
为什么最新的大语言模型(如ChatGPT)都使用强化学习来做微调(finetuning)?
最近,随着ChatGPT的火爆,大语言模型(Large language model)再次被大家所关注。当年BERT横空出世的时候,基于BERT做微调风靡全球。但是,最新的大语言模型如ChatGPT都使用强化学习来做微调,而不是用之前大家所知道的有监督的学习。这是为什么呢?著名AI研究员Sebastian Raschka解释了这样一个很重要的转变。大约有5个原因促使了这一转变。
汇总「R」相关的原创 AI 技术文章与大模型实践笔记,持续更新。
最近,随着ChatGPT的火爆,大语言模型(Large language model)再次被大家所关注。当年BERT横空出世的时候,基于BERT做微调风靡全球。但是,最新的大语言模型如ChatGPT都使用强化学习来做微调,而不是用之前大家所知道的有监督的学习。这是为什么呢?著名AI研究员Sebastian Raschka解释了这样一个很重要的转变。大约有5个原因促使了这一转变。
OpenAI在其官方GitHub上公开了一个最新的开源Python库:tiktoken,这个库主要是用力做字节对编码的。相比较HuggingFace的tokenizer,其速度提升了好几倍。
2022年的PyTorch Conference在新奥尔良举办。刚刚会上的keynote官宣PyTorch2.0版本即将到来。PyTorch是目前最流行的深度学习框架之一,它的易用性被广大的用户所喜爱。关于PyTorch2.0,官方透露了一些值得期待的特性。
近几年语言模型的发展速度很快,各种大语言预训练模型的推出让算法在各种NLP的任务中都取得了前所未有的成绩。其中2017年谷歌发布的Attention is All You Need论文将transformer架构推向了世界,这也是现在最流行的语言模型结构。威斯康星大学麦迪逊分校的统计学教授Sebastian Raschka总结了6中Language Transformer的使用方法。值得一看。
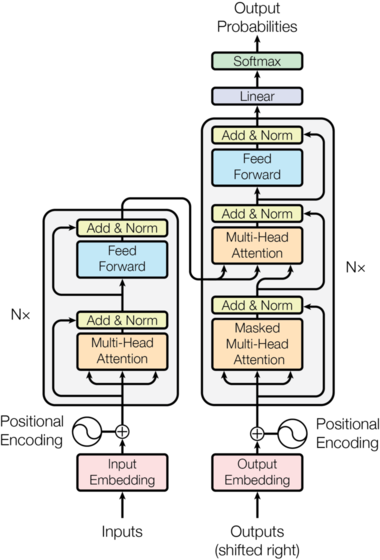
The Annotated Transfomer是哈佛大学的研究人员于2018年发布的Transformer新手入门教程。这个教程从最基础的理论开始,手把手教你按照最简单的python代码实现Transformer,一经推出就广受好评。2022年,这个入门教程有了新的版本。

Batch Normalization(BN)是深度学习领域最重要的技巧之一,最早由Google的研究人员提出。这个技术可以大大提高深度学习网络的收敛速度。简单来说,BN就是将每一层网络进行归一化,就可以提高整个网络的训练速度,并打乱训练数据,提升精度。但是,BN的使用可以在很多地方,很多人最大的困惑是放在激活函数之前还是激活函数之后使用,著名机器学习领域的博主Santiago总结了这部分需要注意的内容。
Hugging Face一直在努力支持深度学习,但是,这只是深度学习的一部分。传统统计机器学习领域里面最重要的工具Scikit-learn如今终于和深度学习的开源标杆工具Hugging Face联手。
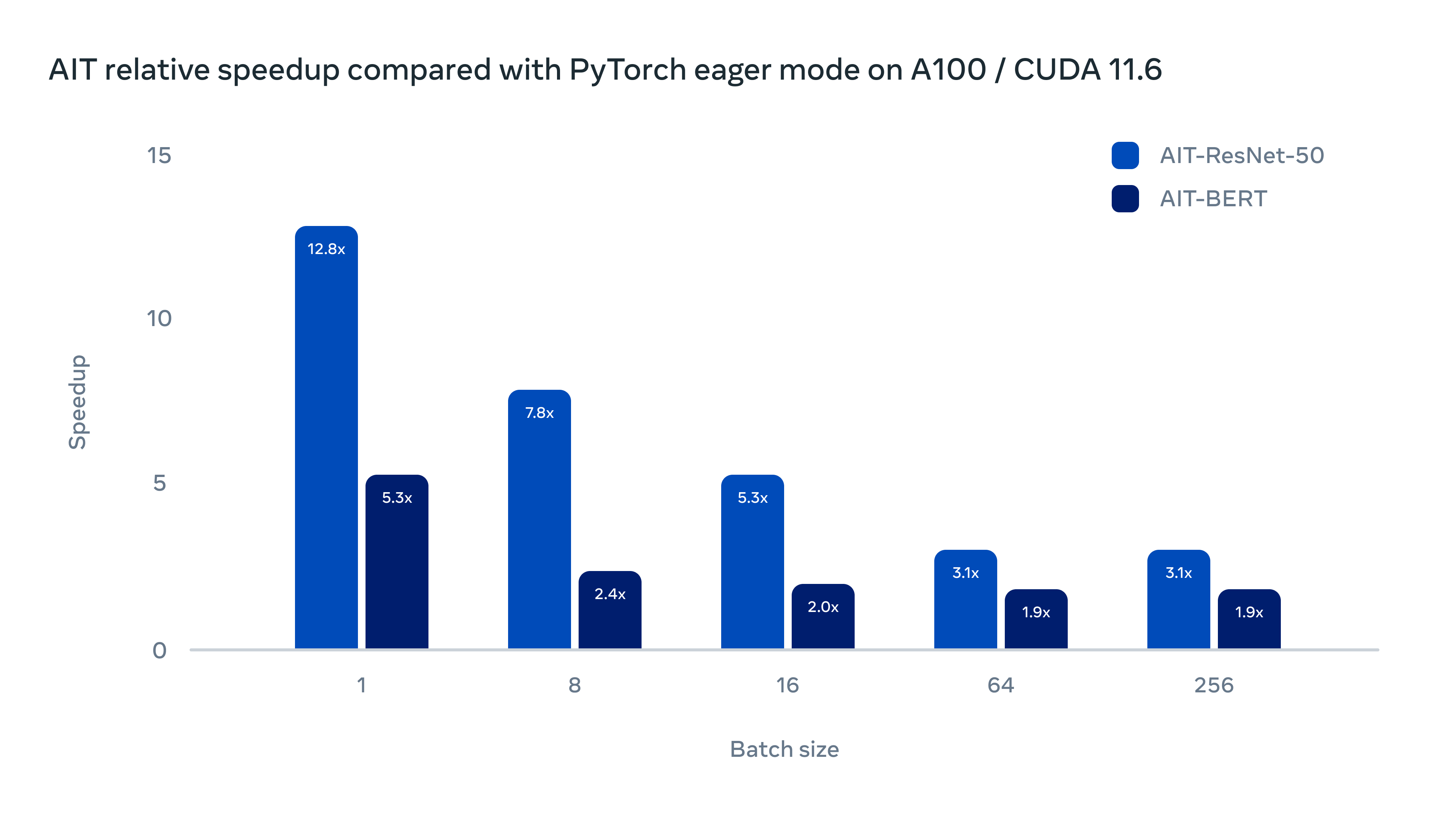
为了提高AI模型的推理速度,降低在不同GPU硬件部署的成本,Meta AI研究人员在昨天发布了一个全新的AI推理引擎AITemplate(AIT),该引擎是一个Python框架,它在各种广泛使用的人工智能模型(如卷积神经网络、变换器和扩散器)上提供接近硬件原生的Tensor Core(英伟达GPU)和Matrix Core(AMD GPU)性能。
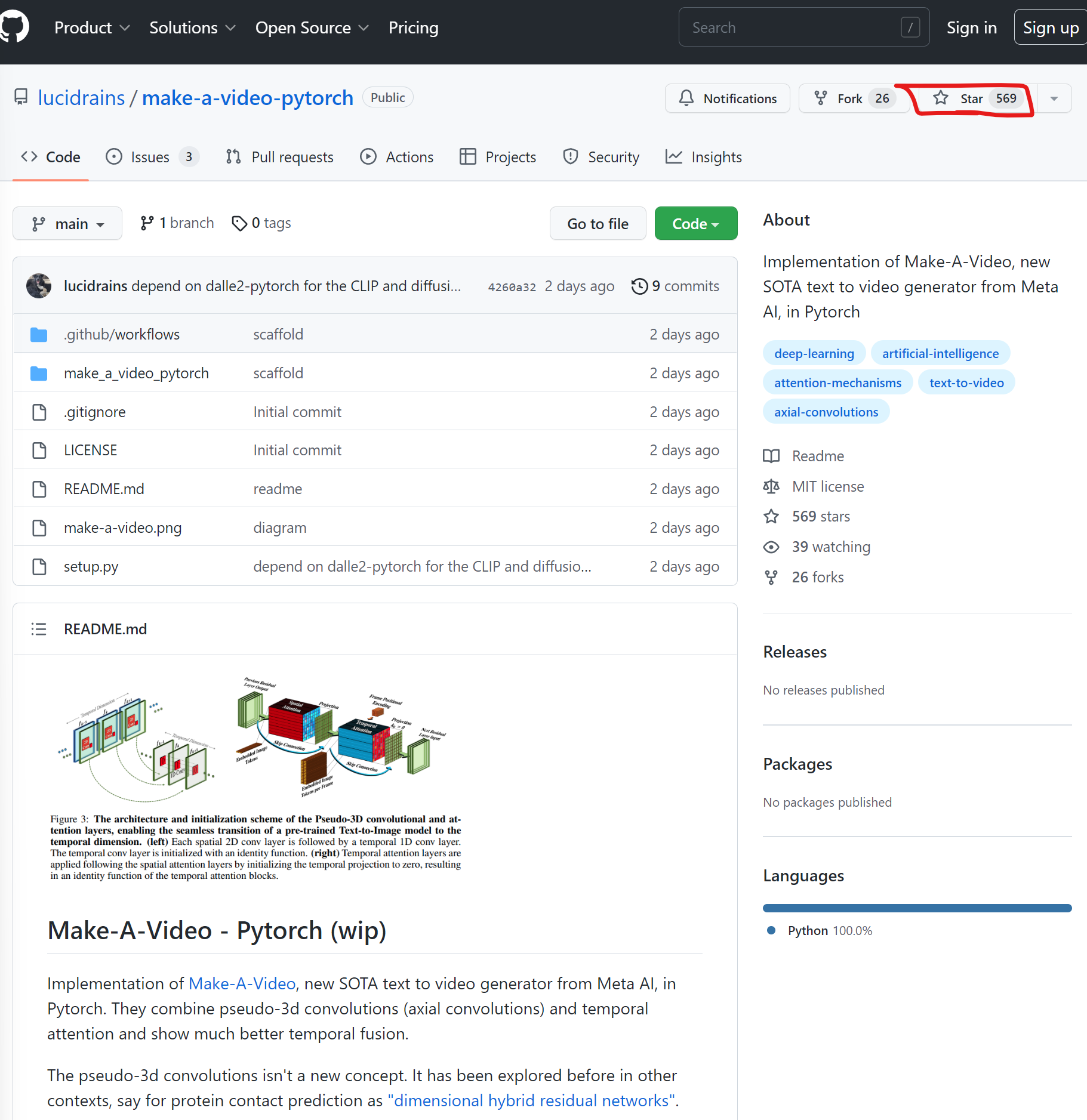
MetaAI在2天前刚发布了一个最新的Text-to-Video模型,让生成模型从逼真的图片生成往前推进到视频生成。当然,官方还是希望将其当作一种SaaS服务提供。但是,才2天,业界基于论文的开源PyTorch实现就已经准备公开,且获得了569个Star!卷到家了!

Stable Diffusion是一种功能强大的开源文本到图像(Text-to-Image)生成模型。虽然目前有多个开源项目可以实现基于文本提示(prompt)创建图像,但Stable Diffusion性能极其强大,其结果甚至可以媲美DALL·E2。而现在KerasCV提供了这个模型的官方实现!
KerasCV是由Keras官方团队发布的一个计算机视觉框架,可以帮助大家用来处理计算机视觉领域的相关任务和问题。这是2022年4月刚发布的最新产品,由于是官方团队出品的工具,所以质量有保证,且社区活跃,一直在积极更新。
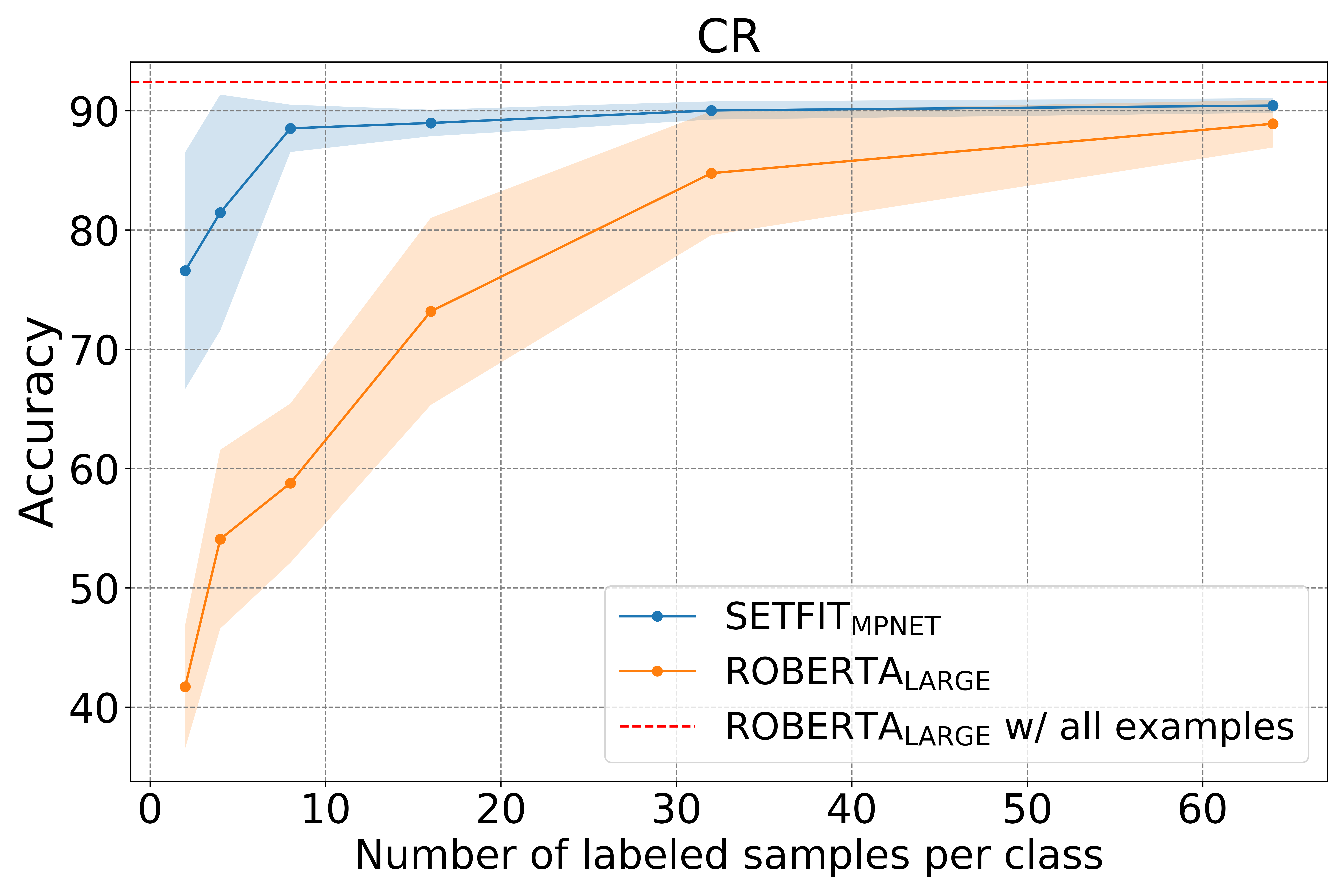
少量标记的学习(Few-shot learning)是一种在较少标注数据集中进行模型训练的一种学习方法。为了解决大量标注数据难以获取的情况,利用预训练模型,在少量标记的数据中进行微调是一种新的帮助我们进行模型训练的方法。而就在昨天,Hugging Face发布了一个新的语句transformers(Sentence Transformers)框架,可以针对少量标记数据进行模型微调以获取很好的效果。

今天Google发布了TensorStore,这是一个开源的C++和Python软件库,设计用于存储和操作大规模n维数据。TensorStore已经被用来解决科学计算中的关键工程挑战(例如,管理和处理神经科学中的大型数据集,如石油级的三维电子显微镜数据和神经元活动的 "4d "视频)。TensorStore还被用于创建大规模的机器学习模型,如PaLM,解决了分布式训练期间管理模型参数(检查点)的问题。
最近一段时间Text-to-Image模型十分火热。OpenAI的DALL·E2模型的效果十分惊艳。不过,由于Open AI现在的不Open策略,大家还无法使用这个模型,业界只开放了一个小版本的DALL·E mini。不过,前段时间,Stability AI发布的Stable Diffusion其效果明显好于现有模型,且免费开放使用,让大家都开心了一把。不过原有模型是Torch实现的,而现在,基于Tensorflow/Keras实现的Stable Diffusion已经开源。
昨天,Meta的Zuckerberg宣布,将PyTorch由Meta AI移交给Linux Foundation托管。这意味着PyTorch从今天起从Meta独立,并作为Linux Foundation下的一个项目。
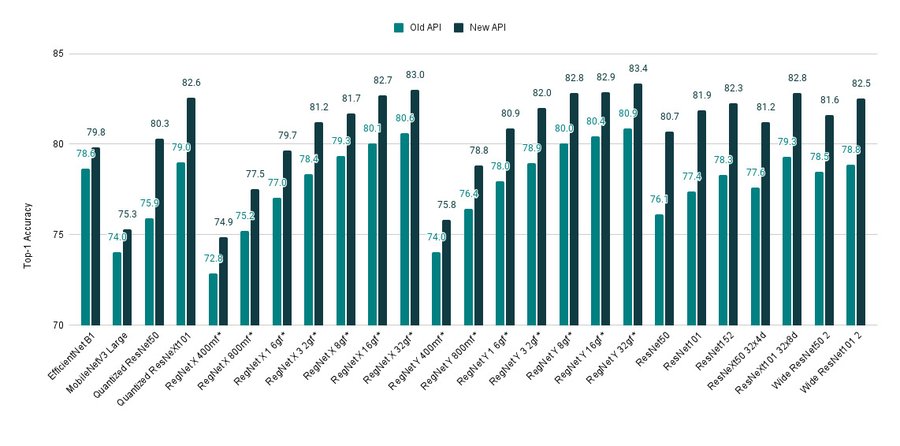
PyTorch最新的1.12版本已经在前天发布。而其中TorchVision是基于PyTorch框架开发的面向CV解决方案的一个PyThon库,其最主要的特点是包含了很多流行的数据集、模型架构以及预训练模型等。本次也随着PyTorch1.12的发布更新到了v0.13。此次发布包含几个非常好的提升,值得大家关注。

自从苹果发布M1系列的自研芯片开始,基于ARM架构的电脑处理器开始大放异彩。而强大的M1芯片的能力也让很多Mac用户高兴很久。而就在现在,M1也开始支持PyTorch的深度学习框架了。PyTorch官网刚刚宣布,经过和Apple的Metal工程师队伍的合作,PyTorch支持Mac的GPU加速了。
Jupyter Notebook虽然在教学等领域有着非常大的优势,但是实际编程中,它的效率、可维护性等方面与python脚本相比的差距到底在哪也一直不那么清晰。就在上个月底,JetBrains的研究人员使用了大量的数据详细对比了二者的差异。这里总结一下其主要结论。
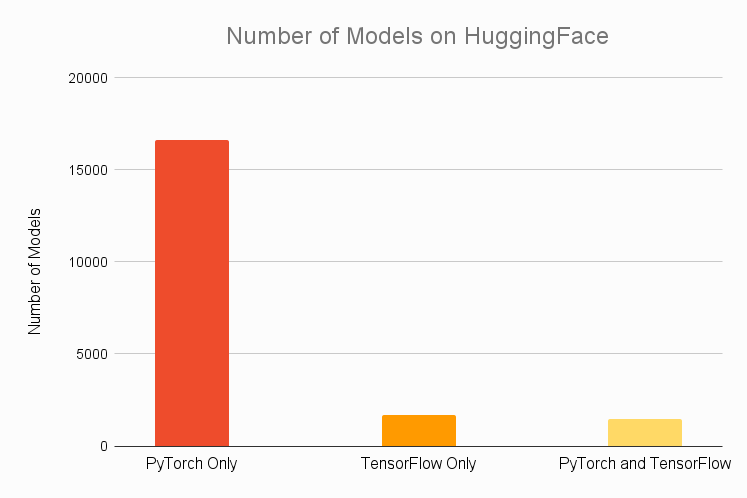
Tensorflow和PyTorch是深度学习最流行的两个框架,二者都有坚定的支持者。一般认为由于Google的支持,TensorFlow的社区支持比较好,在工业应用广泛。但是尽管有keras加持,但易用性方面依然被认为不如PyTorch。而后者最早由Facebook人工智能团队开发。由于其易用性,被认为在科学研究中有广泛使用。那么,最近几年二者发展如何,是否实际还如之前的观点一样,这里AssemblyAI的一个作者做了一些对比。

MLPerf™是MLCommons发布的一个用来测试AI相关软硬件性能的基准测试工具。2021年12月1日, Training v1.1的结果发布,这个结果不仅展示了最新的AI相关软硬件的进展,也有一个新的现象,就是AI训练正在超越摩尔定律。本文将简要解读一下相关数据。
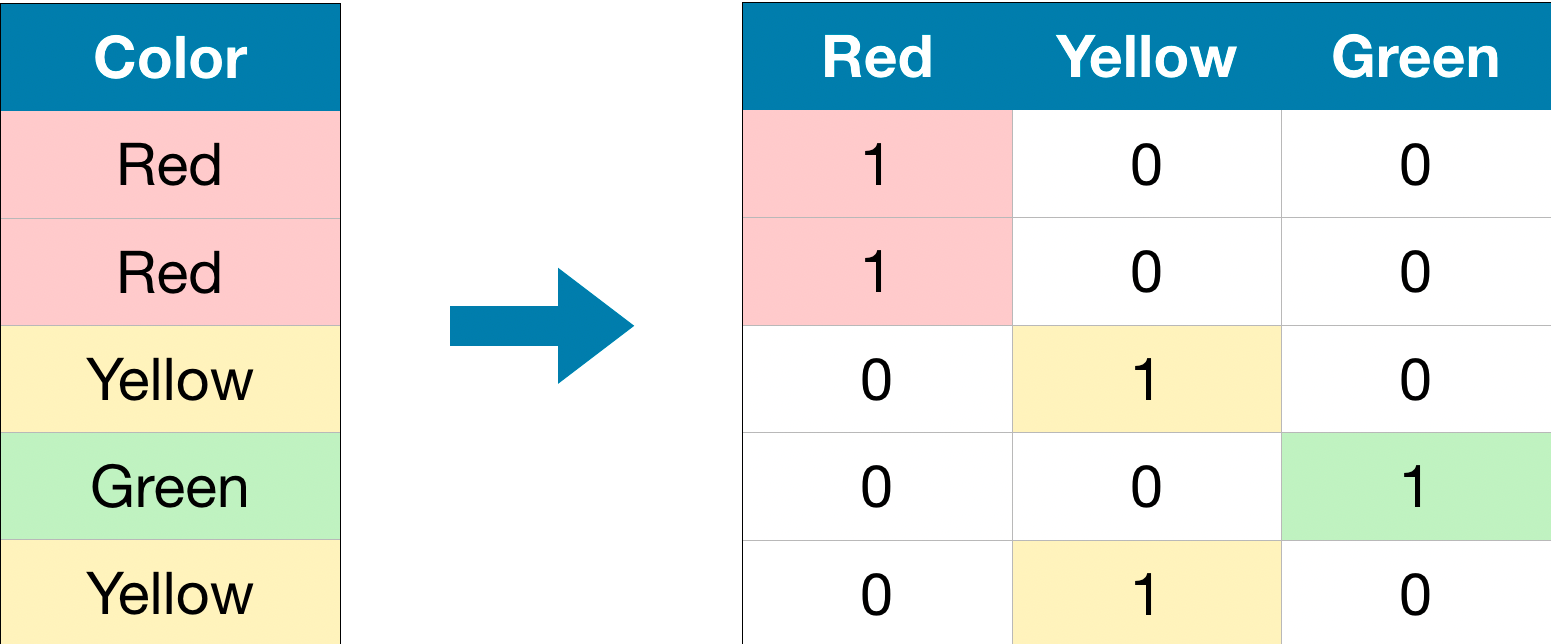
对于分类特征的处理,sklearn中常见的方法有两种,一种是OneHotEncoder,另一种很多人说是LabelEncoder,其实不对。sklearn中,还有一个OrdinalEncoder,二者似乎一样,但其实并不相同,差别很大。本文将用Kaggle的房价预测的实例来描述如何这些差异以及不同处理对预测算法的影响。

Batch Normalization(BN)是一种深度学习的layer(层)。它可以帮助神经网络模型加速训练,并同时使得模型变得更加稳定。尽管BN的效果很好,但是它的原理却依然没有十分清晰。本文总结一些相关的讨论,来帮助我们理解BN背后的原理。

Python最新正式版本3.10在10月4日已经发布。这个版本从2020年5月开始开发,经历差不多一年半的时间终于正式发布。当然每一个新版本都有很多新功能。我们将持续关注新功能,在这篇文章中,我们将简述3.10中新功能中的语法——结构模式匹配(structural pattern matching)。
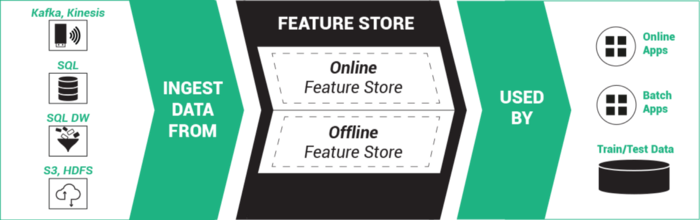
在2020年的亚马逊reInvent发布会上,亚马逊正式发布了一项新的服务,即Amazon SageMaker Feature Store,中文简介是适用于机器学习特征的完全托管的存储库。 Feature Store是这两年兴起的另一个关于人工智能系统的基础设施,应该也是未来几年最重要的人工智能基础设施之一。本文将介绍一下Feature Store是什么以及为什么很多企业开始推广这个东西。