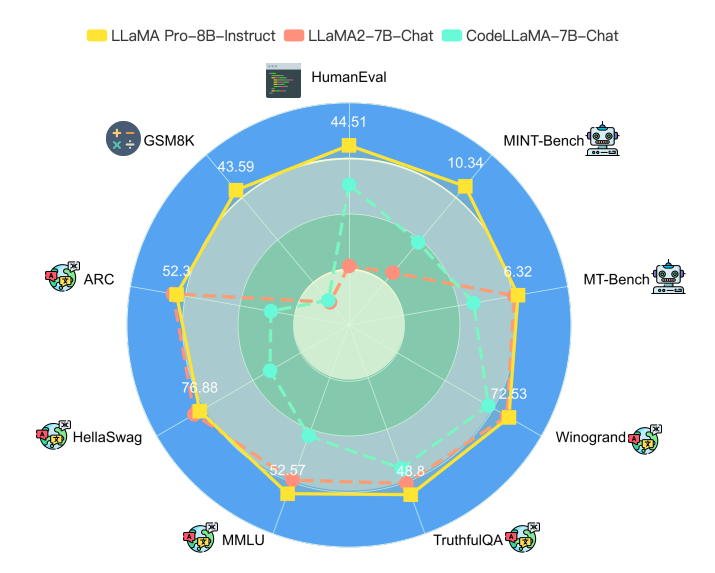
如何解决大模型微调过程中的知识遗忘?香港大学提出有监督微调新范式并开源新模型LLaMA Pro
大语言模型一个非常重要的应用方式就是微调(fine-tuning)。微调通常需要改变模型的预训练结果,即对预训练结果的参数继续更新,让模型可以在特定领域的数据集或者任务上有更好的效果。但是微调一个严重的副作用是可能会让大模型遗忘此前预训练获得的知识。为此,香港大学研究人员推出了一种新的微调方法,可以保证模型原有能力的基础上提升特定领域任务的水平,并据此开源了一个新的模型LLaMA Pro。
探索人工智能与大模型最新资讯与技术博客,涵盖机器学习、深度学习、自然语言处理等领域的原创技术文章与实践案例。
大语言模型一个非常重要的应用方式就是微调(fine-tuning)。微调通常需要改变模型的预训练结果,即对预训练结果的参数继续更新,让模型可以在特定领域的数据集或者任务上有更好的效果。但是微调一个严重的副作用是可能会让大模型遗忘此前预训练获得的知识。为此,香港大学研究人员推出了一种新的微调方法,可以保证模型原有能力的基础上提升特定领域任务的水平,并据此开源了一个新的模型LLaMA Pro。

最近两天,关于AI技术和产品的进展依然很快。所以,我们本次直接给出一个AI技术进展快报。与大家分享一下最新的AI技术情况。

微软在去年4月份的时候推出了一个构建虚拟助手的指南:《构建人工智能应用的开发者指南·第二版》。这份报告帮助我们借助微软的工具构建一个虚拟助手,本文将简要描述一下这份报告,文末有相关资源下载。
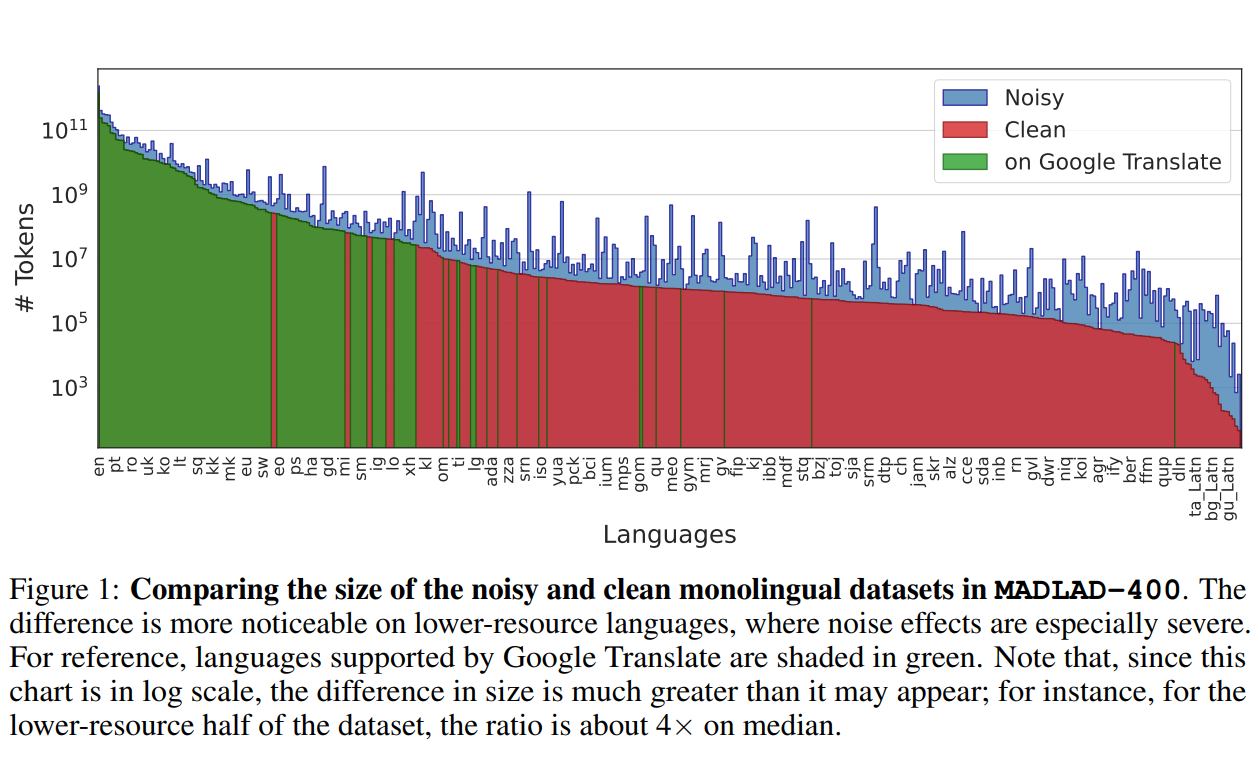
Google DeepMind与Google Research的研究人员推出了一个全新的多语言数据集——MADLAD-400!这个数据集汇集了来自全球互联网的419种语言的大量文本数据,其规模和语言覆盖范围在公开可用的多语言数据集中应该是最大的。研究人员从Common Crawl这个庞大的网页爬虫项目中提取了大量数据,并进行了人工审核,删除了许多噪音,使数据集的质量得到了显著提升。
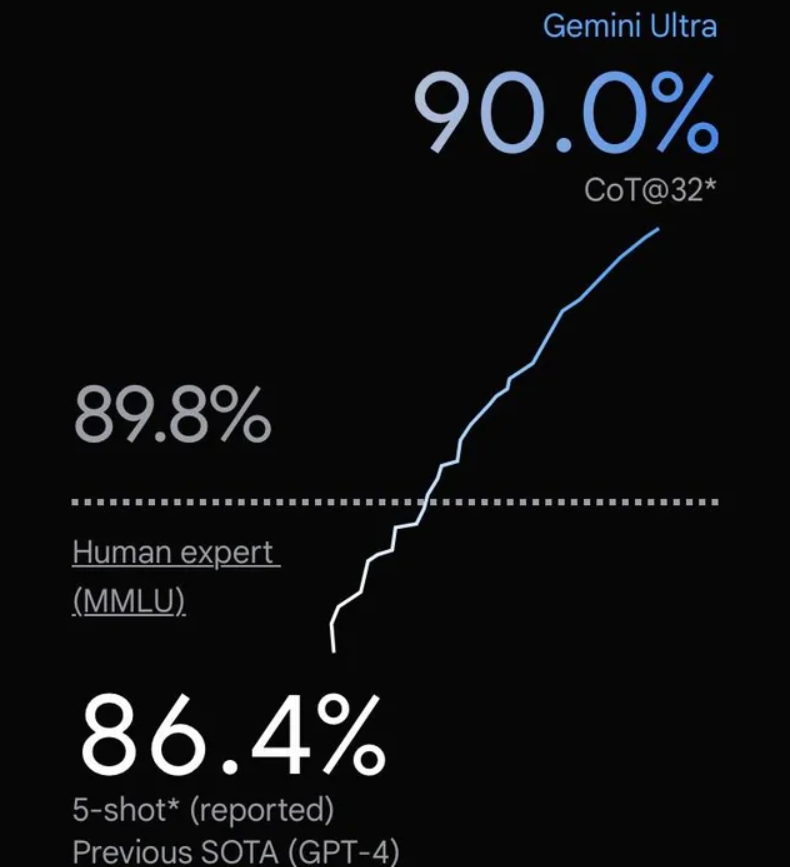
谷歌在几个小时前发布了Gemini大模型,号称历史最强的大模型。这是一系列的多模态的大模型,在各项评分中超过了GPT-4V,可能是目前最强的模型。

OpenAI在3月15日发布了一个最新的GPT-3和Codex的版本,这个版本最大的能力就是可以在已有的文本上插入或者编辑新的内容。而不是续写已有的文本。这个能力最大的应用就是重写已有文本,或者用来重构代码。
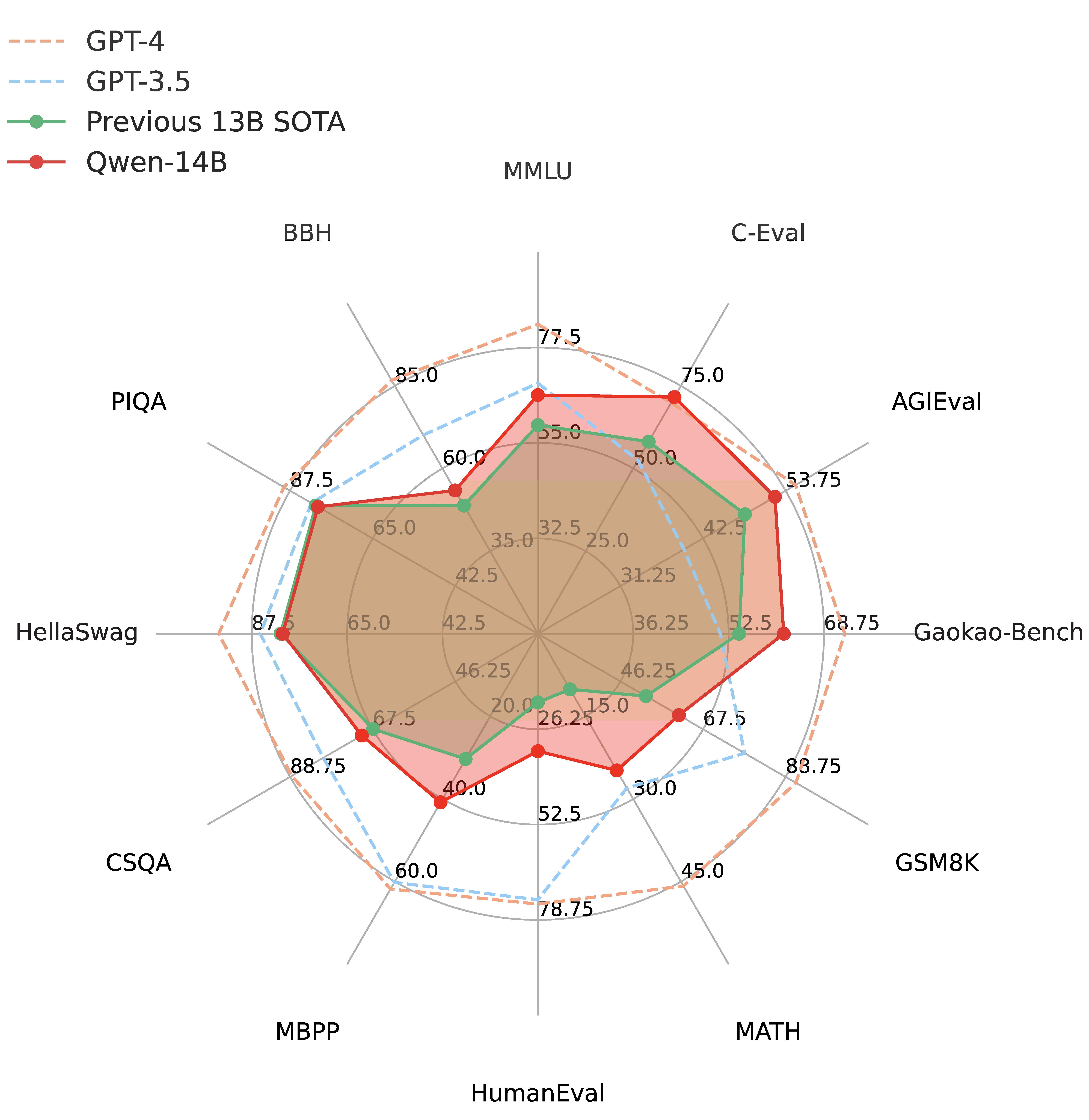
通义千问是阿里巴巴推出的一个大语言模型,此前开源的Qwen-7B引起了广泛的关注,因为他的理解能力很强但是参数规模很小,因此受到了很多人的欢迎。而目前再次开源全新的Qwen-14B的模型,参数规模142亿,但是它的理解能力接近700亿参数规模的LLaMA2-70B,数学推理能力超过GPT-3.5。

Mistral-7B是由MistralAI开源的一个73亿参数规模的大语言模型,最早在2023年9月底开源。因为其良好的性能和友好的开源协议被很多人使用。今天,这个模型升级到来v0.2版本Mistral-7B-v0.2。基于Mistral-7B-v0.2进行指令微调的模型 Mistral-7B-Instruct-v0.2在2023年11月11日公布,而这个基座模型则是在2023年3月24日开源。
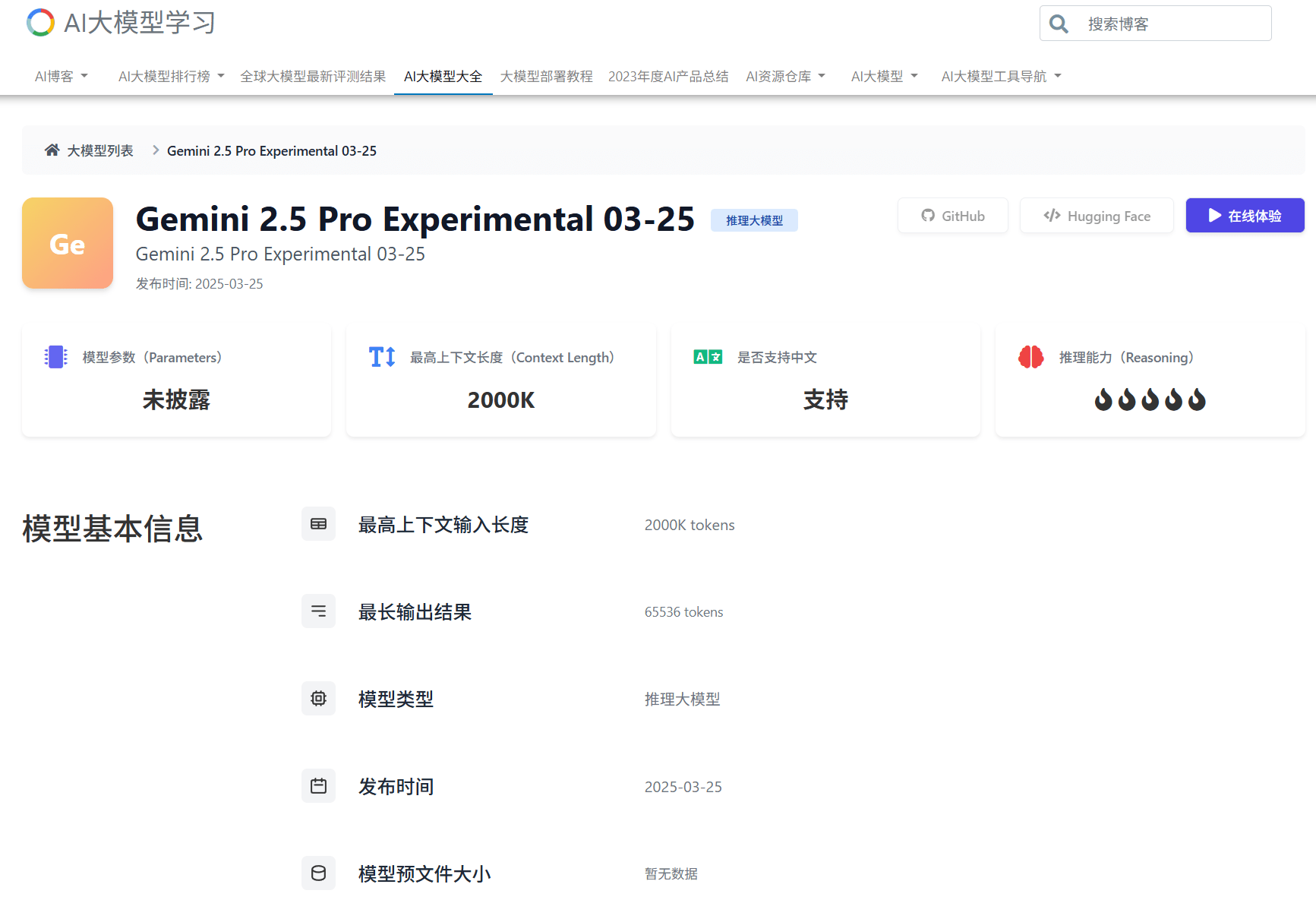
Gemini 2.5 Pro是Google发布的一个新一代大模型,Gemini 2.5 Pro是一个推理大模型,在数学和编程方面有了非常强大的能力,该模型最高支持200万tokens的上下文输入,非常强大!

The AI Index报告是斯坦福大学发布的人工智能发展研究报告。最早的报告开始于2017年,每年一个版本,主要是总结过去一年人工智能的发展情况。2023年斯坦福The AI Index已经在近日发布。相比较之前的报告,今年的报告新增对Foundation模型的分析。让我们看看斯坦福大学如何总结2022年人工智能领域的发展情况。
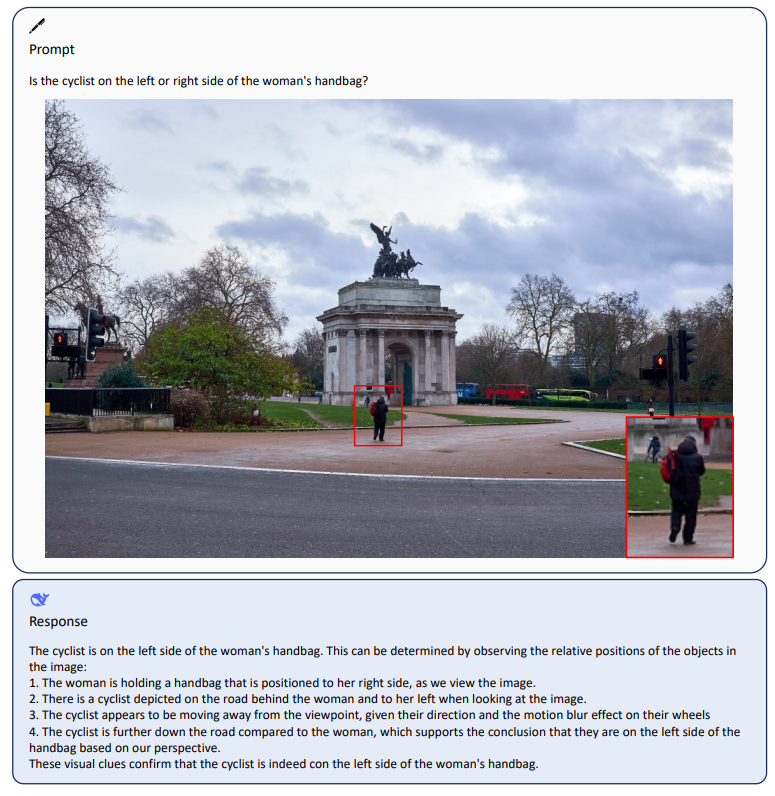
深度求索是著名量化机构幻方量化旗下的一家大模型初创企业,成立与2023年7月份。他们开源了很多大模型,其中编程大模型DeepSeek-Coder系列获得了非常多的好评。而在今天,DeepSeek-AI再次开源了全新的多模态大模型DeepSeek-VL系列,包含70亿和13亿两种不同规模的4个版本的模型。

昨天,卡地夫大学的NLP研究小组CardiffNLP发布了一个全新的NLP处理Python库——TweetNLP,这是一个完全基于推文训练的NLP的Python库。它提供了一组非常实用的NLP工具,可以做推文的情感分析、emoji预测、命名实体识别等。
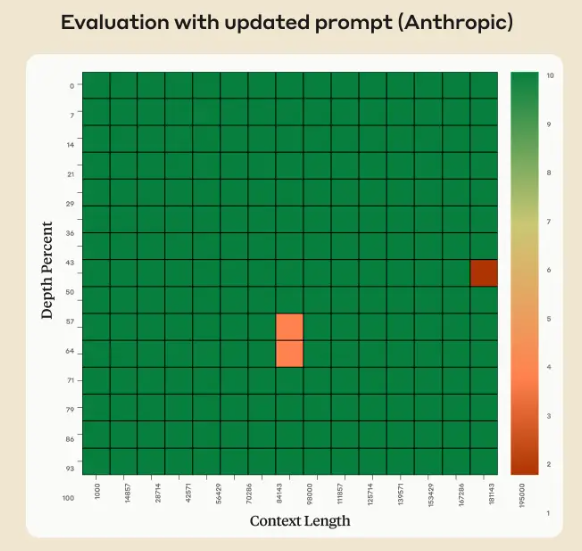
Claude 2.1版本的模型上下文长度最高拓展到200K,也是目前商用领域上下文长度支持最长的模型之一。但是,在模型发布不久之后,有人测试发现模型在超过20K之后效果下降明显。但是Anthropic官方发布了一个说明解释这不是Claude模型本身在超长上下文的真实原因,主要是模型拒绝回答一些与文章主体不符的内容,实际中只需要一句prompt即可提高性能,将模型在超长上下文的水平准确率从27%提高到98%。

Qwen3 是阿里于 2025 年 6 月开源的新一代大模型系列,共发布了 8 个不同参数规模的模型,覆盖从 6 亿到 2350 亿参数的范围,融合了稠密模型和 MoE 架构。值得注意的是,此次未包含此前广受关注的 Qwen-72B 稠密模型版本,阿里表示从 Qwen3 起,超过 30B 参数的模型将统一采用 MoE 架构以优化性能和效率。
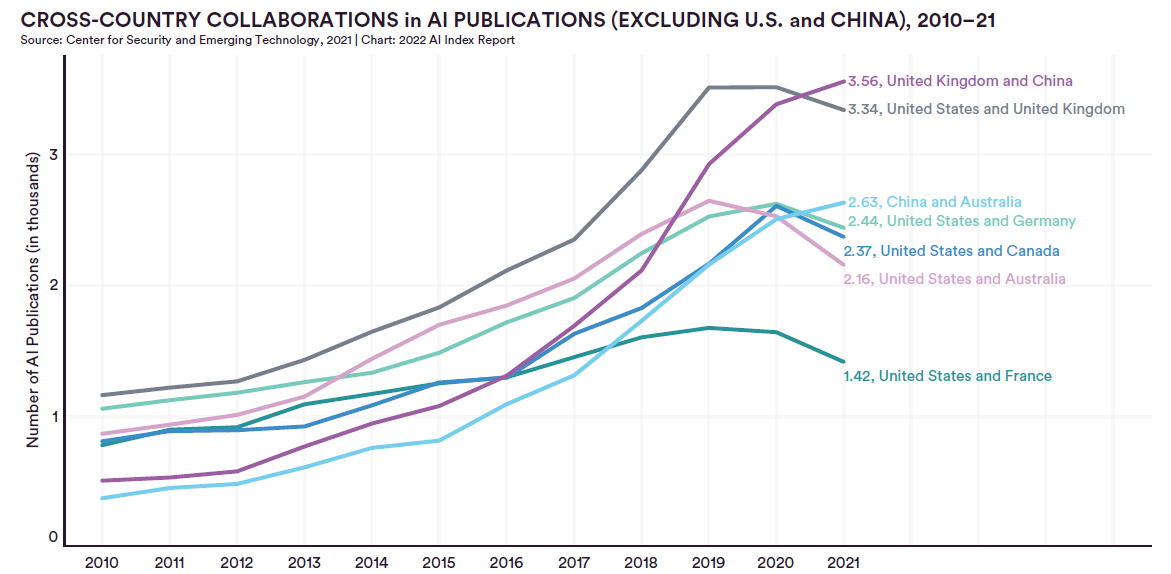
人工智能指数是斯坦福大学以人为本人工智能研究所(Stanford Institute for Human-Centered Artificial Intelligence (HAI))联合学术界、工业界的专家一起发布的人工智能相关的发展报告。2022年度AI指数报告在近几日发布。

随着安全隐私被大家所重视,网站开启HTTPS访问已经是不可阻挡的趋势。HTTPS协议就是借助SSL/TLS证书实现http的加密传输的协议(HTTP Over SSL/TLS)。本文将记录如何使用第三方库申请Let's Encrypt证书,并在tomcat中开启相关的功能。

今天,HuggingFace官方宣布了Transformers最大胆的功能:Transformers Agents。这是继AutoGPT开创性发布之后,AI Agent被业界接受的另一个重要的里程碑。

在深度学习和计算机视觉的发展历程中,视频生成技术一直是一个极具挑战和创新的领域。而发布了一系列开源领域最强图像生成模型Stable Diffusion系列模型背后的企业StabilityAI最近又开源了一个的文本生成视频大模型Stable Video Diffusion模型,这个模型可以生成最多20帧的视频。测试效果,这个模型普通版本与runway差不多,20帧版本则超过了runway!

近几年语言模型的发展速度很快,各种大语言预训练模型的推出让算法在各种NLP的任务中都取得了前所未有的成绩。其中2017年谷歌发布的Attention is All You Need论文将transformer架构推向了世界,这也是现在最流行的语言模型结构。威斯康星大学麦迪逊分校的统计学教授Sebastian Raschka总结了6中Language Transformer的使用方法。值得一看。

2024年10月22日,Anthropic发布了两个新模型:升级版的Claude 3.5 Sonnet和全新的Claude 3.5 Haiku。升级版的Claude 3.5 Sonnet在保持原有价格和速度的基础上,实现了全面性能提升,尤其在编码领域取得了显著进步。新推出的Claude 3.5 Haiku则以与Claude 3 Haiku相同的成本和类似的速度,在多个评测中达到了与Claude 3 Opus相当的性能水平。

今天,吴恩达在推特上宣布和OpenAI、LangChain以及Lamini三家公司共同推出了3门短视频课程,分别是《使用ChatGPT API构建系统》、《基于LangChain的大语言模型应用与开发》和《Diffusion模型是如何工作的》。三门课程都是1个小时的短视频课程,而且配有详细的Jupyter Notebook使用方法。
