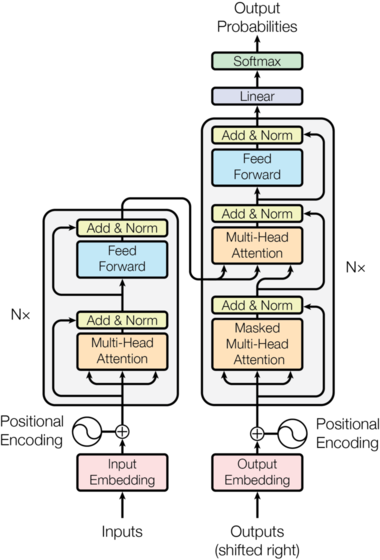
The Annotated Transfomer是哈佛大学的研究人员于2018年发布的Transformer新手入门教程。这个教程从最基础的理论开始,手把手教你按照最简单的python代码实现Transformer,一经推出就广受好评。2022年,这个入门教程有了新的版本。

LangChain是当前大模型应用开发领域里面最火热的框架。由于其提供了丰富的数据访问接口、各种大模型的交互接口以及很多构造大模型应用所需要的方法与实践工具,受到了很多人的关注。然而,今天Hacker News上的一位开发者直接提出LangChain是一个无用的框架,引起了很多人的共鸣。很多人都表示,在实际开发中,LangChain有很多问题,可能并不适合用来做大模型应用开发。
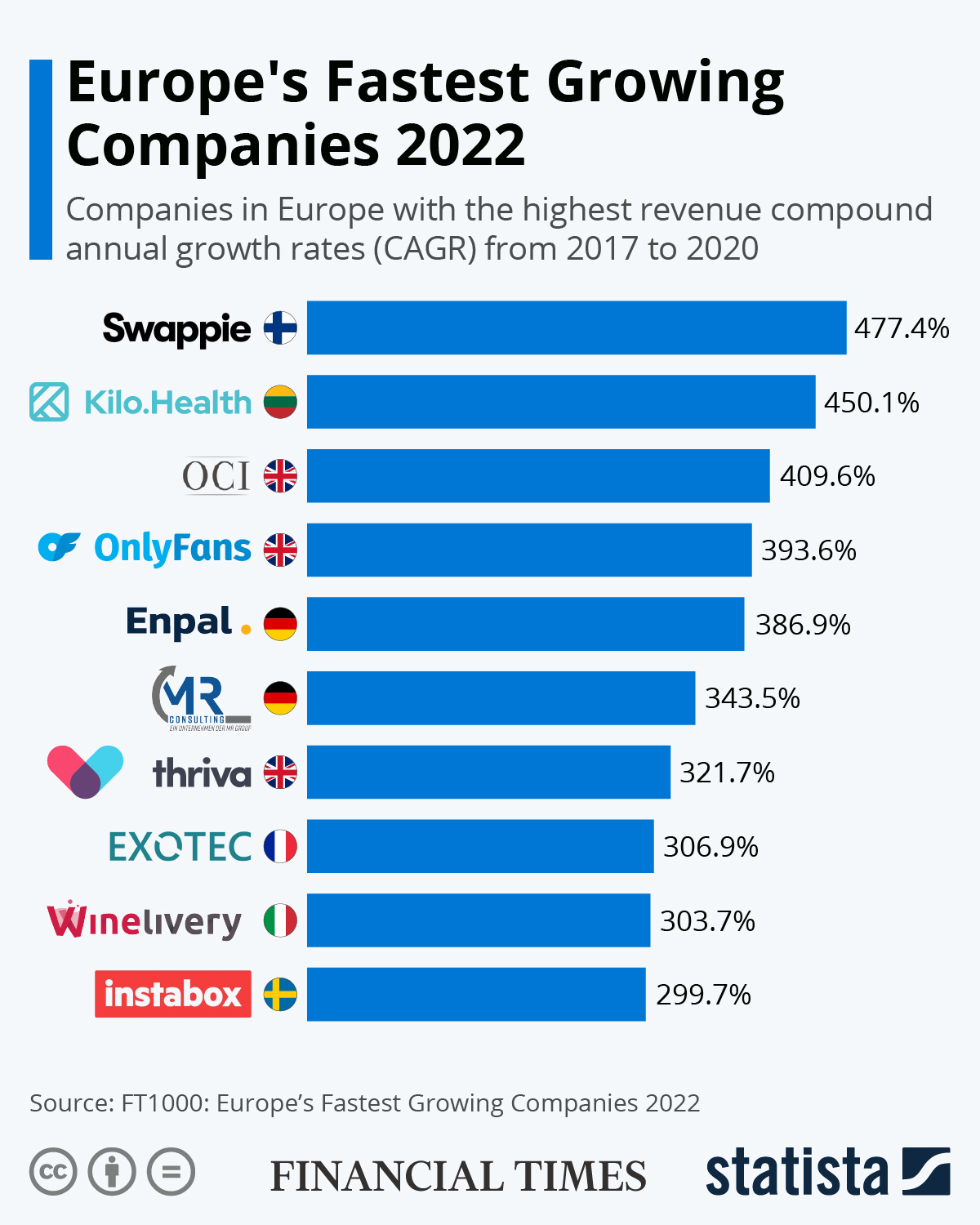
FT1000是金融时报评选的欧洲增长速度最快的前1000个公司,这个名单可以看出来过去几年欧洲哪些企业增长较快,它们在哪些行业经营等。2022年的榜单也刚刚发布,让我们一睹为快。

MLPerf™是MLCommons发布的一个用来测试AI相关软硬件性能的基准测试工具。2021年12月1日, Training v1.1的结果发布,这个结果不仅展示了最新的AI相关软硬件的进展,也有一个新的现象,就是AI训练正在超越摩尔定律。本文将简要解读一下相关数据。
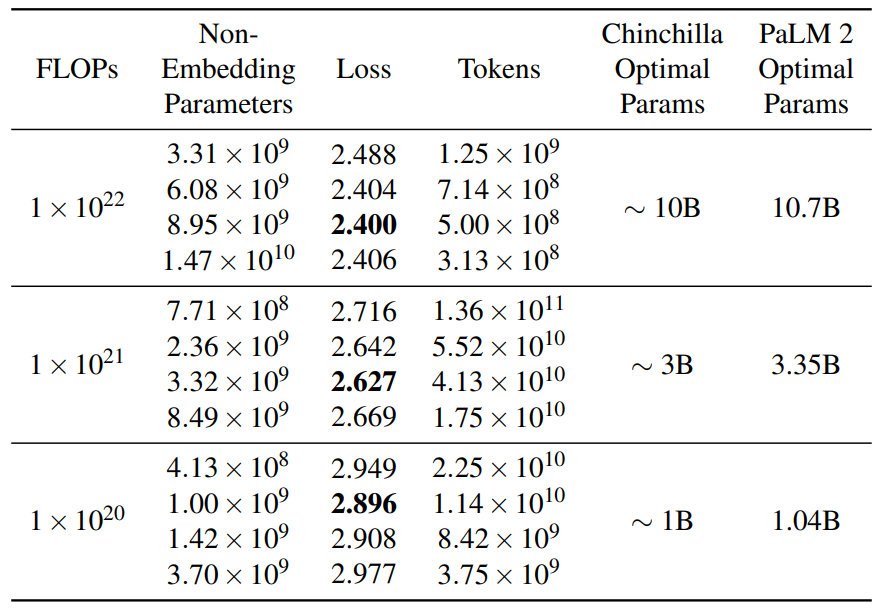
作为PaLM的继任者,PaLM2的发布被谷歌寄予厚望。与OpenAI类似,谷歌官方没有透露很多关于模型的技术细节,虽然发布了一个92页的技术报告,但是,正文内容仅仅27页,引用和作者14页,剩余51页都是展示大量的测试结果。而前面的27页内容中也没有过多的细节描述。尽管如此,这里面依然有几个十分重要的结论供大家参考。
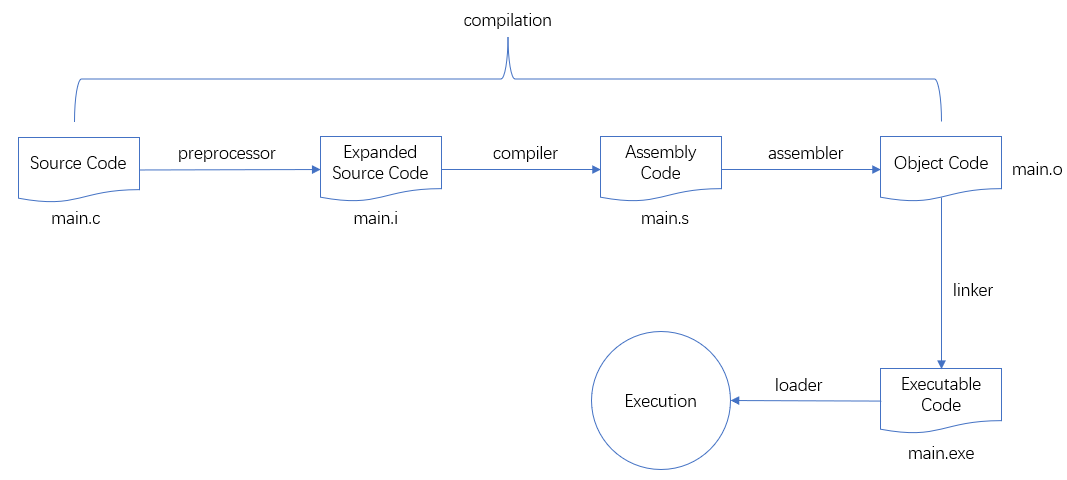
C/C++的源程序文件都是程序员按照相关语法和规则编写的。但是这样的程序文件并不能直接被硬件识别和执行。本文将简要描述C/C++的源代码是如何经过转化并最终转变成可以被硬件识别执行的二进制文件的。
今天,MetaAI发布了一个新的语音处理领域的生成式大模型Voicebox,可以像GPT那样用生成式的方式处理语音(speech)数据的相关任务,包括语音编辑、跨风格语音生成等语音数据处理相关的很多任务。这可能就是语音处理领域的GPT时刻!

GPU Utils最近总结了一个关于英伟达H100显卡在AI训练中的应用文章。里面透露总结了一些当前的主流厂商拥有的显卡数量以及一些模型训练所需的显卡数。文章主要描述的是H1000的供应与需求,也包含H100的性能描述,本文主要总结一下里面提到的显卡数相关统计供大家参考。
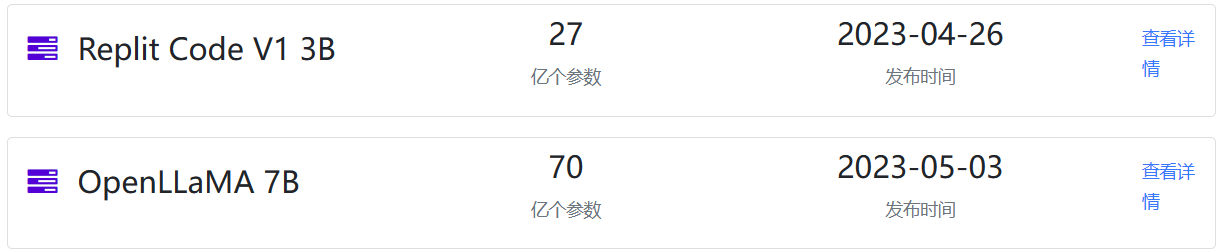
五一长假最后一天,AI技术的发展依然火热。今天有2个重磅的开源模型发布:一个是前几天提到的Replit的代码补全大模型Replit Code V1 3B,一个是UC Berkeley的博士生Hao Liu发起的一个开源LLaMA复刻项目。

吴恩达创办的DeepLearning.AI一直在提供各种面向AI领域的精品课程。在上个月,他们发布的四门AI短课程(包含了ChatGPT的使用、ChatGPT Prompt工程技术、面向LLM应用的LangChain教程和Diffusion工作原理)受到了广泛的欢迎。今天,吴恩达宣布与AWS的研究人员一起推出了全新的长课程《Generative AI with Large Language Models》,这门课程的主要内容是讲授生成式AI的工作原理以及如何部署面向真实世界应用的生成式AI模型。


Allen Institute for AI简称AI2,是2014年成立的一个非营利性研究组织,其创办者是之前的微软联合创始人Paul G. Allen。目前该组织主导了几个非常大的项目,希望借助AI来推动科学、医学等领域的进步。此前也开源过大模型OLMo等。这次是该组织第一份发布AI数据集相关的项目,名称位Dolma,是一个包含了3万亿tokens的数据集,目前第一版本仅仅包含英文。
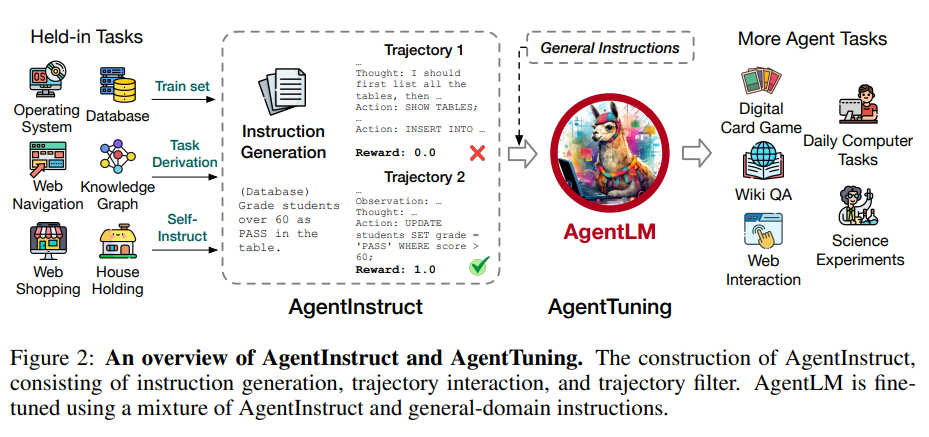
尽管开源的大语言模型发展非常迅速,但是,在以大语言模型作为核心的新一代AI Agent解决方案上,开源大语言模型比商业模型表现要明显地差。为了提高大语言模型作为AI Agent的表现和能力,清华大学和智谱AI推出了一种新的方案,AgentTuning,可以将有效增强开源大语言模型作为AI Agent的能力。
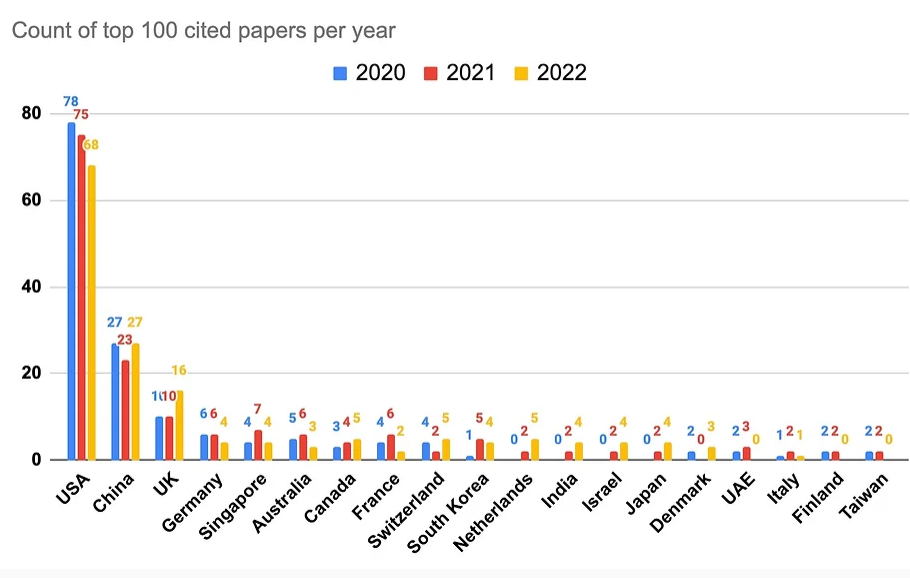
尽管AI领域在工业界发展迅速,企业研究机构在拼命的开发相关的产品以推动各自业务的发展。但是他们也在科研领域不断贡献大量的AI论文。Zeta Alpha的一篇博客分析了2022年发表的被引用最多的100篇AI论文,给大家提供一个洞察思路。

SAM全称是Segment Anything Model,由MetaAI最新发布的一个图像分割领域的预训练模型。该模型十分强大,并且有类似GPT那种基于Prompt的工作能力,在图像分割任务上展示了强大的能力!此外,该模型从数据集到训练代码和预训练结果完全开源!真Open的AI!

BAAI全称北京智源人工智能研究院(Beijing Academy of Artificial Intelligence),是国内非常重要的一个人工智能研究机构。此前发布了悟道系列数据集和大模型。在最近,他们开源了一个全新的国产开源大语言模型Aquila系列模型。该模型基于大量的中英文数据集训练,是一个完全开源可商用国产大语言模型。

研究生级别的 **Google 防查找问答基准测试**(即Graduate-Level Google-Proof Q&A Benchmark,简称 GPQA)是大型语言模型(LLM)面临的最具挑战性的评估之一。GPQA 旨在推动人工智能能力的极限,提供一个严格的测试平台,不仅评估模型的事实记忆能力,还考察其在专业科学领域的深度推理和理解能力。本篇博文将客观介绍 GPQA,涵盖它的起源、目的、组成部分,以及领先的大型语言模型在这个高要求基准测试中的表现。
在Python工程中,我们经常可以看到带有“\_\_init\_\_.py”文件的目录,在PyCharm中,带有这个文件的目录被认为是Python的包目录,与目录的图标有不一样的显示。那么这个文件的作用是什么,我们平时如何使用呢,这篇文章将解释这个问题。

当前的大模型的参数规模较大,数以千亿的参数导致了它们的预训练结果文件都在几十GB甚至是几百GB,这不仅导致其使用成本很高,在不同平台进行交换也非常困难。因此,大模型预训练结果文件的保存格式对于模型的使用和生态的发展来说极其重要。昨天HuggingFace官方宣布将推动GGUF格式的大模型文件在HuggingFace上的使用。