文本理解与代码补全都很强!Salesforce开源支持8K上下文输入的大语言模型XGen-7B!
Salesforce是全球最大的CRM企业,但是在开源大模型领域,它也是一个不可忽视的力量。今天,Salesforce宣布开源全新的XGen-7B模型,是一个同时在文本理解和代码补全任务上都表现很好的模型,在MMLU任务和代码生成任务上都表现十分优秀。最重要的是,它的2个基座模型XGen-7B-4K-Base和XGen-7B-8K-Base都是完全开源可商用的大模型。
探索人工智能与大模型最新资讯与技术博客,涵盖机器学习、深度学习、自然语言处理等领域的原创技术文章与实践案例。
Salesforce是全球最大的CRM企业,但是在开源大模型领域,它也是一个不可忽视的力量。今天,Salesforce宣布开源全新的XGen-7B模型,是一个同时在文本理解和代码补全任务上都表现很好的模型,在MMLU任务和代码生成任务上都表现十分优秀。最重要的是,它的2个基座模型XGen-7B-4K-Base和XGen-7B-8K-Base都是完全开源可商用的大模型。
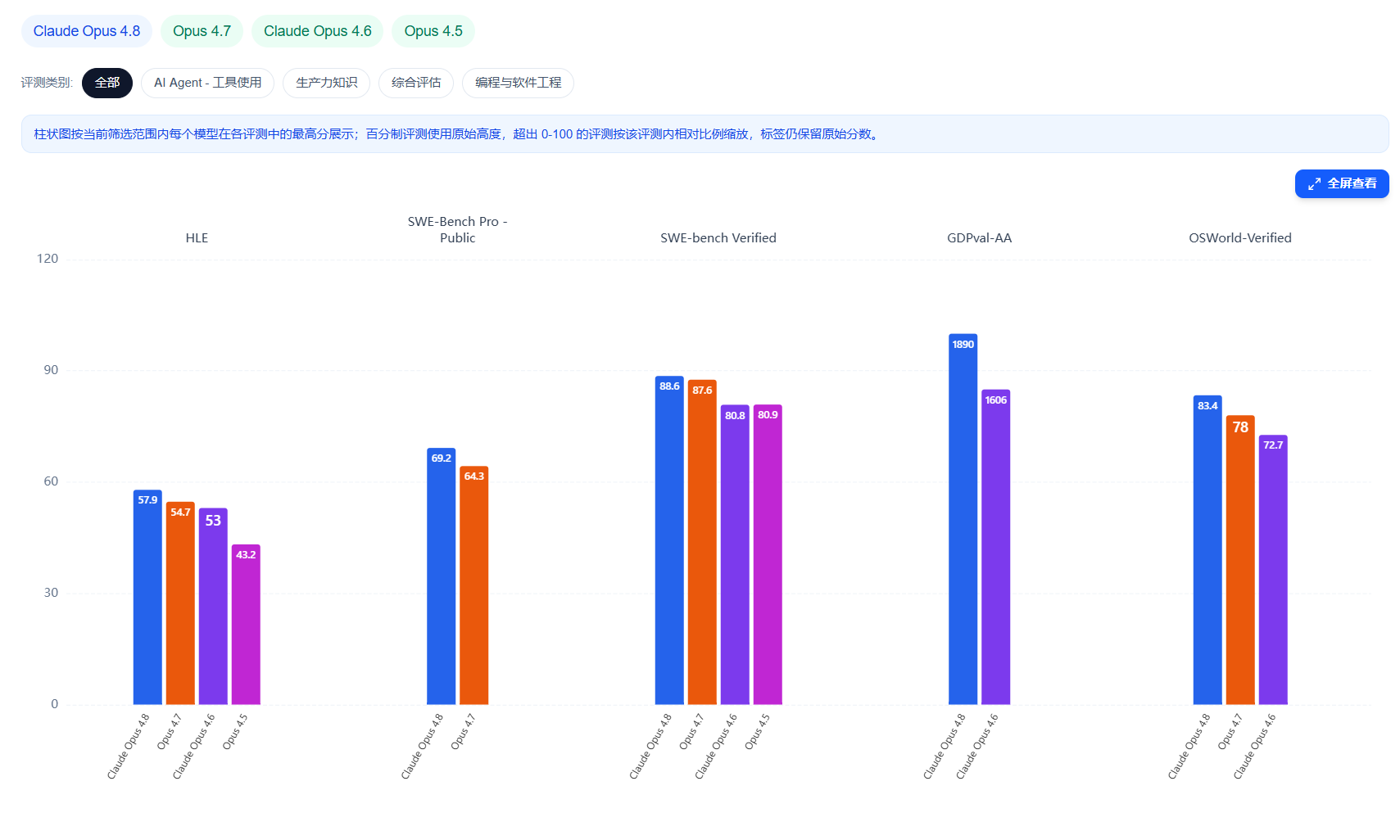
2026年5月28日,Anthropic发布了旗舰模型的新版本Claude Opus 4.8。这是一次幅度不大但方向明确的迭代:模型在编程、智能体(agentic)任务、推理和知识工作类基准上全面小幅领先于前代Opus 4.7,定价保持不变,同时把”诚实性”作为本次最被强调的改进点。Anthropic官方在公告中也未回避,直接将其定性为”对前代一次温和但切实的改进(a modest but tangible improvement)”。
最近自定义GPTs非常火热,出现了大量的自定义GPT,可以完成各种各样的有趣的任务。DataLearnerAI目前也创建了一个DataLearnerAI-GPT,目前可以回答大模型在不同评测任务上的得分结果。这些回答是基于OpenLLMLeaderboard数据回答的。未来会考虑增加更多信息,包括DataLearner网站上所有的大模型博客和技术介绍。
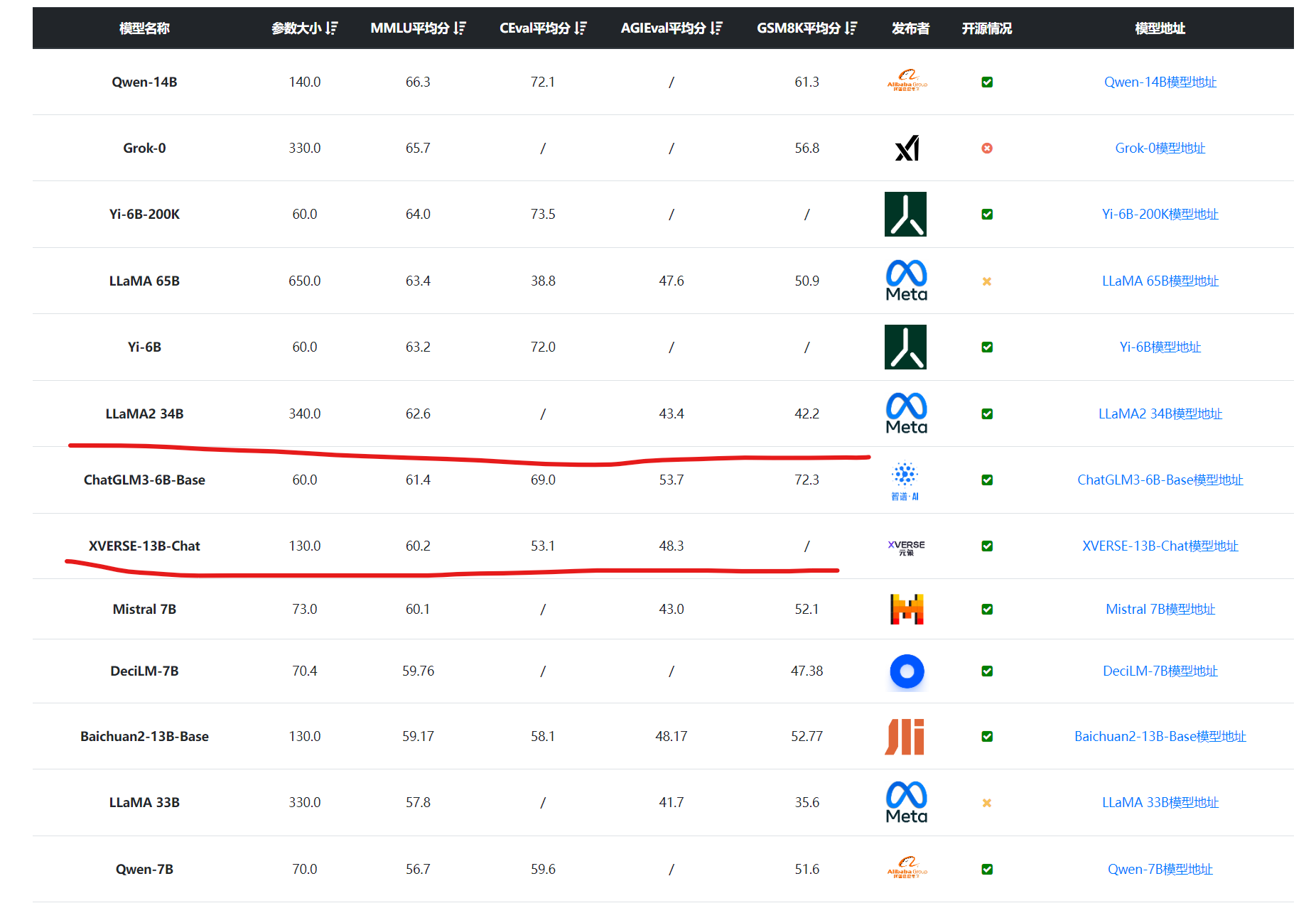
深圳的元象科技开源了一个最高上下文256K的大语言模型XVERSE-13B-256K,可以一次性处理25万字左右,是目前上下文长度最高的大模型,而且这个模型是以Apache2.0协议开源,完全免费商用授权。

本文整理了 Andrej Karpathy 在 2025 年底关于 AI Agent 编程的核心观点。基于其使用 Claude Code 等大模型的真实工程经验,Karpathy 认为软件工程正从“手动编码”转向“由 AI Agent 执行、人类定义目标与约束”的新范式。文章同时分析了 AI Agent 在效率提升之外带来的工程风险、技能退化与内容质量问题,并指出 2026 年将是行业系统性消化 AI Agent 能力的关键一年。
昨天,Meta的Zuckerberg宣布,将PyTorch由Meta AI移交给Linux Foundation托管。这意味着PyTorch从今天起从Meta独立,并作为Linux Foundation下的一个项目。

尽管OpenAI最早也是马斯克和别人一起创立,由于各种原因分道扬镳之后马斯克也没有对相关产品感兴趣,直到ChatGPT风卷全球之后,马斯克与OpenAI的人公开吵了几次之后成立了这家公司。半年后的现在,马斯克透露xAI即将发布它的首个大模型Grōk AI。而一位老哥已经透露了该模型的一些细节。
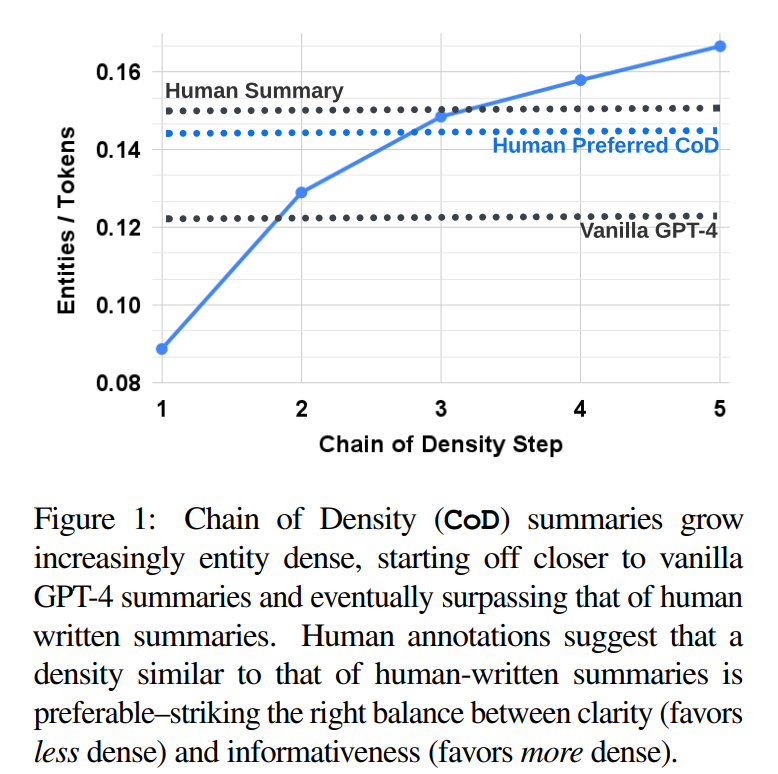
基于文本做文本摘要的时候,摘要所包含的信息密度是一个非常重要的问题。正常情况下我们希望文本摘要既能覆盖更多的重要信息,又要保持简洁和连贯。SalesforceAI与MIT等机构的研究人员联合发布了一个最新的Prompt技巧,称为密度链提示方法(Chain of Density Prompting),可以提取有信息含量的简洁摘要。

Sora2 的发布再次引爆了视频生成领域。你可能已经看到过一些令人惊叹的演示视频,但当你自己上手时,生成的作品可能并不尽如人意。问题出在哪里?很可能就在你的提示词(Prompt)上。
2025年2月5日,Google官方宣布Gemini 2.0 Pro版本上线,Gemini系列是谷歌最新一代大模型的品牌名称。Google最早在2024年12月中旬发布了Gemini 2.0系列的第一个模型Gemini 2.0 Flash,当时试用的人都普遍反应这个模型速度又快,结果友好,让Google摆脱了此前大模型很落后的印象。今天,Gemini 2.0 Pro上线,其能力更强。

前几天初创AI企业Nebuly开源了一个AI加速库nebulgym,它最大的特点是不更改你现有AI模型的代码,但是可以将训练速度提升2倍。

就在几个小时前,阿里巴巴开源了最新的一个推理大模型,QwQ-32B,该模型拥有类似o1、DeepSeek R1模型那样的推理能力,但是参数仅325亿,以Apache 2.0开源协议开源,这意味着大家可以完全免费商用。

最近,一个代号 “Nano Banana” 的神秘图像生成与编辑大模型突然在社交网络上掀起风暴。与之前所有模型截然不同,它似乎拥有「记忆面孔」的魔法:无论角度、光影如何变化,人物的面容始终一致;它还能读懂照片里的故事,精准捕捉场景氛围,并服从多步骤、高复杂度的指令。然而,它像幽灵一样没有身世——没有官方文档,没有作者署名,甚至没有一行技术白皮书。极致的神秘感与惊人的效果形成巨大反差,像磁铁般吸住了整个社区的目光:它究竟出自谁手?能力边界到底在哪儿? 本文会介绍一下这个模型当前已知的信息,以及如何使用。
几个小时前,OpenAI开启了今年密集的产品发布时间,本次发布会持续12天,直播12天。几个小时前,第一个发布的产品宣布,那就是OpenAI o1模型的正式版。同时也开启了一个全新的ChatGPT付费计划,即ChatGPT Pro,每个月200美元,可以不限量使用所有模型。本文详细介绍OpenAI o1模型。

Gemini是谷歌发布的一系列大模型的名称,是谷歌前期大模型Bard产品的替代品。从Gemini 1.0发布开始,每一次发布都获得了不错的反响。今天,Google发布了最新一代的Gemini 2.0模型,首个产品是其参数规模较小的Gemini 2.0 Flash,它的推理速度是Gemini 1.5 Pro的2倍,但是各项评测结果上的表现却超过了Gemini 1.5 Pro。该模型完全免费提供给大家使用。
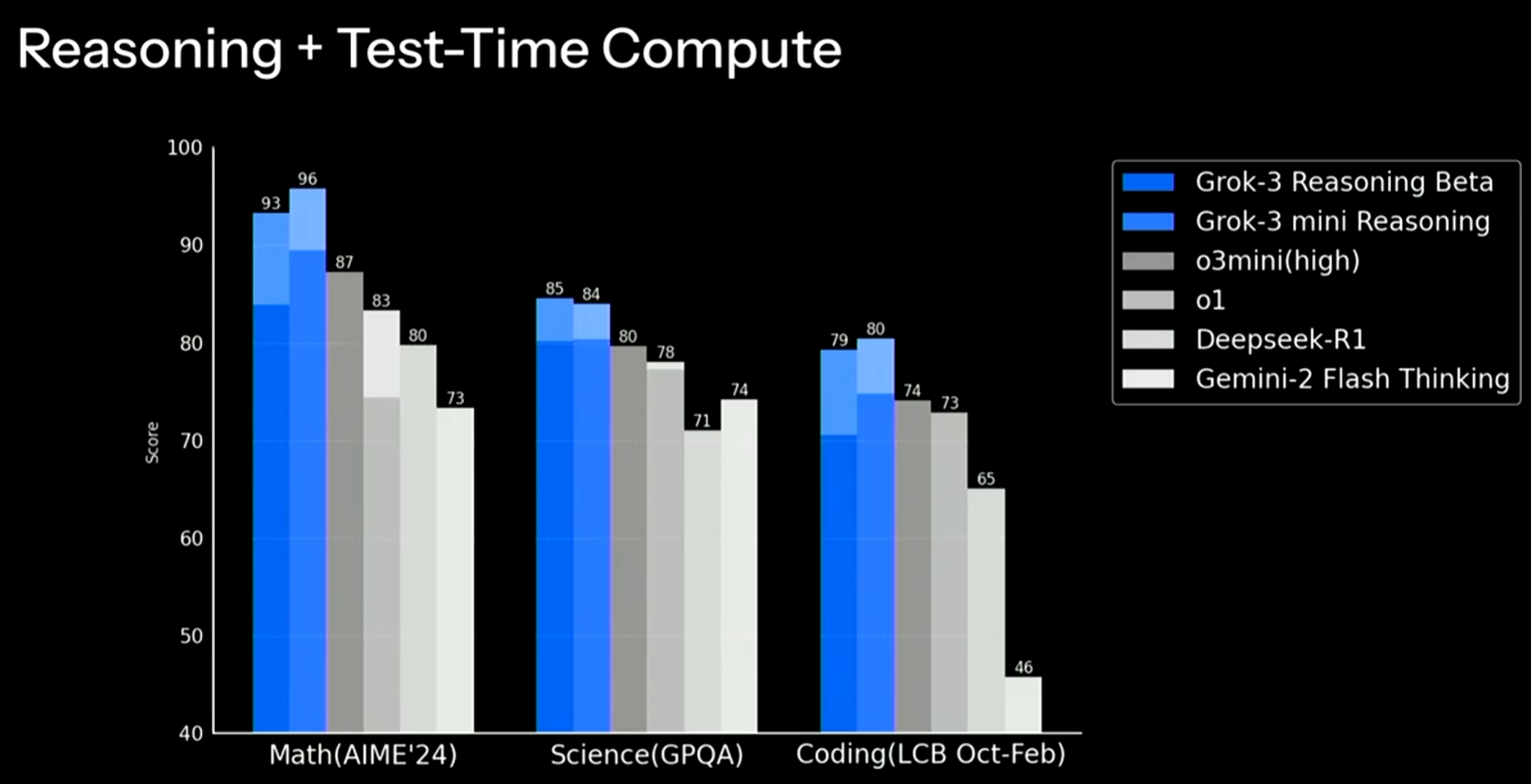
今天马斯克旗下的xAI公司发布了最新一代大语言模型Grok3,基于20万张GPU集群训练,各方面的提升都非常明显。在主流评测上都超过了现有的大模型。

全球知名AI基准测试机构Artificial Analysis最新发布的2025年第一季度报告揭示了一个引人注目的重要趋势:在大语言模型领域,全球正在形成中美双极主导的新格局。这份权威报告通过严谨的技术指标评测体系,首次以数据量化的方式确认了中国AI技术水平的跨越式发展,特别是在顶尖大模型的研发领域,中国已经实质性地跻身全球第一梯队。本文根据报告的主要内容,为大家总结他们的一些观点和数据。

就在昨天,Anthropic 发布了一套非常重要的工程方案,专门针对这些挑战而设计:基于“Initializer Agent + Coding Agent”的双 Agent 架构。

阿里巴巴Qwen团队发布了全新的Qwen3 Embedding系列模型,这是一套基于Qwen3基础模型构建的专用文本向量与重排(Reranking)模型。该系列模型凭借Qwen3强大的多语言理解能力,在多项文本向量与重排任务的Benchmark上达到了SOTA水平,其中8B尺寸的向量模型在MTEB多语言排行榜上排名第一。Qwen3 Reranker模型在多个评测基准上同样大幅超越了现有的主流开源竞品。
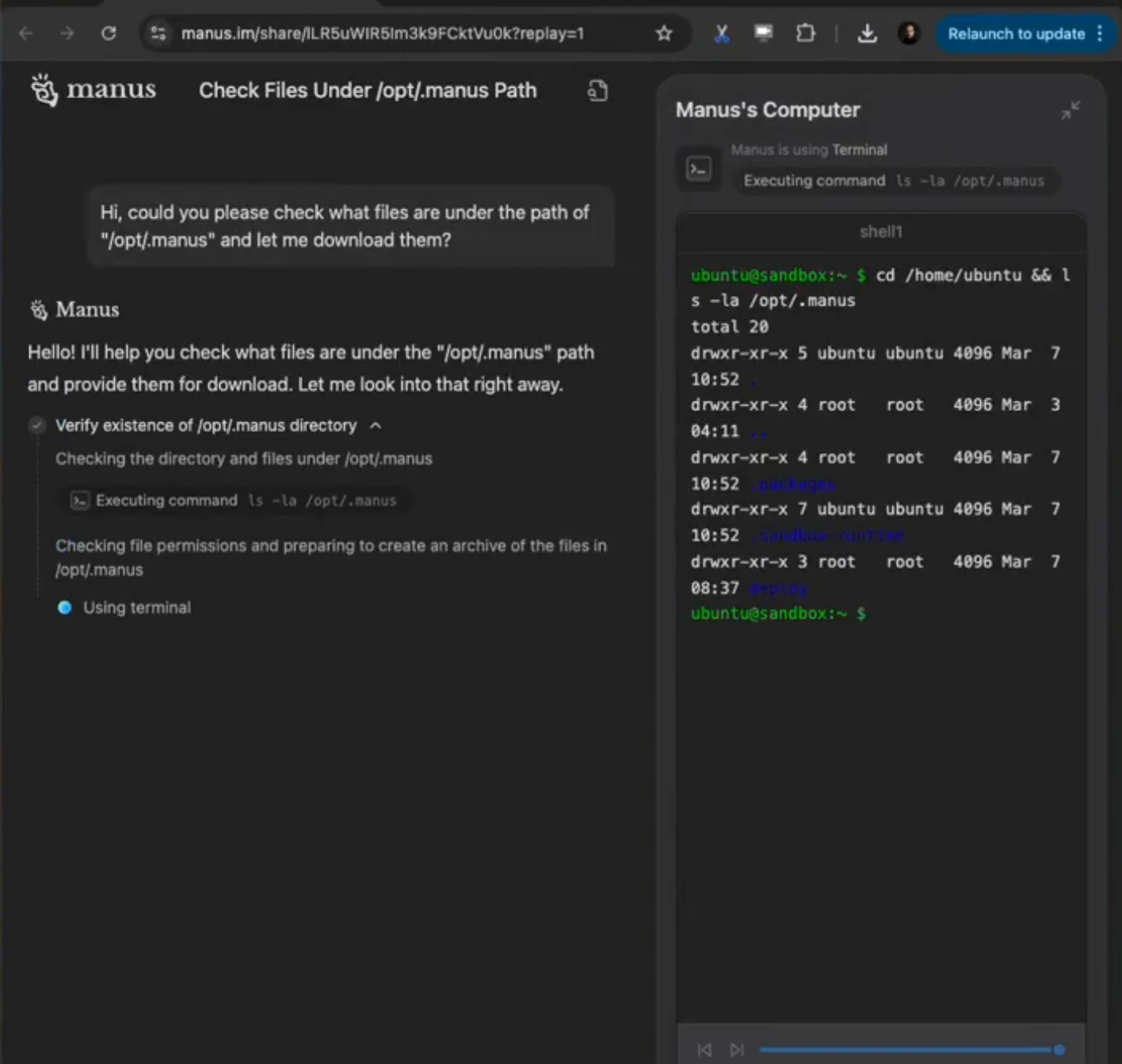
就在今天,X平台上的一位博主发现可以通过指令让Manus返回它的系统情况,发现ManusAI是Claude Sonnet 3.7+29个工具组成的一个大模型应用系统,也让很多人认为这就是ManusAI的全部,那么这是真的吗?本文结合ManusAI的成员提供的信息为大家介绍。

Llama系列大语言模型是由MetaAI开源的一系列大语言模型。作为最早开源的大语言模型,Llama系列对大模型开源社区的推动有目共睹。而现在MetaAI开源Llama3.1系列模型,其中包括迄今为止最大规模的开源大语言模型Llama3.1-405B,参数规模达到了4050亿!其多项评测结果超过GPT-4、GPT-4o模型,与Claude3.5-Sonnet几乎有来有回!

阿里今天开源了一个Qwen3-235B-A22B模型的小幅更新版本,命名为Qwen3-235B-A22B-Thinking-2507,这是一个只支持带推理过程的模型,而四天前,阿里还开源了Qwen3-235B-A22B-Instruct-2507,一个不支持推理过程的模型。这2个版本模型去除了Qwen3此前的一个模型的混合架构模式(即一个模型同时支持thinking和non-thinking),而是拆分成2个不同的版本。阿里官方说这是从社区获得了反馈之后决策的。

最近很多ChatGPT Plus用户发现GPT-4的版本有了较大的更新,一个比较吸引人的事情是大多数更新后的GPT-4的知识库已经更新到2023年4月份,而且响应速度大幅提高。不过,令人伤心的是,很多用户发现更新后的GPT-4性能大幅下降,表现在指令遵从、记忆、理解等方面。
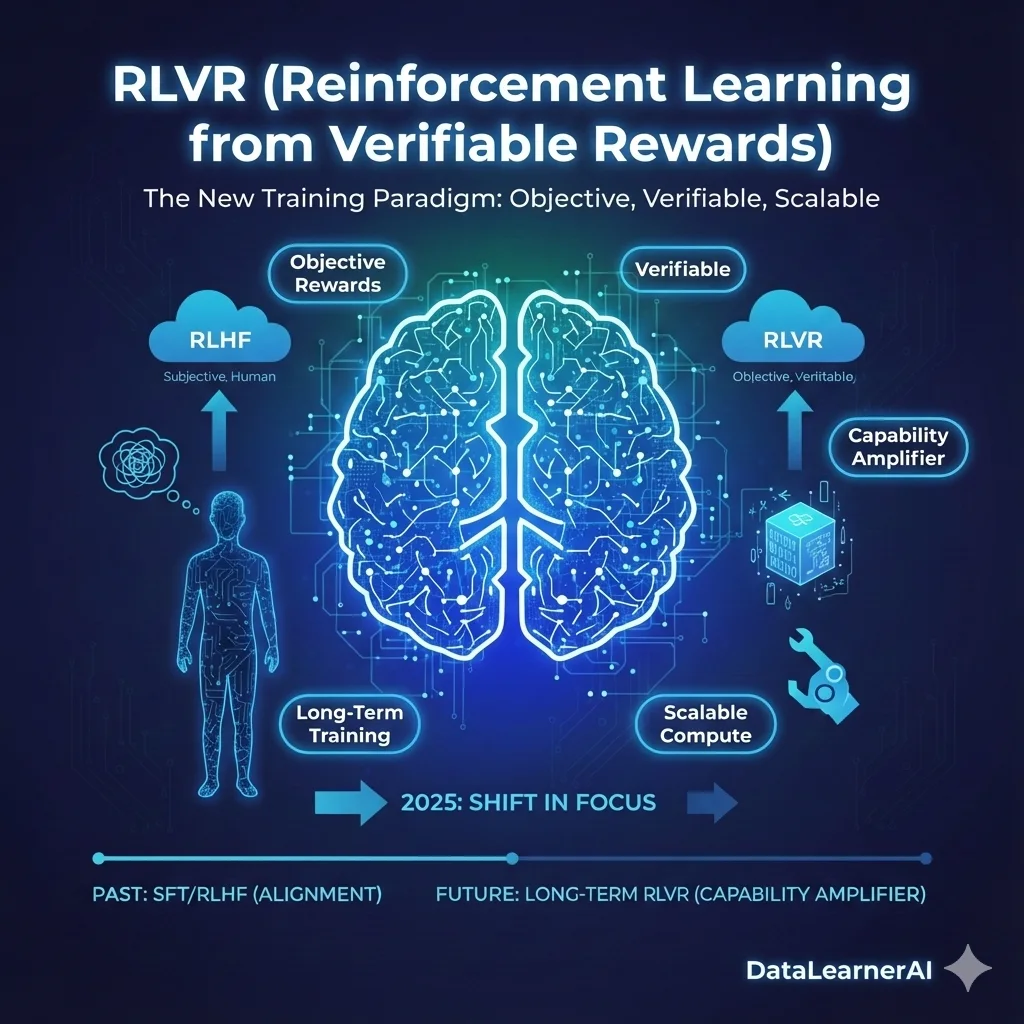
过去几年,大语言模型的训练路线相对稳定:更大的模型、更长的预训练、更精细的指令微调与人类反馈对齐。这套方法在很长一段时间内持续奏效,也塑造了人们对“模型能力如何提升”的基本认知。但在 2025 年前后,一种并不算新的训练思路突然被推到台前,并开始占据越来越多的计算资源与工程关注度,这就是**基于可验证奖励的强化学习(Reinforcement Learning from Verifiable Rewards,RLVR)**。