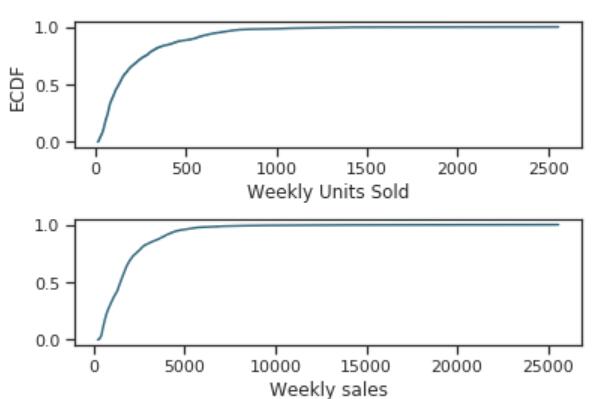
考虑价格和促销影响的销售预测算法实践
这是一篇来自Towards Data Science上面的一篇个人实践分享,主要是针对销量进行预测。一般来说,销量受到价格、季节等因素影响较大。这里就是考虑这些因素进行的一个实践。值得大家一试。这里我们翻译一下,并对其中的某些工作做一些简单的解释。
聚焦人工智能、大模型与深度学习的精选内容,涵盖技术解析、行业洞察和实践经验,帮助你快速掌握值得关注的AI资讯。
这是一篇来自Towards Data Science上面的一篇个人实践分享,主要是针对销量进行预测。一般来说,销量受到价格、季节等因素影响较大。这里就是考虑这些因素进行的一个实践。值得大家一试。这里我们翻译一下,并对其中的某些工作做一些简单的解释。

Scikit-Learn有很优秀的机器学习处理思想,包括TensorFlow等新框架都借鉴了它的设计思想。最近的更新也让Scikit-Learn更加强大。在描述这个更新之前我们先简单看一下历史,然后让我们一起看看都有什么新内容吧。

TensorFlow中常见的错误解释及解决方法
Batch Normalization是深度学习中最重要的技巧之一。是由Sergey Ioffe和Christian Szeged创建的。Batch Normalization使超参数的搜索更加快速便捷,也使得神经网络鲁棒性更好。本篇博客将简要介绍相关概念和原理。
这是一个新大陆,有博客园,算法区,技术堡,论文馆,数据林,工具库。尽情畅游吧!


Tensorflow中tf.data.Dataset是最常用的数据集类,我们也使用这个类做转换数据、迭代数据等操作。本篇博客将简要描述这个类的使用方法。
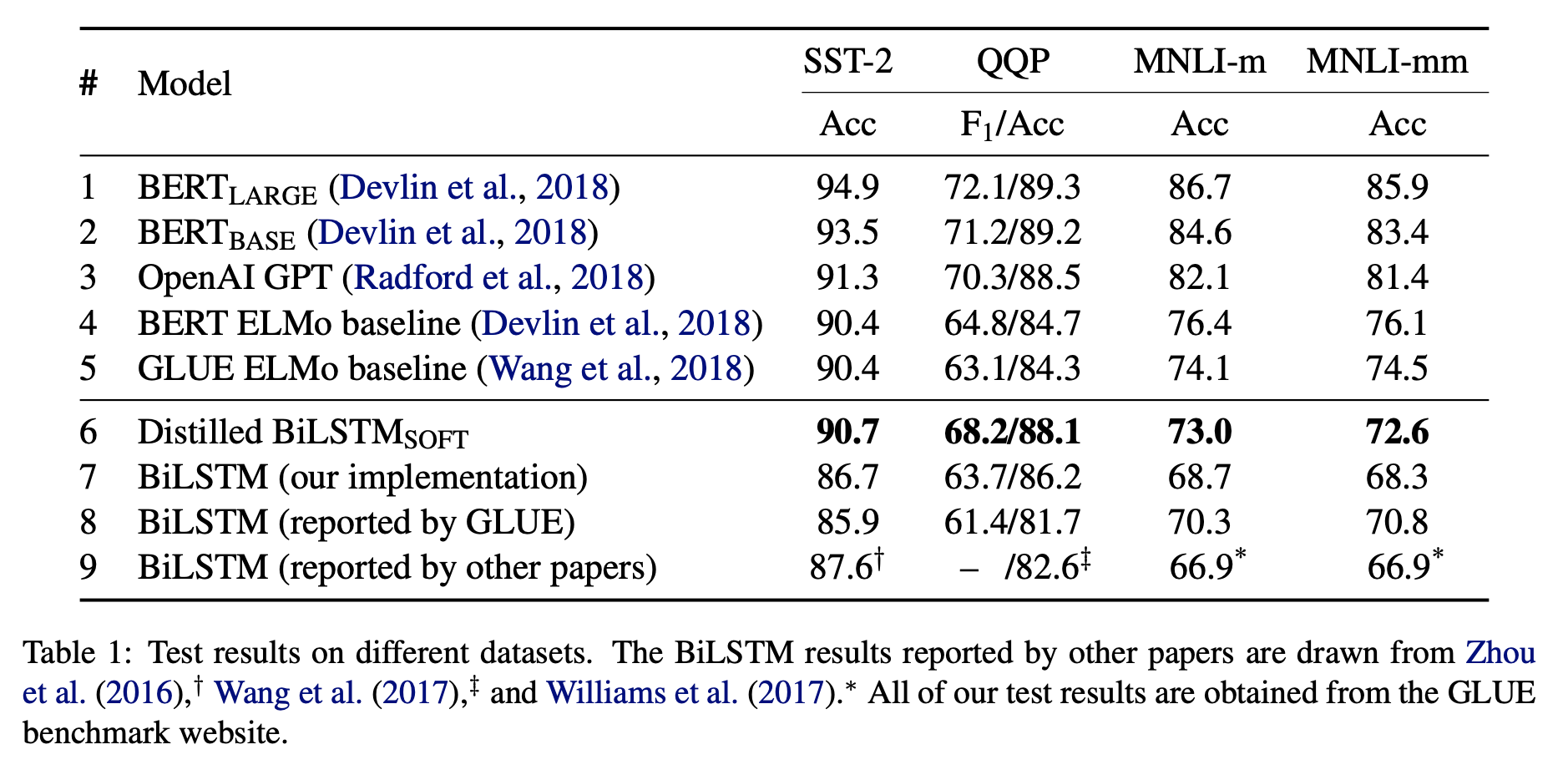
BERT是很好的模型,但是它的参数太大,网络结构太复杂。在很多没有GPU的环境下都无法部署。本文讲的是如何利用BERT构造更好的小的逻辑回归模型来代替原始BERT模型,可以放入生产环境中,以节约资源。
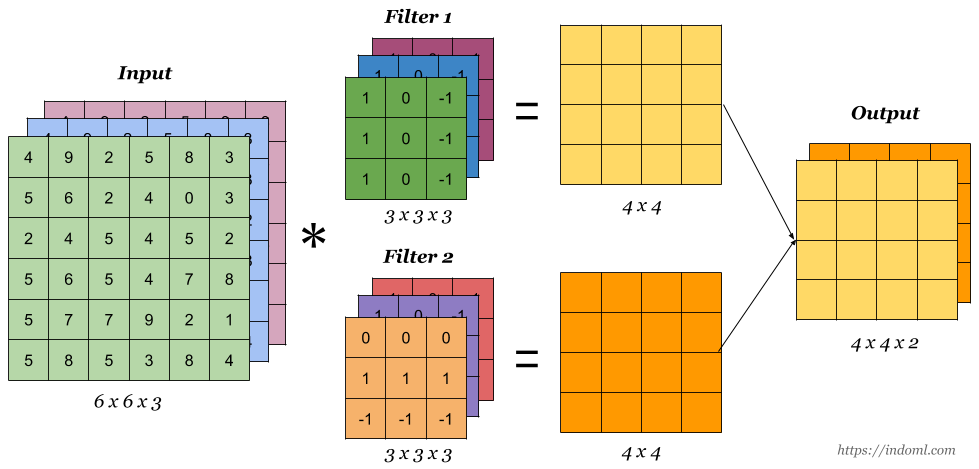
卷积操作的维度计算是定义神经网络结构的重要问题,在使用如PyTorch、Tensorflow等深度学习框架搭建神经网络的时候,对每一层输入的维度和输出的维度都必须计算准确,否则容易出错,这里将详细说明相关的维度计算。
深度学习本质上是表示学习,它通过多层非线性神经网络模型从底层特征中学习出对具体任务而言更有效的高级抽象特征。针对一个具体的任务,我们往往会遇到这种情况:需要用一个模型学习出特征表示,然后将学习出的特征表示作为另一个模型的输入。这就要求我们会获取模型中间层的输出,下面以具体代码形式介绍两种具体方法。
Keras框架下的保存模型和加载模型
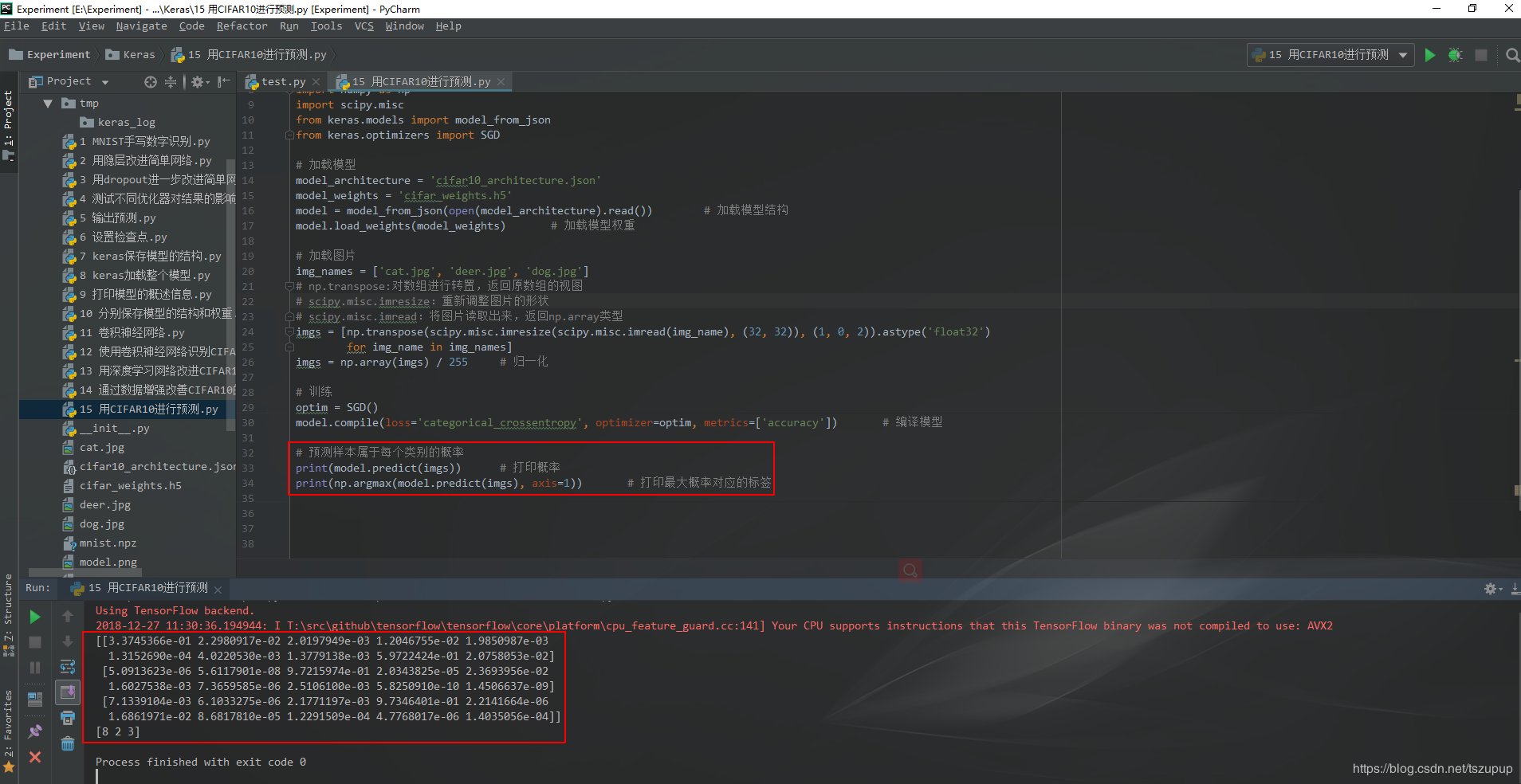
Keras中predict()方法和predict_classes()方法的区别
TensorFlow基本概念
tf.nn.softmax_cross_entropy_with_logits函数
Microsoft Visual C++ 14.0 is required
之前面的博客中,我们已经描述了基本的RNN模型。但是基本的RNN模型有一些缺点难以克服。其中梯度消失问题(Vanishing Gradients)最难以解决。为了解决这个问题,GRU(Gated Recurrent Unit)神经网络应运而生。本篇博客将描述GRU神经网络的工作原理。GRU主要思想来自下面两篇论文:
在前面的博客中,我们已经介绍了基本的RNN模型和GRU深度学习网络,在这篇博客中,我们将介绍LSTM模型,LSTM全称是Long Short-Time Memory,也是RNN模型的一种。

使用预训练模型处理NLP任务是目前深度学习中一个非常火热的领域。本文总结了8个顶级的预训练模型,并提供了每个模型相关的资源(包括官方文档、Github代码和别人已经基于这些模型预训练好的模型等)。
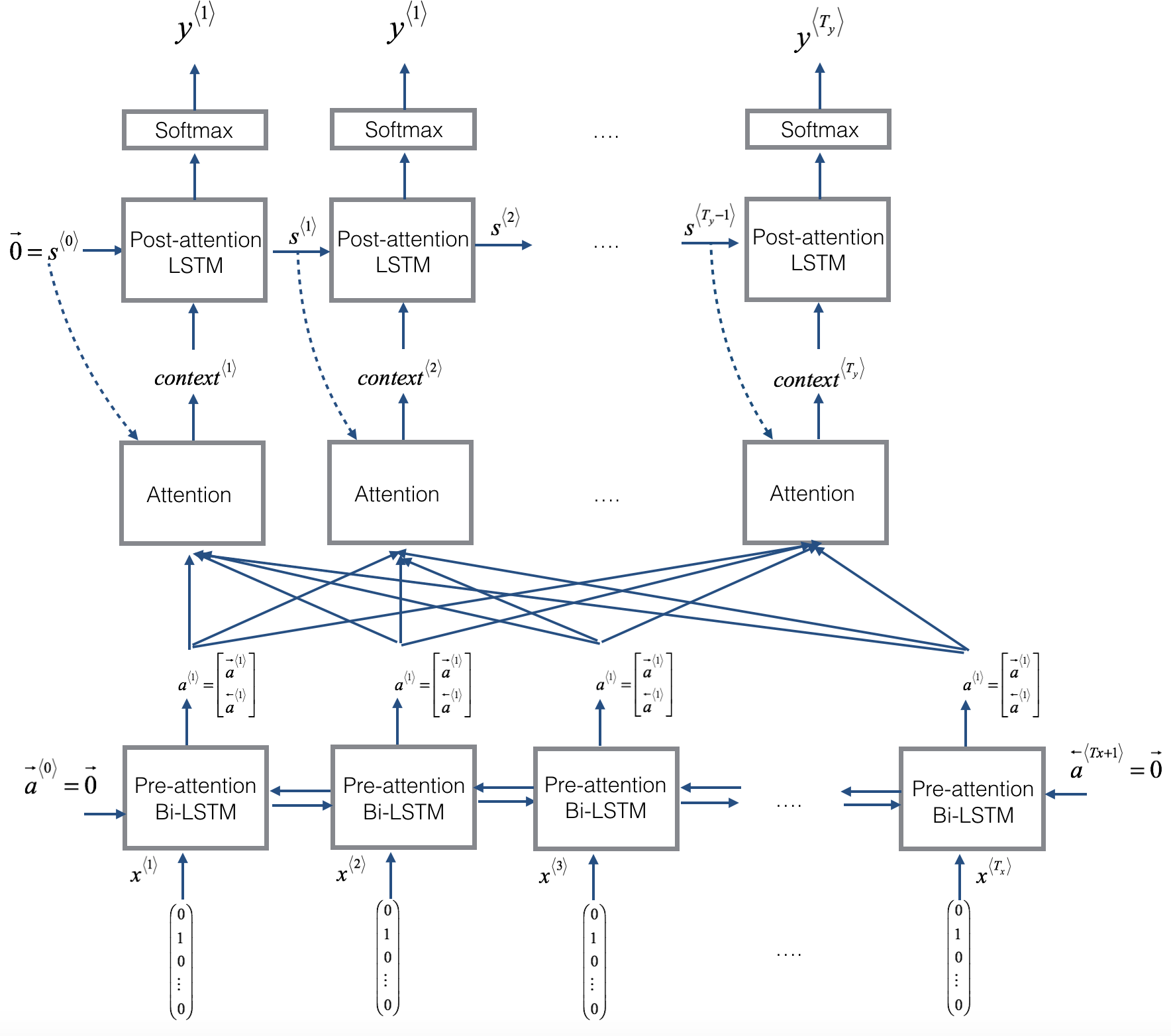
Encoder-Decoder的深度学习架构是目前非常流行的神经网络架构,在许多的任务上都取得了很好的成绩。在之前的博客中,我们也详细介绍了该架构(参见深度学习之Encoder-Decoder架构)。本篇博客将详细讲述Attention机制。

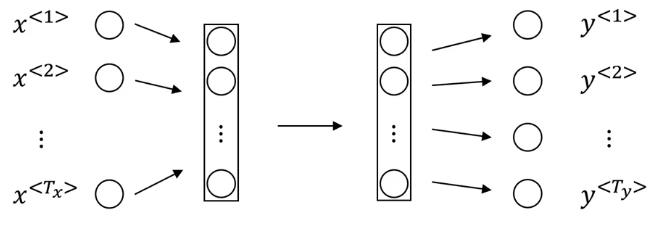
深度学习中Sequence to Sequence (Seq2Seq) 模型的目标是将一个序列转换成另一个序列。包括机器翻译(machine translate)、会话识别(speech recognition)和时间序列预测(time series forcasting)等任务都可以理解成是Seq2Seq任务。RNN(Recurrent Neural Networks)是深度学习中最基本的序列模型。
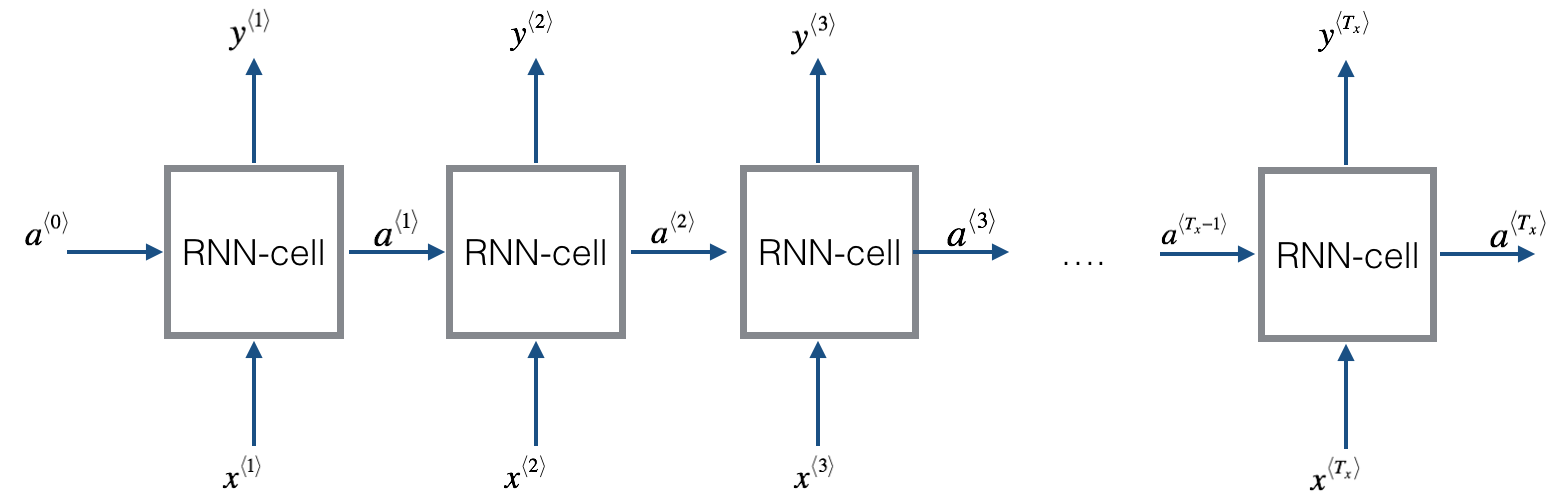
序列数据是生活中很常见的一种数据,如一句话、一段时间某个广告位的流量、一连串运动视频的截图等。在这些数据中也有着很多数据挖掘的需求。RNN就是解决这类问题的一种深度学习方法。其全称是Recurrent Neural Networks,中文是递归神经网络。主要解决序列数据的数据挖掘问题。

R语言进行数据分析非常简单方便,在这篇博客中,我们将描述如何使用R语言进行K-means聚类分析,并分析结果。