
原创博客
原创AI技术博客
探索人工智能与大模型最新资讯与技术博客,涵盖机器学习、深度学习、自然语言处理等领域的原创技术文章与实践案例。
阿里巴巴的第二代通义千问可能即将发布:Qwen2相关信息已经提交HuggingFace官方的transformers库
通义千问是阿里巴巴开源的一系列大语言模型。Qwen系列大模型最高参数量720亿,最低18亿,覆盖了非常多的范围,其各项评测效果也非常好。而昨天,Qwen团队的开发人员向HuggingFace的transformers库上提交了一段代码,包含了Qwen2的相关信息,这意味着Qwen2模型即将到来。

深度学习中为什么要使用Batch Normalization
Batch Normalization(BN)是一种深度学习的layer(层)。它可以帮助神经网络模型加速训练,并同时使得模型变得更加稳定。尽管BN的效果很好,但是它的原理却依然没有十分清晰。本文总结一些相关的讨论,来帮助我们理解BN背后的原理。
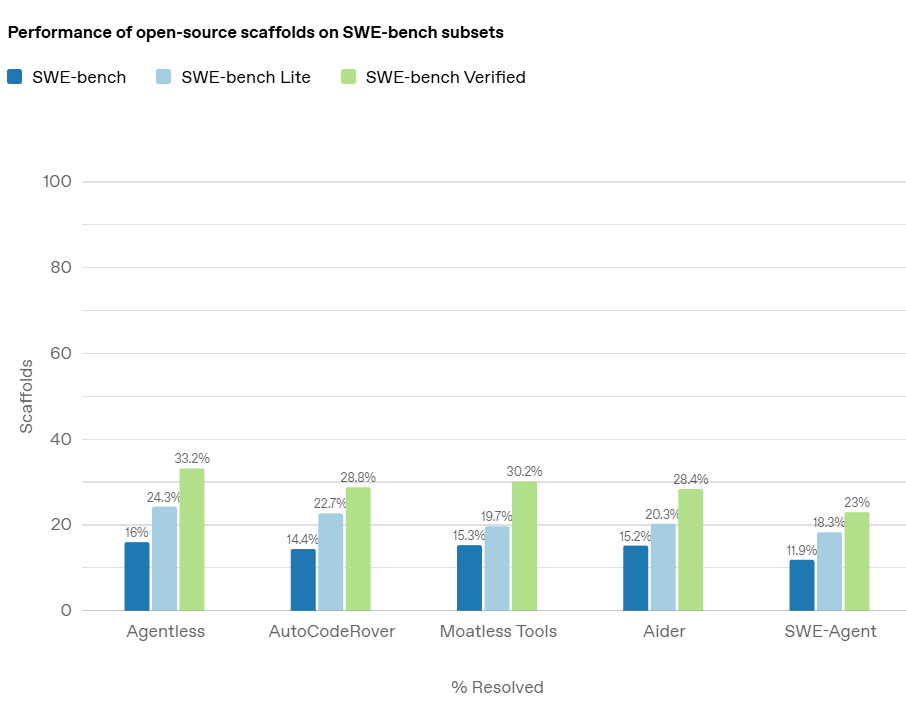
SWE-bench Verified:提升 AI 模型在软件工程任务评估中的可靠性
在人工智能领域,随着大型语言模型(LLMs)在各类任务中的表现不断提升,评估这些模型的实际能力变得尤为重要。尤其是在软件工程领域,AI 模型是否能够准确地解决真实的编程问题,是衡量其真正应用潜力的关键。而在这方面,OpenAI 推出的 *SWE-bench Verified* 基准测试,旨在提供一个更加可靠和精确的评估工具,帮助开发者和研究者全面了解 AI 模型在处理软件工程任务时的能力。
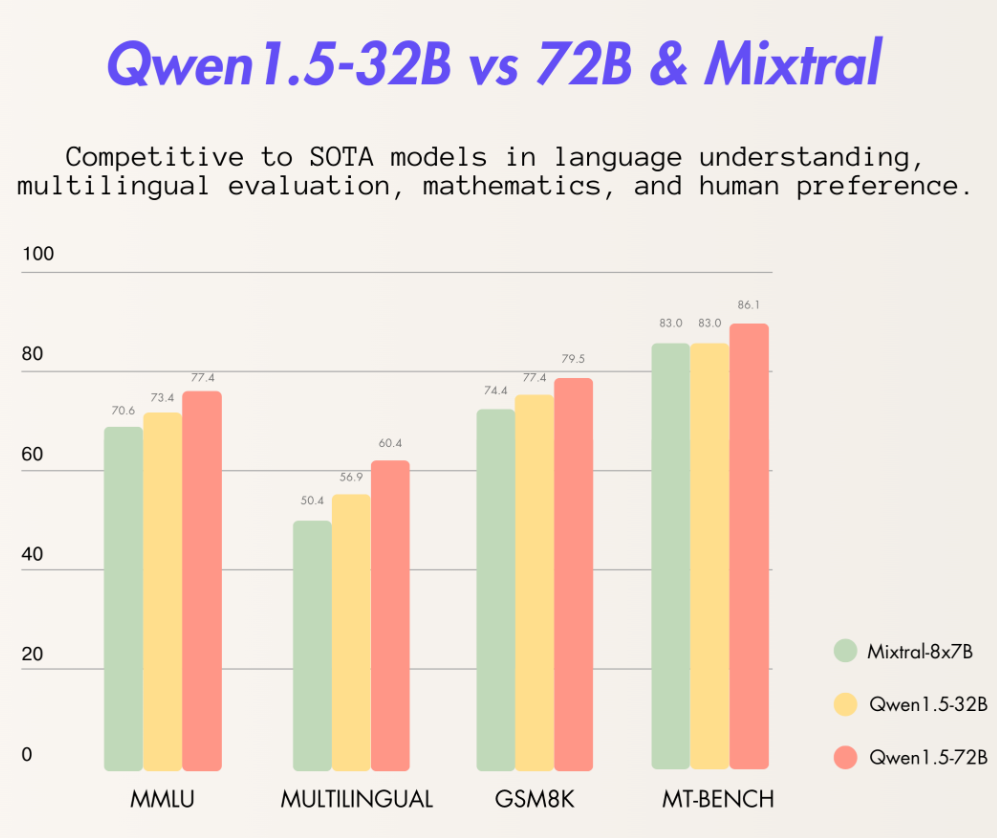
Qwen1.5系列再次更新:阿里巴巴开源320亿参数Qwen1.5-32B模型,评测结果超过Mixtral 8×7B MoE,性价比更高!
阿里巴巴最新开源了320亿参数的大语言模型Qwen1.5-32B,这个模型在各项评测结果中都略超此前最强开源大模型Mixtral 8×7B MoE,比720亿参数的Qwen-1.5-72B模型略差。但是一半的参数意味着只有一半的显存,这样的性价比极高。

全球首个AI软件工程师问世:可以自己训练微调大模型的AI软件工程师Devin简介
大多数编程领域的大模型应用都是单行代码补全或者单个函数生成的方式。完整的程序生成依然面临较大的挑战。而现在,一个初创企业直接发布了一个AI软件工程师,可以直接作为一个程序员来接受用户需求和反馈,独立完成编码和应用上线功能。这就是Cognition发布的全球首个AI软件工程师Devin。

开源模型进展迅猛!最新开源不可商用模型Command R+在大模型匿名投票得分上已经超过GPT-4-Turbo!
开源大语言模型经过一年多的发展,终于有一个模型可以在权威榜单上击败GPT-4的较早的版本,这就是CohereAI企业开源的Command R+。这是一个开源但是不允许商用的模型,参数规模达到1040亿,也是目前为止开源参数规模最大的一个模型。
未经证实的GPT-4技术细节,关于GPT-4的参数数量、架构、基础设施、训练数据集、成本等信息泄露,仅供参考
几个小时前SemiAnalysis的DYLAN PATEL和DYLAN PATEL发布了一个关于GPT-4的技术信息,包括GPT-4的架构、参数数量、训练成本、训练数据集等。本篇涉及的GPT-4数据是由他们收集,并未公开数据源。但是内容还是有一定参考性,大家自行判断。

OpenAI是一家什么样的企业——OpenAI介绍与成果总结
OpenAI是全球最著名的人工智能研究机构,发布了许多著名的人工智能技术和成果,如大语言模型GPT系列、文本生成图片预训练模型DALL·E系列、语音识别模型Whisper系列等。由于这些模型在各自领域都有相当惊艳的表现,引起了全世界广泛的关注。

一个非常有趣的数据工程师小游戏
Firebolt开发了一个数据工程师的网页小游戏,带你体验数据分析的全流程。游戏里你扮演一个数据工程师,从数据收集开始,经历数据pipeline、数据入数据湖以及数据分析等,最终形成各种图表的结果。

Python3.10版本的结构模式匹配(structural pattern matching)简介
Python最新正式版本3.10在10月4日已经发布。这个版本从2020年5月开始开发,经历差不多一年半的时间终于正式发布。当然每一个新版本都有很多新功能。我们将持续关注新功能,在这篇文章中,我们将简述3.10中新功能中的语法——结构模式匹配(structural pattern matching)。
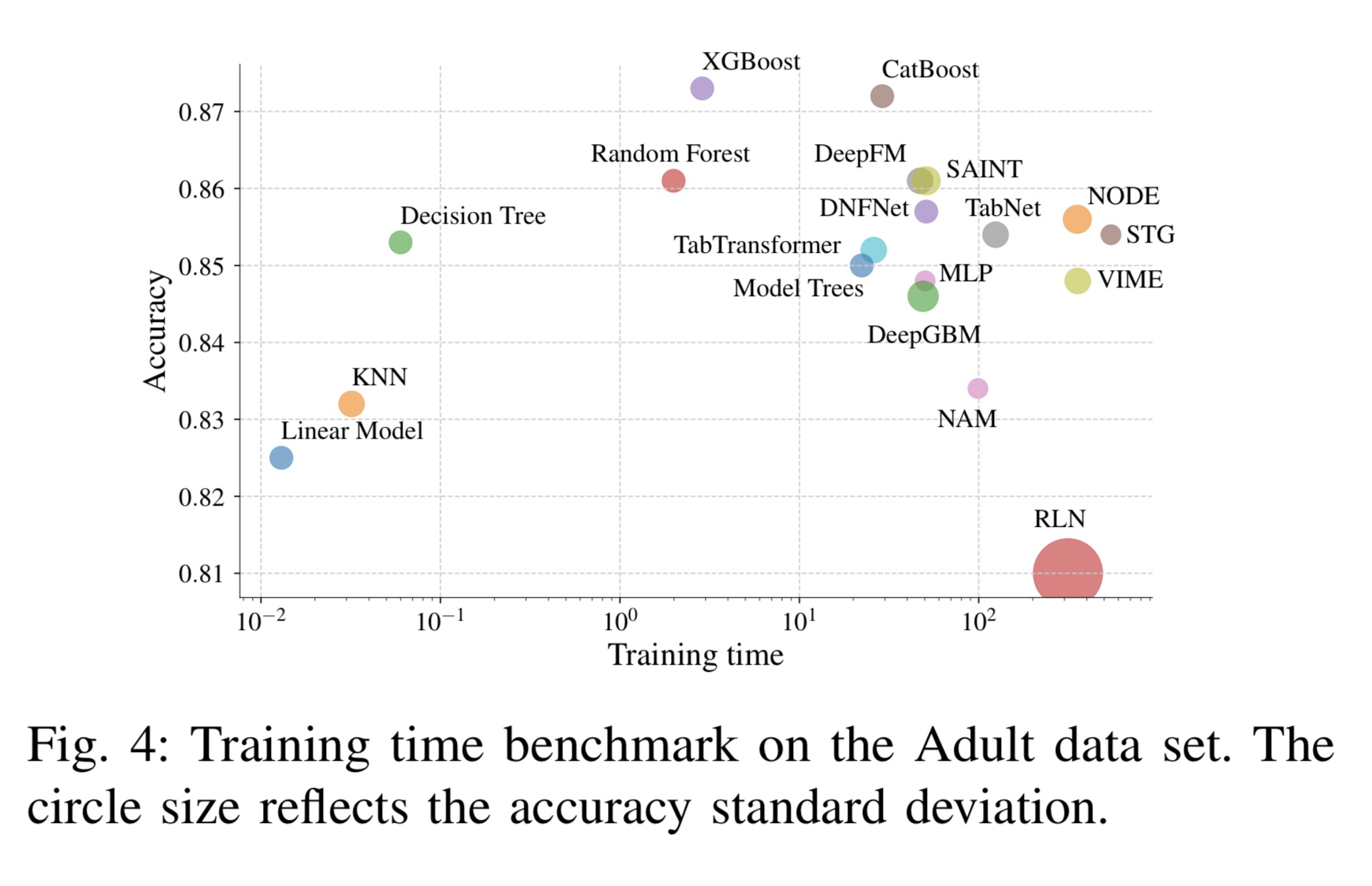
Deep Neural Networks and Tabular Data: A Survey——XGBoost依然是最优秀的算法模型
异质表格数据是最常用的数据形式,对于众多关键和计算要求高的应用来说是必不可少的。在同质数据集上,深度神经网络已多次显示出优异的性能,因此被广泛采用。然而,它们在表格数据建模(推理或生成)方面的应用仍然具有高度挑战性。

推荐一个给新手的可视化的机器学习模型训练网站
使用AI技术预测未来、对数据进行分类可以解决很多个人或者小企业的问题。然而,对于新手和非行业的小企业来说,学习或者雇佣一个专业人才解决这些问题似乎有些得不偿失。这里给大家推荐一个给新手的可视化的机器学习模型训练网站,可以让大家都能享受到AI技术带来的红利。
重磅!阿里开源第三代千问大模型:Qwen3系列,最小仅6亿参数规模,最大2350亿参数规模大模型!可以根据问题难度自动选择是否带思考过程的大模型,评测超DeepSeek-R1和OpenAI o3
阿里巴巴刚刚开源了第三代千问大模型,Qwen3系列包含了8个不同参数规模的大模型,最大达到2350亿参数规模,最小仅6亿参数规模。本次发布的Qwen3系列是推理大模型和常规的大模型混合版本,即Qwen3可以根据输入问题的情况自动选择是否进行推理。
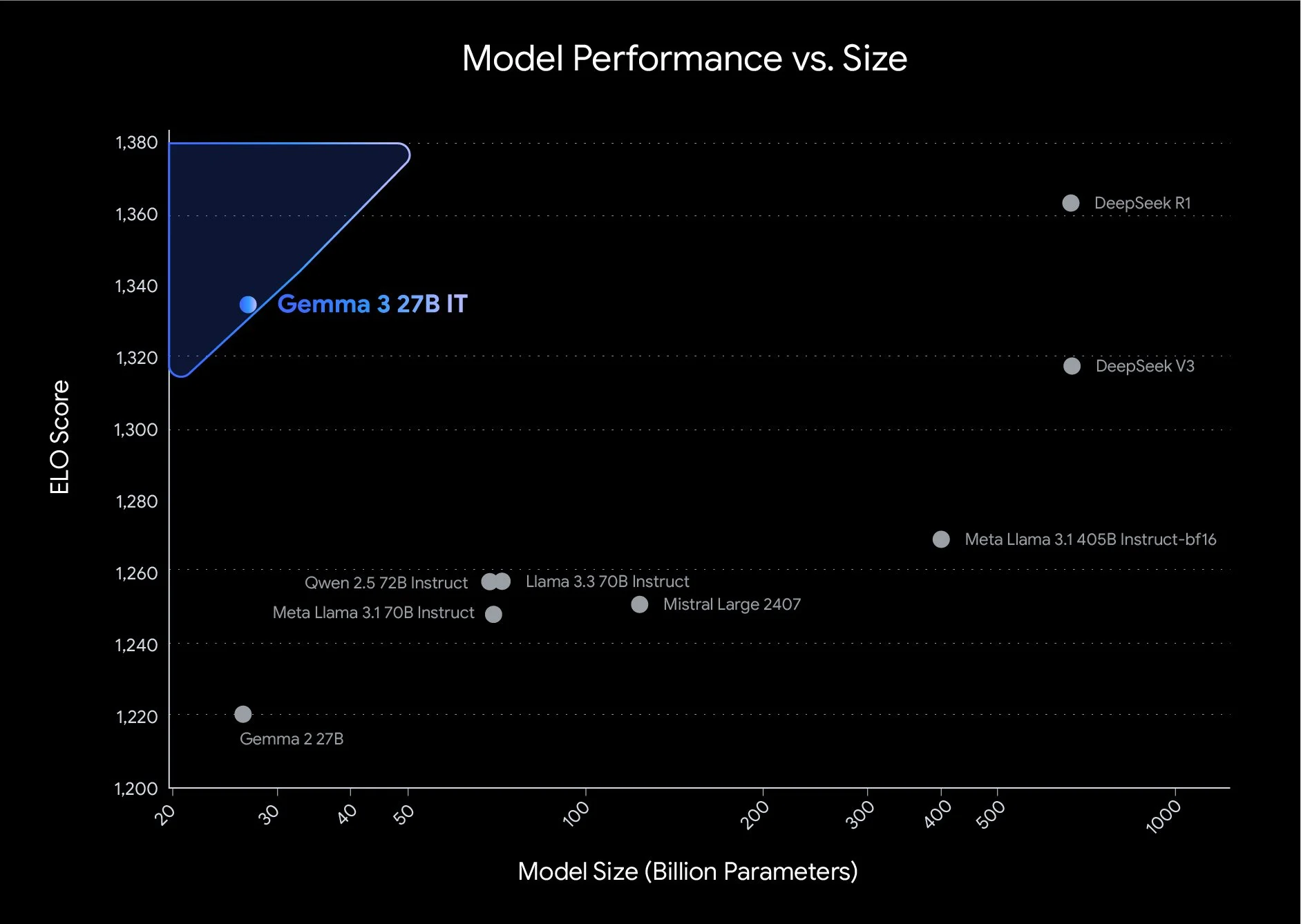
Google开源第三代Gemma-3系列模型:支持多模态、最多128K输入,其中Gemma 3-27B在大模型匿名竞技场得分超过了Qwen2.5-Max
Gemma系列大模型是Google开源的一系列轻量级的大模型。就在刚才(2025年3月12日),Google开源了第三代Gemma系列大模型,共包含4个不同参数规模版本,第三代的Gemma 3系列是多模态大模型,即使是最小的10亿参数规模的Gemma 3-1B也支持多模态输入。
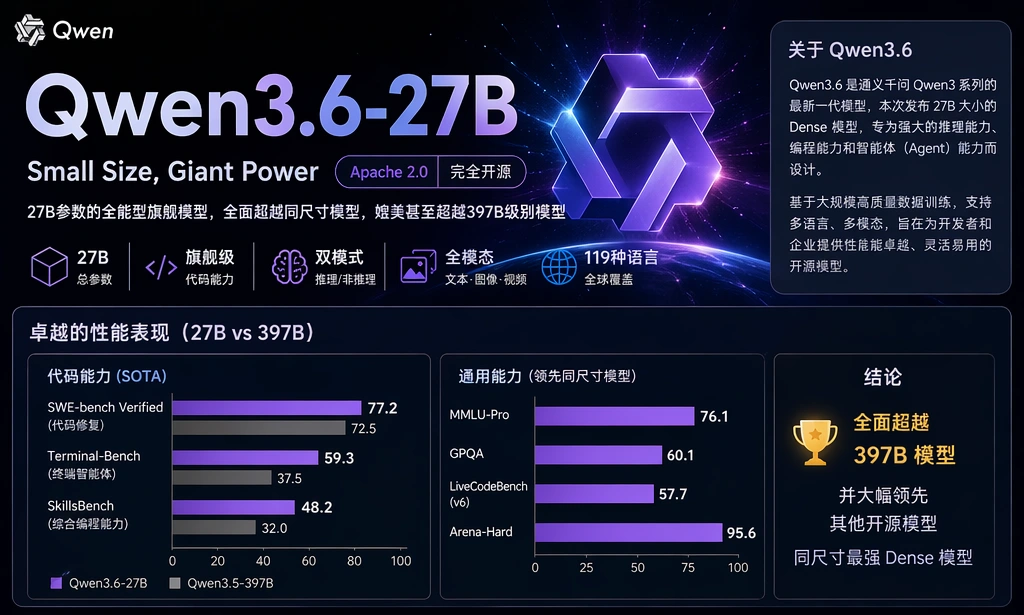
阿里正式开源Qwen3.6-27B:代码智能体能力上超越全面超越前代旗舰版本之 Qwen3.5-397B-A17B
Qwen3.6-27B 于2026年4月22日发布,是首个在全主要代码智能体评测上超越 Qwen3.5-397B-A17B 的开源稠密27B模型。SWE-bench Verified 77.2、Terminal Bench 2.0 59.3、SkillsBench 48.2(前代30.0)、AIME 2026 94.1(全球第4)。本文结合 DataLearner 评测数据与官方基准,分析其实质进展与能力边界。
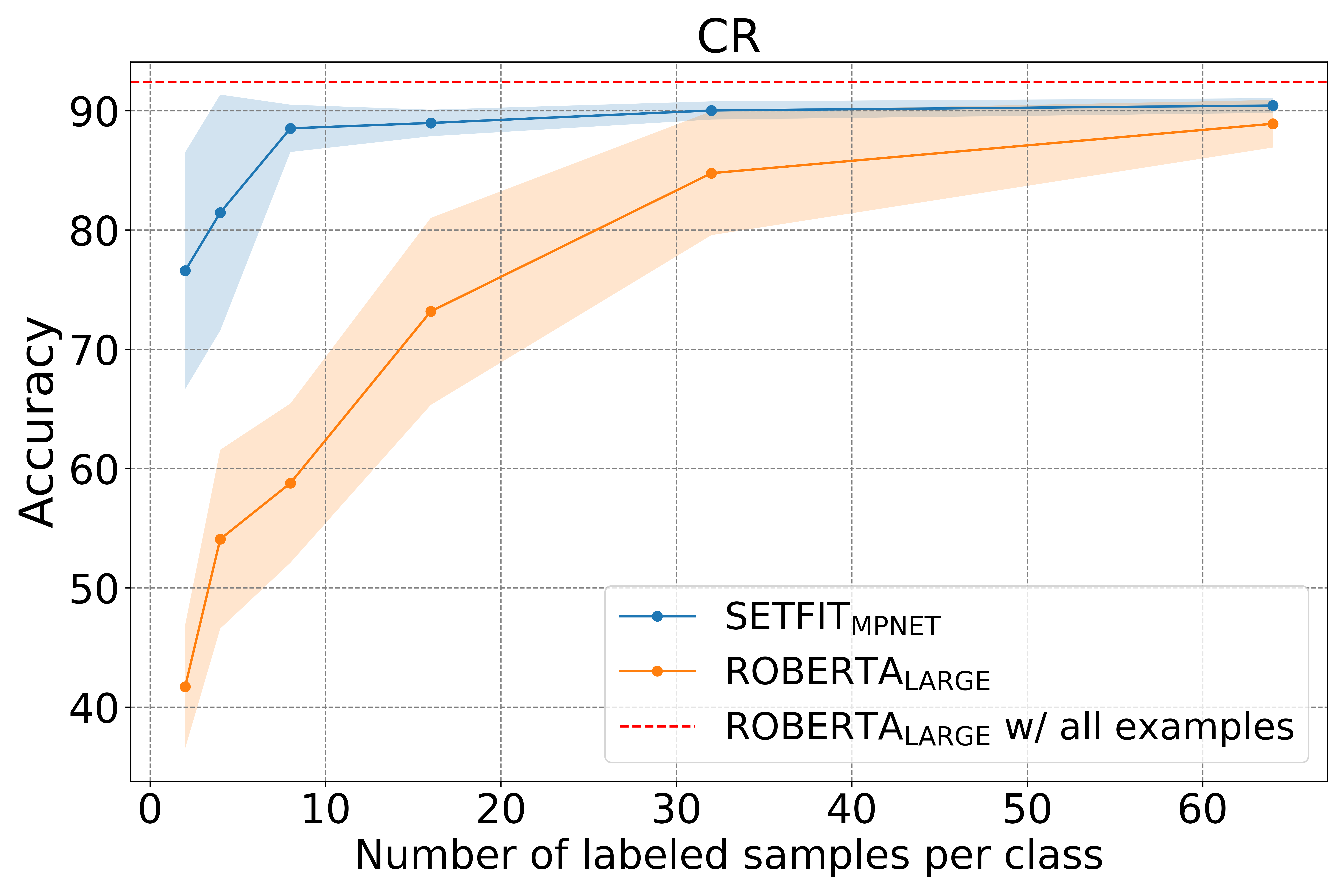
缺少有标注的数据集吗?福音来了——HuggingFace发布few-shot神器SetFit
少量标记的学习(Few-shot learning)是一种在较少标注数据集中进行模型训练的一种学习方法。为了解决大量标注数据难以获取的情况,利用预训练模型,在少量标记的数据中进行微调是一种新的帮助我们进行模型训练的方法。而就在昨天,Hugging Face发布了一个新的语句transformers(Sentence Transformers)框架,可以针对少量标记数据进行模型微调以获取很好的效果。

重磅!OpenAI发布GPT-4o mini,这是GPT-3.5的替代升级版,价格下降60%,但是更快更强!编程能力甚至超过GPT-4!
就在刚才,OpenAI官方宣布即将推出GPT-4o mini模型,这是一个成本很低的AI大模型,是GPT-3.5的替代版本。OpenAI官方说,该模型最大的特点是很便宜,但是能力更强,因此可以极大提高AI在不同领域的应用。

Terminal-Bench 评测全解析:一个用于评测大模型在终端环境使用工具能力的评测基准以及Terminal 1.0与 2.0 的完整对比
本文介绍 Terminal-Bench 的设计理念,深入讲解 core、Terminal-Bench Hard 与最新 Terminal-Bench 2.0 的区别,帮助开发者选择合适的 AI 终端评测基准。

来自OpenAI的官方解释:ChatGPT中的GPTs与Assistants API的区别是什么?有什么差异?
OpenAI发布的产品中,有2个产品可以用来将GPT当作一个类似AI Agent工具使用,同时支持接入自定义的接口和数据。那就是GPTs和Assistant API,前者可以在界面直接操作,后者则是一个API,两者功能接近,为了让大家更加清晰理解二者区别,OpenAI官方最近发布了二者的解释。