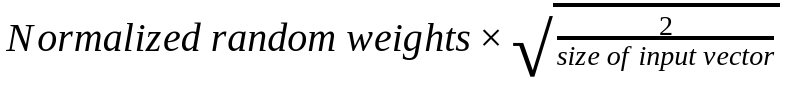OpenAI官方教程:如何针对大模型微调以及微调后模型出现的常见问题分析和解决思路~以GPT-3.5微调为例
OpenAI在2023年8月份发布了GPT-3.5的微调接口,并表示会在2023年秋天开放16K的gpt-3.5-turbo-16k模型和GPT-4的微调(参考:[重磅!GPT-3.5可以微调了!OpenAI发布GPT-3.5 Turbo微调接口](https://www.datalearner.com/blog/1051692752268726 "重磅!GPT-3.5可以微调了!OpenAI发布GPT-3.5 Turbo微调接口"))。然而,微调并不是一个简单的问题,如何对大模型微调以及如果微调出现问题