
什么时候该使用推理大模型?OpenAI官方推出推理大模型和大语言模型的最佳使用指南
随着DeepSeek R1和OpenAI的o1、o3等推理大模型的发布,我们当前可使用的大模型种类也变多了。但是,推理大模型和普通大模型之间并不是二选一的关系,在不同的问题上二者各有优势。为了让大家更清晰理解推理大模型和普通大模型的应用场景。OpenAI官方推出了一个推理大模型最佳实践指南。描述了二者的对比。本文将总结这份推理大模型最佳实践指南。
Explore the latest AI and LLM news and technical articles, covering original content and practical cases in machine learning, deep learning, and natural language processing.
随着DeepSeek R1和OpenAI的o1、o3等推理大模型的发布,我们当前可使用的大模型种类也变多了。但是,推理大模型和普通大模型之间并不是二选一的关系,在不同的问题上二者各有优势。为了让大家更清晰理解推理大模型和普通大模型的应用场景。OpenAI官方推出了一个推理大模型最佳实践指南。描述了二者的对比。本文将总结这份推理大模型最佳实践指南。

就在几个小时前,阿里巴巴开源了最新的一个推理大模型,QwQ-32B,该模型拥有类似o1、DeepSeek R1模型那样的推理能力,但是参数仅325亿,以Apache 2.0开源协议开源,这意味着大家可以完全免费商用。

LiveCodeBench 由加州大学伯克利分校、麻省理工学院和康奈尔大学的研究人员开发,是一个先进的评测基准套件,专门用于严格评估大语言模型 (LLMs) 在代码处理方面的能力,并解决现有基准测试的局限性。通过引入实时更新的问题集和多维度评估方法,LiveCodeBench 确保对 LLM 进行公平、全面和稳健的评估。
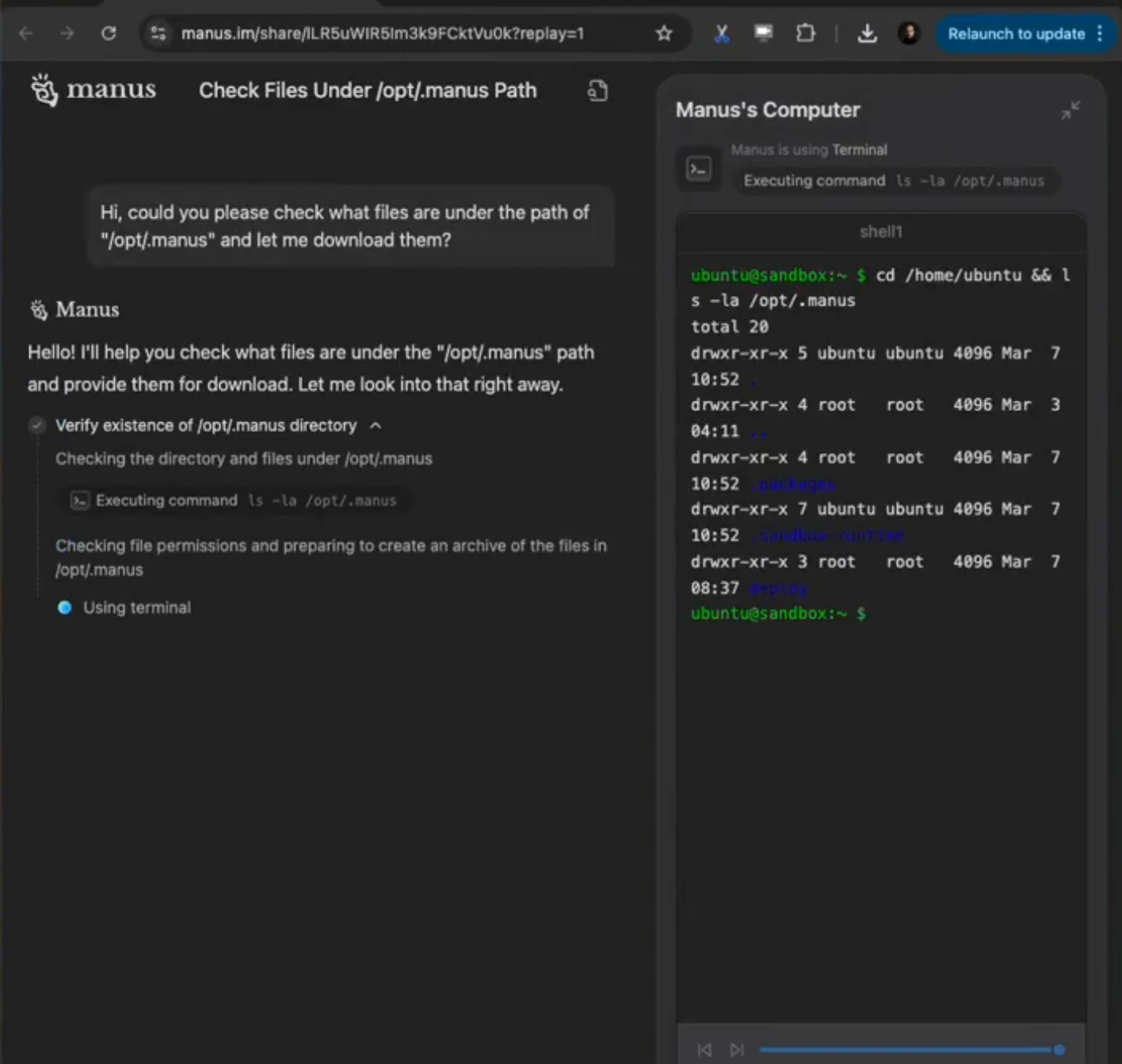
就在今天,X平台上的一位博主发现可以通过指令让Manus返回它的系统情况,发现ManusAI是Claude Sonnet 3.7+29个工具组成的一个大模型应用系统,也让很多人认为这就是ManusAI的全部,那么这是真的吗?本文结合ManusAI的成员提供的信息为大家介绍。
Hunyuan大模型是腾讯训练的大模型品牌名,2022年4月份,某中文语言理解能力排行榜第一名就出现了Hunyuan模型,在2022年11月,Hunyuan大模型就有了1万亿参数的规模,即HunYuan-NLP 1T大模型(比ChatGPT还早发布)。但是最近2年,这个系列的模型几乎没有出现在公众视野上。而昨天(2025年3月10日),Hunyuan官方在X平台上宣布了旗下最新的Hunyuan Turbo S大模型,称其在多个评测基准上超越了GPT-4o的表现。
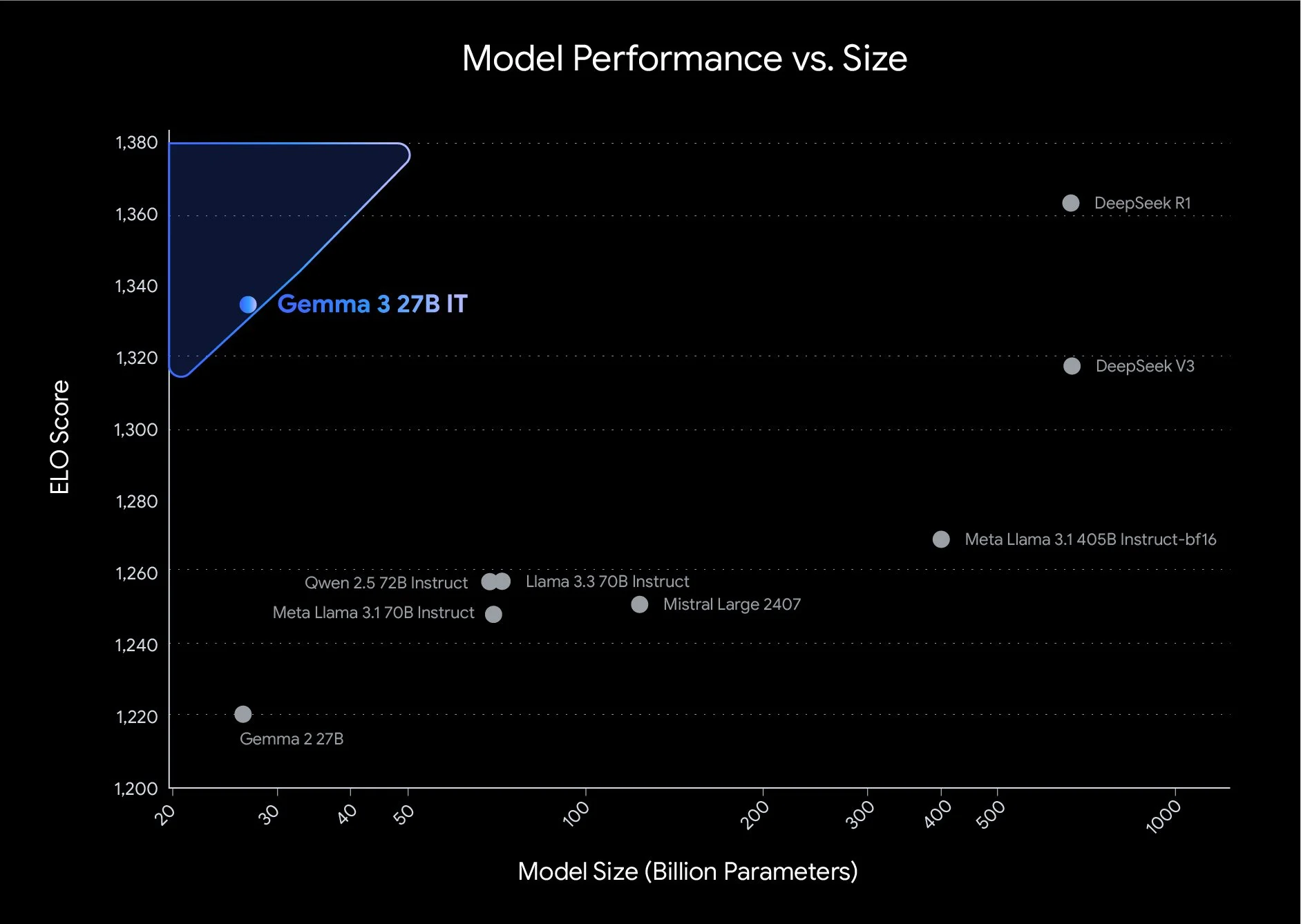
Gemma系列大模型是Google开源的一系列轻量级的大模型。就在刚才(2025年3月12日),Google开源了第三代Gemma系列大模型,共包含4个不同参数规模版本,第三代的Gemma 3系列是多模态大模型,即使是最小的10亿参数规模的Gemma 3-1B也支持多模态输入。
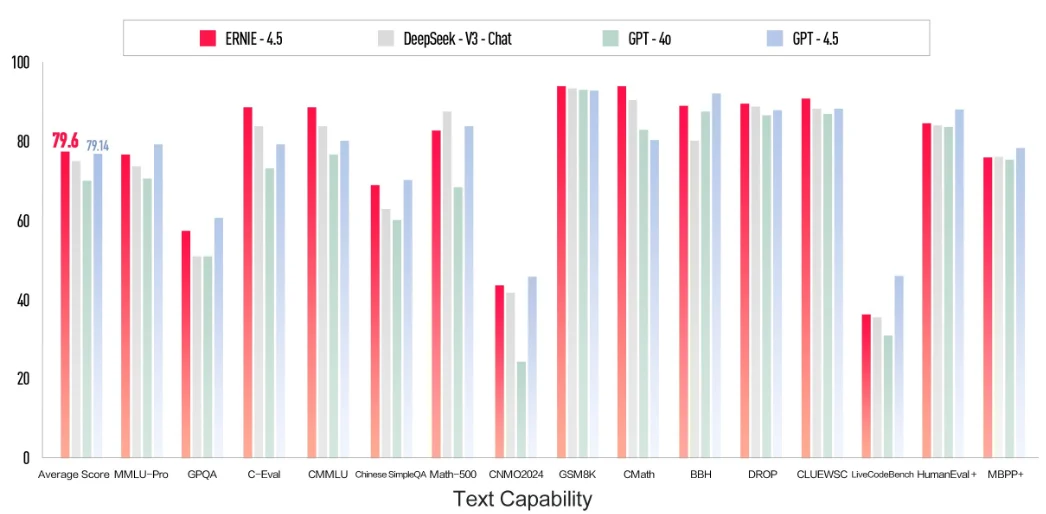
3月16日,百度宣布推出两款新一代文心大模型——ERNIE 4.5与ERNIE X1,并提前向公众免费开放其智能对话平台“文心一言”(ERNIE Bot)。官方宣称,这两款模型的能力均超过了GPT-4o,但是价格只有GPT-4o的1%,且是DeepSeek的一半。

研究生级别的 **Google 防查找问答基准测试**(即Graduate-Level Google-Proof Q&A Benchmark,简称 GPQA)是大型语言模型(LLM)面临的最具挑战性的评估之一。GPQA 旨在推动人工智能能力的极限,提供一个严格的测试平台,不仅评估模型的事实记忆能力,还考察其在专业科学领域的深度推理和理解能力。本篇博文将客观介绍 GPQA,涵盖它的起源、目的、组成部分,以及领先的大型语言模型在这个高要求基准测试中的表现。
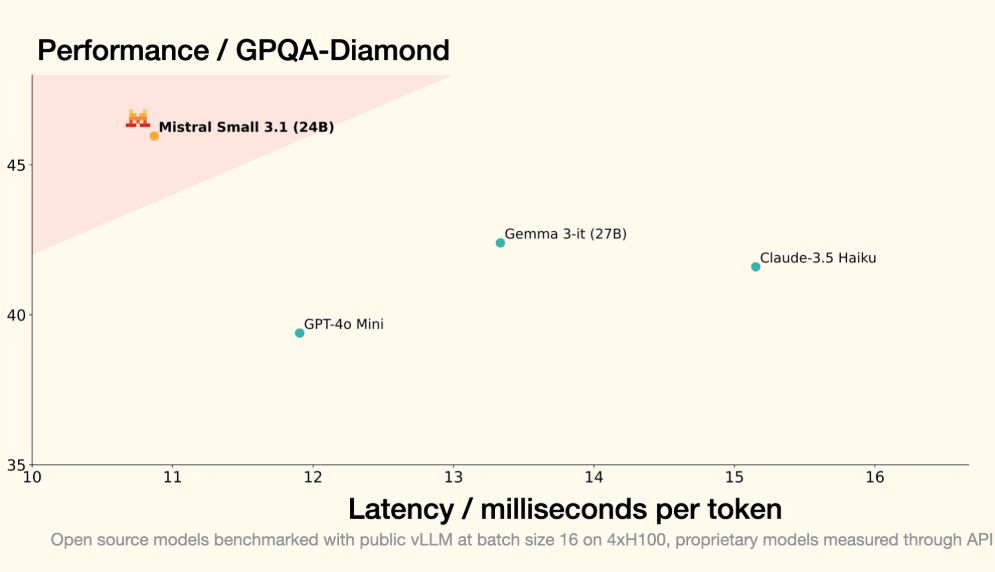
欧洲大模型之光MistralAI开源了2个全新的多模态大模型,即Mistral-Small-3.1-24B基座版本和指令微调版本。这两个大模型均以Apache2.0协议开源,因此可以完全免费商用。而官方也给出了这个模型在多个评测集上的效果,高于GPT-4o-mini和Gemma 3 27B。因为其参数规模较小,推理速度可以达到每秒150个tokens,同时支持多种语言,是一个非常值得关注的小而美的多模态大模型。
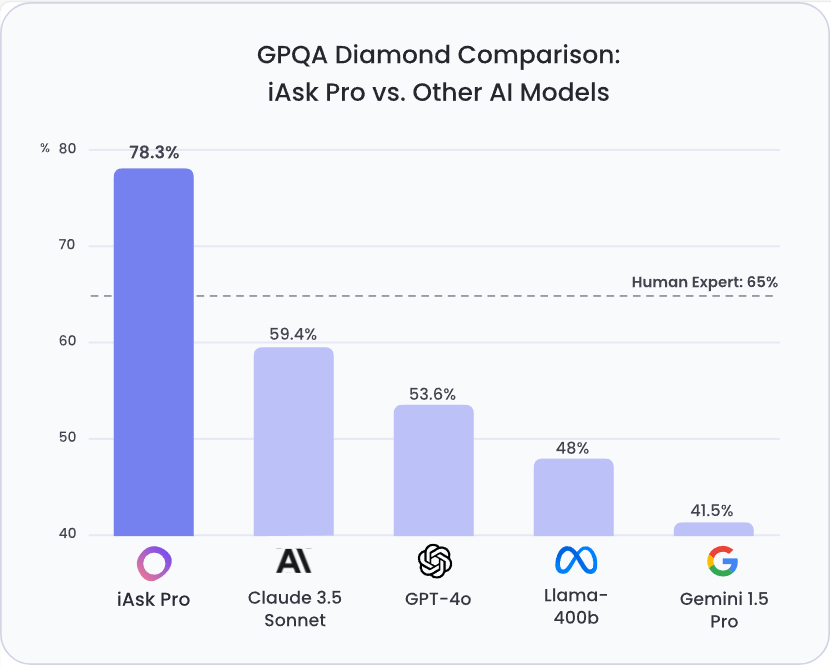
通用人工智能(AGI)的进步需要可靠的评估基准。GPQA (Grade-Level Problems in Question Answering) Diamond 基准旨在衡量模型在需要深度推理和领域专业知识问题上的能力。该基准由纽约大学、CohereAI 及 Anthropic 的研究人员联合发布,其相关论文可在 arXiv 上查阅 (https://arxiv.org/pdf/2311.12022 )。GPQA Diamond是GPQA系列中最高质量的评测数据,包含198条结果。
2025年3月20日,OpenAI 推出了三款新模型——gpt-4o-transcribe、gpt-4o-mini-transcribe 和 gpt-4o-mini-tts——标志着自动语音识别 (ASR) 和文本转语音 (TTS) 领域的重要进步。这些模型基于 GPT-4o 架构,旨在为开发人员和用户提高准确性、自定义能力和可访问性,与 OpenAI 对于代理式 AI 系统的更广泛愿景一致。本文提供了对每个模型、其能力、定价、可用性和竞争环境的详细审查,确保技术和非技术受众都能全面理解。
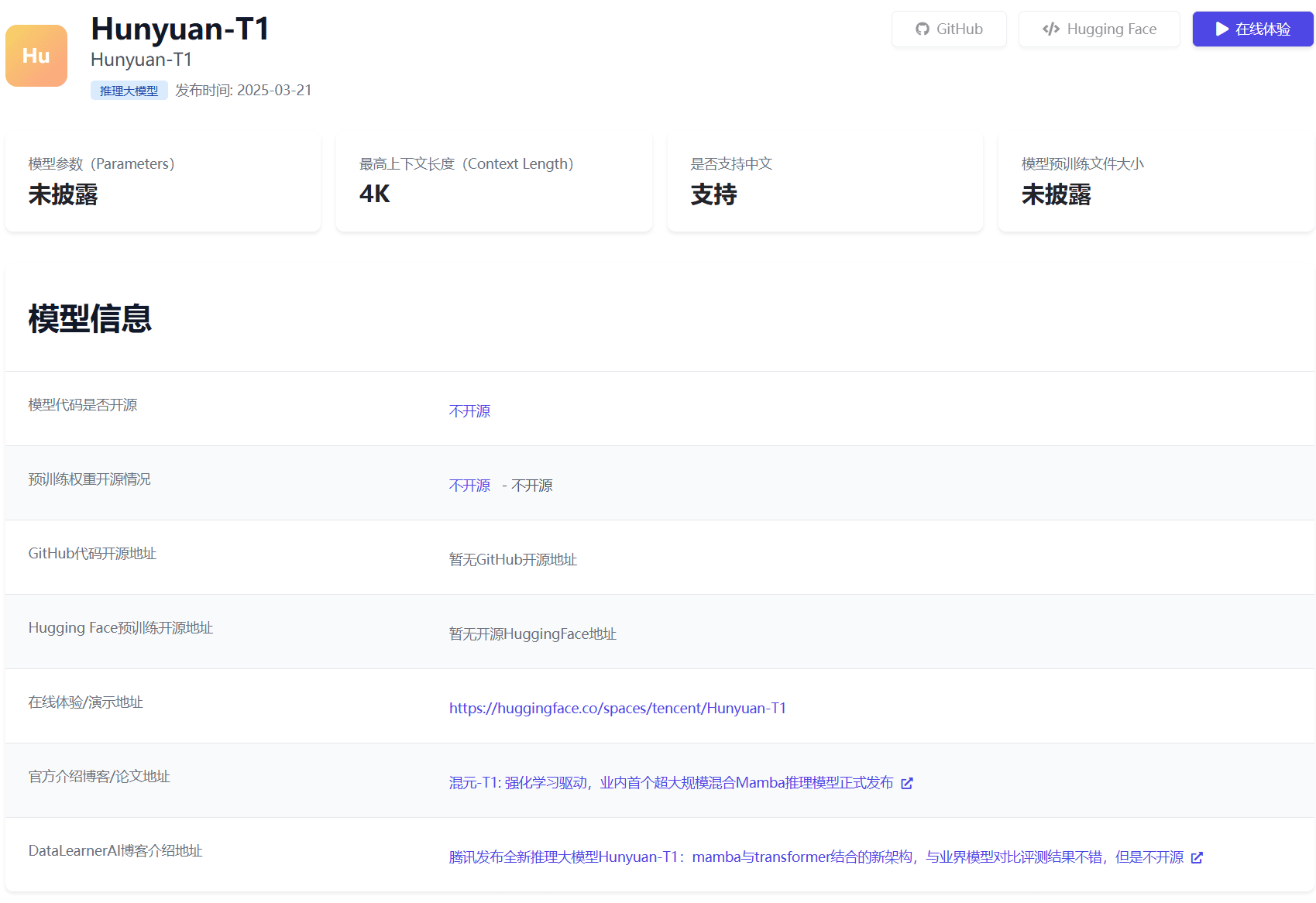
2025年3月21日,腾讯正式推出其全新大模型**Hunyuan-T1**,该模型基于此前发布的TurboS快速思维基座,首次采用**Hybrid-Transformer-Mamba混合专家架构(MoE)**,在推理效率、长文本处理及资源消耗优化等方面表现还不错。此外,这个新架构也使得Hunyuan-T1速度非常快,模型支持首字符1秒内响应,生成速度达60-80 token/秒,适用于实时交互场景。
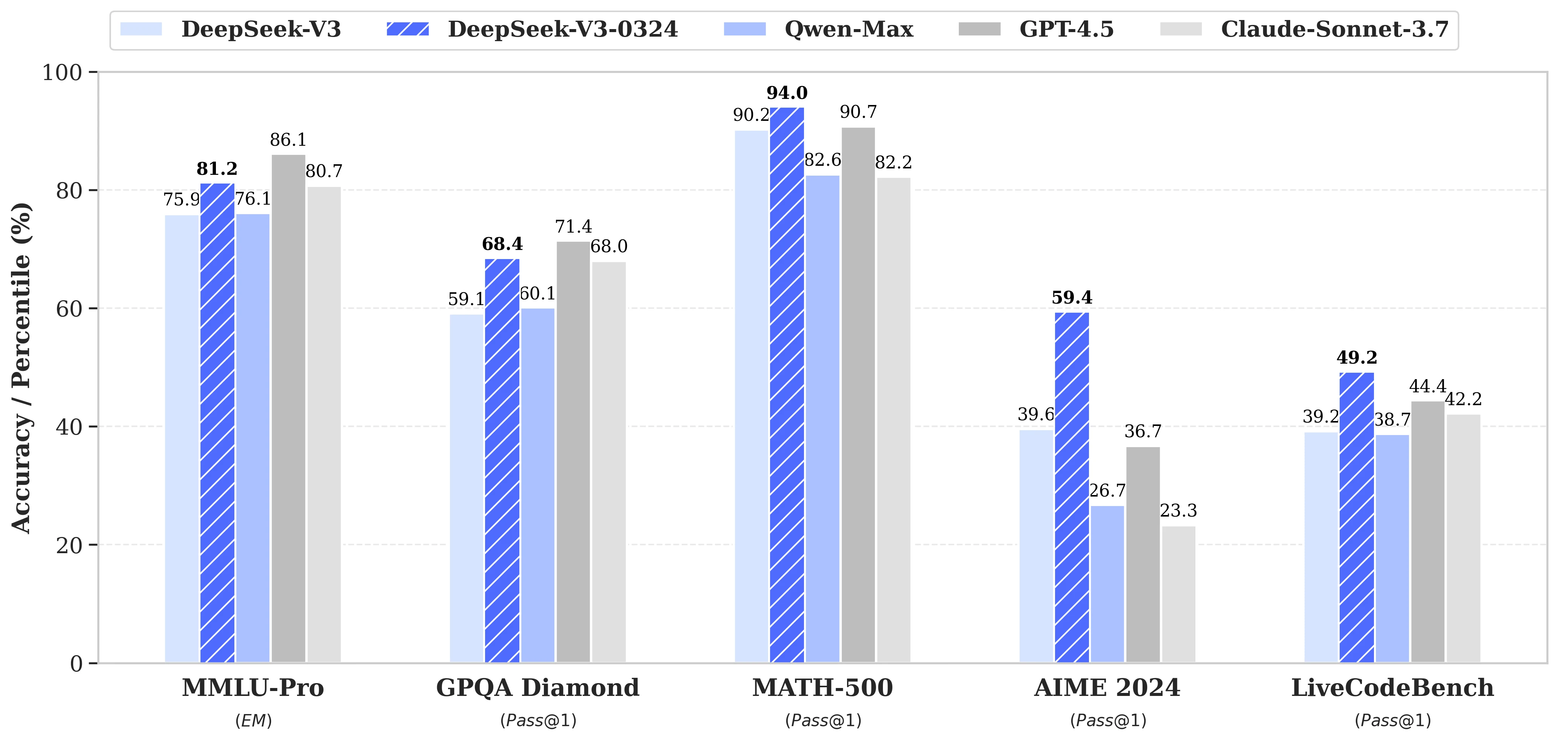
2025年3月25日,DeepSeekAI低调开源了DeepSeek-V3-0324大模型。作为DeepSeek-V3的重要升级版本,该模型在推理能力、中文写作、前端开发以及功能调用等多个关键领域实现了显著提升。在MMLU Pro等评测上,已经成为了非推理大模型中最强的模型,部分评测结果超过GPT-4.5模型。
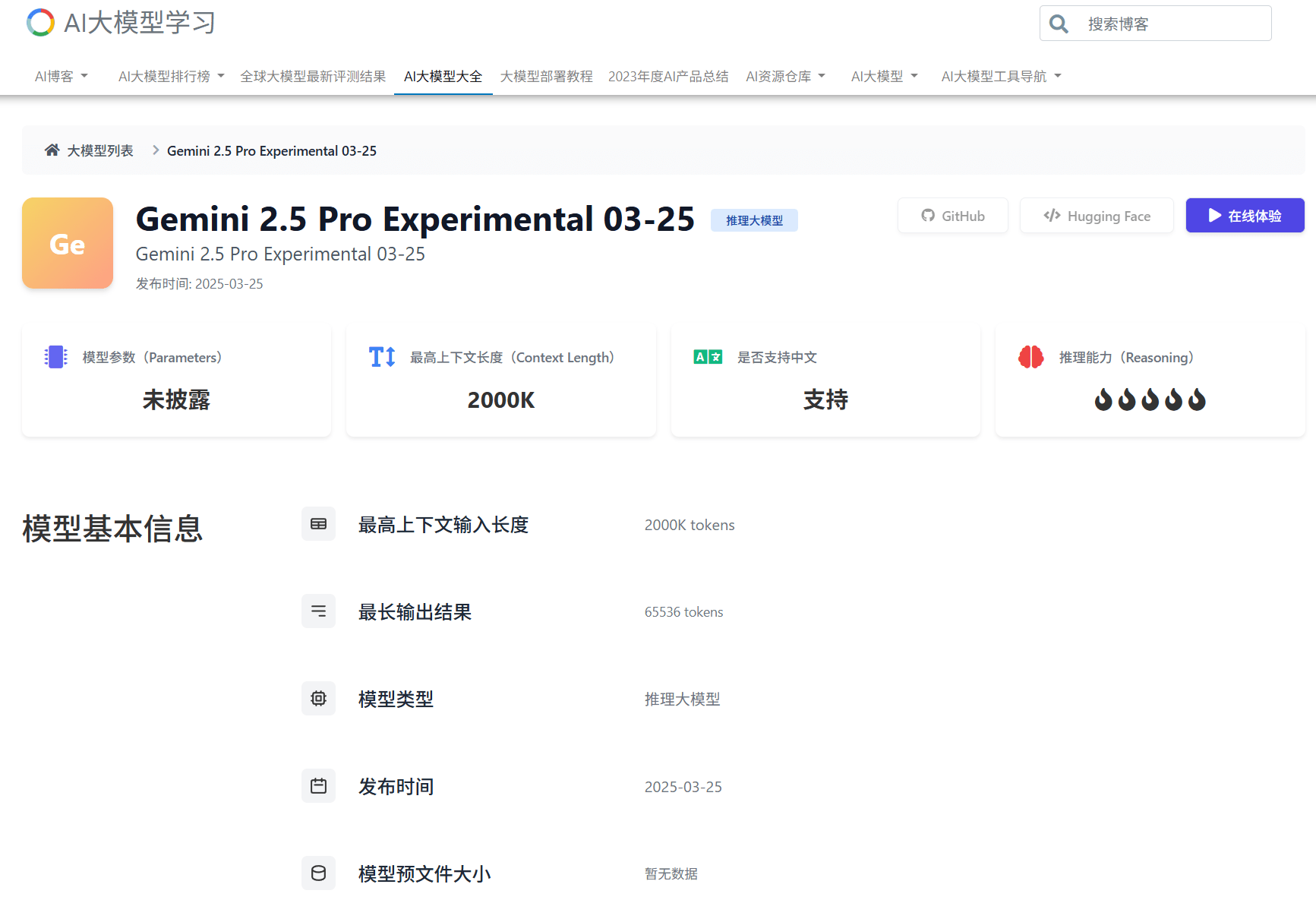
Gemini 2.5 Pro是Google发布的一个新一代大模型,Gemini 2.5 Pro是一个推理大模型,在数学和编程方面有了非常强大的能力,该模型最高支持200万tokens的上下文输入,非常强大!
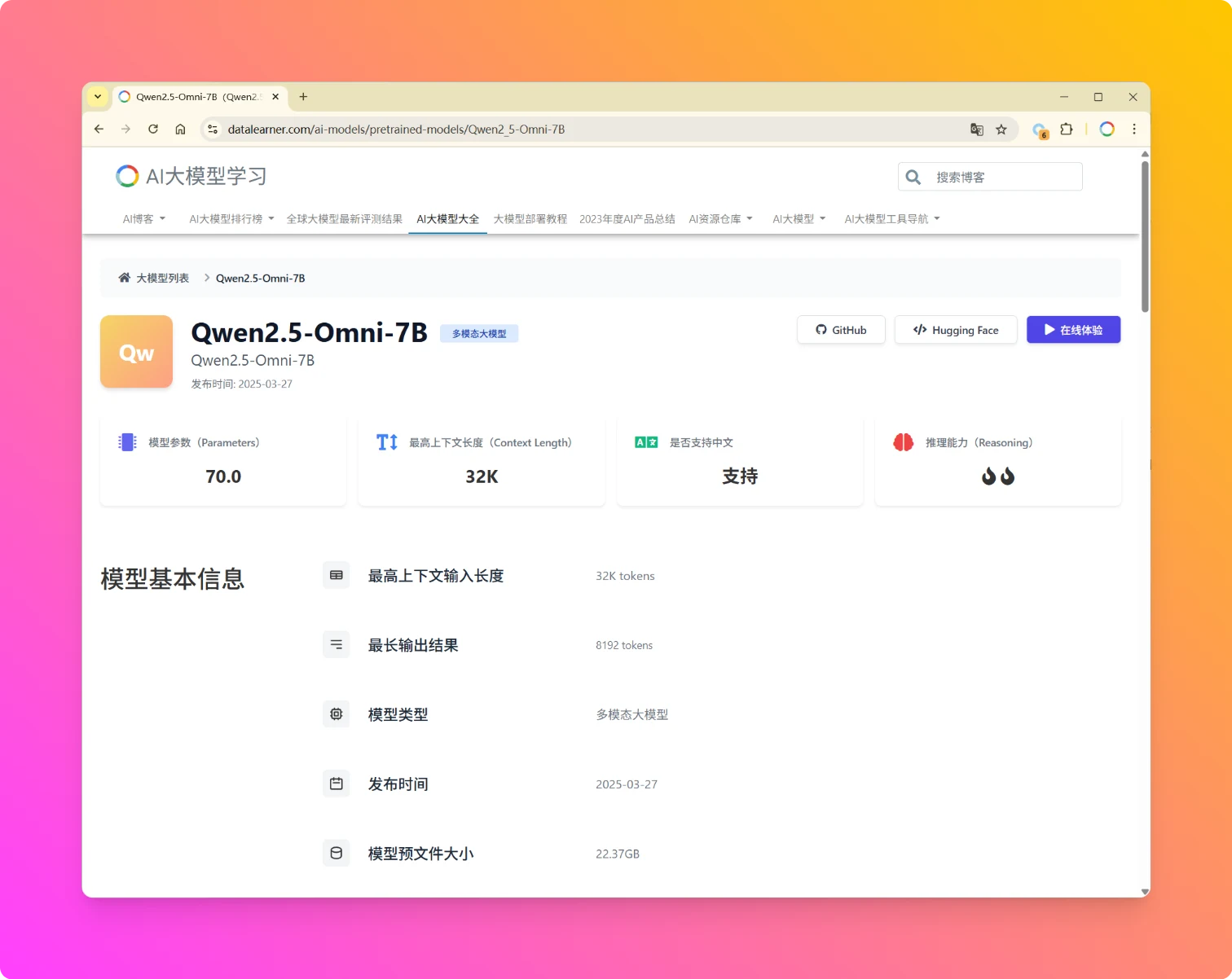
Qwen2.5-Omni-7B是阿里巴巴发布的一款端到端全模态大模型,支持文本、图像、音频、视频(无音频轨)的多模态输入与实时生成能力,可同步输出文本与自然语音的流式响应。目前,该模型在HuggingFace以Apache2.0协议开源,可以免费商用授权。
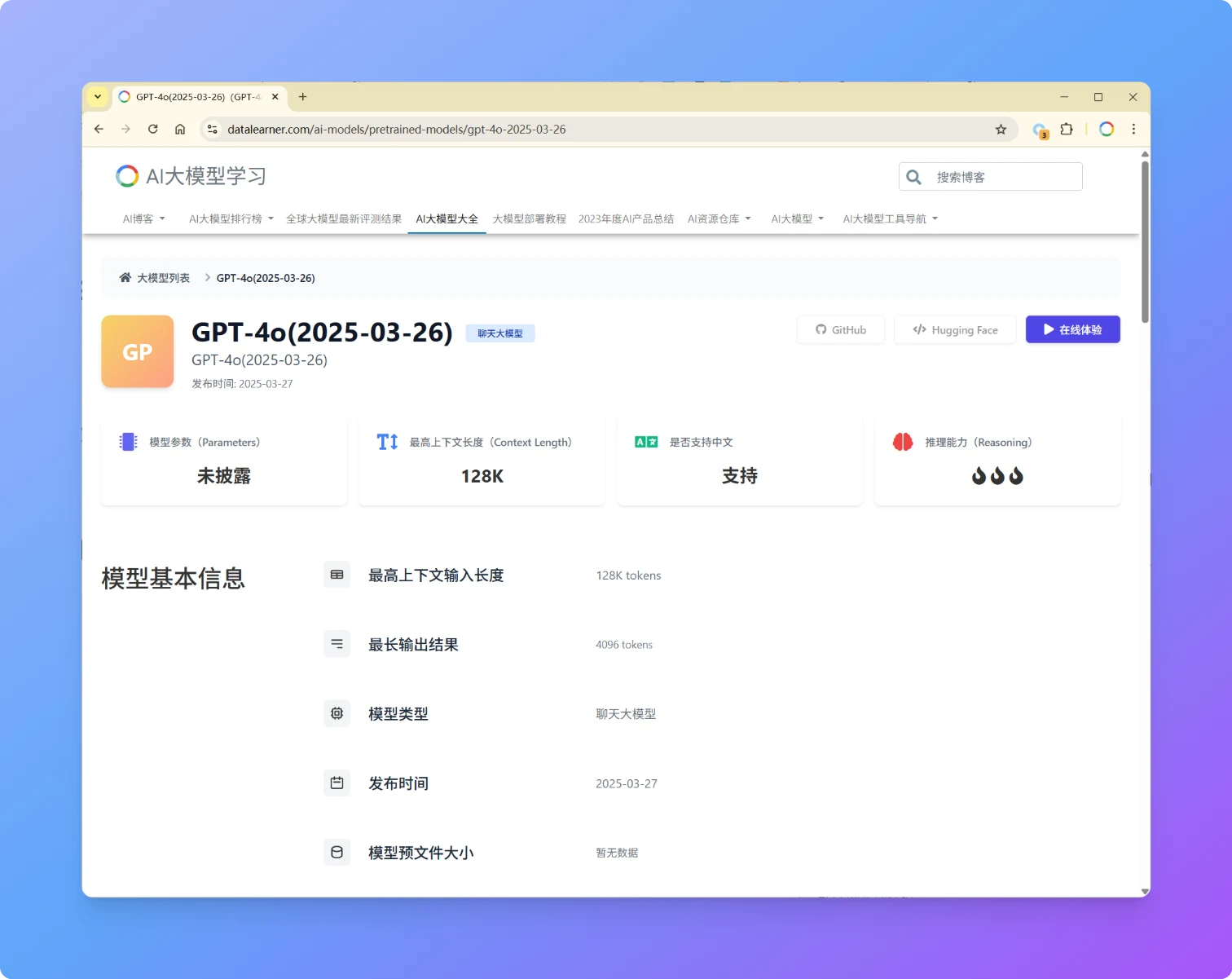
OpenAI再次发布GPT-4o更新版本,版本号为GPT-4o(2025-03-26),本次发布的GPT-4o模型在性能、易用性和协作能力上迎来多项优化,进一步提升了模型的直觉性、创造力和任务执行能力。此次更新聚焦于 STEM 与编程问题解决、指令遵循精度以及自然交互体验,各方面评测进步明显,超过了GPT-4.5。
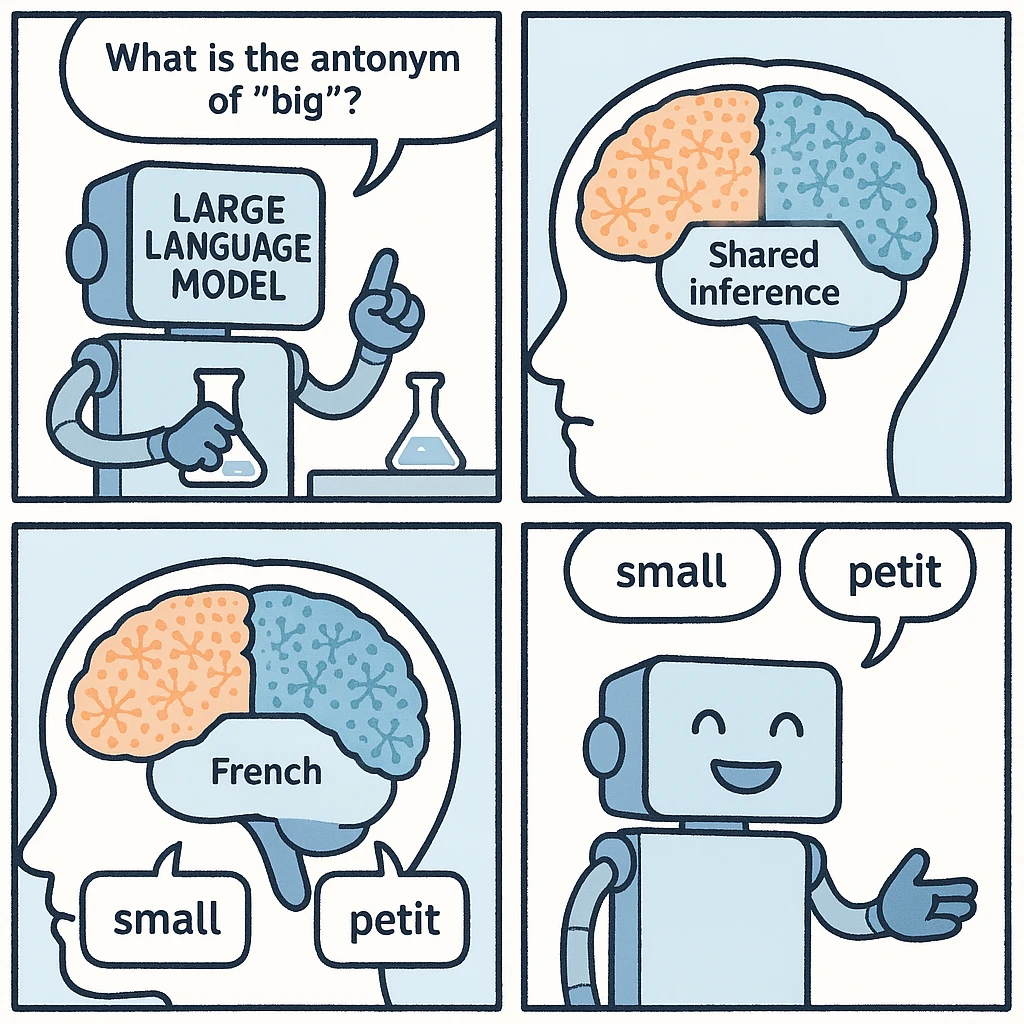
最近,Anthropic研究人员通过观察大模型内部运作机制发现了大模型内部可能存在一种与特定语言无关的内部共享区域,它可以把不同语种的输入,在同样的区域进行内部推理,并最终根据语种输出答案。这个现象让我们发现大模型本身理解语言的时候可能与人类类似,拥有高度抽象的内部表示,能够跨越多种语言统一相同的概念。
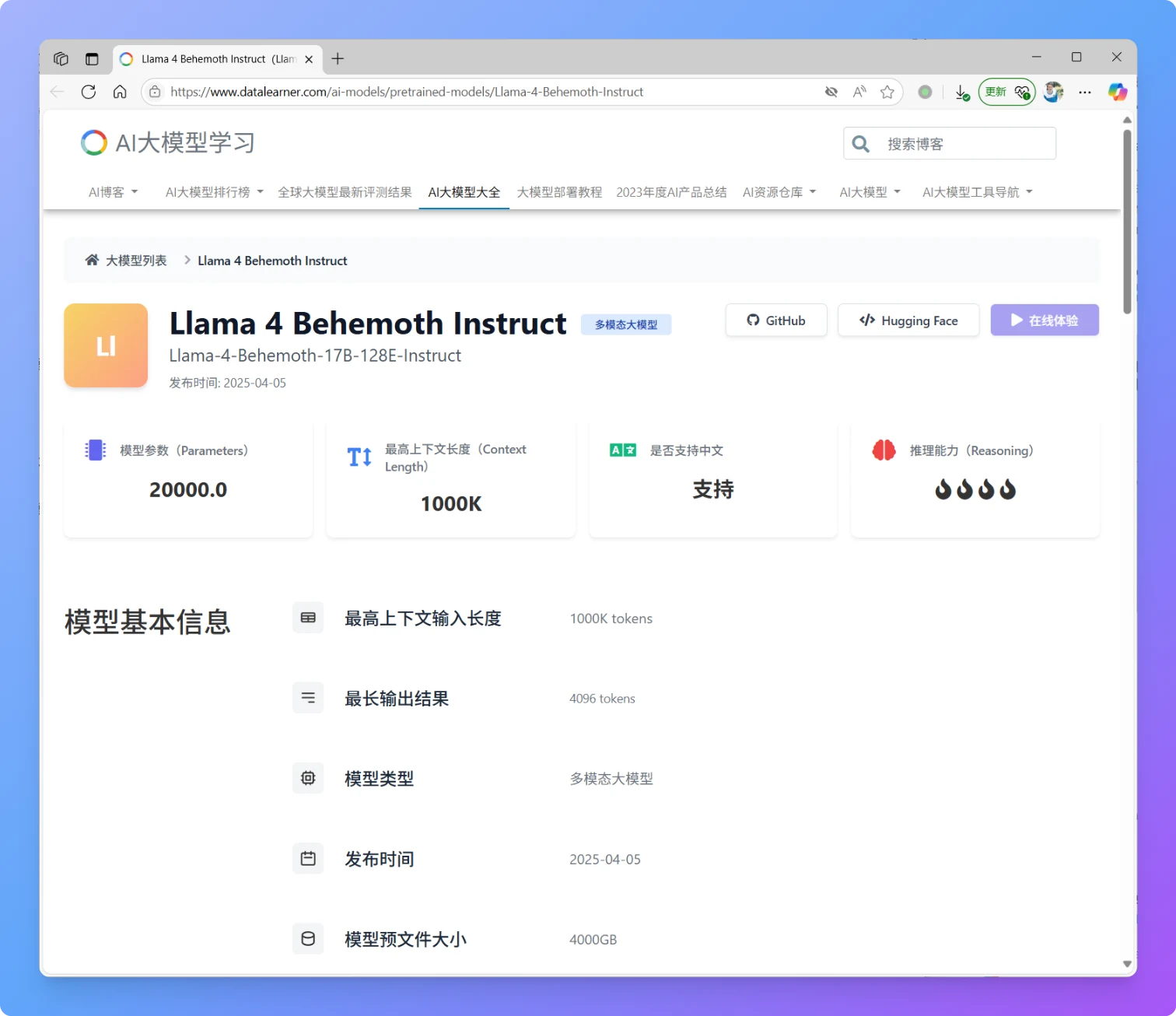
就在刚刚,MetaAI发布了全新一代Llama4大模型,Llama正式进入多模态和MoE架构时代。本次新发布的是Llama4中的2个模型分别是Llama4 Scout和Llama4 Maverick。这两个模型都是170亿激活参数,但是前者共16个专家,后者有128个专家,因此总的参数量分别达到了1090亿和4000亿!不过根据评测的情况看,即使是4000亿规模170亿激活的模型,也和DeepSeek V3.1(即DeepSeek V3 0324)版本差不多。
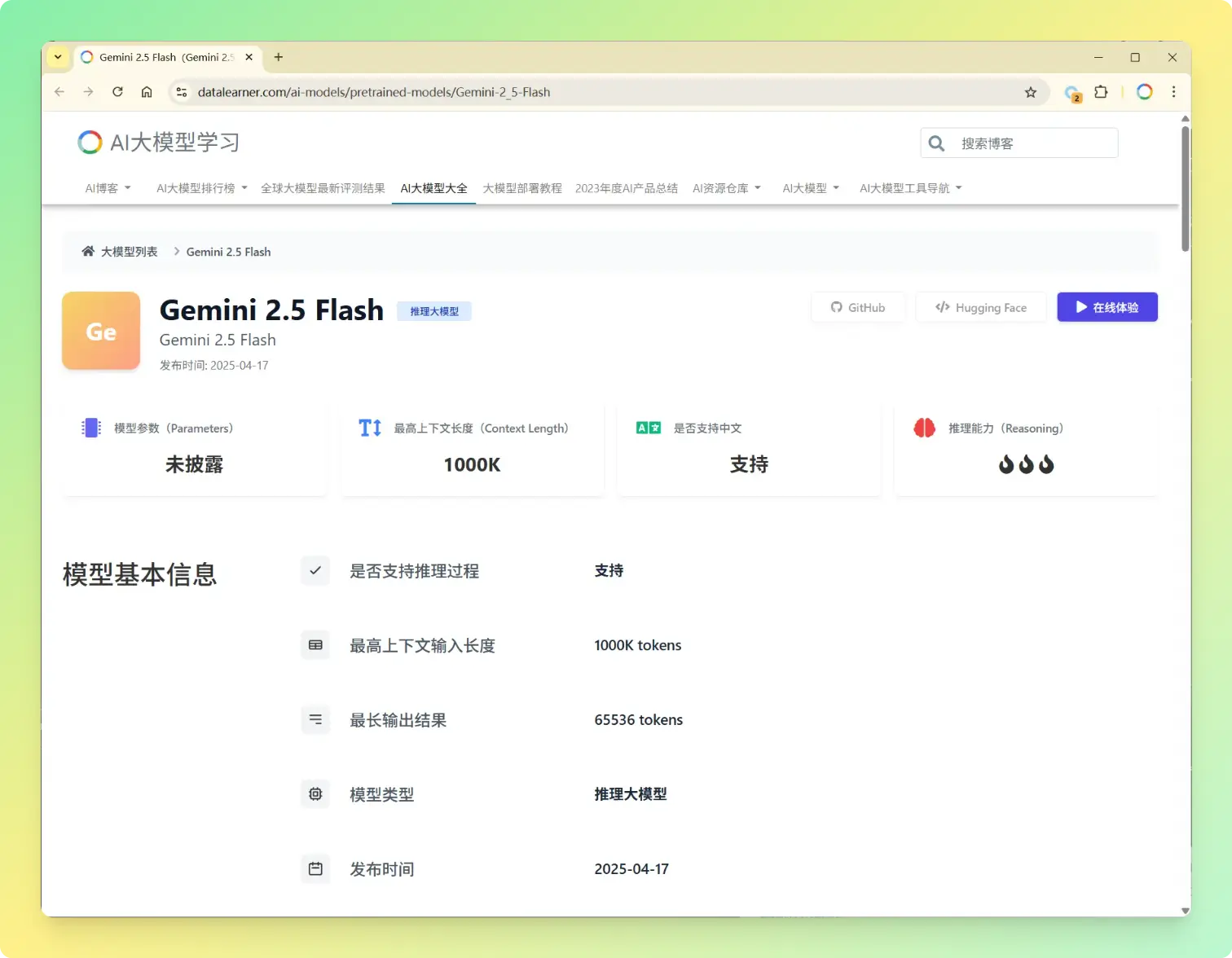
Gemini系列是Google的大模型品牌,2025年3月25日,Google发布了Gemini 2.5 Pro版本,这是谷歌发布的Gemini 2.5系列的第一个模型,参数规模较大,但是在多项评测结果上获得了全球最优的效果,Gemini 2.5 Pro成本比较高,时延也比较大,20天之后,谷歌又发布了Gemini 2.5 Flash模型,是性能、成本和效果的最佳均衡模型。
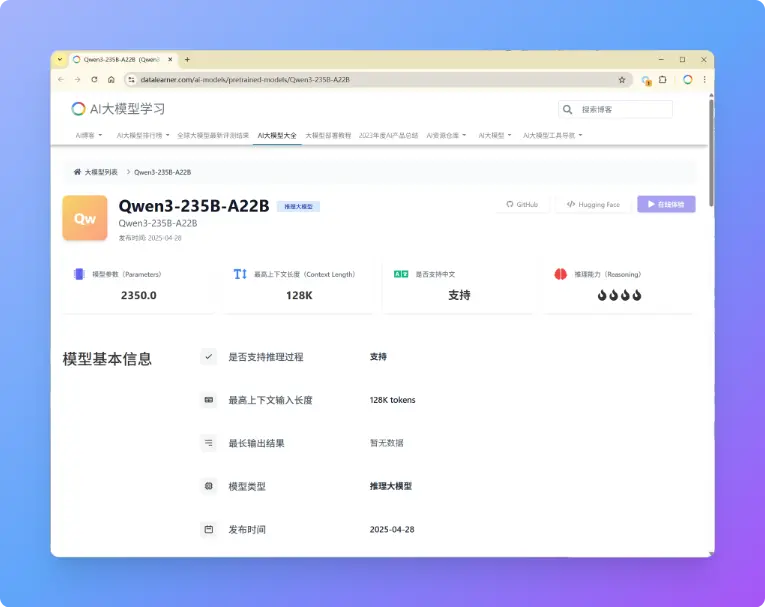
阿里巴巴刚刚开源了第三代千问大模型,Qwen3系列包含了8个不同参数规模的大模型,最大达到2350亿参数规模,最小仅6亿参数规模。本次发布的Qwen3系列是推理大模型和常规的大模型混合版本,即Qwen3可以根据输入问题的情况自动选择是否进行推理。
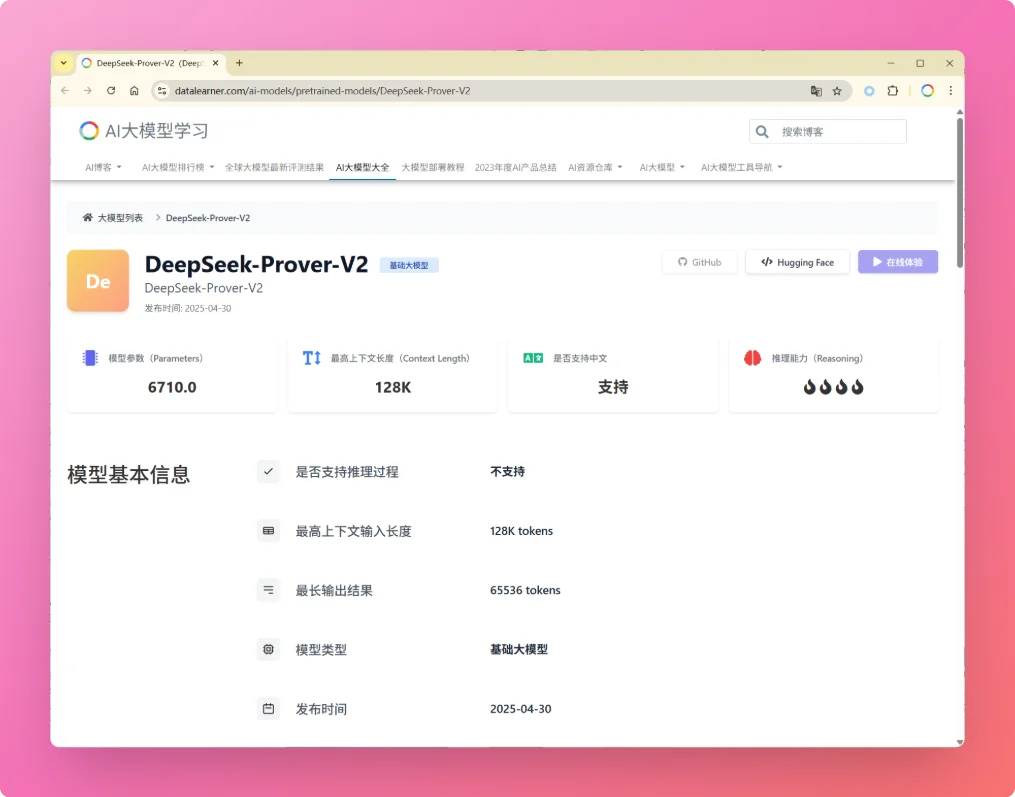
就在刚才,DeepSeek-AI发布了其新一代自动定理证明模型 **DeepSeek-Prover-V2**。尽管官方暂未公开详细报告,但从其前代模型 **DeepSeek-Prover-V1.5** 的技术细节,以及去年底发布的通用推理模型 DeepSeek-R1 的进展来看,V2 很可能在多个关键能力上取得了实质性提升。

微软发布了全新的Phi-4推理模型系列,是小型语言模型(SLM)在复杂推理能力上的一种新的尝试。本次发布包含三个不同规模和性能的推理模型,分别是Phi-4-reasoning(140亿参数)、Phi-4-reasoning-plus(增强版140亿参数)和Phi-4-Mini-Reasoning(38亿参数)。这三款模型尽管参数规模远小于当前主流大型语言模型,却在多项推理基准测试中展现出与甚至超越大型模型的能力。
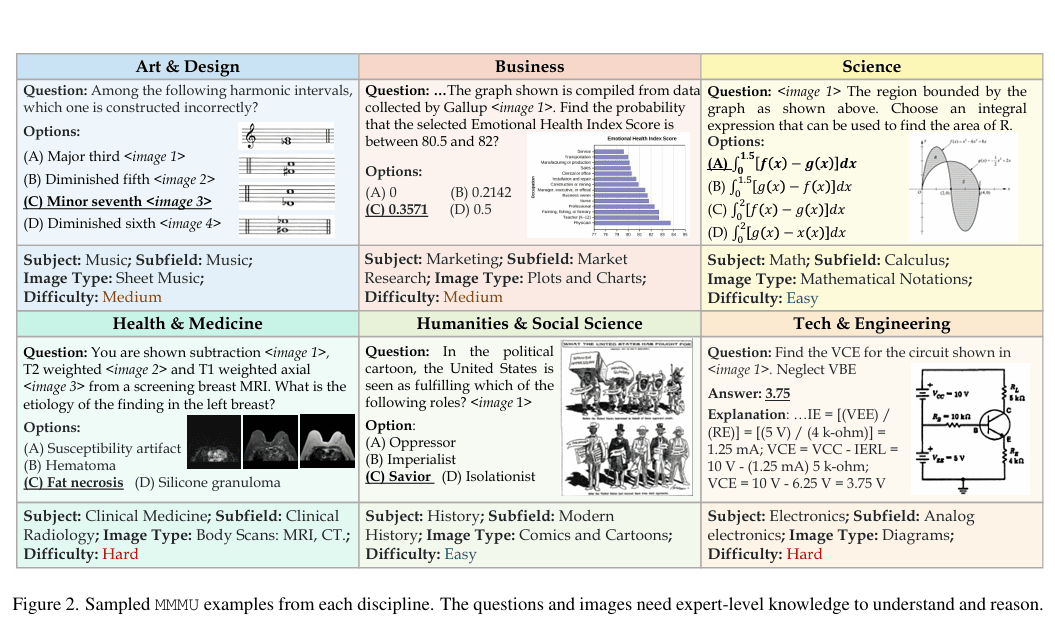
大规模多学科多模态理解与推理基准(MMMU)于2023年11月推出,是一种用于评估多模态模型的复杂工具。该基准测试人工智能系统在需要大学水平学科知识和深思熟虑推理的任务上的能力。与之前的基准不同,MMMU强调跨多个领域的先进感知和推理,旨在衡量朝专家级人工智能通用智能(AGI)的进展。
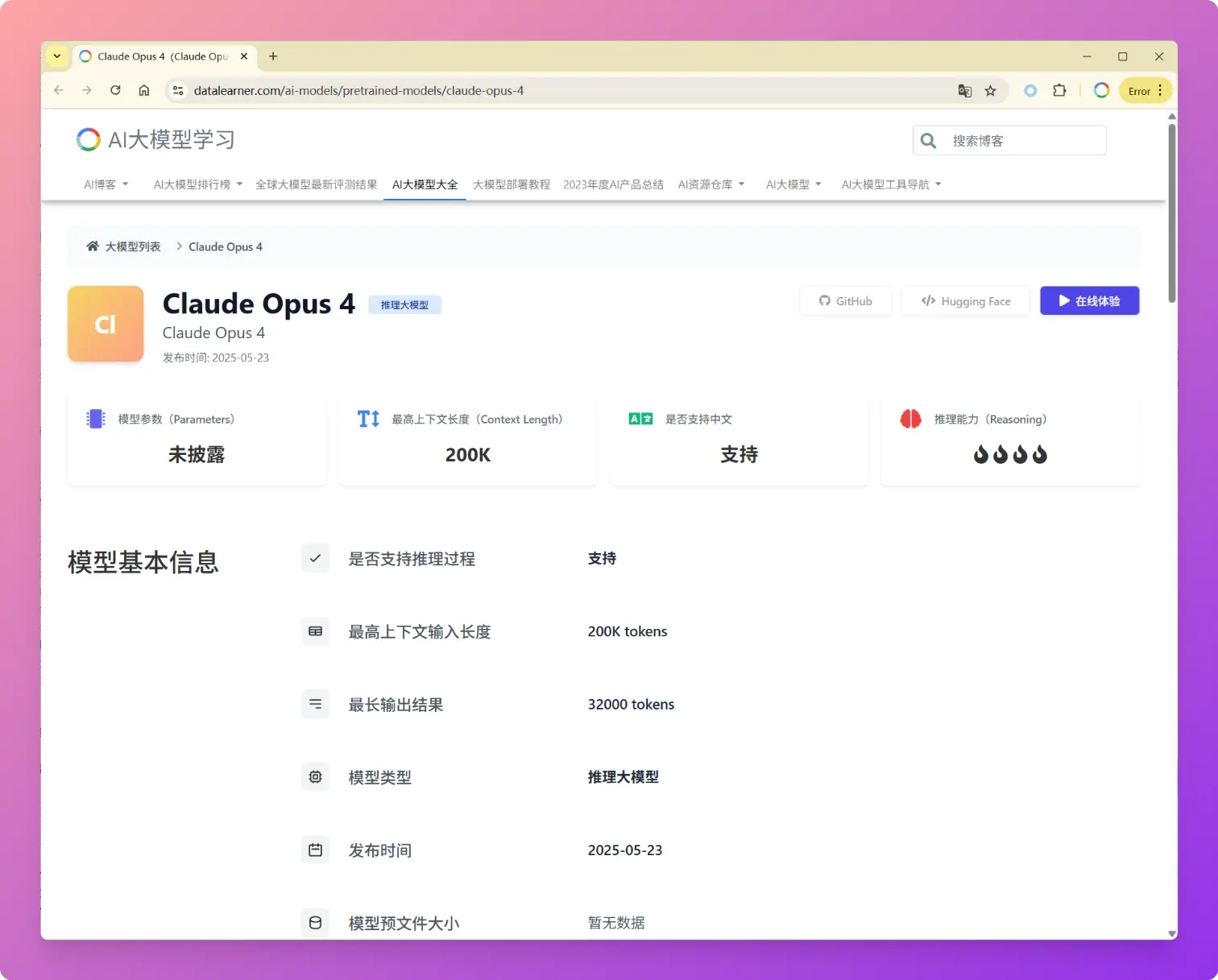
2025年5月23日,Anthropic发布了新一代大语言模型Claude 4系列,包括Claude Opus 4和Claude Sonnet 4两个版本。Anthropic的官方博客强调Claude Opus 4是当前全球最强的编程大模型,与传统聚焦于文本生成和知识问答的模型不同,Claude 4明确定位为任务执行引擎和AI Agent系统的核心组件。这次发布不仅仅是性能参数的提升,更代表了Anthropic认为AI模型从"对话助手"向"自主工作伙伴"的根本性转变。