
深度学习的反向传播手动推导
反向传播算法是深度学习求解最重要的方法。这里我们手动推导一下。
聚焦人工智能、大模型与深度学习的精选内容,涵盖技术解析、行业洞察和实践经验,帮助你快速掌握值得关注的AI资讯。
反向传播算法是深度学习求解最重要的方法。这里我们手动推导一下。
深度学习是目前最火的算法领域。他在诸多任务中取得的骄人成绩使得其进化越来越好。本文收集深度学习中的经典算法,以及相关的解释和代码实现。
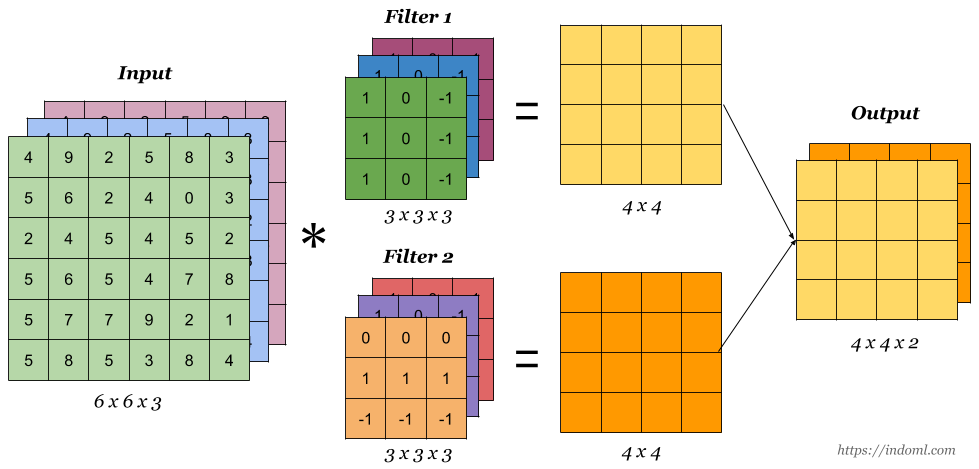
卷积操作的维度计算是定义神经网络结构的重要问题,在使用如PyTorch、Tensorflow等深度学习框架搭建神经网络的时候,对每一层输入的维度和输出的维度都必须计算准确,否则容易出错,这里将详细说明相关的维度计算。
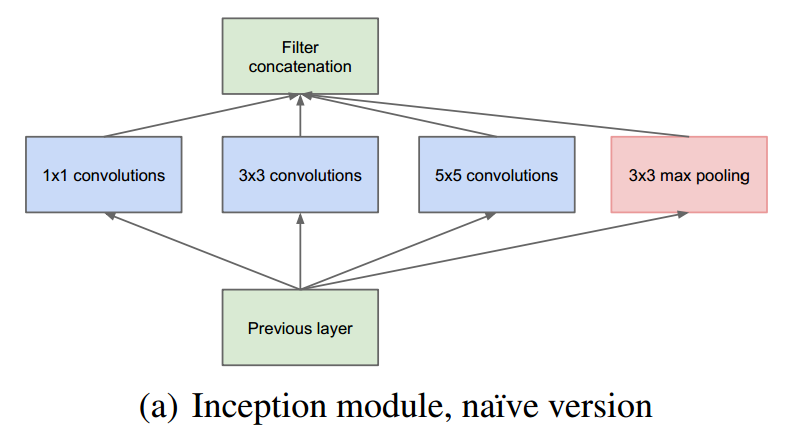
GoogLeNet是谷歌在2014年提出的一种CNN深度学习方法,它赢得了2014年ILSVRC的冠军,其错误率要低于当时的VGGNet。与之前的深度学习网络思路不同,之前的CNN网络的主要目标还是加深网络的深度,而GoogLeNet则提出了一种新的结构,称之为inception。GoogLeNet利用inception结构组成了一个22层的巨大的网络,但是其参数却比之前的如AlexNet网络低很多。是一种非常优秀的CNN结构。
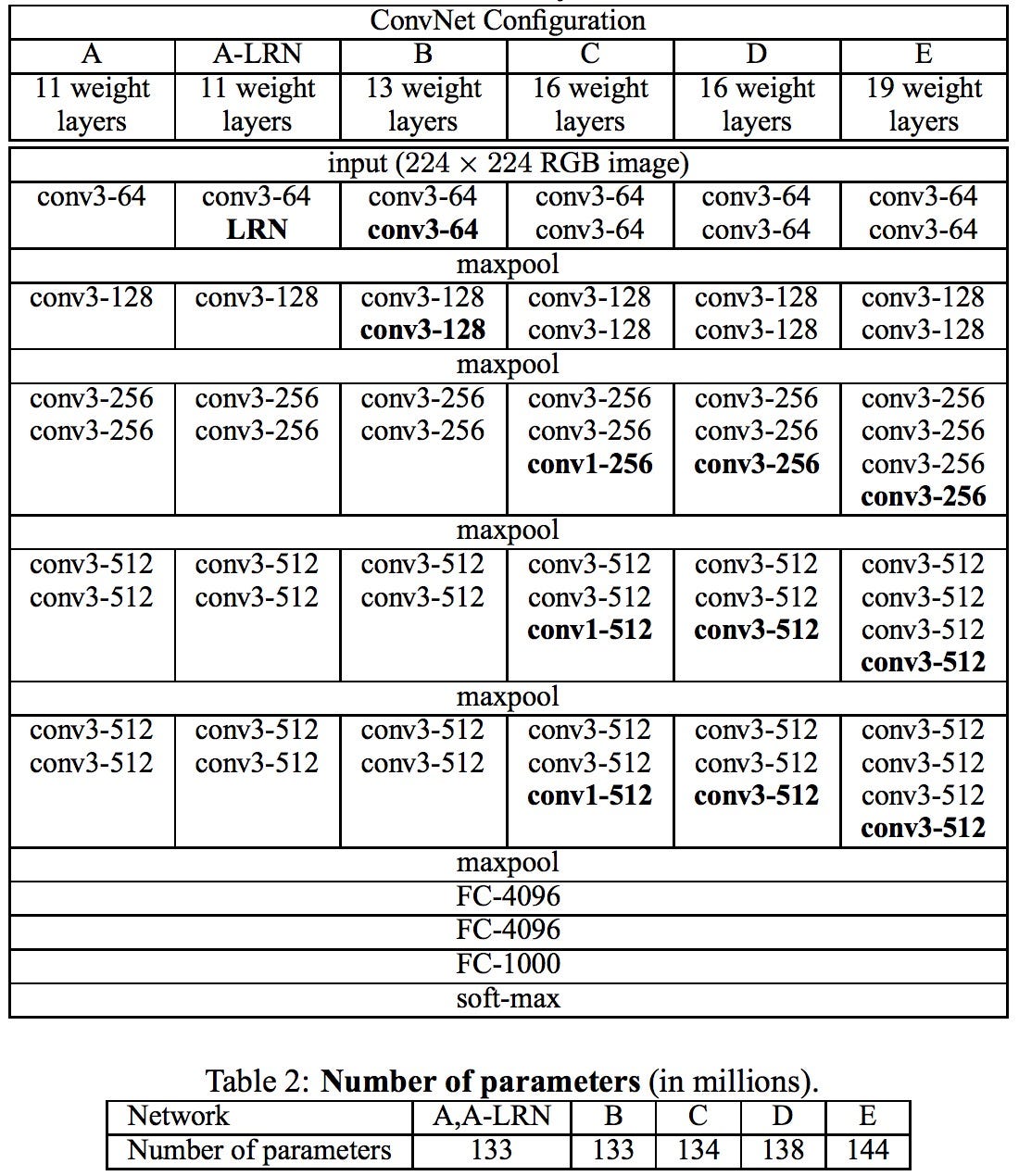
VGGNet(Visual Geometry Group)是2014年又一个经典的卷积神经网络。VGGNet最主要的目标是试图回答“如何设计网络结构”的问题。随着AlexNet提出,很多人开始利用卷积神经网络来解决图像识别的问题。一般的做法都是重复几层卷积网络,每个卷积网络之后接一些池化层,最后再加上几个全连接层。而VGGNet的提出,给这些结构设计带来了一些标准参考。
1998年,LeCun提出了LeNet-5网络用来解决手写识别的问题。LeNet-5被誉为是卷积神经网络的“Hello Word”,足以见到这篇论文的重要性。在此之前,LeCun最早在1989年提出了LeNet-1,并在接下来的几年中继续探索,陆续提出了LeNet-4、Boosted LeNet-4等。本篇博客将详解LeCun的这篇论文,并不是完全翻译,而是总结每一部分的精华内容。
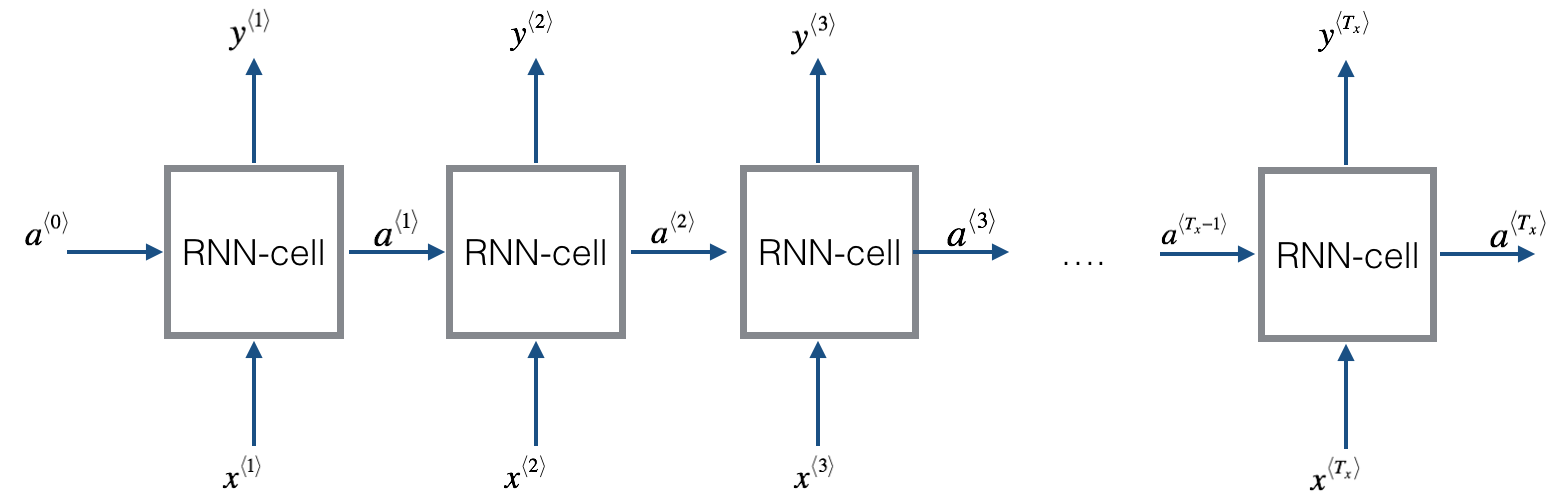
之前面的博客中,我们已经描述了基本的RNN模型。但是基本的RNN模型有一些缺点难以克服。其中梯度消失问题(Vanishing Gradients)最难以解决。为了解决这个问题,GRU(Gated Recurrent Unit)神经网络应运而生。本篇博客将描述GRU神经网络的工作原理。GRU主要思想来自下面两篇论文:
在前面的博客中,我们已经介绍了基本的RNN模型和GRU深度学习网络,在这篇博客中,我们将介绍LSTM模型,LSTM全称是Long Short-Time Memory,也是RNN模型的一种。

使用预训练模型处理NLP任务是目前深度学习中一个非常火热的领域。本文总结了8个顶级的预训练模型,并提供了每个模型相关的资源(包括官方文档、Github代码和别人已经基于这些模型预训练好的模型等)。
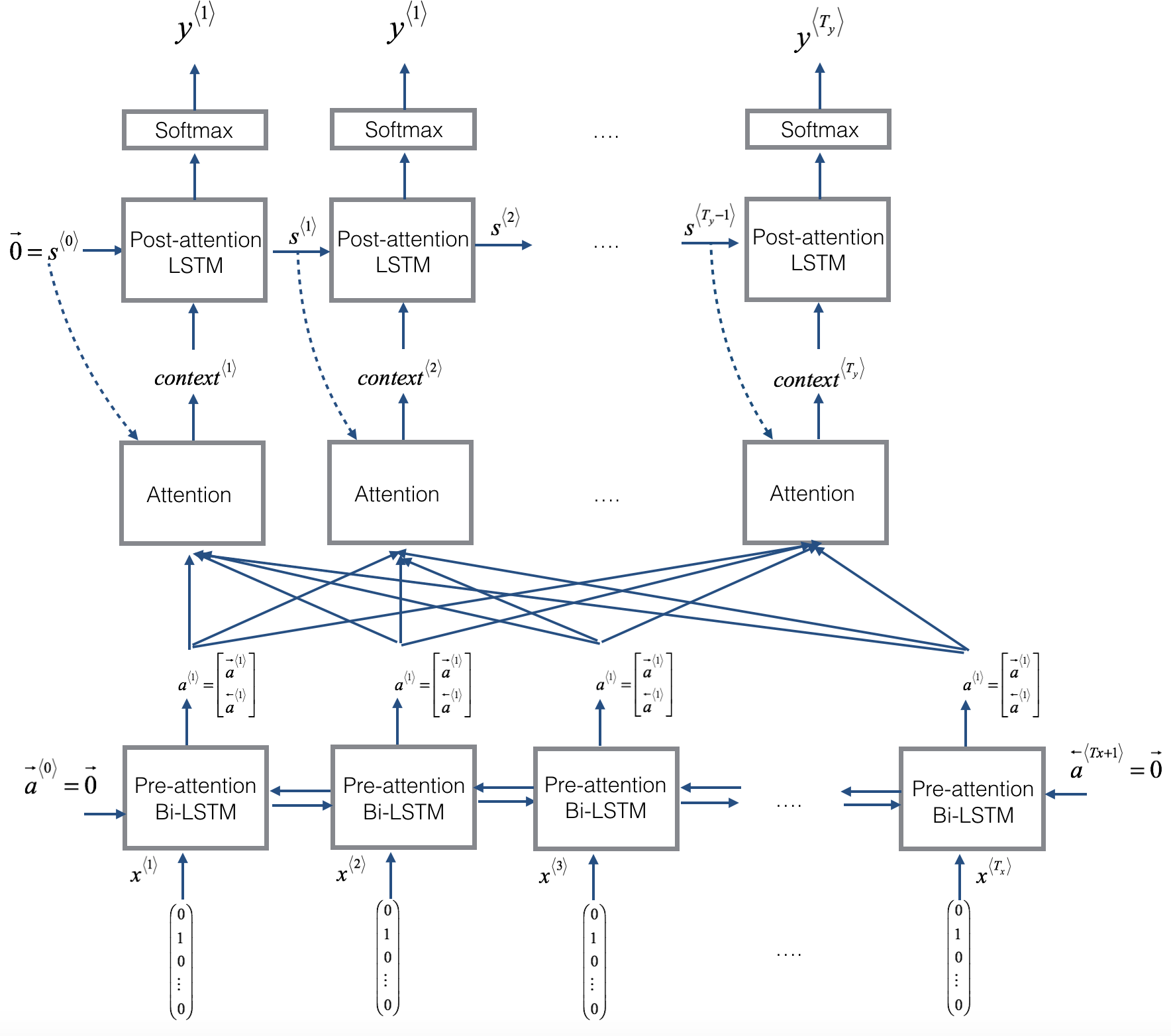
Encoder-Decoder的深度学习架构是目前非常流行的神经网络架构,在许多的任务上都取得了很好的成绩。在之前的博客中,我们也详细介绍了该架构(参见深度学习之Encoder-Decoder架构)。本篇博客将详细讲述Attention机制。

深度学习中Sequence to Sequence (Seq2Seq) 模型的目标是将一个序列转换成另一个序列。包括机器翻译(machine translate)、会话识别(speech recognition)和时间序列预测(time series forcasting)等任务都可以理解成是Seq2Seq任务。RNN(Recurrent Neural Networks)是深度学习中最基本的序列模型。
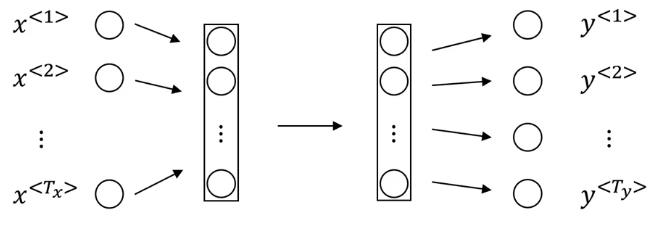
序列数据是生活中很常见的一种数据,如一句话、一段时间某个广告位的流量、一连串运动视频的截图等。在这些数据中也有着很多数据挖掘的需求。RNN就是解决这类问题的一种深度学习方法。其全称是Recurrent Neural Networks,中文是递归神经网络。主要解决序列数据的数据挖掘问题。
您刚刚经历了一个耗时的过程,将一堆数据加载到python对象中。 也许你从数千个网站上爬取了数据。也许你计算了pi的数值。如果您的笔记本电脑电池耗尽或python崩溃,您的信息将丢失。 Pickling允许您将python对象保存为硬盘驱动器上的二进制文件。 在你pickle你的对象后,你可以结束你的python会话,重新启动你的计算机,然后再次将你的对象加载到python中。
广告分配问题属于运筹中的优化问题。一般情况下,我们期望有个最大化收益,但同时需要保证合约的完成。因此,这是一个带不等式约束的最优化问题。由于广告数量和用户数量很多,因此,求解的难度很高。在这篇文章中,作者推导了原问题的拉格朗日函数的系数之间的关系,大大降低了求解的难度。这里将简要介绍原理和推导过程。
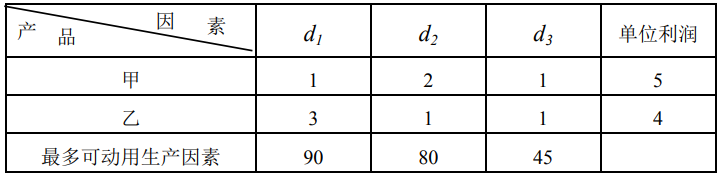
对偶问题(Dual Problem)是运筹学中一个很重要的概念,是基于原问题的约束条件和目标函数为基础构造而来。每一个线性规划的问题都存在一个与之对应的对偶问题。对偶问题在求解最优化问题时很有用。
KKT条件(Karush–Kuhn–Tucker conditions)是求解带不等式约束的最优化问题中非常重要的一个概念和方法。这篇博客将解释相关概念和操作。
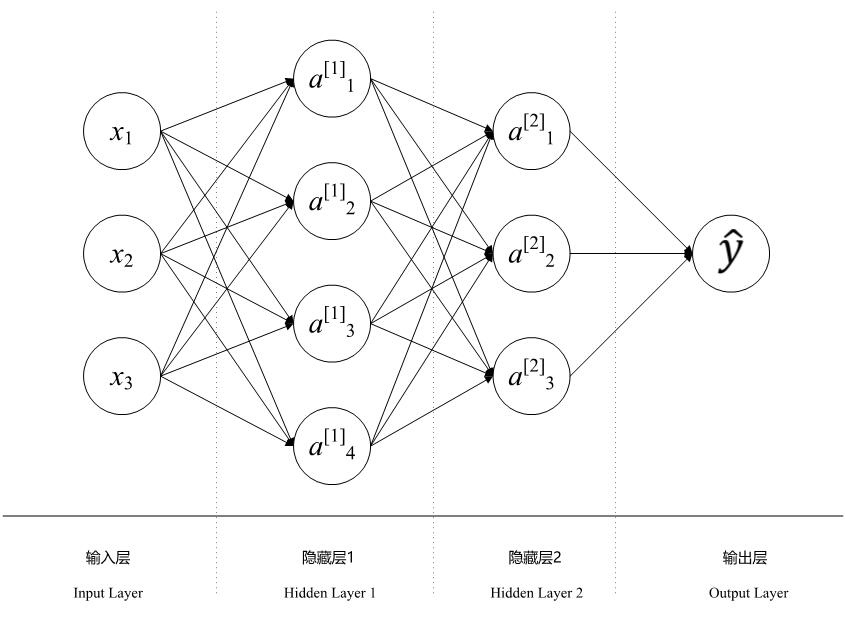
深度学习中的符号很多,但是大多数情况下,大家都使用同一套符号来表示。这篇博客主要以一个简单的神经网络为例,说明深度学习的标准符号以及相关的维度表示。主要来源是吴恩达的coursera课程。

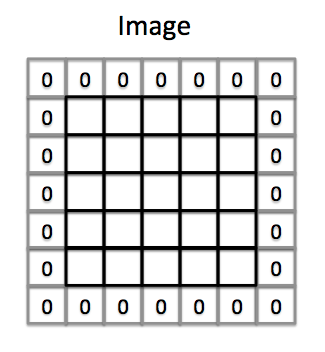
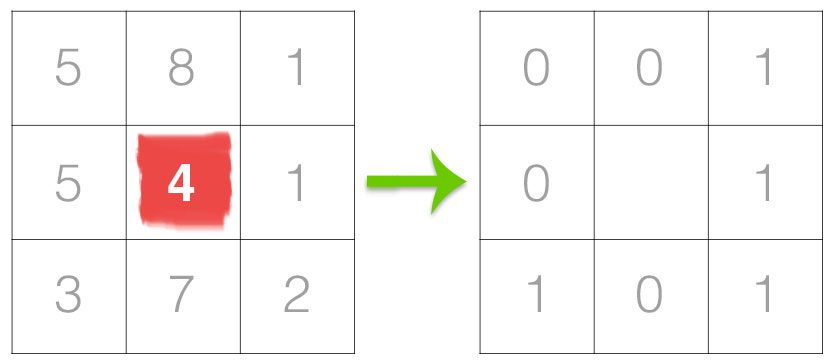
卷积神经网络是深度学习中处理图像的利器。在卷积神经网络中,Padding是一种非常常见的操作。本片博客将简要介绍Padding的原理。
机器学习是实现人工智能最重要的方法之一,包括深度学习等都属于机器学习中的一种方法。因此,机器学习的应用被认为是实现人工智能应用的重要途径。人工智能的应用目标是使用计算机(机器)来代替或者辅助人工来完成某项任务。机器学习在解决业务问题的应用需要谨慎考虑。本文提供一些步骤可以参考。
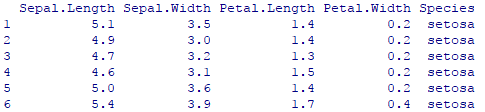
R语言进行数据分析非常简单方便,在这篇博客中,我们将描述如何使用R语言进行K-means聚类分析,并分析结果。