
重磅!第二代ChatGLM发布!清华大学THUDM发布ChatGLM2-6B:更快更准,更低成本更长输入!
ChatGLM-6B是国产开源大模型领域最强大的的大语言模型。因其优秀的效果和较低的资源占用在国内引起了很多的关注。2023年6月25日,清华大学KEG和数据挖掘小组(THUDM)发布了第二代ChatGLM2-6B。
加载中...
汇总「C」相关的原创 AI 技术文章与大模型实践笔记,持续更新。
ChatGLM-6B是国产开源大模型领域最强大的的大语言模型。因其优秀的效果和较低的资源占用在国内引起了很多的关注。2023年6月25日,清华大学KEG和数据挖掘小组(THUDM)发布了第二代ChatGLM2-6B。

5月27日,OpenBMB发布了一个最高有100亿参数规模的开源大语言模型CPM-BEE,OpenBMB是清华大学NLP实验室联合智源研究院成立的一个开源组织。该模型针对高质量中文数据集做了训练优化,支持中英文。根据官方的测试结果,其英文测试水平约等于LLaMA-13B,中文评测结果优秀。

昨天,HuggingFace的大语言模型排行榜上突然出现了一个评分超过LLaMA-65B的大语言模型:Falcon-40B,引起了广泛的关注。本文将简要的介绍一下这个模型。截止2023年5月27日,Falcon-40B模型(400亿参数)在推理、理解等4项Open LLM Leaderloard任务上评价得分第一,超过了之前最强大的LLaMA-65B模型。

虽然LLM在很多任务上很好用,但是实际应用中我们常见的文本分类、文本标注等工作目前却依然缺少一个可以利用LLM能力的好方法。LLM的强大并没有在工程落地上比肩传统的机器学习处理框架。上周,一个叫Scikit-LLM新的开源项目发布,将传统优秀的Scikit-learn框架与LLM结合,带来了LLM落地的新方法。

ChatGLM-6B是清华大学知识工程和数据挖掘小组发布的一个类似ChatGPT的开源对话机器人,由于该模型是经过约1T标识符的中英文训练,且大部分都是中文,因此十分适合国内使用。本文将详细记录如何在Windows环境下基于GPU和CPU两种方式部署使用ChatGLM-6B,并说明如何规避其中的问题。

今天,THUDM开源了ChatGLM-6B的多模态升级版模型VisualGLM-6B。这是一个多模态对话语言模型,支持图像、中文和英文。VisualGLM-6B的特别之处在于它能够整合视觉和语言信息。可以用来理解图片,解析图片内容。

RWKV是一个结合了RNN与Transformer双重优点的模型架构。由香港大学物理系毕业的彭博首次提出。简单来说,RWKV是一个RNN架构的模型,但是可以像transformer一样高效训练。今天,HuggingFace官方宣布在transformers库中首次引入RNN这样的模型,足见RWKV模型的价值。

2023年3月23日OpenAI官方宣布ChatGPT即将支持Plugin模式。这是一种用插件的方式来解锁ChatGPT的能力,包括让ChatGPT可以浏览网页、从本地商店订购食材等。今天,沃顿商学院教授Ethan Mollick在推特上公布了自己收到了ChatGPT内测邀请,并使用它的代码解释器(Python Interpreter)插件让ChatGPT针对一份excel数据完成了非常专业的数据分析的工作。

HuggingFace是近几年最火热的AI社区,在短短几年时间里已经称为AI模型的GitHub。目前,HuggingFace上已经托管了18万多的模型、3万多的数据集以及4万多的模型demo(spaces)。今天,HuggingFace发布了HuggingChat,声称要做最好的开源AI Chat项目,并且对所有人开放。

尽管当前ChatGPT和GPT-4非常火热,但是高昂的训练成本和部署成本其实导致大部分个人、学术工作者以及中小企业难以去开发自己的模型。使得使用OpenAI的官方服务几乎成为了一种无可替代的选择。本文介绍的是一种低成本开发高效ChatGPT的思路,我认为它适合一些科研机构去做,也适合中小企业创新的方式。这里提到的思路涉及了一些最近发表的成果和业界的一些实践产出,大家可以参考!
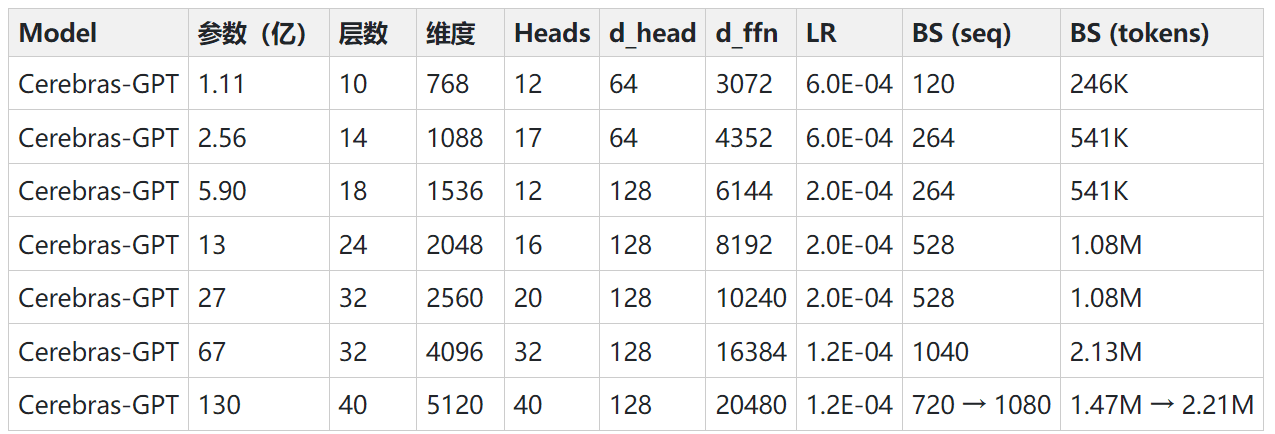
在最近的24个小时内,有2个开源的自然语言处理领域的开源预训练大模型发布。这两个模型都是类似GPT的Transformer模型,可以完成和ChatGPT类似的能力。最重要的是这2个模型完全开源!

RLHF全称Reinforcement Learning from Human Feedback,是随着ChatGPT火爆之后而被大家所关注的技术。昨天,微软开源了业界第一个RLHF的pipeline框架,可以用来训练类似ChatGPT的模型。

目前的LLM有很多限制,有很多问题并不能很好的解决,例如文本输入长度有限、无法记住很早之前的信息等。而这些问题目前也都缺少合适的解决方案。它们所依赖的技术:如任务规划、提示模板、向量化内存等需要的是编程的智慧。Semantic Kernel就是微软在这个背景下推出的一个结合LLM与传统编程技术的编程框架。

这是OpenAI官方的cookebook最新更新的一篇技术博客,里面说明了为什么我们需要使用embeddings-based的搜索技术来完成问答任务。

随着ChatGPT的火爆,Prompts概念开始被大家所熟知。早期类似如BERT模型的微调都是通过有监督学习的方式进行。但是随着模型越来越大,冻结大部分参数,根据下游任务做微调对模型的影响越来越小。大家开始发现,让下游任务适应预训练模型的训练结果有更好的性能。而ChatGPT的火爆让大家知道,虽然ChatGPT的能力很强,但是需要很好的提问方式才能让它为你所服务。

万众瞩目的GPT-4即将来临!3月9日晚上在德国举办的一个AI会议。微软德国的员工参与了讨论,在介绍微软云的AI能力的时候,微软德国CTO Andreas Braun透露了GPT-4将在下周发布。
自从2019年OpenAI开始商业化以来,OpenAI的成果越来越封闭,而商业化的进程越来越快。GPT系列的发展正好印证了这个路径。GPT最初的版本包含了论文、代码和预训练结果。GPT-2刚开始也认为可能会造成不好的伤害而在论文官宣了大半年之后才公布了完整模型。到GPT-3的时候也就给了官方介绍博客和论文,模型则是彻底闭源且开始商业化。而今天OpenAI直接官方博客宣布GPT-3.5商业化,连论文都没有了!
最近,随着ChatGPT的火爆,大语言模型(Large language model)再次被大家所关注。当年BERT横空出世的时候,基于BERT做微调风靡全球。但是,最新的大语言模型如ChatGPT都使用强化学习来做微调,而不是用之前大家所知道的有监督的学习。这是为什么呢?著名AI研究员Sebastian Raschka解释了这样一个很重要的转变。大约有5个原因促使了这一转变。
今天微软宣布,新版本的Bing将全线接入ChatGPT,试图领先谷歌一步。这篇博客将总结一下带了ChatGPT的新版本Bing将有哪些新功能!

Visual Studio Code简称VS Code,是由微软开发的跨平台免费开源的源代码编辑器。相比较Eclipse、PyCharm等软件,它很轻量,并不太像一个完整的IDE(Integrated Development Environment,集成开发环境)。但是,由于其轻量、快速、第三方扩展生态强大等原因,在2015年推出之后就迅速发展成为最受欢迎的开发环境。2019年的Stack Overflow的开发者调查中名列第一,使用占比月50.7%。
12月1日OpenAI官宣了其目前最强的AI对话系统之后,大家发现这个强大的系统能做的事情远超过大家的想象。我们也在第一时间发布了相关的博客:https://datalearner.com/blog/1051669904657253 。由于这个系统实在是太过强大,大家发现的能力越来越强。连Musk也在几个小时之前感叹这个系统是so much better at bullshit than they are!在这篇博客中,我们将收集关于这个系统目前的使用案例,给大家一个更加全面的展示结果。
2022年的PyTorch Conference在新奥尔良举办。刚刚会上的keynote官宣PyTorch2.0版本即将到来。PyTorch是目前最流行的深度学习框架之一,它的易用性被广大的用户所喜爱。关于PyTorch2.0,官方透露了一些值得期待的特性。

Batch Normalization(BN)是深度学习领域最重要的技巧之一,最早由Google的研究人员提出。这个技术可以大大提高深度学习网络的收敛速度。简单来说,BN就是将每一层网络进行归一化,就可以提高整个网络的训练速度,并打乱训练数据,提升精度。但是,BN的使用可以在很多地方,很多人最大的困惑是放在激活函数之前还是激活函数之后使用,著名机器学习领域的博主Santiago总结了这部分需要注意的内容。
Hugging Face一直在努力支持深度学习,但是,这只是深度学习的一部分。传统统计机器学习领域里面最重要的工具Scikit-learn如今终于和深度学习的开源标杆工具Hugging Face联手。