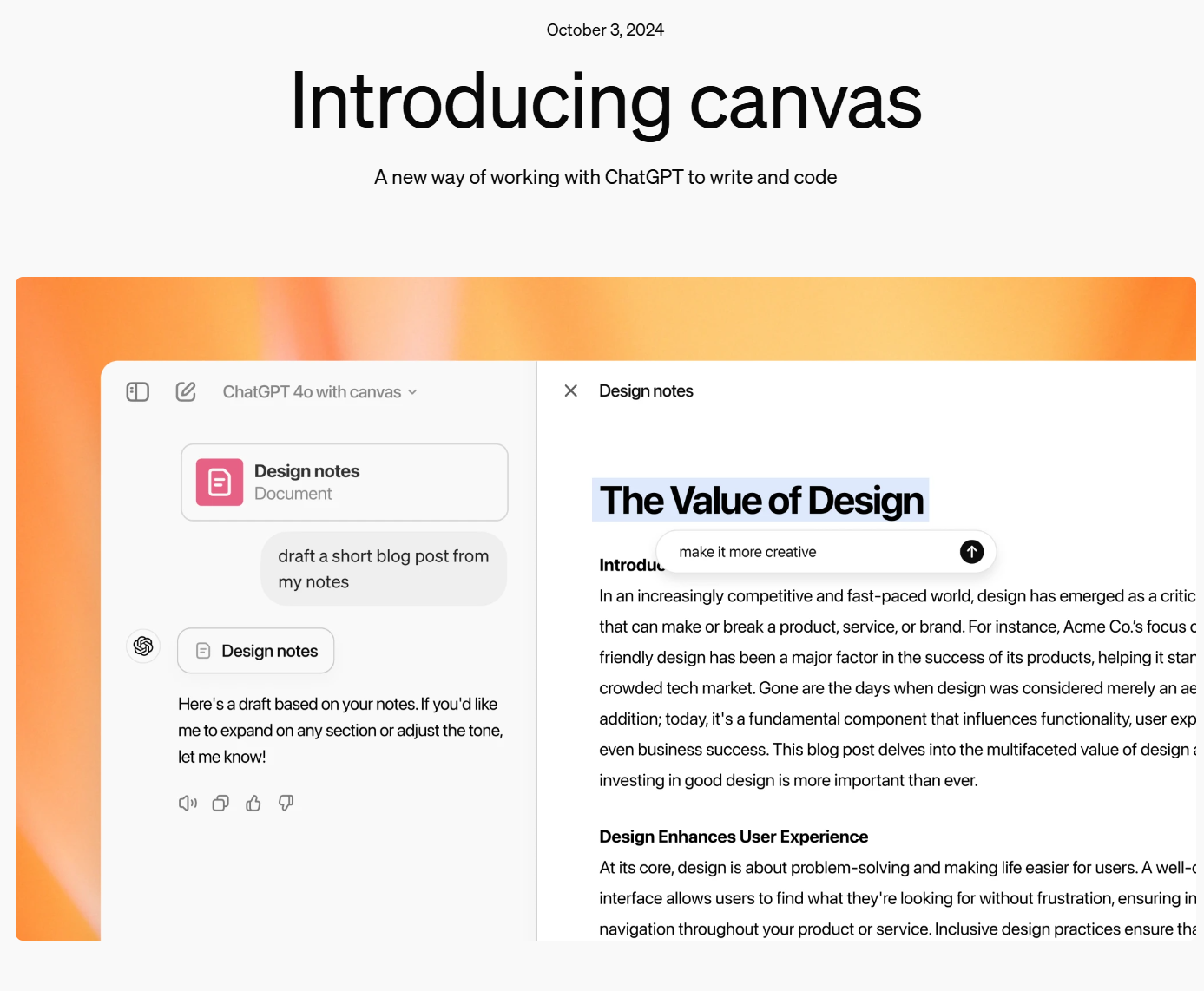
Claude Artifacts的复制?OpenAI发布ChatGPT协作新组件:Canvas,让你与ChatGPT共同处理写作与编程问题!
在写作和编程中,使用 ChatGPT 帮助用户处理各种复杂任务已变得越来越普遍。然而,这个过程中仍然存在一些挑战,比如上下文追踪不够连贯、实时反馈不足,以及在编程时难以精确地处理错误或优化代码。为此,OpenAI发布了一个新的特新:Canvas,它是为了解决上述问题而设计的一个全新工具,集成了写作、编程和实时协作的功能。
探索人工智能与大模型最新资讯与技术博客,涵盖机器学习、深度学习、自然语言处理等领域的原创技术文章与实践案例。
在写作和编程中,使用 ChatGPT 帮助用户处理各种复杂任务已变得越来越普遍。然而,这个过程中仍然存在一些挑战,比如上下文追踪不够连贯、实时反馈不足,以及在编程时难以精确地处理错误或优化代码。为此,OpenAI发布了一个新的特新:Canvas,它是为了解决上述问题而设计的一个全新工具,集成了写作、编程和实时协作的功能。

MTEB是一个用于评估向量大模型向量化准确性的评测排行榜。它全称为Massive Text Embedding Benchmark,是一个旨在衡量文本嵌入模型在多种任务上表现的基准测试。

几个小时前,Anthropic发生一起信息泄露事件,还没来得及官宣,自家最强新模型就被”意外”公之于众。新模型的能力据称远超Opus 4.6!
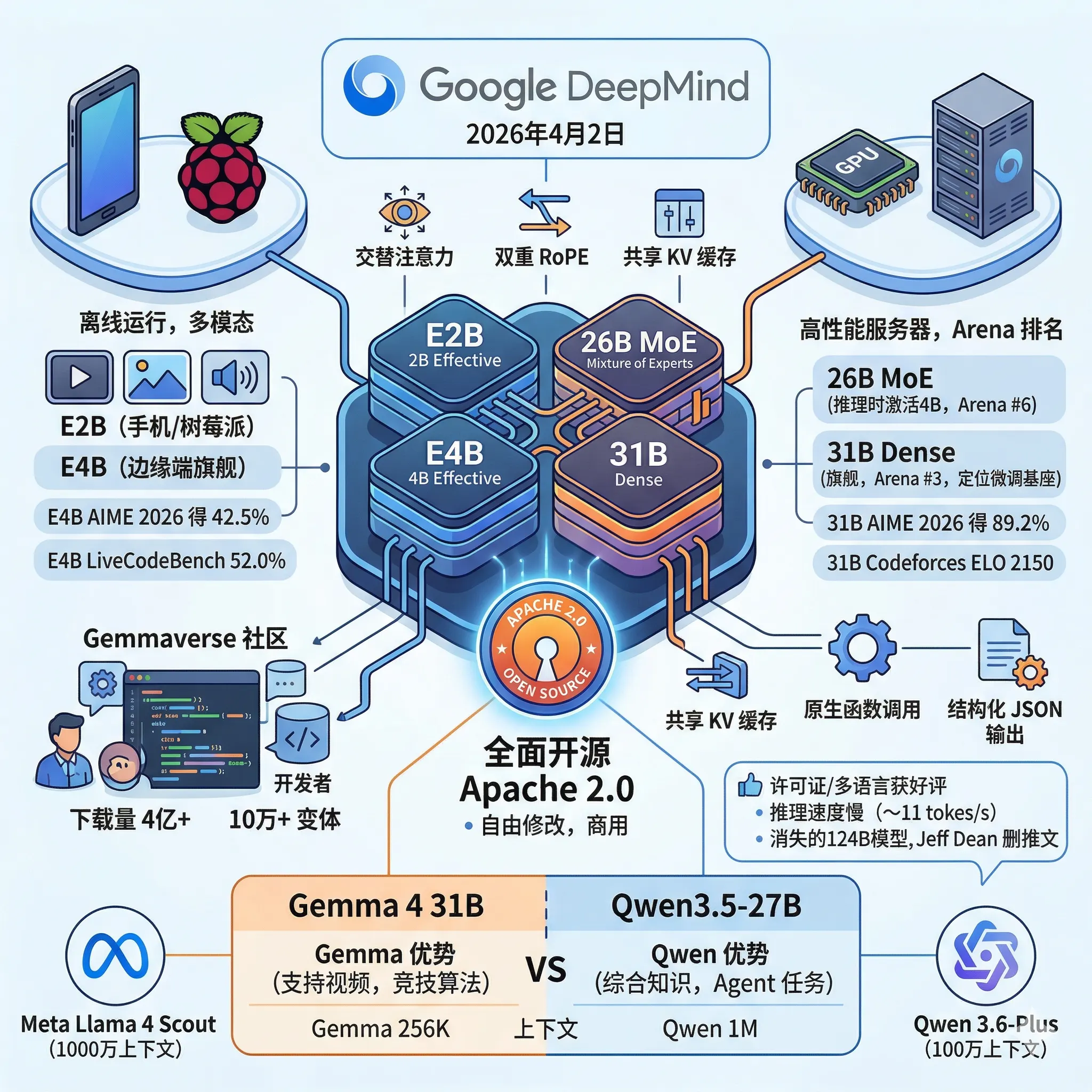
2026年4月2日,Google DeepMind 发布了 Gemma 4 系列,共四个版本:E2B、E4B、26B A4B 和 31B Dense。这也是 Gemma 系列首次采用 Apache 2.0 授权,允许完全商用和二次分发。
DocVQA是一个针对文档图像的视觉问答基准数据集。该数据集包含50,000个问题,这些问题基于12,767张文档图像构建而成。数据集旨在评估模型在提取和理解文档内容方面的能力,特别是当问题涉及布局、表格和文本时。基准通过提供标注的问答对,支持模型在真实文档场景下的测试。
2025年6月26日,阿里达摩院正式发布了全新的Qwen VLo大模型。这是继QwenVL和Qwen2.5 VL后,阿里在多模态大模型领域又一具有里程碑意义的创新。Qwen VLo是一款统一的多模态理解与生成模型,不仅具备深度理解图片与文本内容的能力,更能基于这种理解实现高质量和高度一致的图像生成与编辑,真正跨越了“感知”与“创造”的界限。

2025年11月24日,Anthropic正式发布了Programmatic Tool Calling (PTC)特性,允许Claude通过代码而非单次API调用来编排工具执行。这一创新被认为是Agent开发的重要突破,能够显著降低token消耗、减少延迟并提升准确性。 然而,作为minion框架的创建者,我想分享一个有趣的事实:minion从一开始就采用了这种架构理念。在PTC概念被正式提出之前,minion已经在生产环境中证明了这种方法的价值。
最近 Vibe Coding 的概念越来越热,尤其是 Gemini 3 Pro 发布后,很多人都在说:“现在做网站和 App,好像一句话就能生成。” 界面生成、交互补全、流程搭建这些事情确实越来越轻松,模型能在很短时间内产出一个“看起来完整”的应用原型。一个国产开源项目就在尝试解决这个问题,它就是 AipexBase。

就在今天,Anthropic正式发布Claude Opus 4.7,作为Opus 4.6的直接升级版本,这次更新的重点非常集中:软件工程能力的大幅提升、视觉理解的显著增强,以及一套全新的网络安全防护机制。值得一提的是,Opus 4.7并非Claude系列中能力最强的模型——那个头衔目前属于Claude Mythos Preview——但它是第一个面向大规模开放部署、同时配备完整安全体系的新一代旗舰模型。定价与Opus 4.6保持一致,即API输入25/百万token。
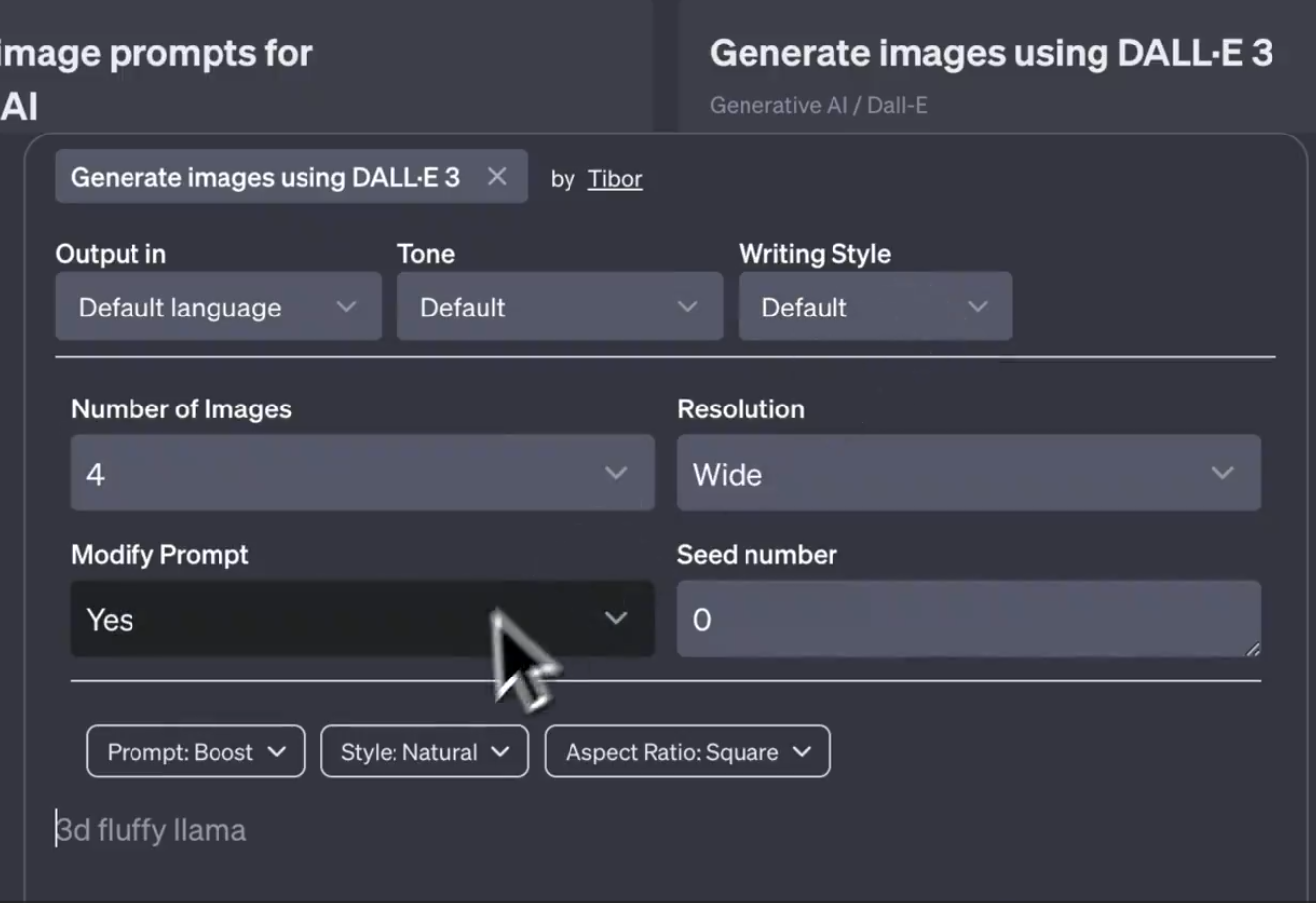
DALL·E3是OpenAI推出的文本生成图片服务,背后也是一个文生图大模型。此前,该模型只能通过对话的方式让模型生成图片结果。无法通过配置信息控制模型输出的效果,包括风格、比例等。而最新的截图显示,OpenAI可能即将推出DALL·E Controls功能,可以从不同的方面来控制图片生成的效果。
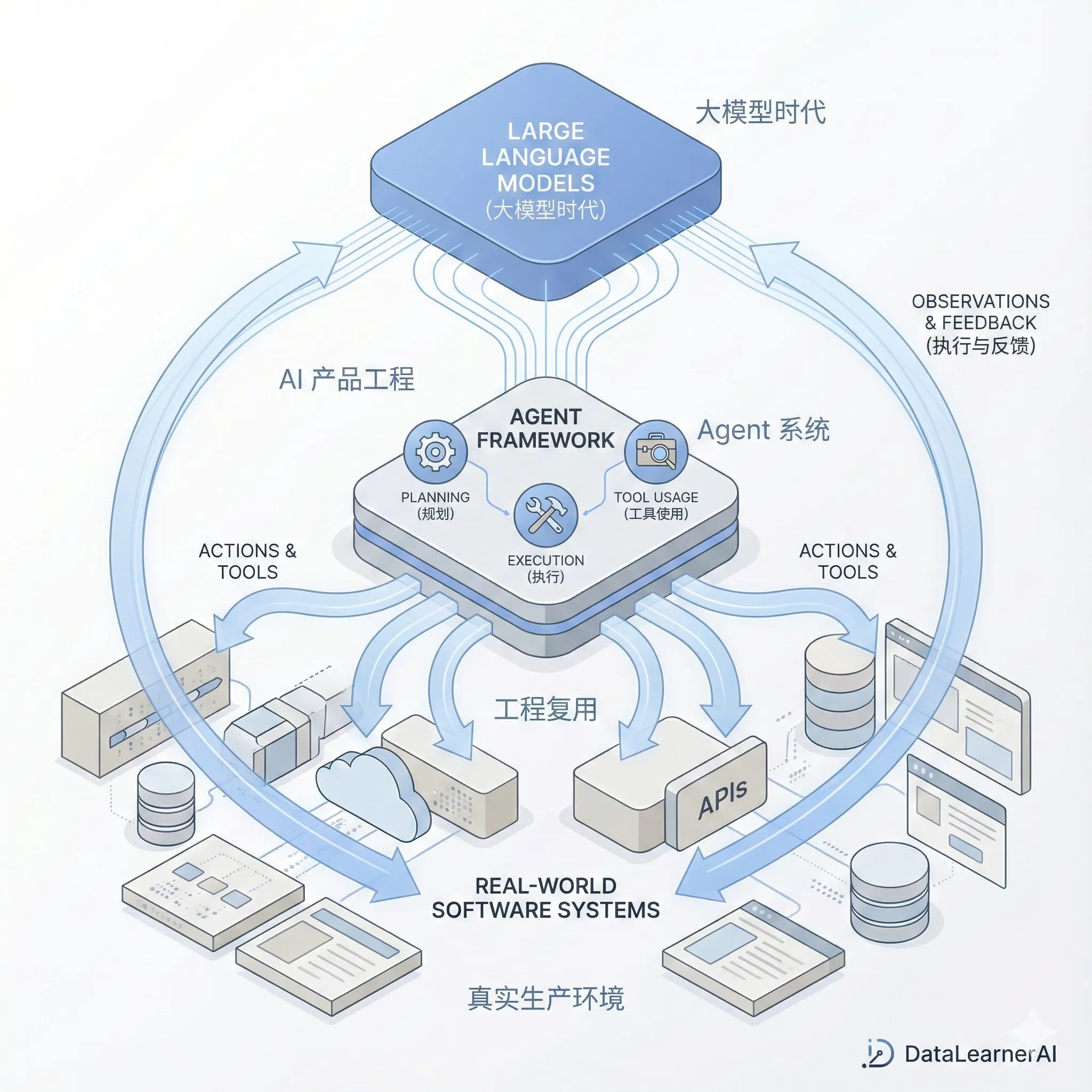
本文基于 Manus 一线工程成员的真实实践,总结并分析了 大模型时代 AI 产品在工程与复用层面发生的关键变化。文章并不关注模型参数或算法细节,而是聚焦于真实生产环境中的工程问题:功能交付的责任边界如何变化、为何原型验证比完整规划更重要,以及在 Agent 系统中个人角色与系统边界如何被重新定义。这些经验揭示了一个趋势——在大模型具备“执行能力”之后,AI 产品的可用性越来越依赖工程体系本身,而非模型能力本身。本文适合关注 AI 工程实践、Agent 架构以及大模型落地问题的技术读者参考。
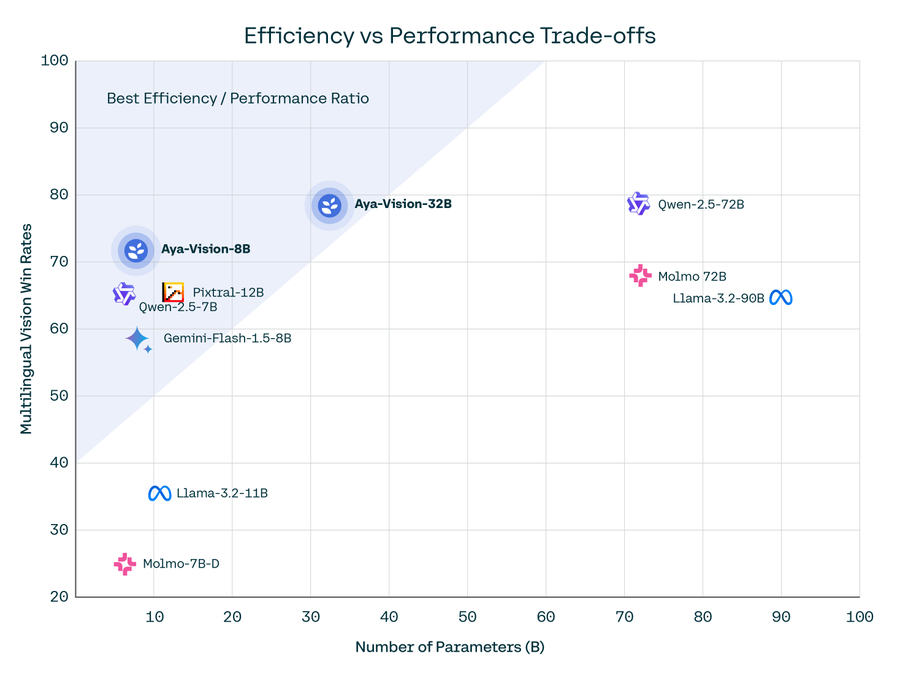
Cohere For AI 推出了 Aya Vision 系列,这是一组包含 80 亿(8B)和 320 亿(32B)参数的视觉语言模型(VLMs)。这些模型针对多模态AI系统中的多语言性能挑战,支持23种语言。Aya Vision 基于 Aya Expanse 语言模型,并通过引入视觉语言理解扩展了其能力。该系列模型旨在提升同时需要文本和图像理解的任务性能。
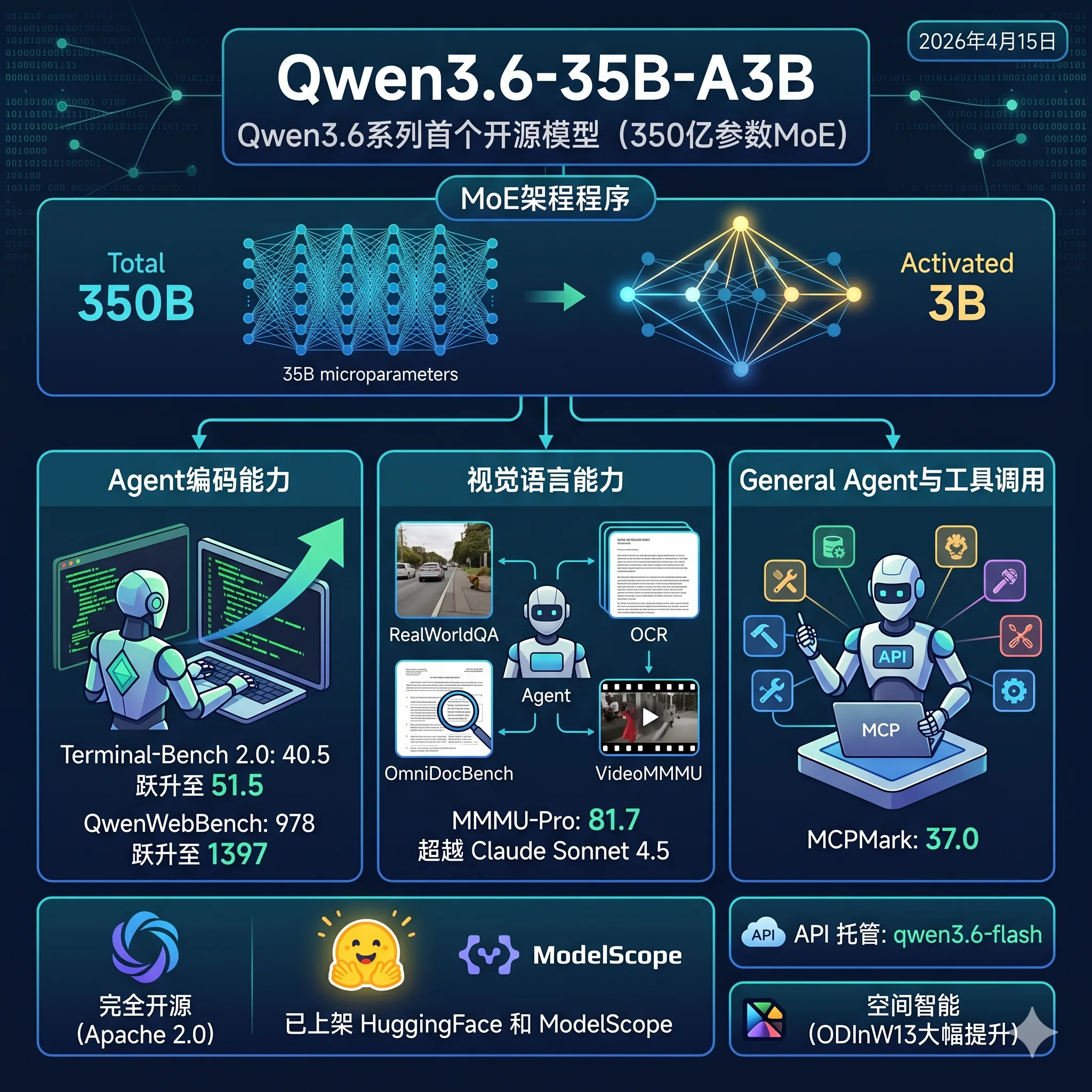
阿里开源Qwen3.6-35B-A3B,350亿总参数仅激活30亿,Terminal-Bench 2.0得分51.5,SWE-bench Verified 73.4,视觉多项超越Claude Sonnet 4.5,Apache 2.0开源。
2026年4月2日,Google DeepMind 正式发布了 Gemma 4 系列模型。自2024年首代 Gemma 发布以来,开发者已经累计下载超过4亿次,并在此基础上衍生出超过10万个变体版本,形成了所谓的"Gemmaverse"社区生态。这次的 Gemma 4,Google 不只是做了常规的性能升级,而是在许可证、模型架构和部署覆盖范围上同时迈出了一大步。
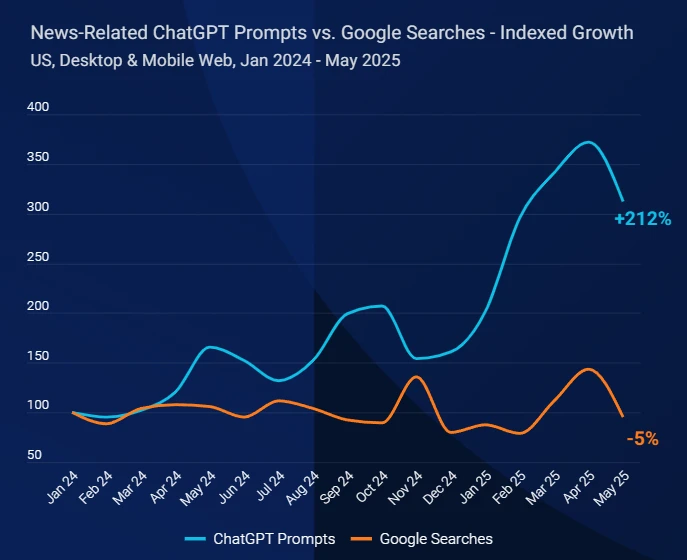
今天,SimilarWeb发布了一个全新的报告,描述了自从ChatGPT这种大模型产品发布之后,新闻出版网站的流量下滑严重,并提供了相关的分析。尽管这是针对新闻网站的报告,但是实际上所有的内容网站或者是内容生产者可能都是有影响的。我们基于这份报告进行解读,为大家提供一个参考。
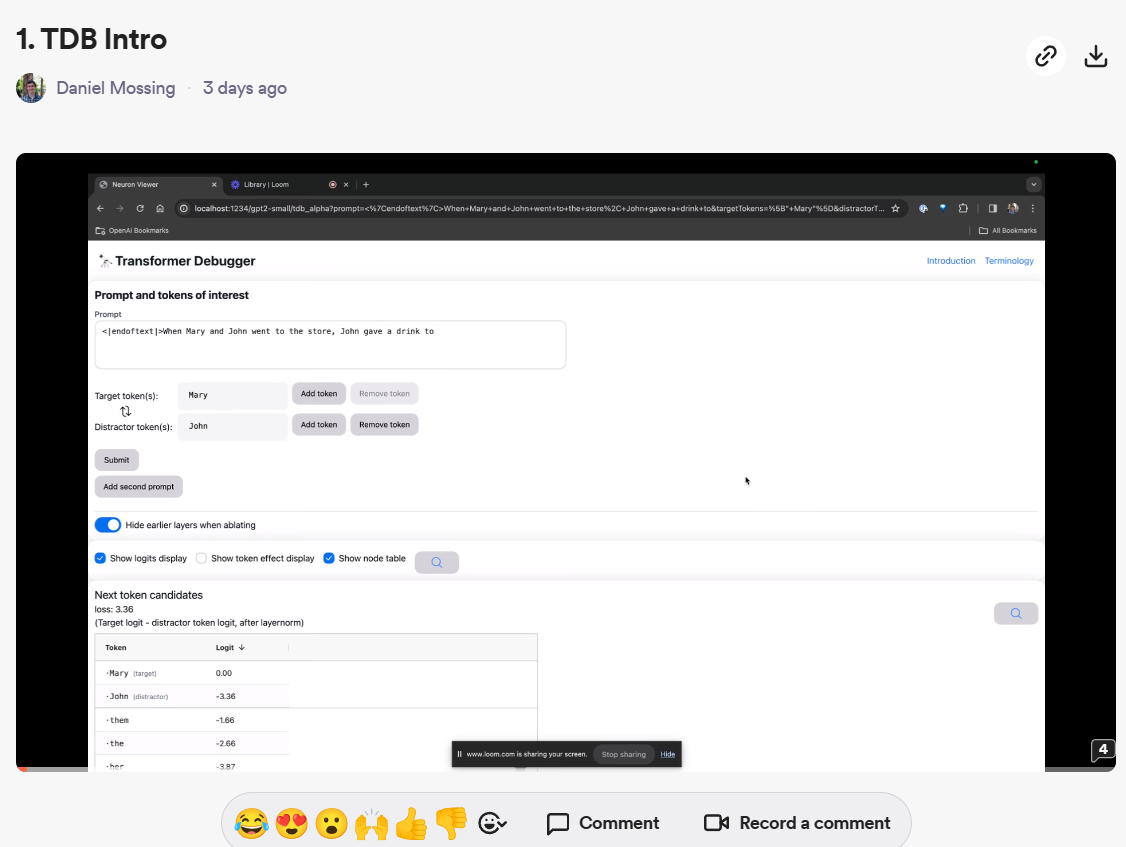
自从OpenAI转向盈利化运营之后,很少再开源自己的技术。但就在刚才,OpenAI开源了一个全新的大模型调测工具:Transformer Debugger。这个工具可以帮助开发者调测大模型的推理情况,帮助我们理解模型的输出并提供一定的解释支持。

编程领域大模型一直是进展非常快的大模型领域。因为编程能力更强的模型,通常在逻辑思维、工具调用上有更好的表现,在很多领域,特别是Agent领域有很大的应用价值。今天法国人工智能明星公司MistralAI发布了2个全新的编程大模型,分别是Devstral Medium和 Devstral Small 1.1,后者是一个开源的240亿参数的编程大模型。

Mistral AI今天发布了其首个专注于推理能力的系列模型——**Magistral**。这次发布包含两个核心模型:旗舰模型`Magistral Medium`和<font color=red>已开源的</font>`Magistral Small (24B)`。最引人注目的亮点是,Mistral展示了其自研的强化学习(RL)pipeline能够从头开始,仅通过RL训练就将基础模型的推理能力提升到业界顶尖水平,而无需依赖任何其他预先存在的推理模型进行数据蒸馏。这套技术栈非常强大!
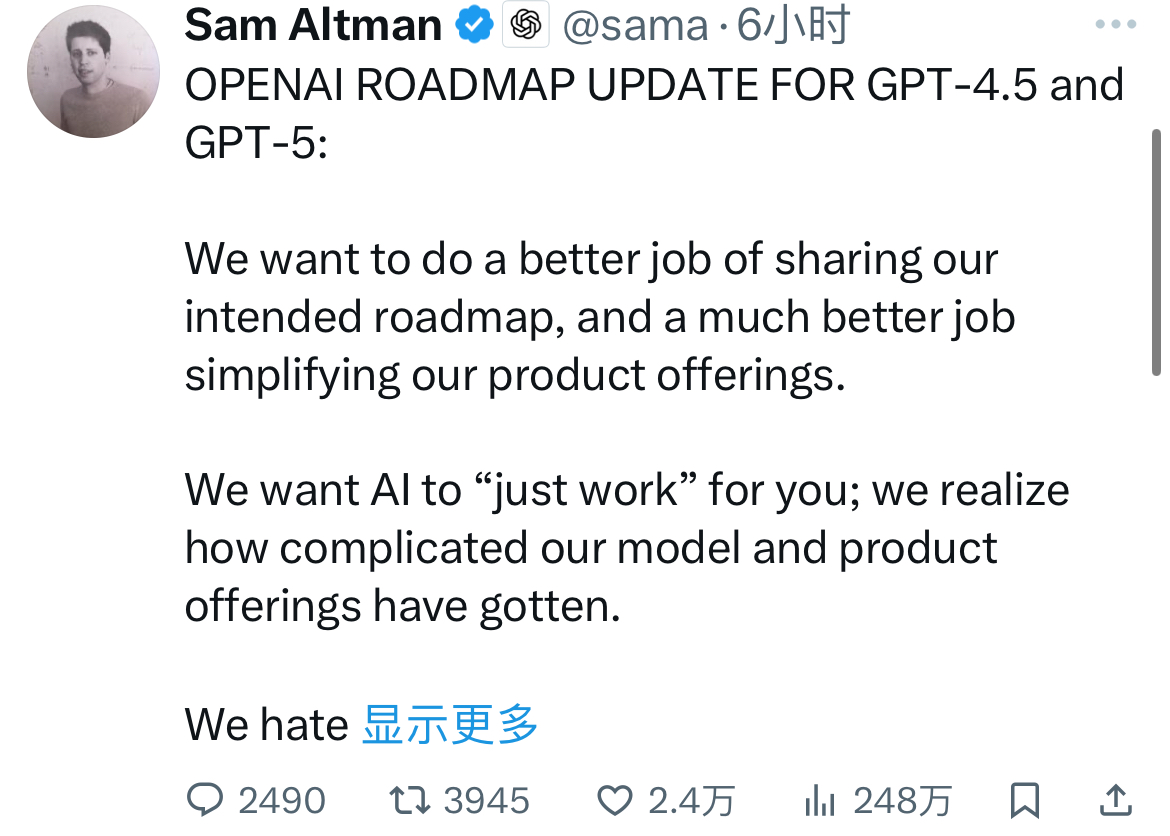
三个小时前,Sam Altam在推特上说明了OpenAI未来的大模型路线图。比较重磅的消息是即将在未来几周发布GPT-4.5,并且在几个月后发布GPT-5。

尽管人工智能语言模型的能力日益强大,但它们依然面临一个棘手的问题:“幻觉”(Hallucination)。所谓幻觉,指的是模型自信地生成一个事实上错误的答案。OpenAI 的最新研究论文指出,这一现象的根源在于标准的训练和评估方式实际上在鼓励模型“猜测”而非“承认不确定性”。
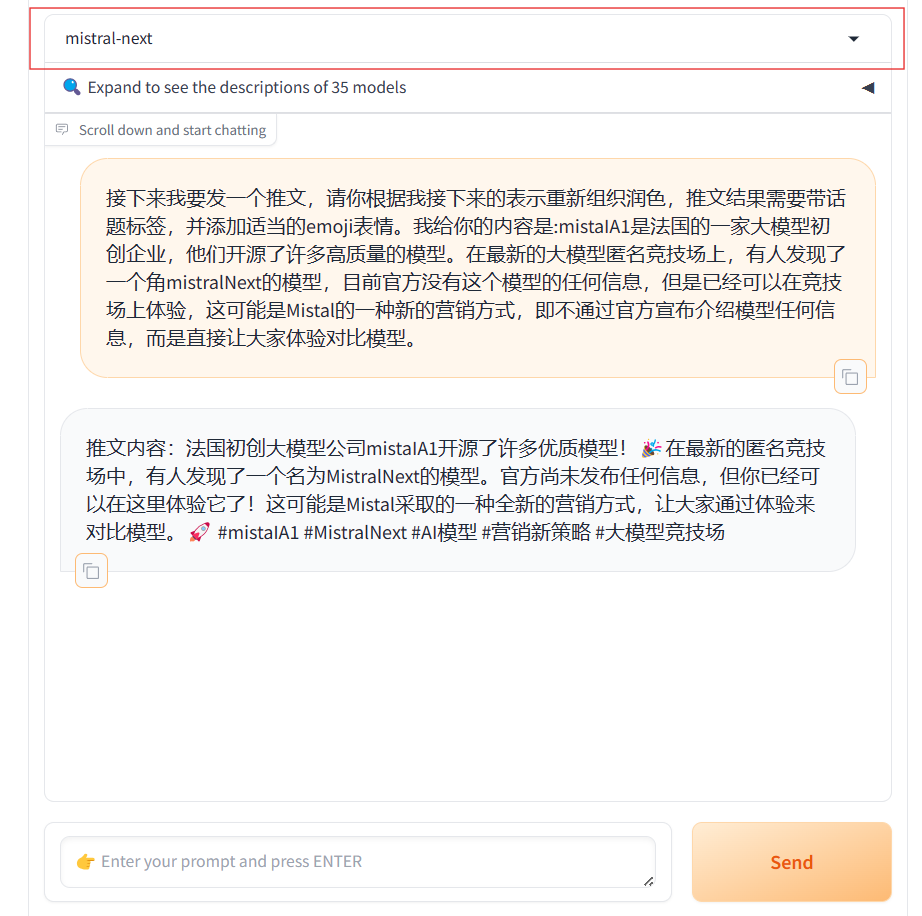
MistralAI又悄悄地上线了另一个模型,即Mistral Next。相比之前的发布预训练种子引起大家猜测的方式,本次MistralAI又把模型发布玩出了花,他们没有公布任何信息,选择直接上架LM-SYS的大模型竞技场Chat Arena,让大家直接体验对比。

在几个小时前,OpenAI开源了两款名为gpt-oss-120b和gpt-oss-20b的大语言模型。这是自GPT-2以来,OpenAI首次推出开源权重大语言模型,这两个模型的评测效果达到了o4-mini和o3-mini的水平,而且以Apache 2.0协议开源,大家可以自由使用,包括任何形式的商用。
BrowseComp是一个用于评估AI代理网页浏览能力的基准测试。它包含1266个问题,这些问题要求代理在互联网上导航以查找难以发现的信息。该基准关注代理在处理多跳事实和纠缠信息时的持久性和创造性。OpenAI于2025年4月10日发布此基准,并将其开源在GitHub仓库中。

LiveBench是一个针对大型语言模型(LLM)的基准测试框架。该框架通过每月更新基于近期来源的问题集来评估模型性能。问题集涵盖数学、编码、推理、语言理解、指令遵循和数据分析等类别。LiveBench采用自动评分机制,确保评估基于客观事实而非主观判断。基准测试的总问题数量约为1000个,每月替换约1/6的问题,以维持测试的有效性。