
吴恩达再开新课程!如何基于大语言模型实现更强大的语义搜索课程!
刚刚,吴恩达宣布deeplearning.ai 与 Cohere 合作推出了一个新课程:“Large Language Models with Semantic Search”。这个课程主要教授大家如何使用LLMs进行语义搜索,还提供了大量实践经验,来克服搜索结果和准确性等挑战。
探索人工智能与大模型最新资讯与技术博客,涵盖机器学习、深度学习、自然语言处理等领域的原创技术文章与实践案例。
刚刚,吴恩达宣布deeplearning.ai 与 Cohere 合作推出了一个新课程:“Large Language Models with Semantic Search”。这个课程主要教授大家如何使用LLMs进行语义搜索,还提供了大量实践经验,来克服搜索结果和准确性等挑战。

Bloomberg在2022年4月开源了Memray,这是一个Python的内存分析器。它可以跟踪Python代码、本地扩展模块和Python解释器本身的内存分配情况。可以看numpy和pandas的运行内存使用。
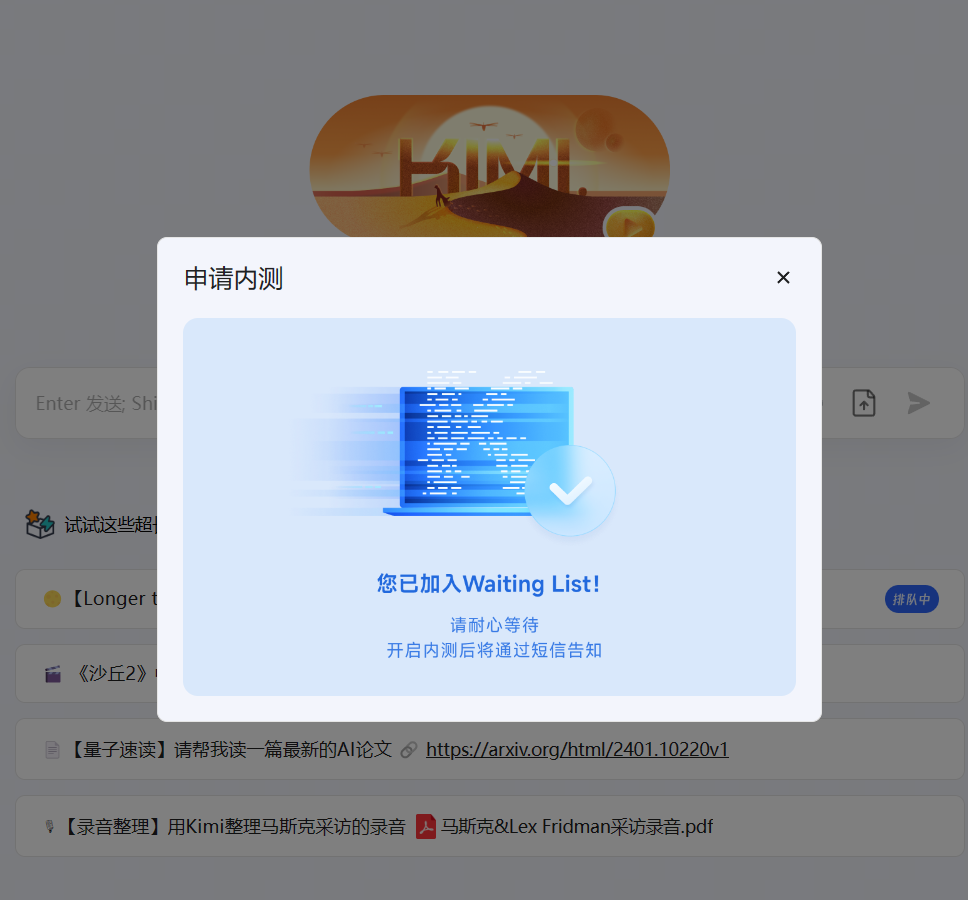
MoonshotAI(月之暗面)是一家中国的大模型初创企业,在2023年4月份成立。其最为著名的产品就是KimiChat,一个完全免费的大模型聊天机器人。就在刚刚,MoonshotAI官方宣布开启200万上下文的KimiChat内测!这应该是全球首个商业产品支持并内测200万上下文输入的模型了!此前其它产品宣布的200万上下文大多数都没有公开商发。
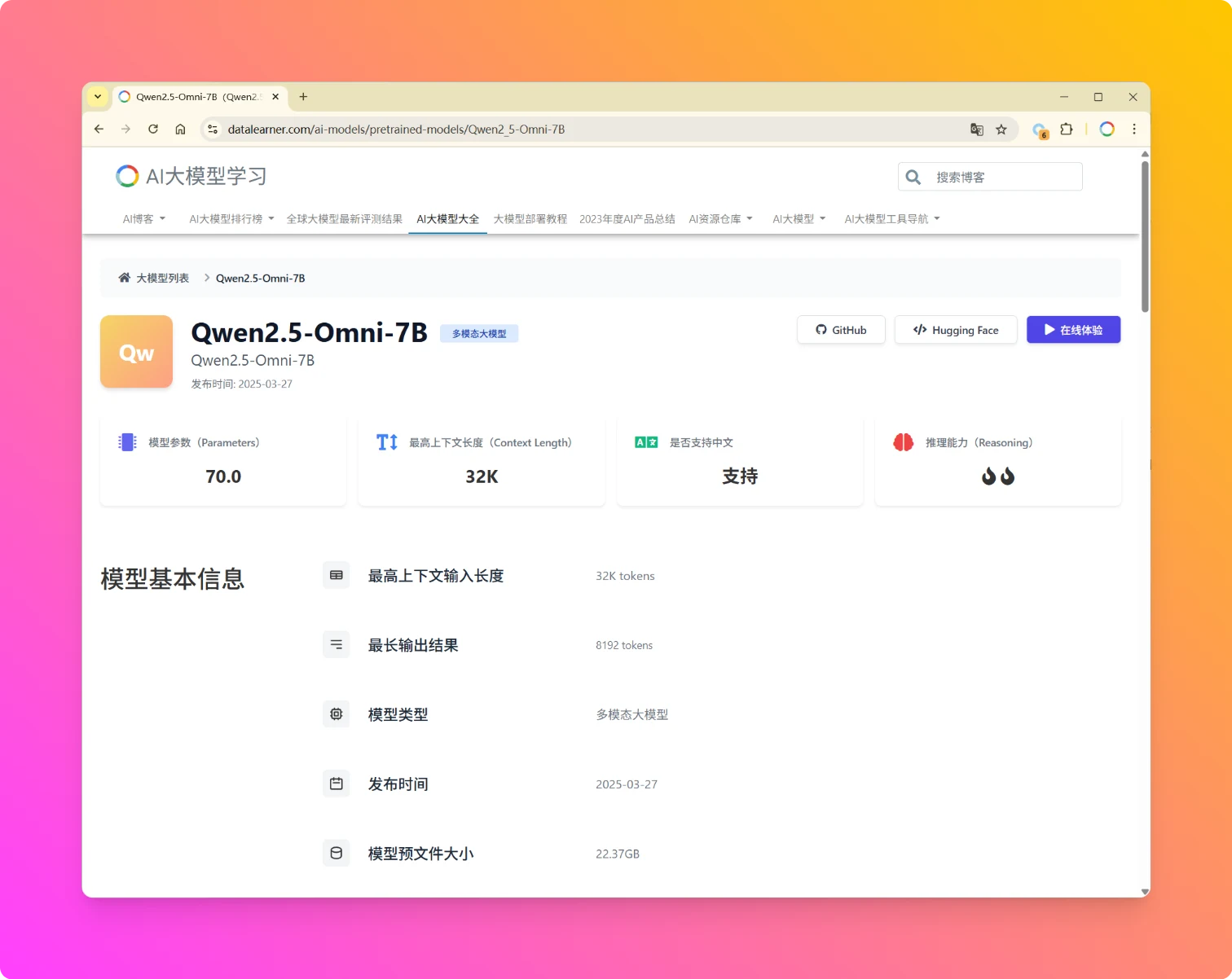
Qwen2.5-Omni-7B是阿里巴巴发布的一款端到端全模态大模型,支持文本、图像、音频、视频(无音频轨)的多模态输入与实时生成能力,可同步输出文本与自然语音的流式响应。目前,该模型在HuggingFace以Apache2.0协议开源,可以免费商用授权。
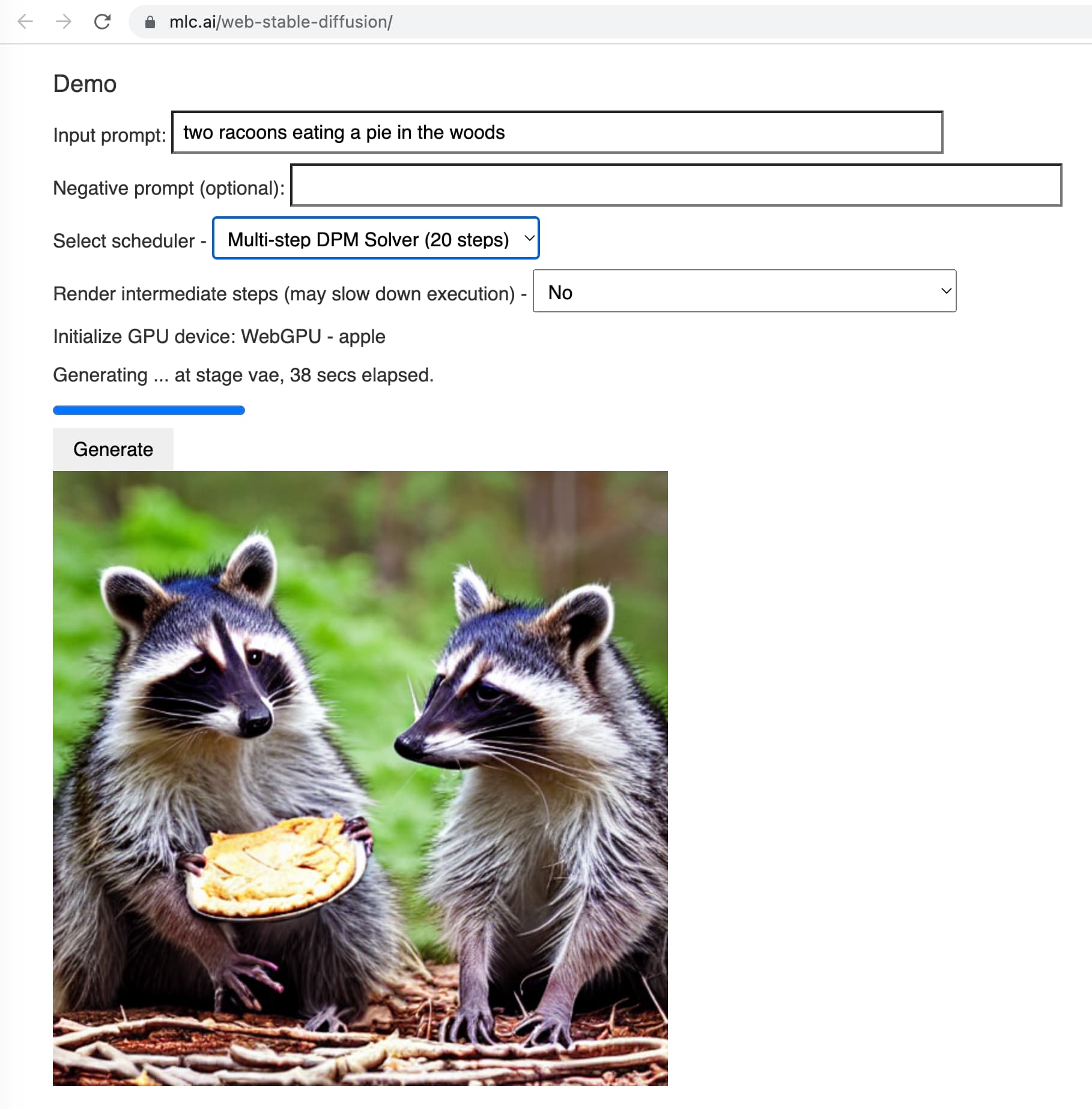
尽管当前ChatGPT和GPT-4非常火热,但是高昂的训练成本和部署成本其实导致大部分个人、学术工作者以及中小企业难以去开发自己的模型。使得使用OpenAI的官方服务几乎成为了一种无可替代的选择。本文介绍的是一种低成本开发高效ChatGPT的思路,我认为它适合一些科研机构去做,也适合中小企业创新的方式。这里提到的思路涉及了一些最近发表的成果和业界的一些实践产出,大家可以参考!
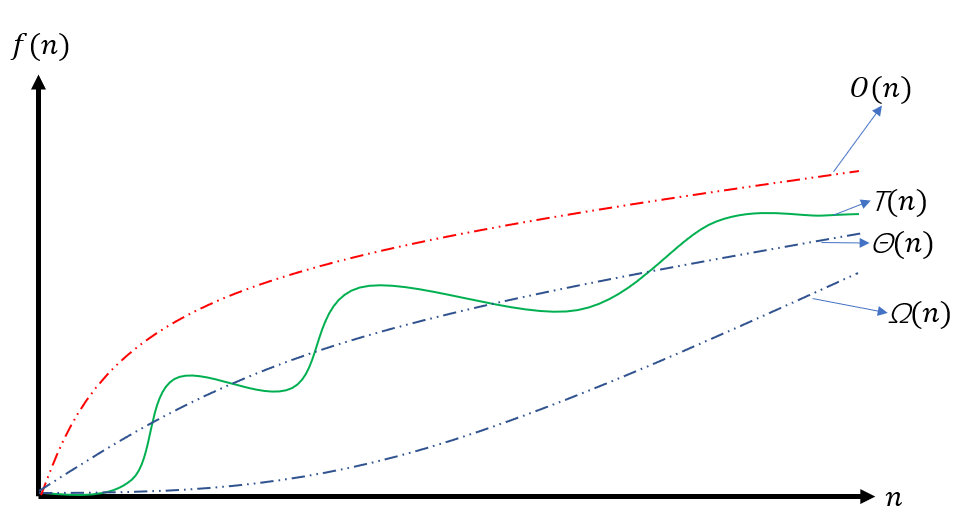
在程序设计和编程中,我们经常会看到关于时间复杂度的讨论。比如为什么A方法比B方法好?是因为A方法的时间复杂度低。那么,这里的时间复杂度如何去理解,又怎么计算呢?常见的O(n)的含义是什么?本文将简单的解释这个概念。

最近这几天,如果你的 X (Twitter) 首页被 Clawdbot 刷屏了,不用惊讶,主要是太火了。但是这个软件的使用有一定门槛,而且争议比较大。X上有一位博主分享了他对这个东西的看法和使用经验,挺详细的,对于想了解Clawdbot是啥的,这个文章不错。大家看也可以从这个文章看到Clawdbot能做什么,和Cowork对比有啥优点和缺点

几个小时前,OpenAI的研究人员披露,其一款内部实验性的大语言模型,在模拟的国际数学奥林匹克(International Math Olympiad ,IMO)竞赛2025中取得了金牌水平的成绩。这是一个里程碑式的突破,因为IMO被认为是衡量创造性数学推理能力的巅峰,远超以往任何AI基准测试。这项成就并非通过专门针对数学的“窄”方法实现,而是源于通用人工智能研究的根本性突破,尤其是在处理难以验证的任务和长时间推理方面。
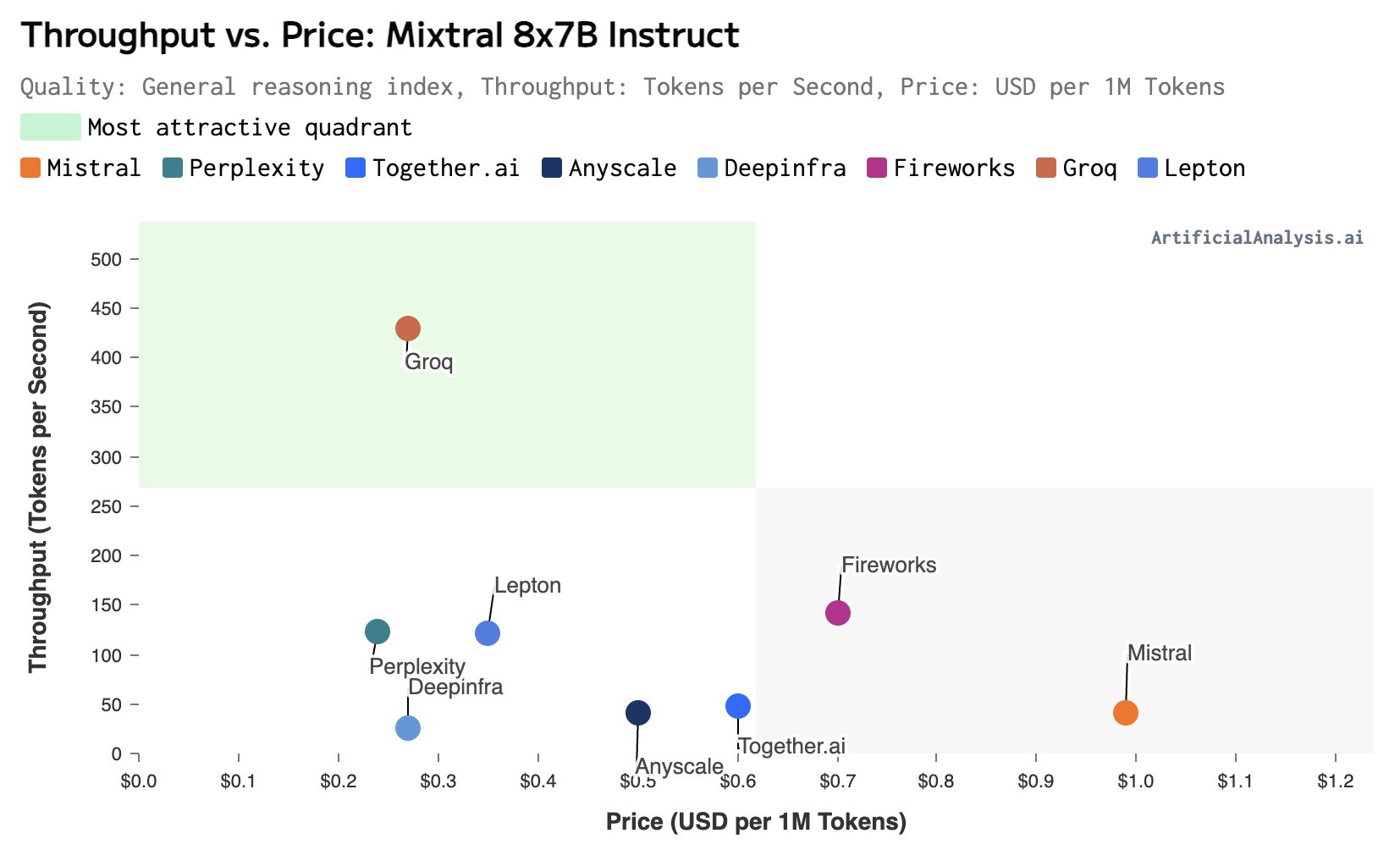
大模型的推理速度是当前制约大模型应用的一个非常重要的问题。在很多的应用场景中(如复杂的接口调用、很多信息处理)的场景,更快的大模型响应速度通常意味着更好的体验。但是,在实际中我们可用的场景下,大多数大语言模型的推理速度都非常有限。慢的有每秒30个tokens,快的一般也不会超过每秒100个tokens。而最近,美国加州一家企业Groq推出了他们的大模型服务,可以达到每秒接近500个tokens的响应速度,非常震撼。
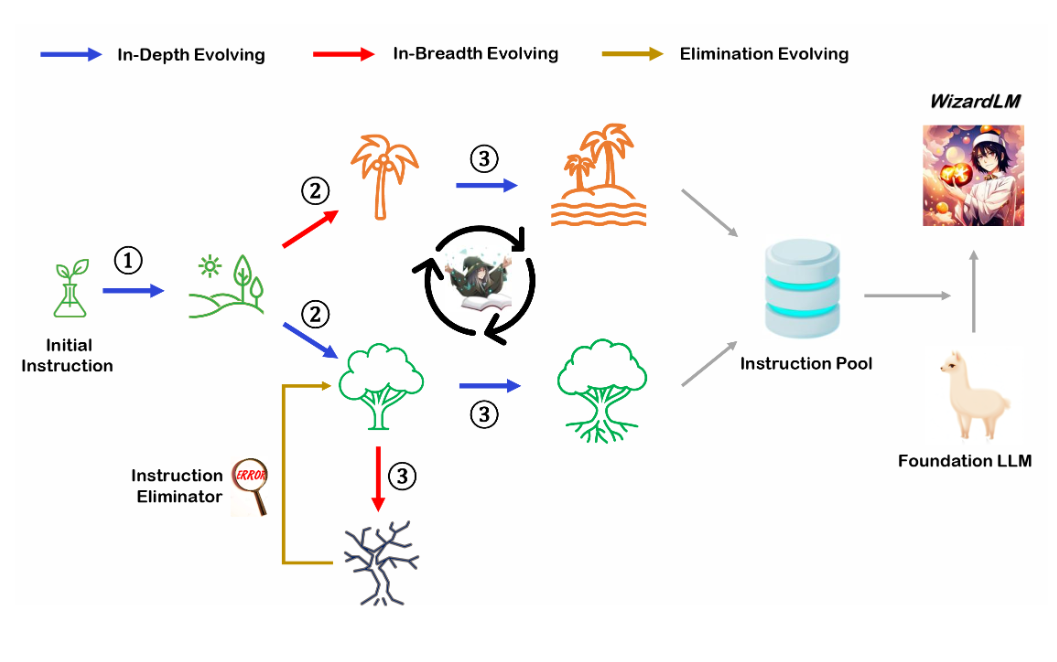
WizardLM是微软联合北京大学开源的一个大语言模型。此前,发布的WizardLM和WizardCoder都是业界开源领域最强的大模型。其中,前者是针对指令优化的大模型,而后者则是针对编程优化的大模型。而此次WizardMath则是他们发布的第三个大模型系列,主要是针对数学推理优化的大模型。在GSM8K的评测上,WizardMath得分超过了ChatGPT-3.5、Claude Instant-1等闭源商业模型,得分十分逆天!

就在刚才,阿里云Qwen团队推出了两个多模态理解大模型Qwen3-VL-4B和Qwen3-VL-8B,本次发布的模型是较小参数规模的模型,可以用于消费级硬件(手机/PC)等,且都是稠密架构。

检索增强生成(Retrieval-augmented Generation,RAG)是一种结合了检索和大模型生成的方法。它从一个大型知识库中检索与输入相关的信息,然后利用这些信息作为上下文和问题一起输入给大语言模型,并让大语言模型基于这些信息生成答案的方式。检索增强生成可以让大语言模型与最新的外部数据或者知识连接,进而可以基于最新的知识和数据回答问题。尽管检索增强生成是一种很好的补充方法,但是,如果文档切分有问题、检索不准确,结果也是不好的。
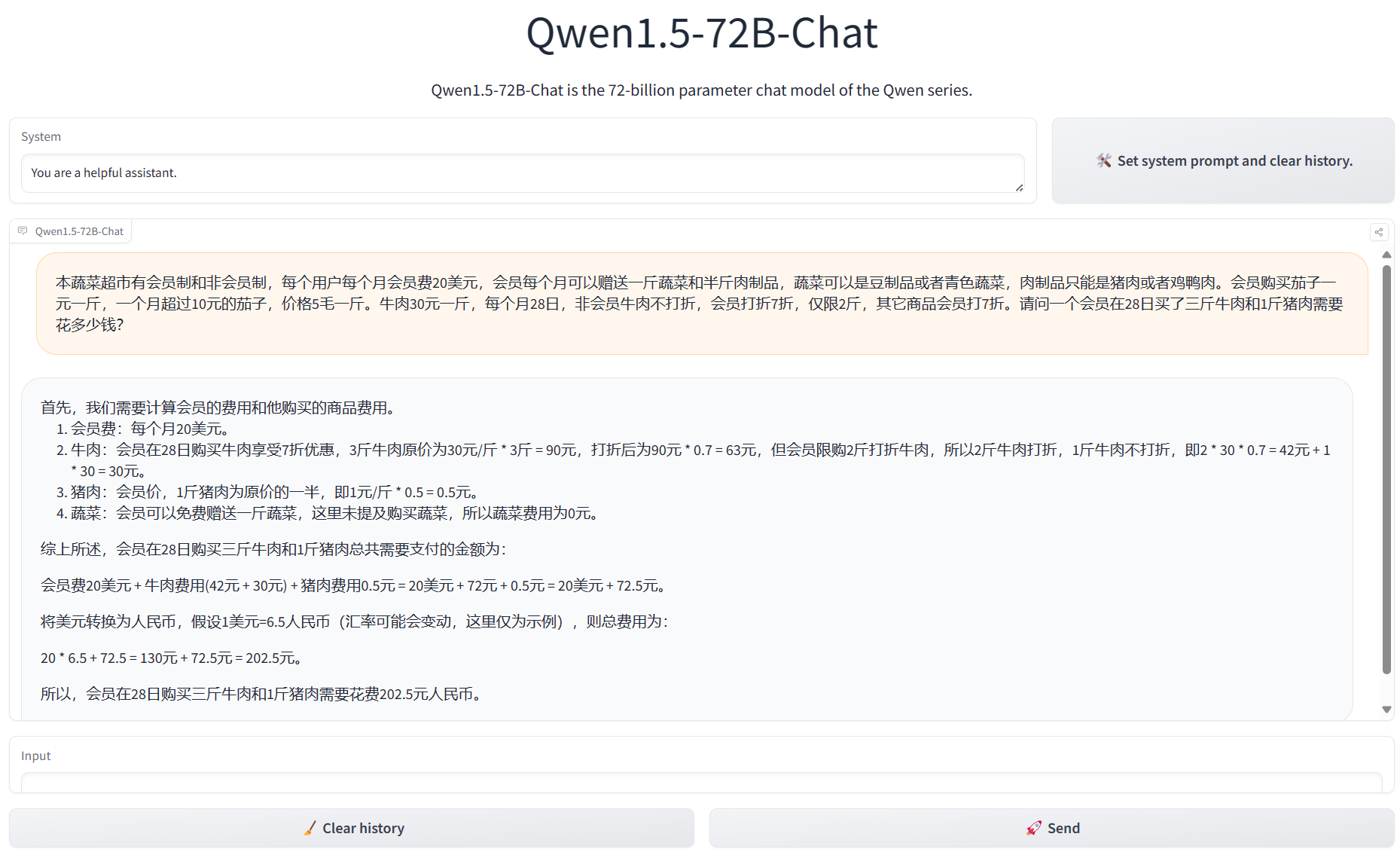
Qwen1.5系列是阿里开源的一系列大语言模型,也是目前为止最强开源模型之一。Qwen1.5是Qwen2的beta版本,此前开源的模型最大参数规模都是720亿,和第一代模型一样。就在刚刚,阿里开源了1100亿参数规模的Qwen1.5-110B模型。评测结果显示MMLU略超Llama3-70B和Mixtral-8×22B。我们实测结果,相比Qwen1.5-72B模型来说,复杂任务的逻辑提升比较明显!
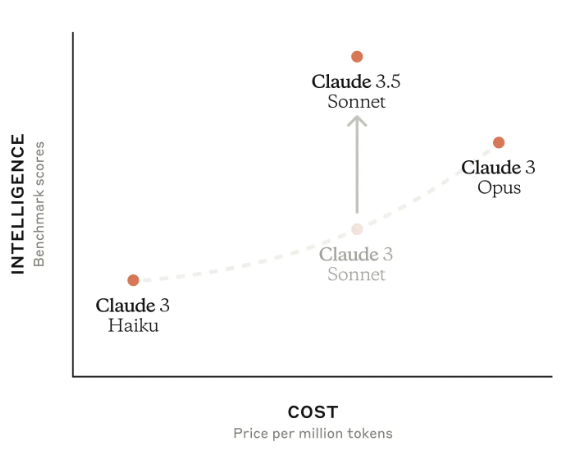
Claude系列模型是Anthropic发布的大模型,一直被认为是最接近GPT-4系列的大模型。2024年3月份,Anthropic发布了Claude3系列,从各方的使用情况看,都接近甚至超过了GPT-4。时隔三个月,Anthropic再次发布全新3.5版本的Claude3.5系列。本次首先发布的是Claude3.5-Sonnet版本。已经支持免费使用。
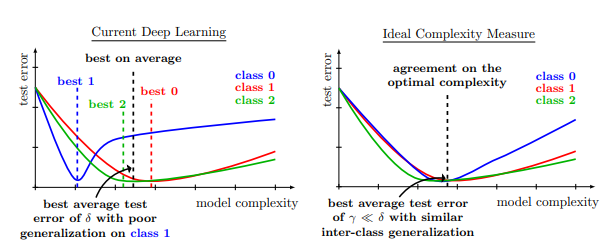
正则化是一种基本技术,通过限制模型的复杂性来防止过度拟合并提高泛化性能。目前的深度网络严重依赖正则化器,如数据增强(DA)或权重衰减,并采用结构风险最小化,即交叉验证,以选择最佳的正则化超参数。然而,正则化和数据增强对模型的影响也不一定总是好的。来自Meta AI研究人员最新的论文发现,正则化是否有效与类别高度相关。
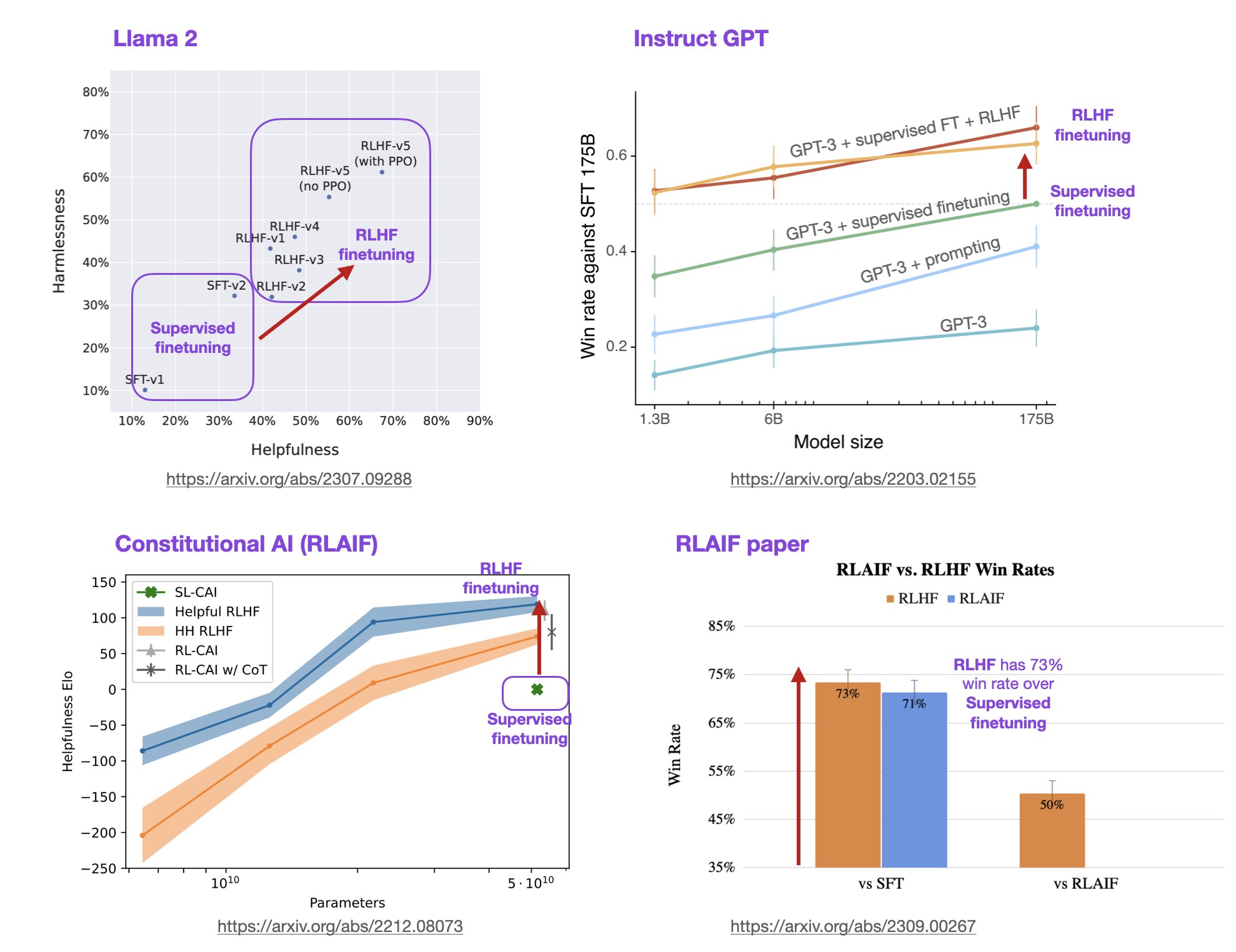
基于人类反馈的强化学习方法(Reinforcement Learning with Human Feedback,RLHF)是一种强化学习(Reinforcement Learning,RL)的变种,它利用人类的专业知识和反馈来指导机器学习模型的训练和决策过程。这种方法旨在克服传统RL方法中的一些挑战,例如样本效率低、训练困难和需要大量的试错。在大语言模型(LLM)中,RLHF带来的模型效果提升不仅仅是模型偏好与人类偏好的对齐,模型的理解能力和效果也会更好。
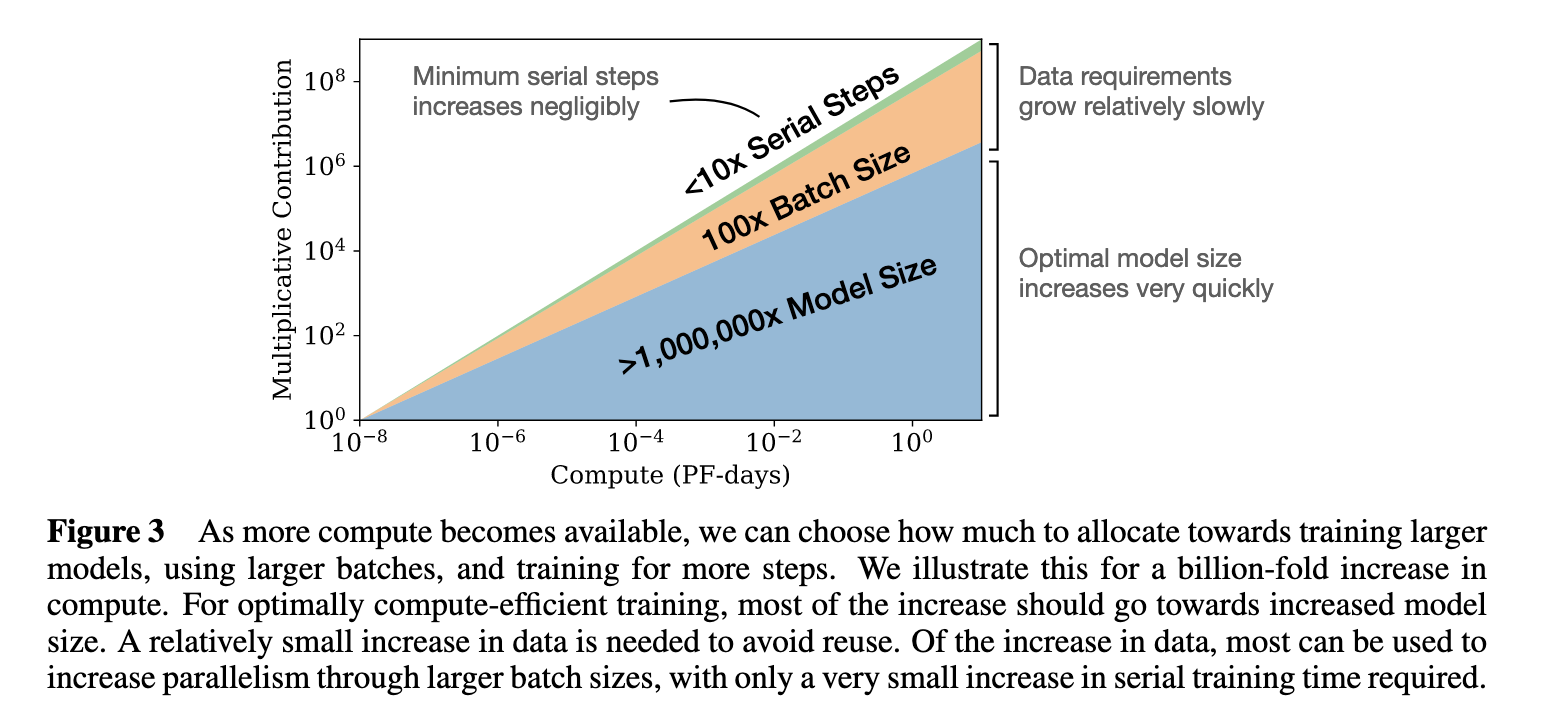
今晚已经是本周的最后一天了,最近的一些深度学习算法方面的进展做个总结吧,感觉都是挺不错的,供大家参考。

大模型微调依然是针对大量私有数据或者特定领域不可缺少的方法。就在前不久,LightningAI发布了一个轻量级大模型微调库Lit-Parrot,仅需一行代码即可微调当前开源大模型。

大家都知道,编程的开发离不开互联网的支持,不管是编程的学习还是bug的修复,都需要社区和外部的支持。因此,我们全新开通了一个程序必备网站列表栏目,为大家提供一站式访问目录。也欢迎评论,大家可以说一下你们写代码时候喜欢用的网站,我们也会更新上去。在这里我们挑选几个必备网站简单介绍一下。
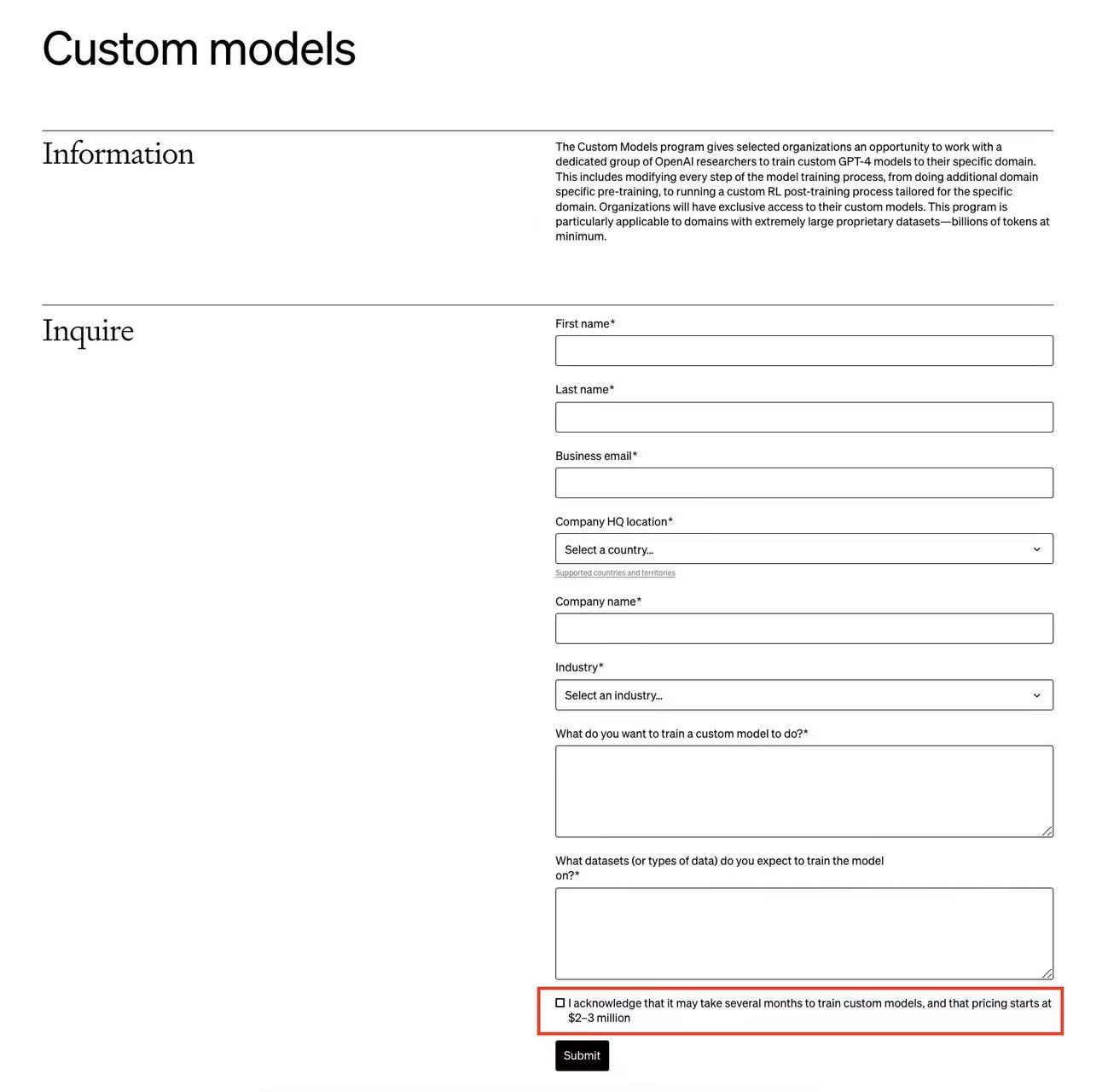
OpenAI的开发者日发布了许多更新。其中,普通用户可以微调GPT-4是非常值得期待的功能之一。但是,OpenAI还有一个针对企业的定制化GPT-4的训练服务,称为Custom Models。而这项为企业单独定制的GPT-4训练服务最新截图显示,需要几个月来训练模型,而且费用是200-300万美元起步!

就在刚刚,阿里巴巴正式免费开源了两款全新的多模态模型——Qwen3-VL-Embedding(多模态向量模型)和 Qwen3-VL-Reranker(多模态重排序模型),首次在开源体系中系统性补齐了多模态 RAG 在“向量化检索 + 精排重排”两个关键环节上的能力空白。这两个模型是基于强大的Qwen3-VL基础模型构建的专用多模态向量与重排(Reranking)模型。
就在刚刚,阿里开源了全新的语音合成大模型Qwen3-TTS系列!本次开源的语音合成模型共5个版本,最小的仅0.6B参数规模,最大的模型参数也就1.7B,基本上手机端都可以运行。此次发布不仅在性能上宣称超越了许多商业级闭源模型(如 OpenAI 的 GPT-4o-Audio 和 ElevenLabs),更重要的这应该是阿里通义千问团队首次开源语音合成系列大模型。
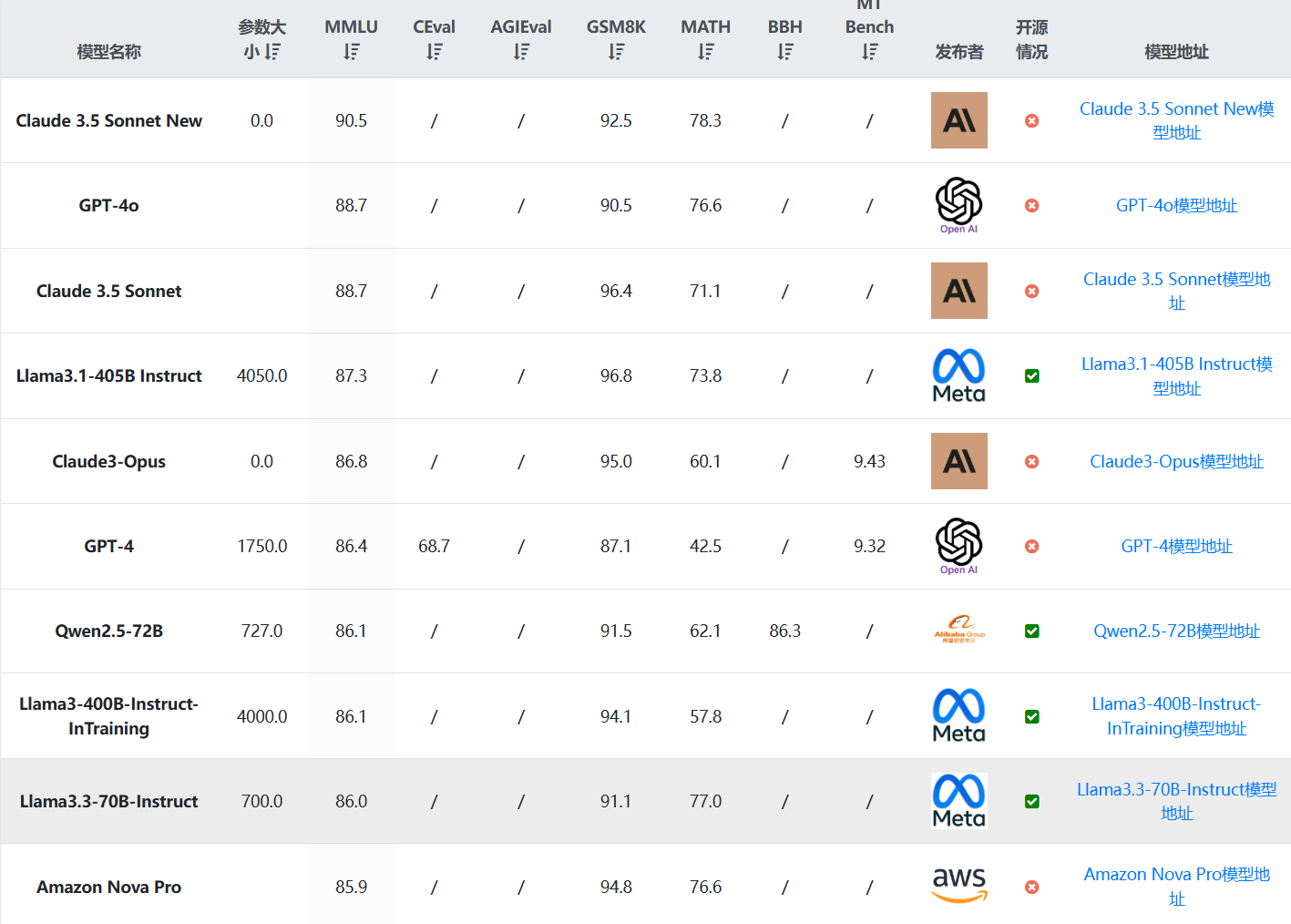
Llama系列大语言模型一直是开源领域的大模型标杆,Llama3系列大模型自从开源之后一直在不断更新。最早的Llama3模型于2024年4月开源,此后,几乎每个三个月都有一个新版本发布。就在昨天,Meta开源了最新的Llama3.3-70B模型,这是Llama3.3系列目前唯一开源的模型。尽管该模型的参数规模仅仅700亿,但是在多项评测基准上已经超过了4050亿参数规模的Llama3.1-405B,后者是Llama系列模型中参数规模最大的一个,也是业界开源模型中参数规模最高的模型之一。
