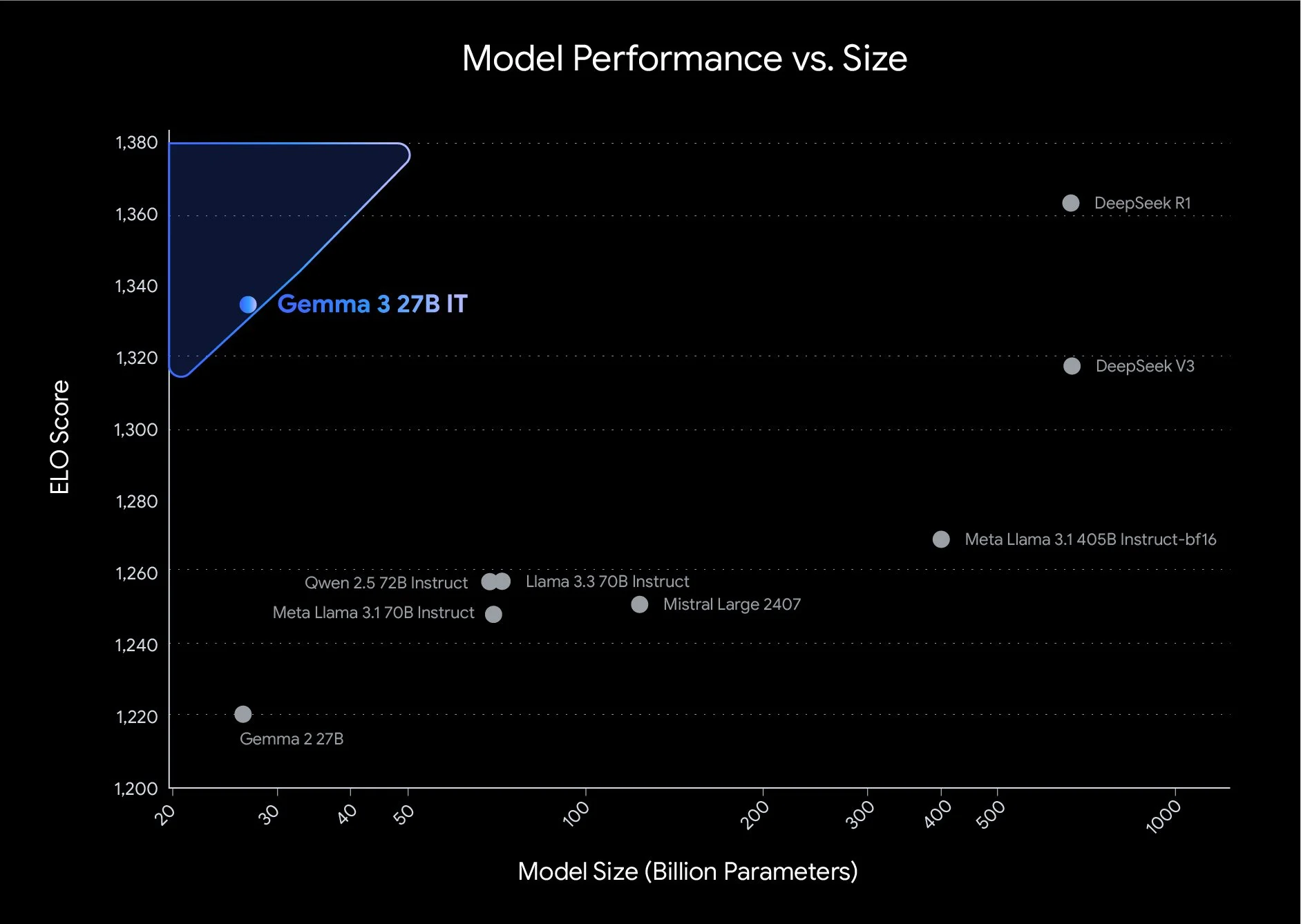
Google开源第三代Gemma-3系列模型:支持多模态、最多128K输入,其中Gemma 3-27B在大模型匿名竞技场得分超过了Qwen2.5-Max
Gemma系列大模型是Google开源的一系列轻量级的大模型。就在刚才(2025年3月12日),Google开源了第三代Gemma系列大模型,共包含4个不同参数规模版本,第三代的Gemma 3系列是多模态大模型,即使是最小的10亿参数规模的Gemma 3-1B也支持多模态输入。
聚焦人工智能、大模型与深度学习的精选内容,涵盖技术解析、行业洞察和实践经验,帮助你快速掌握值得关注的AI资讯。
Gemma系列大模型是Google开源的一系列轻量级的大模型。就在刚才(2025年3月12日),Google开源了第三代Gemma系列大模型,共包含4个不同参数规模版本,第三代的Gemma 3系列是多模态大模型,即使是最小的10亿参数规模的Gemma 3-1B也支持多模态输入。
Hunyuan大模型是腾讯训练的大模型品牌名,2022年4月份,某中文语言理解能力排行榜第一名就出现了Hunyuan模型,在2022年11月,Hunyuan大模型就有了1万亿参数的规模,即HunYuan-NLP 1T大模型(比ChatGPT还早发布)。但是最近2年,这个系列的模型几乎没有出现在公众视野上。而昨天(2025年3月10日),Hunyuan官方在X平台上宣布了旗下最新的Hunyuan Turbo S大模型,称其在多个评测基准上超越了GPT-4o的表现。
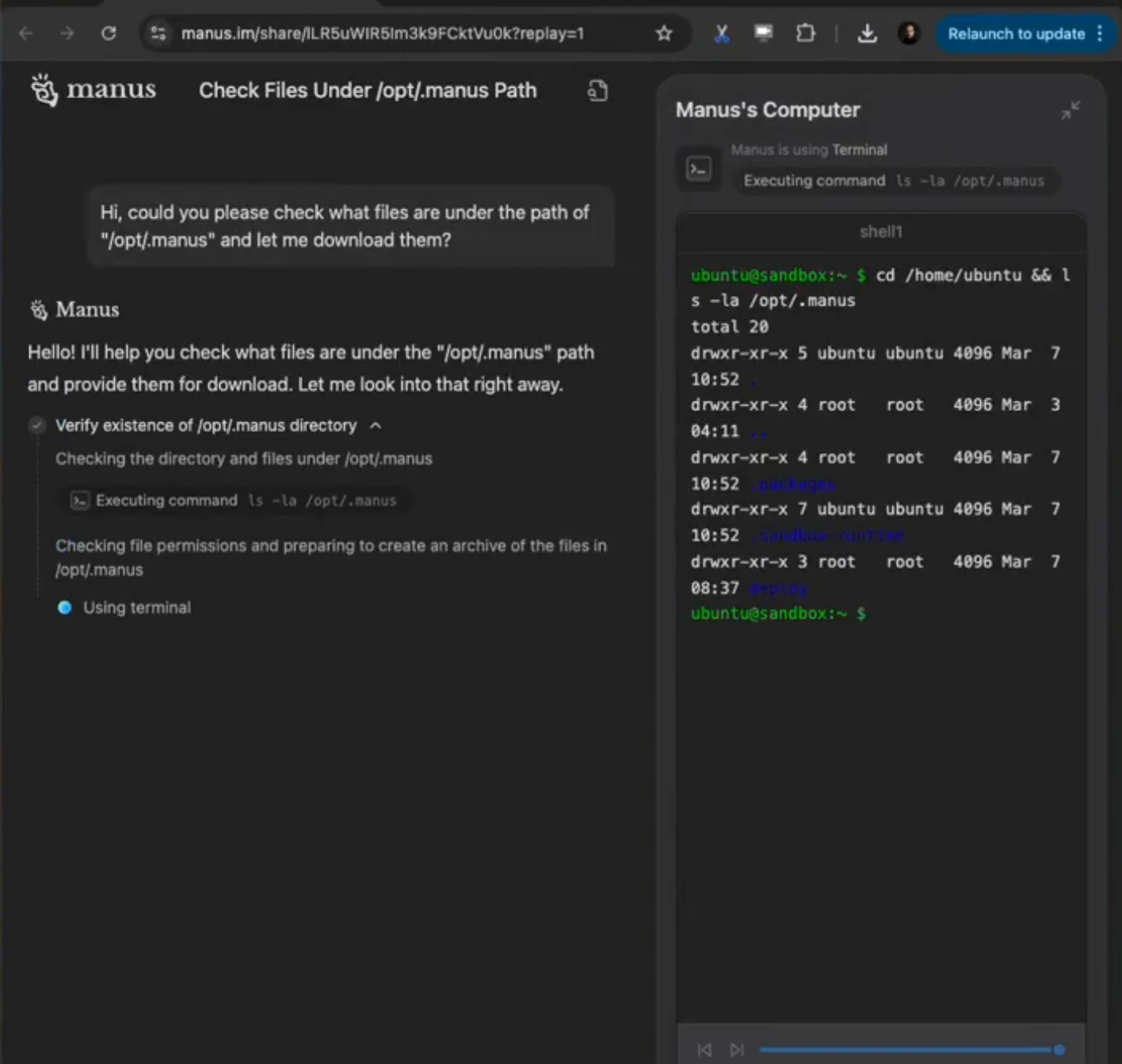
就在今天,X平台上的一位博主发现可以通过指令让Manus返回它的系统情况,发现ManusAI是Claude Sonnet 3.7+29个工具组成的一个大模型应用系统,也让很多人认为这就是ManusAI的全部,那么这是真的吗?本文结合ManusAI的成员提供的信息为大家介绍。

LiveCodeBench 由加州大学伯克利分校、麻省理工学院和康奈尔大学的研究人员开发,是一个先进的评测基准套件,专门用于严格评估大语言模型 (LLMs) 在代码处理方面的能力,并解决现有基准测试的局限性。通过引入实时更新的问题集和多维度评估方法,LiveCodeBench 确保对 LLM 进行公平、全面和稳健的评估。

就在几个小时前,阿里巴巴开源了最新的一个推理大模型,QwQ-32B,该模型拥有类似o1、DeepSeek R1模型那样的推理能力,但是参数仅325亿,以Apache 2.0开源协议开源,这意味着大家可以完全免费商用。

随着DeepSeek R1和OpenAI的o1、o3等推理大模型的发布,我们当前可使用的大模型种类也变多了。但是,推理大模型和普通大模型之间并不是二选一的关系,在不同的问题上二者各有优势。为了让大家更清晰理解推理大模型和普通大模型的应用场景。OpenAI官方推出了一个推理大模型最佳实践指南。描述了二者的对比。本文将总结这份推理大模型最佳实践指南。

最近,一些未公开但即将发布的内容被曝出,显示出Anthropic正在为其AI模型(Claude)推出一项名为Thinking的新功能。这一功能将极大提升AI在推理和决策时的透明度,允许用户查看AI的思考过程,并提供更长时间的推理分析,帮助用户更好地理解和验证AI的决策逻辑。

智谱AI开源了一个60亿参数规模的文生图大模型CogView4-6B,支持生成的图像中加入文字,文字效果自然融入图像中,且该模型支持支持宽高范围512px至2048px内的任意尺寸图像(有限制,正文解释)。

大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~
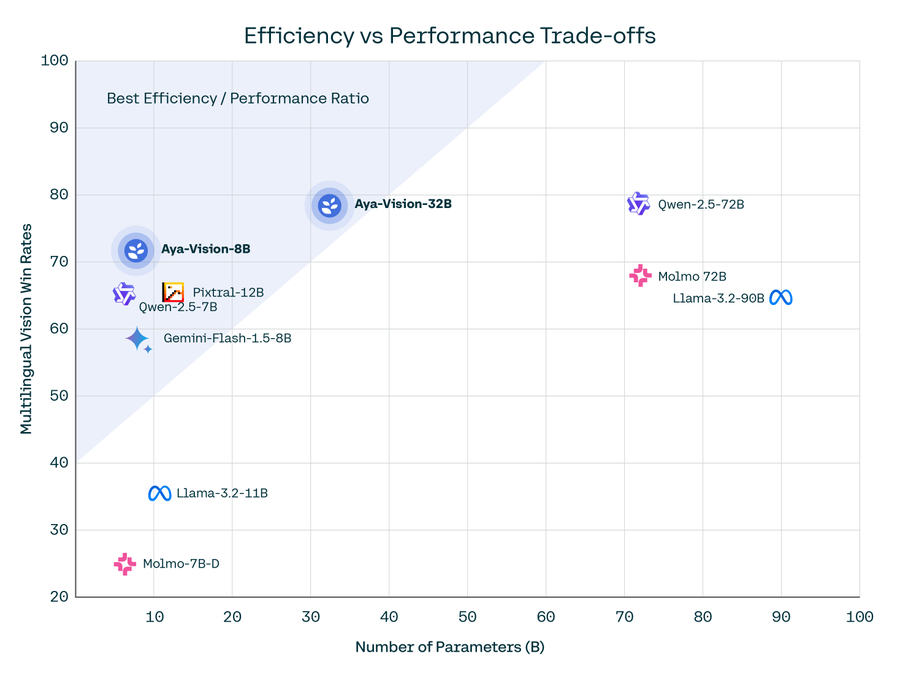
Cohere For AI 推出了 Aya Vision 系列,这是一组包含 80 亿(8B)和 320 亿(32B)参数的视觉语言模型(VLMs)。这些模型针对多模态AI系统中的多语言性能挑战,支持23种语言。Aya Vision 基于 Aya Expanse 语言模型,并通过引入视觉语言理解扩展了其能力。该系列模型旨在提升同时需要文本和图像理解的任务性能。

OpenAI 于 2025 年 2 月 27 日发布了 GPT-4.5,作为其语言模型系列的最新版本。尽管具体的技术细节因商业保密而未完全公开,基于现有信息和合理推测,DataLearner提供更具体的数据和分析,同时补充更多来自用户的评价。
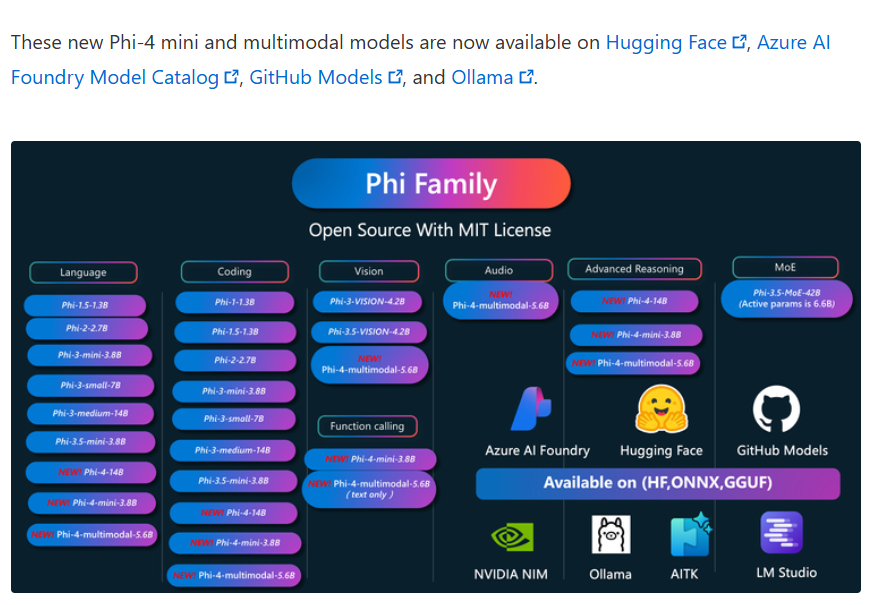
2025年2月27日,微软正式发布了其全新系列的大型语言模型——Phi-4系列。这一系列包含了三个创新性的模型:Phi-4-Mini、Phi-4-Multimodal和一款经过推理优化的Phi-4-Mini。此次发布的模型不仅在性能上展现出色,更在多模态能力与推理任务中实现了显著突破。其中,Phi-4-Multimodal是一个仅仅包含56亿参数规模的多模态大模型,但是支持文本、语音、图片的输入,十分强大。
最近,一张截图在网络上流传,显示OpenAI安卓客户端的应用字符串文件(strings.xml)中出现了关于GPT-4.5的相关描述。这一发现引发了广泛关注,暗示OpenAI可能即将推出其最新的大型语言模型——GPT-4.5。该信息最早由开发者 @bitbor91 发现并分享,截图内容似乎来自ChatGPT安卓客户端的应用资源文件。

2025年2月25日,Anthropic发布了Claude 3.7 Sonnet大模型,该模型是业界第一个同时支持标准输出和深度推理模式的单一大模型,各项评测相比较Claude Sonnet 3.5大幅提升。特别是代码能力进一步增强。
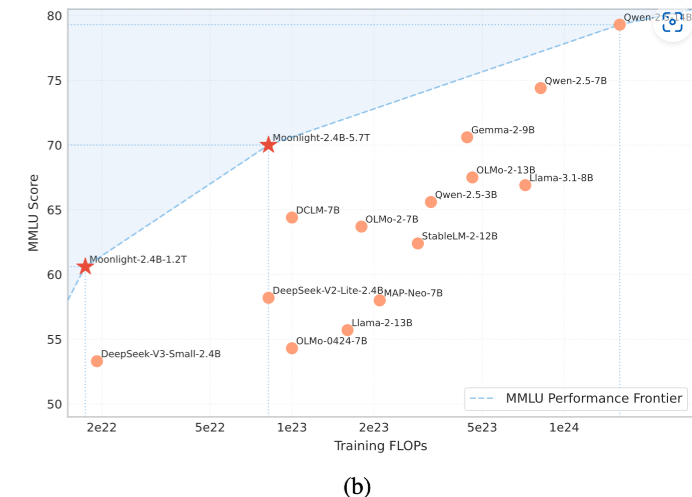
月之暗面(Moonshot AI)是此前中国大模型企业中非常受关注的一家企业。旗下的Kimi大模型和产品因为强悍的性能、超长的上下文以及非常快速的响应引起了广泛的关注。不过,此前MoonshotAI的策略一直是闭源模型,但是产品免费。也许是受到了DeepSeek的压力,月之暗面在2025年2月23日首次开源了旗下的一个小规模参数的大语言模型Moonlight-16B。
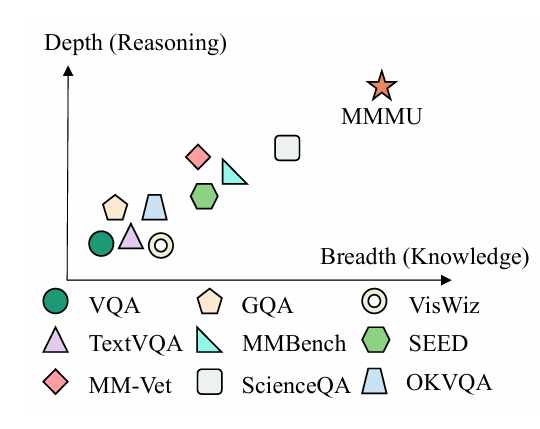
大模型多模态评测基准MMMU(大规模多学科多模态理解和推理基准)是一项旨在评估多模态人工智能模型在复杂跨学科任务中综合能力的测试工具。

短短两年间,AI技术的进步为软件工程带来了新的可能性。然而,这些模型在真实世界的软件工程任务中究竟能发挥多大的作用?它们能否通过完成实际的软件工程任务来赚取可观的收入?为了验证大模型解决真实任务的能力和水平,OpenAI发布了一个全新的大模型评测基准SWE-Lancer来评测大模型这方面的能力。
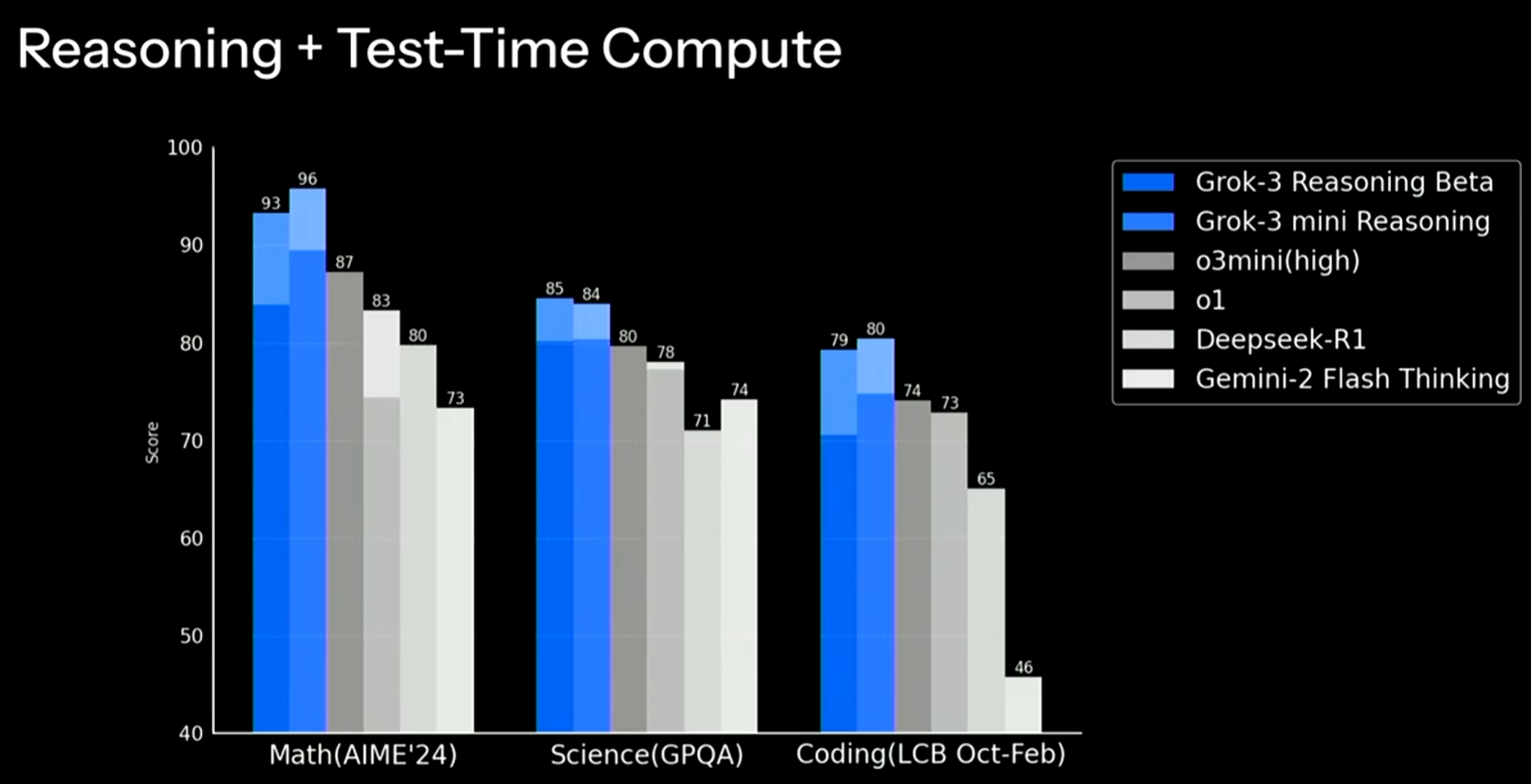
今天马斯克旗下的xAI公司发布了最新一代大语言模型Grok3,基于20万张GPU集群训练,各方面的提升都非常明显。在主流评测上都超过了现有的大模型。
在评估大型语言模型(LLM)的数学推理能力时,MATH和MATH-500是两个备受关注的基准测试。尽管它们都旨在衡量模型的数学解题能力,但在发布者、发布目的、评测目标和对比结果等方面存在显著差异。
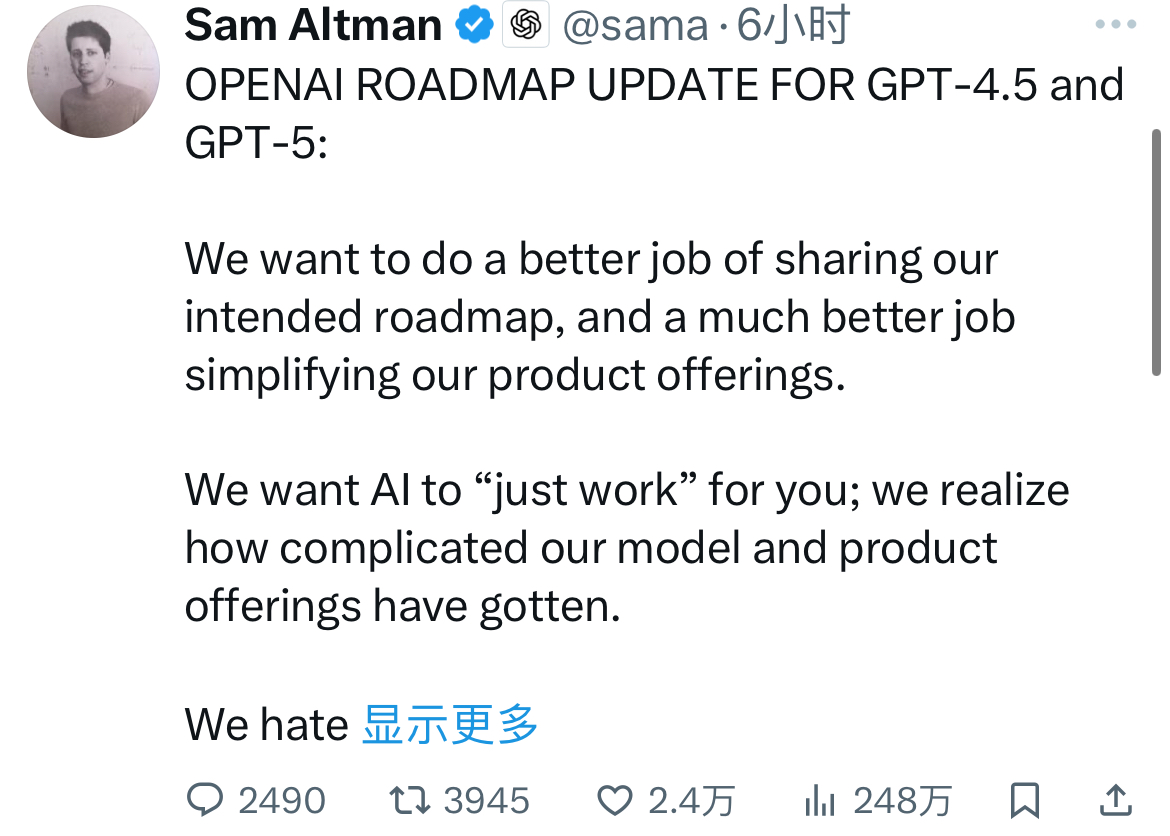
三个小时前,Sam Altam在推特上说明了OpenAI未来的大模型路线图。比较重磅的消息是即将在未来几周发布GPT-4.5,并且在几个月后发布GPT-5。

全球知名AI基准测试机构Artificial Analysis最新发布的2025年第一季度报告揭示了一个引人注目的重要趋势:在大语言模型领域,全球正在形成中美双极主导的新格局。这份权威报告通过严谨的技术指标评测体系,首次以数据量化的方式确认了中国AI技术水平的跨越式发展,特别是在顶尖大模型的研发领域,中国已经实质性地跻身全球第一梯队。本文根据报告的主要内容,为大家总结他们的一些观点和数据。

最近,随着DeepSeek R1的火爆,推理大模型也进入大众的视野。但是,相比较此前的GPT-4o,推理大模型的区别是什么?它适合什么样的任务?推理大模型是如何训练出来的?很多人并不了解。本文将详细解释推理大模型的核心内容。
2025年2月5日,Google官方宣布Gemini 2.0 Pro版本上线,Gemini系列是谷歌最新一代大模型的品牌名称。Google最早在2024年12月中旬发布了Gemini 2.0系列的第一个模型Gemini 2.0 Flash,当时试用的人都普遍反应这个模型速度又快,结果友好,让Google摆脱了此前大模型很落后的印象。今天,Gemini 2.0 Pro上线,其能力更强。
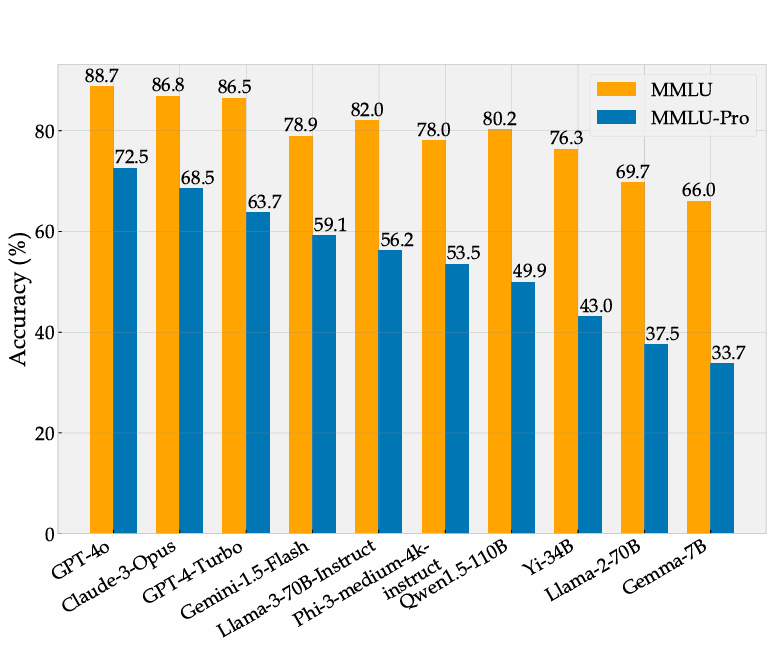
大模型已经对很多行业产生了巨大的影响,如何准确评测大模型的能力和效果,已经成为业界亟待解决的关键问题。生成式AI模型,如大型语言模型(LLMs),能够生成高质量的文本、代码、图像等内容,但其评测却相对很困难。而此前很多较早的评测也很难区分当前最优模型的能力。 以MMLU评测为例,2023年3月份,GPT-4在MMLU获得了86.4分之后,将近2年后的2024年年底,业界最好的大模型在MMLU上得分也就90.5,提升十分有限。 为此,滑铁卢大学、多伦多大学和卡耐基梅隆大学的研究人员一起提出了MMLU P