多项式分布的贝叶斯推断
多项式分布是非常常见的分布,他是二项分布在多维上的推广。例如掷骰子结果中,1-6点出现的次数就是一个多项式分布。多项式分布在如主题建模中非常常见,本文将讲述多项式分布的贝叶斯推导过程。
探索人工智能与大模型最新资讯与技术博客,涵盖机器学习、深度学习、自然语言处理等领域的原创技术文章与实践案例。
多项式分布是非常常见的分布,他是二项分布在多维上的推广。例如掷骰子结果中,1-6点出现的次数就是一个多项式分布。多项式分布在如主题建模中非常常见,本文将讲述多项式分布的贝叶斯推导过程。

预测问题一直是机器学习领域最重要的问题之一。很多算法包括回归、决策树等都是用来解决预测的常用算法。预测问题的核心是基于已有的有标签的数据来判断新数据的标签。一般来说,根据预测标签是离散的还是连续的可以分成分类问题和回归问题。注意,本篇博客主要是快速回顾描述各个模型的优缺点,因此不会对模型有很深的介绍。
Anthropic公司宣布,其开发的智能助手Claude推出收费订阅服务,命名为Claude Pro,定价20美元一个月(或者18英镑)。免费用户依然可以使用,但是有发送频率限制。本篇博客将解释一下ClaudeAI的Claude服务是否收费以及收费之后的ClaudePro提供的服务等。

使用配置文件控制程序的运行是一种非常常见的编程技巧,因此配置文件的解析是所有编程语言中都不可缺少的模块。在Python中,通常使用configparser模块进行配置文件解析。但是configparser解析配置文件有几个常见问题:读取当前项目下某个位置的配置文件、重复配置项的处理以及大小写配置项的读取。本文将描述如何解决这三个问题。
在使用HttpClient作为客户端请求数据的时候,我们常常需要以一个用户的身份多次请求一个网站内的多种资源。例如,我一次登录后,后面希望以这个身份继续访问不用重新登录。这里就可以使用cookie了。
使用爬虫获取数据对科研来说及其重要,本系列博客将讲述如何使用Java编写爬虫工具获取网页数据。包括HttpClient 4.3及以上版本的Header设置,请求参数设置等。
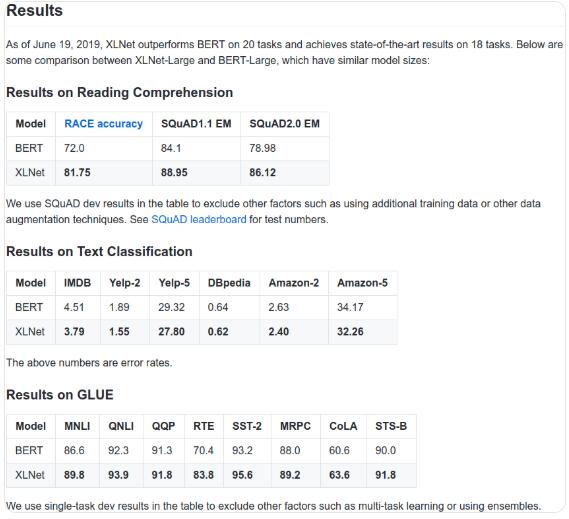
前几天刚刚发布的XLNet彻底火了,原因是它在20多项任务中超越了BERT。这是一个非常让人惊讶的结果。之前我们也说过,在斯坦福问答系统中,XLNet也取得了目前单模型第一的成绩(总排名第四,前三个模型都是集成模型)。
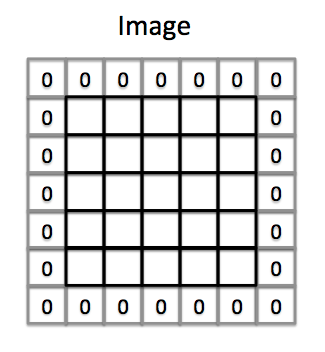
卷积神经网络是深度学习中处理图像的利器。在卷积神经网络中,Padding是一种非常常见的操作。本片博客将简要介绍Padding的原理。
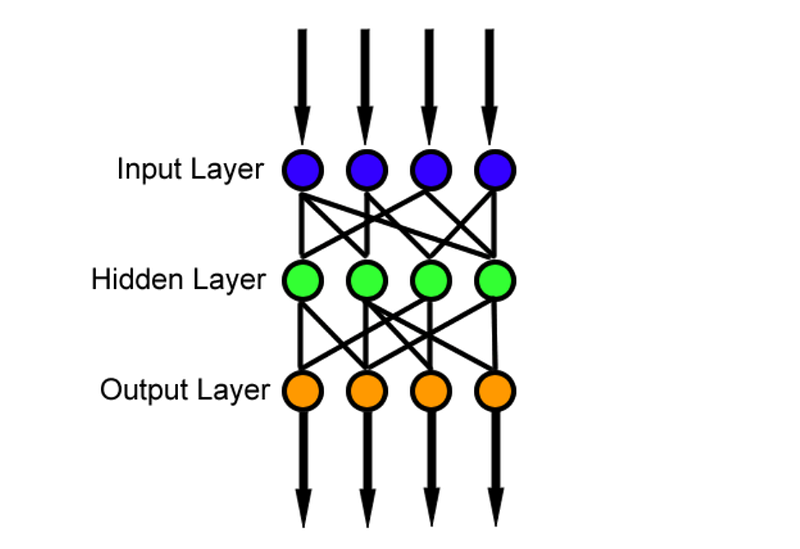
深度学习是计算机领域中目前非常火的话题,不仅在学术界有很多论文,在业界也有很多实际运用。本篇博客主要介绍了三种基本的深度学习的架构,并对深度学习的原理作了简单的描述。本篇文章翻译自Medium上一篇入门介绍。
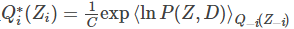
变分贝叶斯是一类用于贝叶斯估计和机器学习领域中近似计算复杂(intractable)积分的技术。它主要应用于复杂的统计模型中,这种模型一般包括三类变量:观测变量(observed variables, data),未知参数(parameters)和潜变量(latent variables)。
昨天,Copilot团队推出了一个名为GitHub Copilot Labs的VS Code配套扩展。它独立于(并依赖于)GitHub Copilot扩展。它可以用来解释代码和翻译代码。
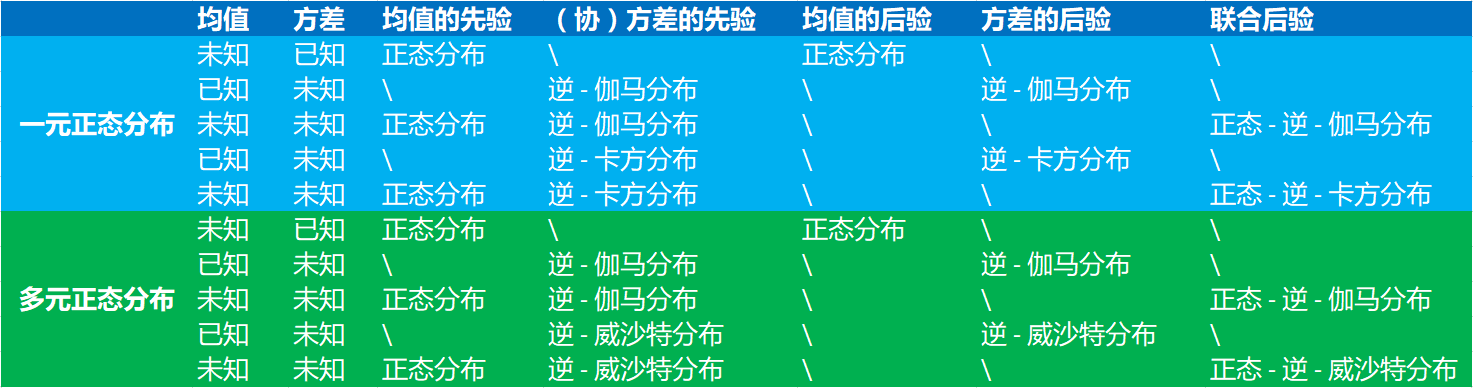
高斯分布是最常见的分布,也是数据挖掘和人工智能中相关统计学习方法所涉及到的最重要的分布之一。使用贝叶斯理论进行统计推断是目前最流行的推断方式。
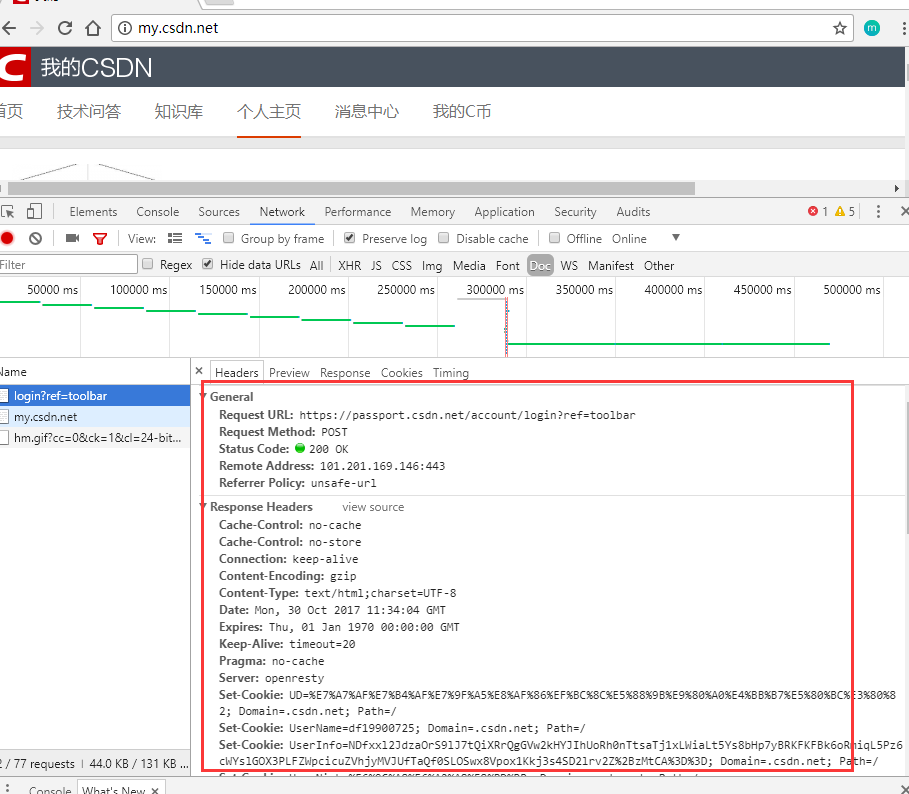
网络爬虫需要解决的一个重要的问题就是要针对某些需要用户名和密码访问的页面可以模拟用户自动登录。在这一篇博客中我们将介绍如何使用Chrome浏览器自带的抓包工具分析页面并模拟用户自动登录
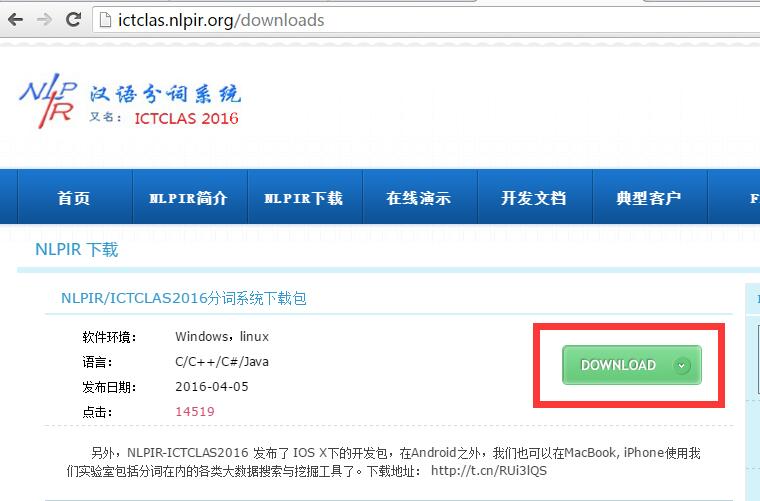
张华平汉语分词系统,现称为NLPIR汉语分词系统,是优秀的中文分词系统。但其使用却有一些配置上的设置是新手可能遇到的一个困难。这里我们简单介绍使用Eclipse导入NLPIR分词系统工程的使用方法。
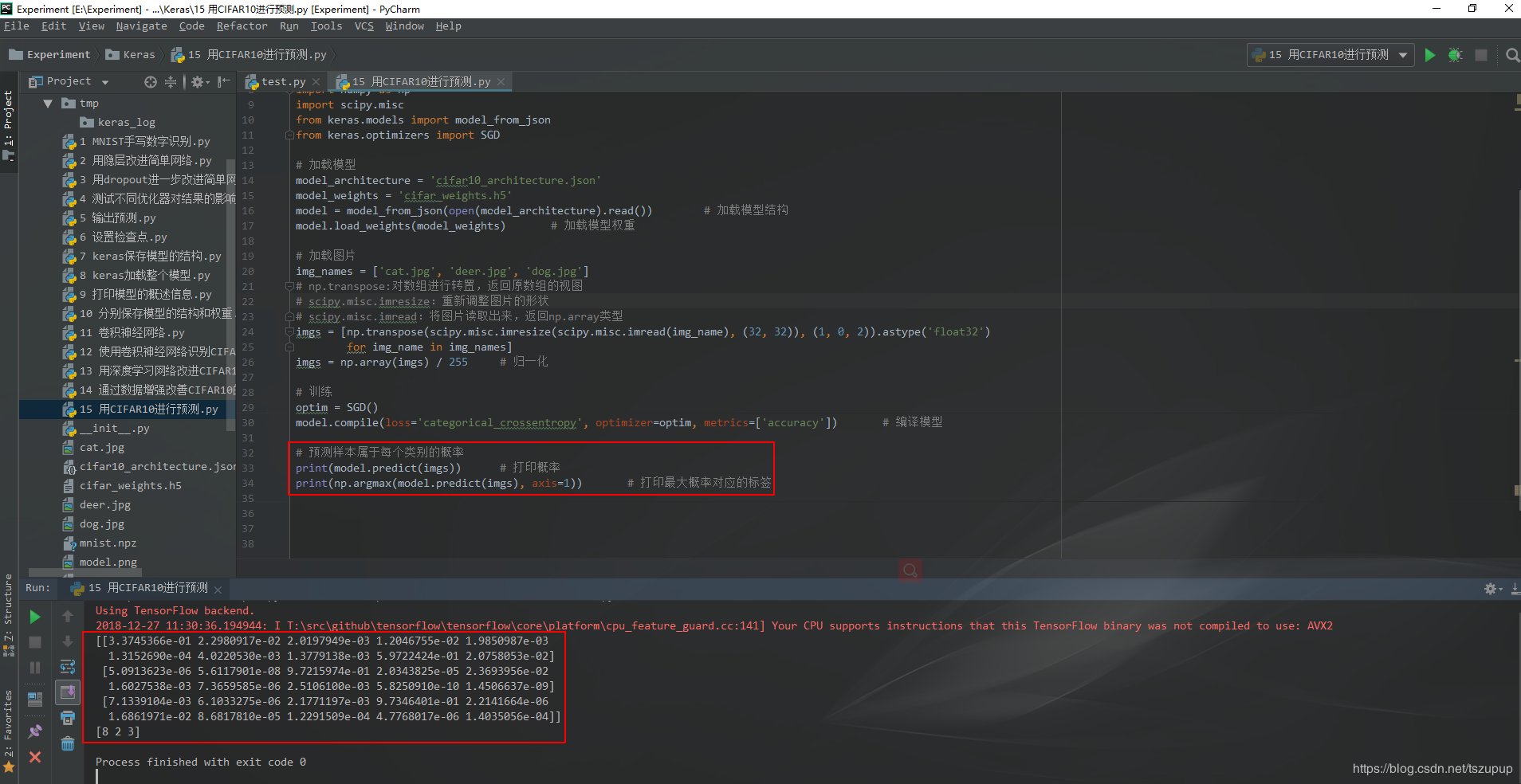
Keras中predict()方法和predict_classes()方法的区别

LAION全称Large-scale Artificial Intelligence Open Network,是一家非营利组织,成员来自世界各地,旨在向公众提供大规模机器学习模型、数据集和相关代码。他们声称自己是真正的Open AI,100%非盈利且100%Free。在九月份,他们公布了一个全新的图像-文本对(image-text pair)数据集。该数据集包含4亿条数据。
通过调整提示文本,可以使语言模型更好地理解任务的要求和上下文,从而提高其在特定任务上的表现。Prompt tuning是使大型语言模型更加智能和高效的关键步骤之一。只有通过精心设计和优化提示文本,我们才能充分发挥大型语言模型的潜力,并使其更好地服务于人类的需求。因此,Prompt engineering,这一种新的工程能力也开始变得重要。
嵌入(Embedding)是深度学习方法处理自然语言文本最重要的方式之一。它将人类的自然语言和文本转换成一个浮点型的向量。向量之间的距离代表了它们的关系。今天,OpenAI宣布了他们的Embedding新模型——text-embedding-ada-002。官方宣称这是目前OpenAI最强的嵌入模型,可以将任意文本转换成一个向量,且效果好于目前所有OpenAI的模型。
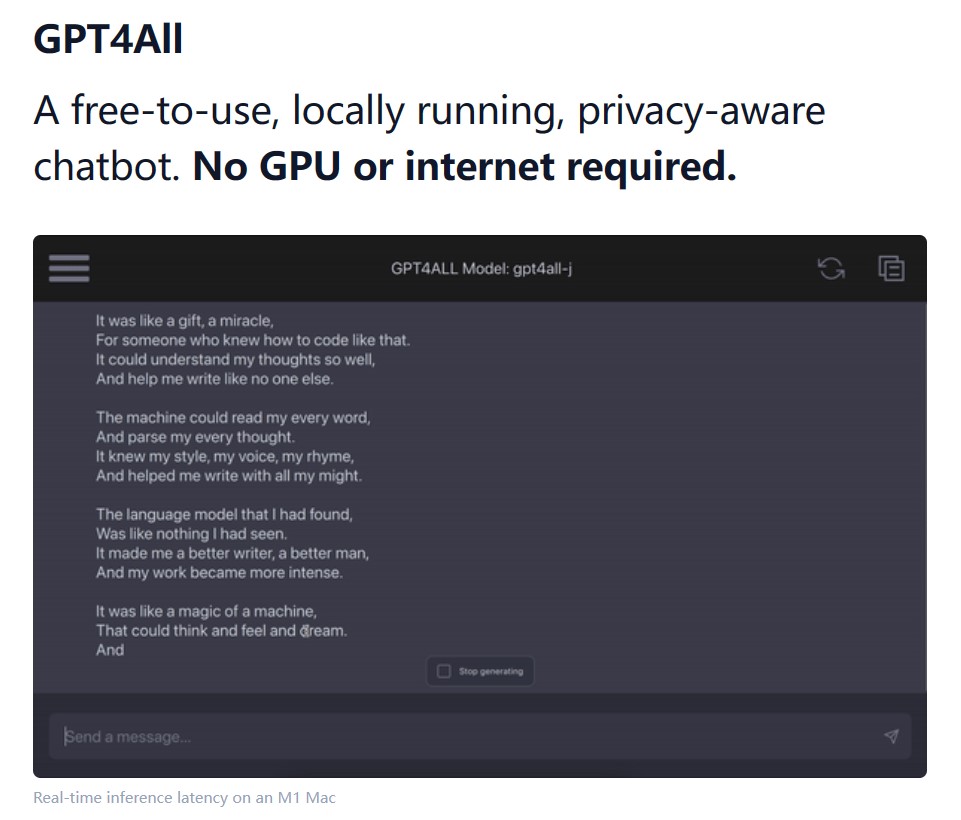
NomicAI推出了GPT4All这款软件,它是一款可以在本地运行各种开源大语言模型的软件。GPT4All将大型语言模型的强大能力带到普通用户的电脑上,无需联网,无需昂贵的硬件,只需几个简单的步骤,你就可以使用当前业界最强大的开源模型。
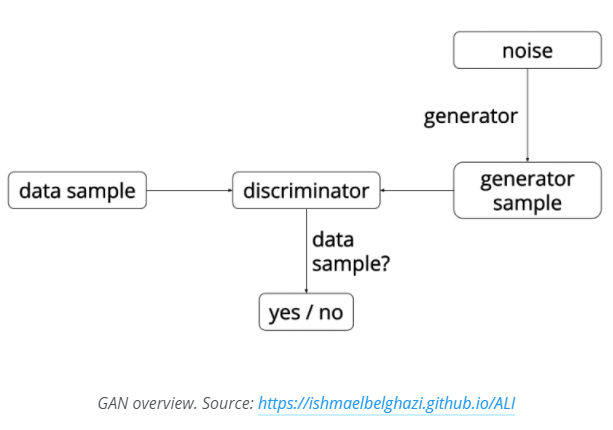
这篇博客是AYLIEN上的一篇关于生成对抗网络的简单介绍,包含非常简洁的代码示例。是入门非常好的材料。