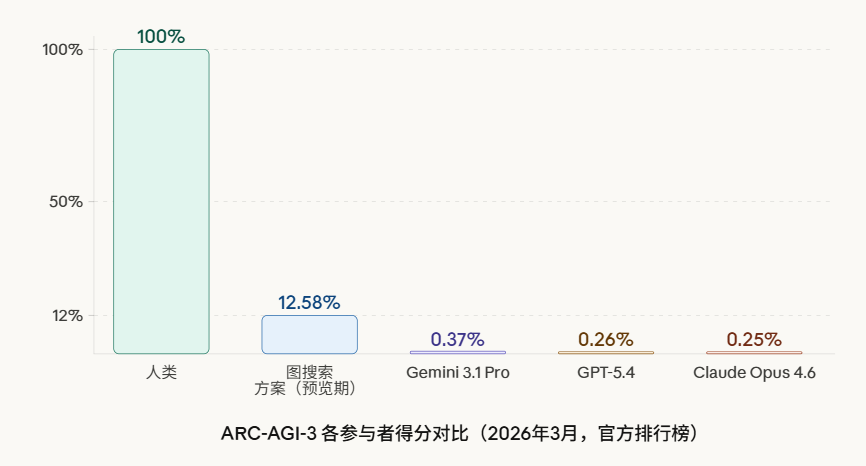
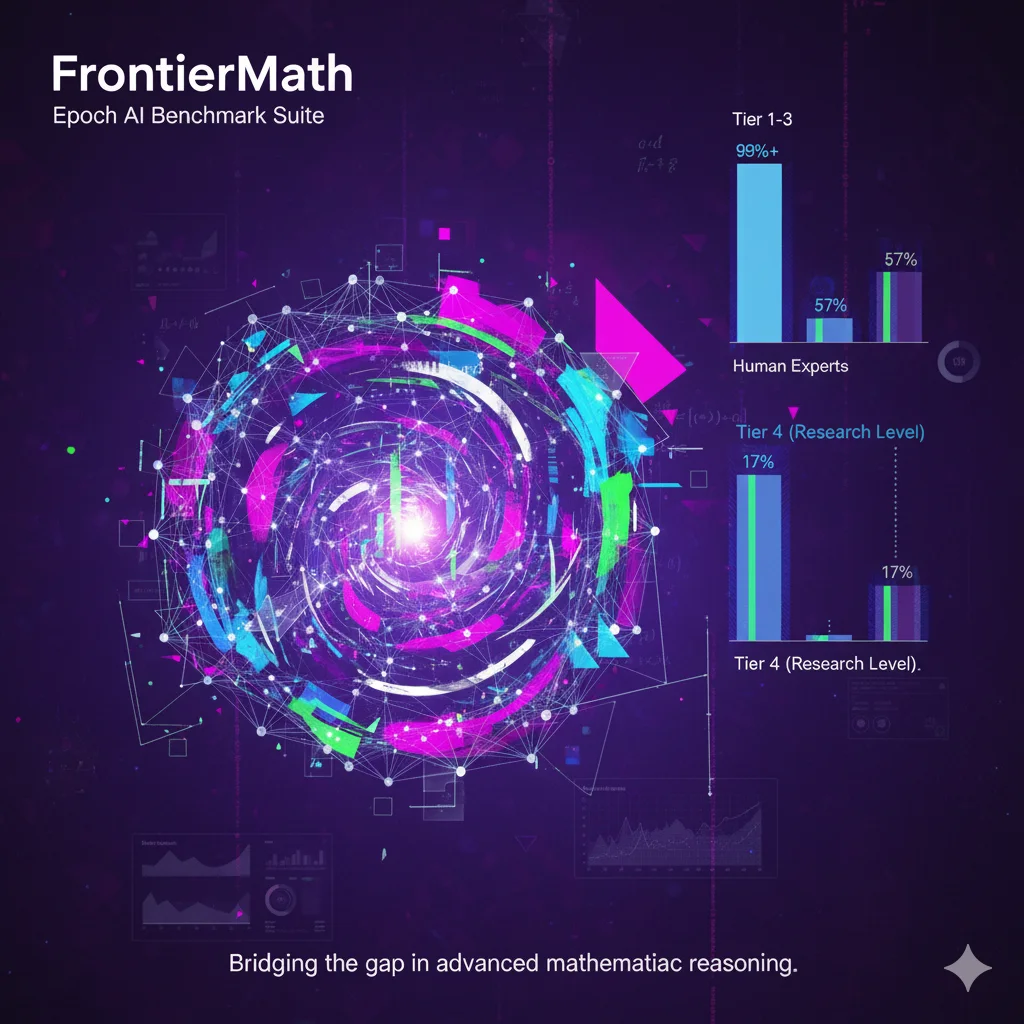
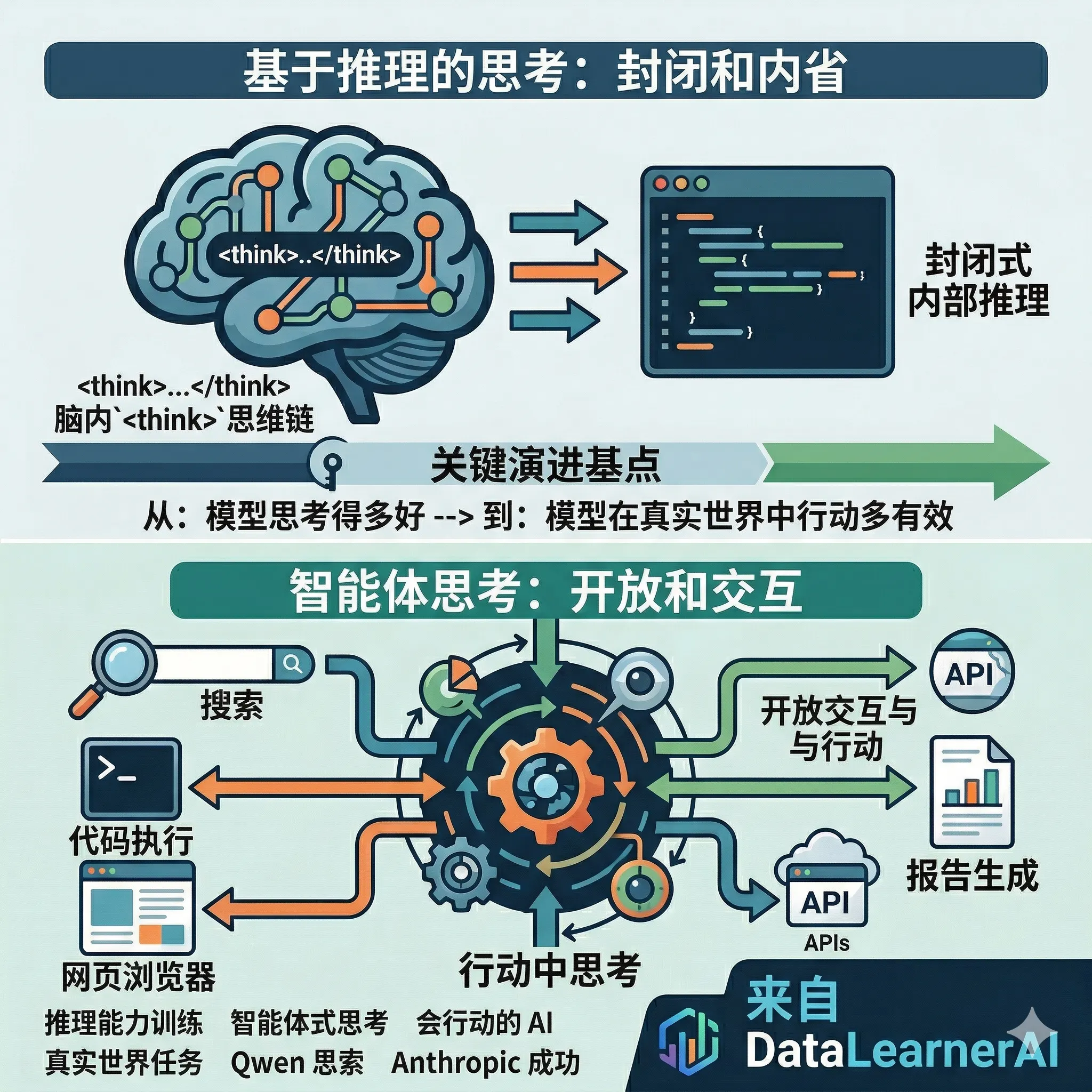
IMO-Bench:谷歌发布的用于大模型数学推理的鲁棒评估基准
IMO-Bench 是 Google DeepMind 开发的一套基准测试套件,针对国际数学奥林匹克(IMO)水平的数学问题设计,用于评估大型语言模型在数学推理方面的能力。该基准包括三个子基准:AnswerBench、ProofBench 和 GradingBench,涵盖从短答案验证到完整证明生成和评分的全过程。发布于 2025 年 11 月,该基准通过专家审核的问题集,帮助模型实现 IMO 金牌级别的性能,并提供自动评分机制以支持大规模评估。