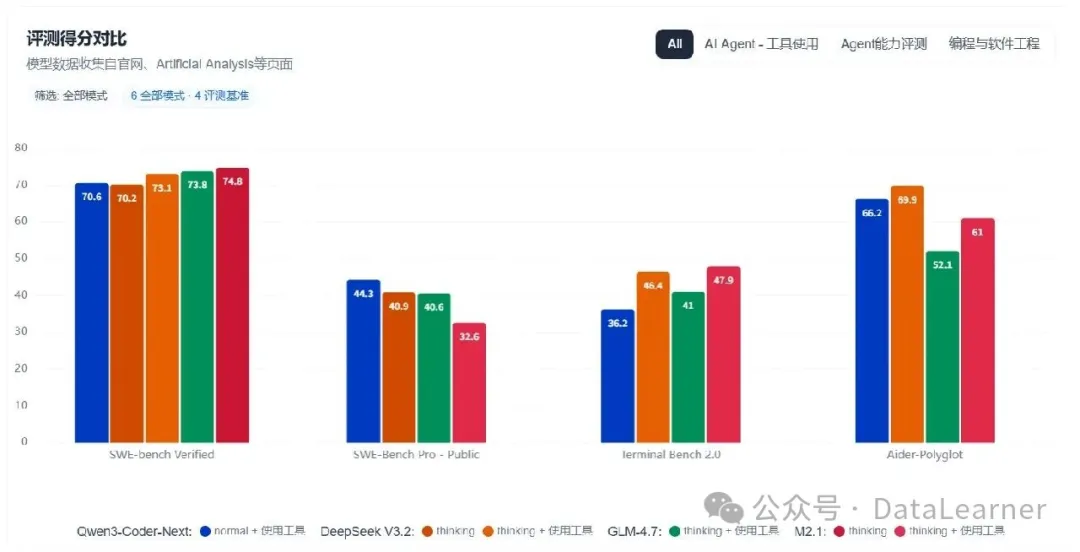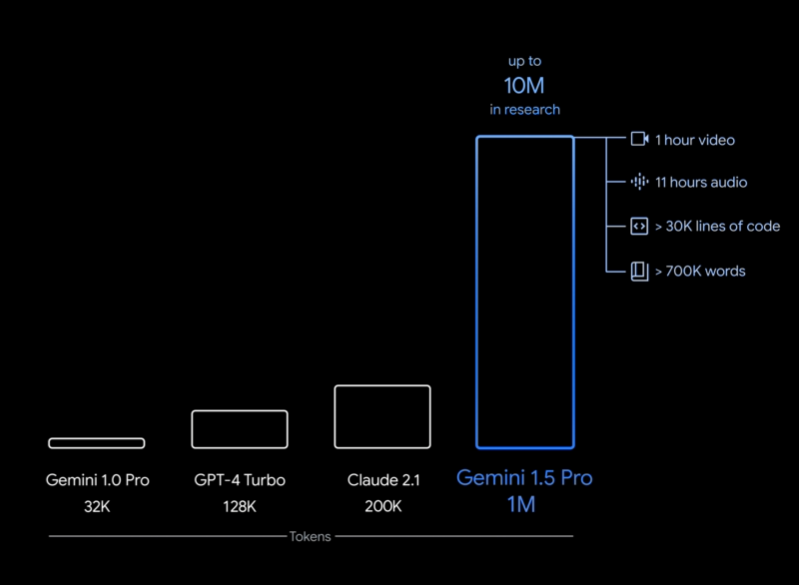
重磅!谷歌宣布发布Gemini 1.5 Pro,距离Gemini发布仅仅一个半月!最高支持1000万上下文长度,GSM8K评测全球第一
在2023年12月份,Google发布了Gemini系列大模型(参考:谷歌发布号称超过GPT-4V的大模型Gemini:4个版本,最大的Gemini的MMLU得分90.04,首次超过90的大模型),包含3个不同参数规模的版本。其中,Gemini Ultra号称在MMLU评测上超过了GPT-4,并且在月初也将Bard更名为Gemini,开放了Gemini Ultra的付费使用。刚刚,Google的CEO劈柴哥宣布发布了Gemini 1.5 Pro,这意味着仅仅一个半月,Gemini有了重大更新。