
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



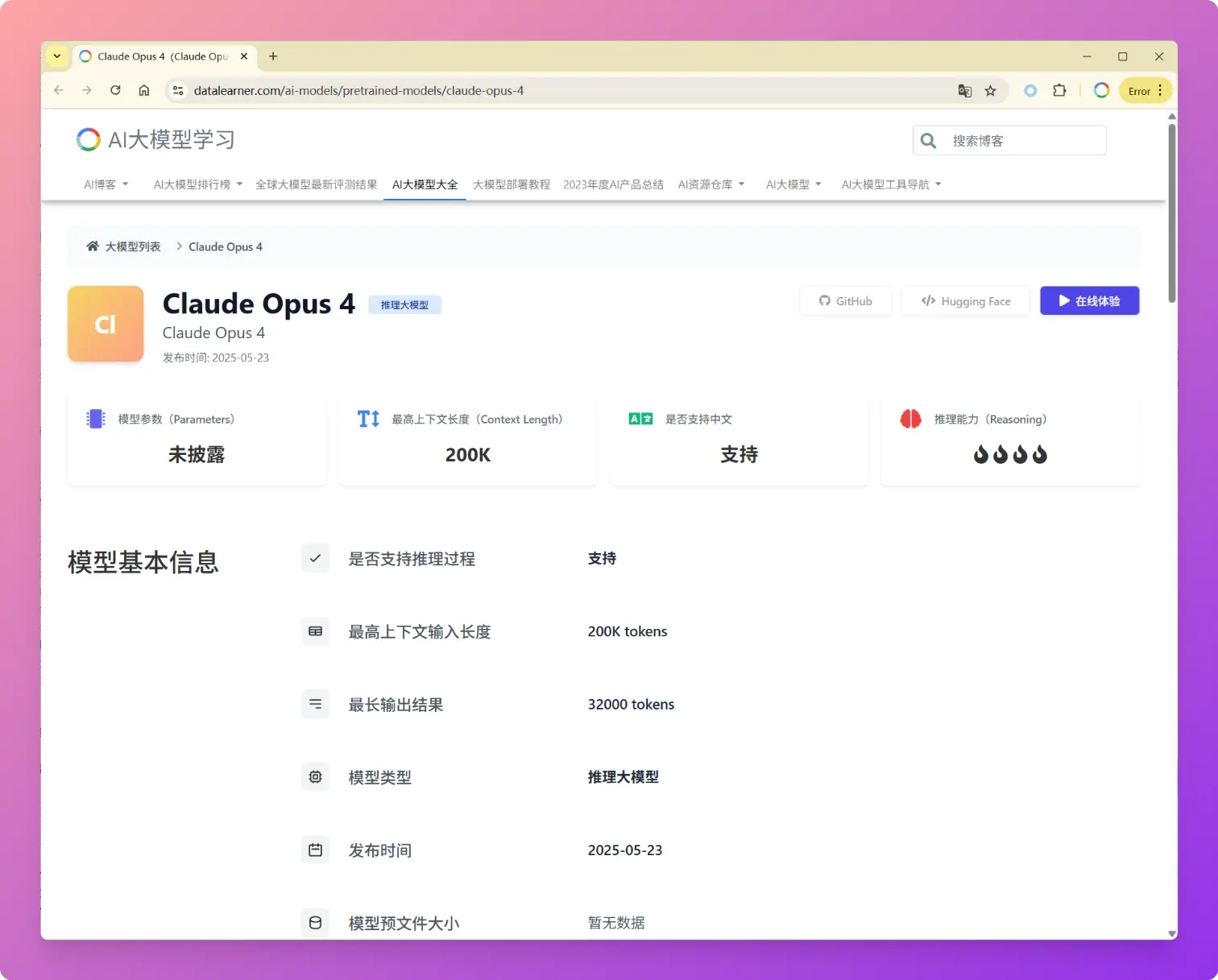
2025年5月23日,Anthropic发布了新一代大语言模型Claude 4系列,包括Claude Opus 4和Claude Sonnet 4两个版本。Anthropic的官方博客强调Claude Opus 4是当前全球最强的编程大模型,与传统聚焦于文本生成和知识问答的模型不同,Claude 4明确定位为任务执行引擎和AI Agent系统的核心组件。这次发布不仅仅是性能参数的提升,更代表了Anthropic认为AI模型从"对话助手"向"自主工作伙伴"的根本性转变。
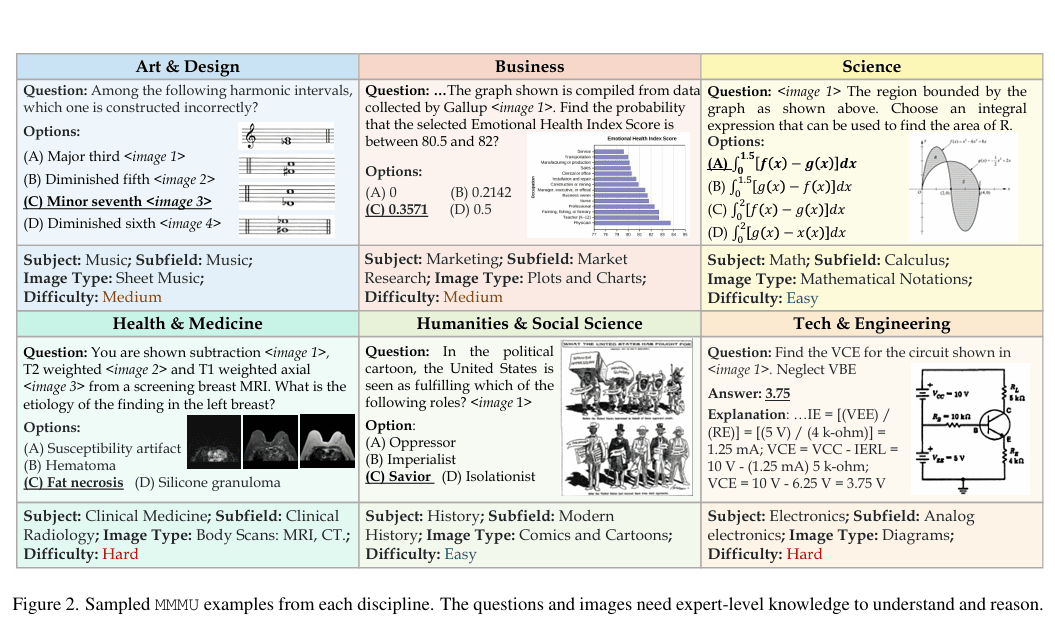
大规模多学科多模态理解与推理基准(MMMU)于2023年11月推出,是一种用于评估多模态模型的复杂工具。该基准测试人工智能系统在需要大学水平学科知识和深思熟虑推理的任务上的能力。与之前的基准不同,MMMU强调跨多个领域的先进感知和推理,旨在衡量朝专家级人工智能通用智能(AGI)的进展。

微软发布了全新的Phi-4推理模型系列,是小型语言模型(SLM)在复杂推理能力上的一种新的尝试。本次发布包含三个不同规模和性能的推理模型,分别是Phi-4-reasoning(140亿参数)、Phi-4-reasoning-plus(增强版140亿参数)和Phi-4-Mini-Reasoning(38亿参数)。这三款模型尽管参数规模远小于当前主流大型语言模型,却在多项推理基准测试中展现出与甚至超越大型模型的能力。
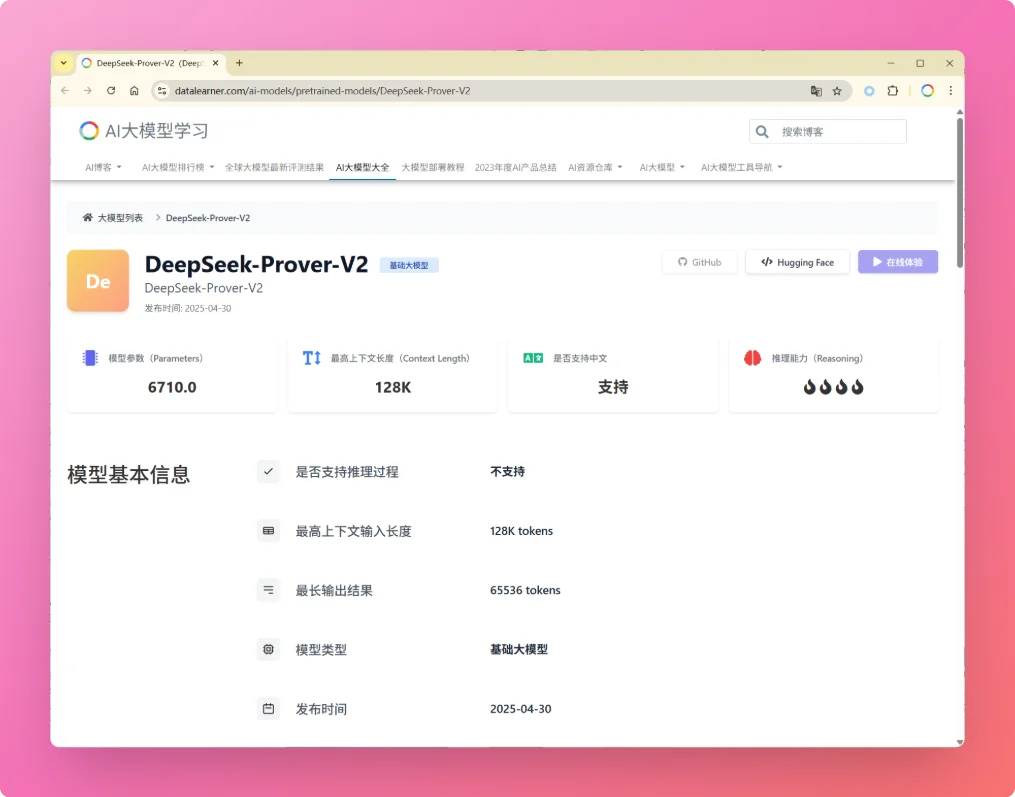
就在刚才,DeepSeek-AI发布了其新一代自动定理证明模型 **DeepSeek-Prover-V2**。尽管官方暂未公开详细报告,但从其前代模型 **DeepSeek-Prover-V1.5** 的技术细节,以及去年底发布的通用推理模型 DeepSeek-R1 的进展来看,V2 很可能在多个关键能力上取得了实质性提升。
随着大语言模型(LLM)的发展越来越快,我们需要更好的方法来评估它们到底有多“聪明”,特别是在处理复杂数学问题的时候。AIME 2025 就是这样一个工具,它专门用来测试当前 AI 在高等数学推理方面的真实水平。
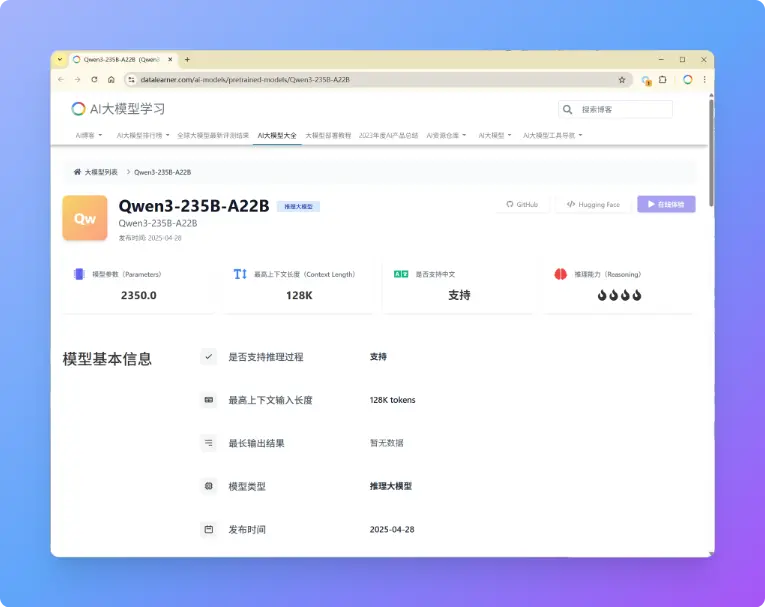
阿里巴巴刚刚开源了第三代千问大模型,Qwen3系列包含了8个不同参数规模的大模型,最大达到2350亿参数规模,最小仅6亿参数规模。本次发布的Qwen3系列是推理大模型和常规的大模型混合版本,即Qwen3可以根据输入问题的情况自动选择是否进行推理。
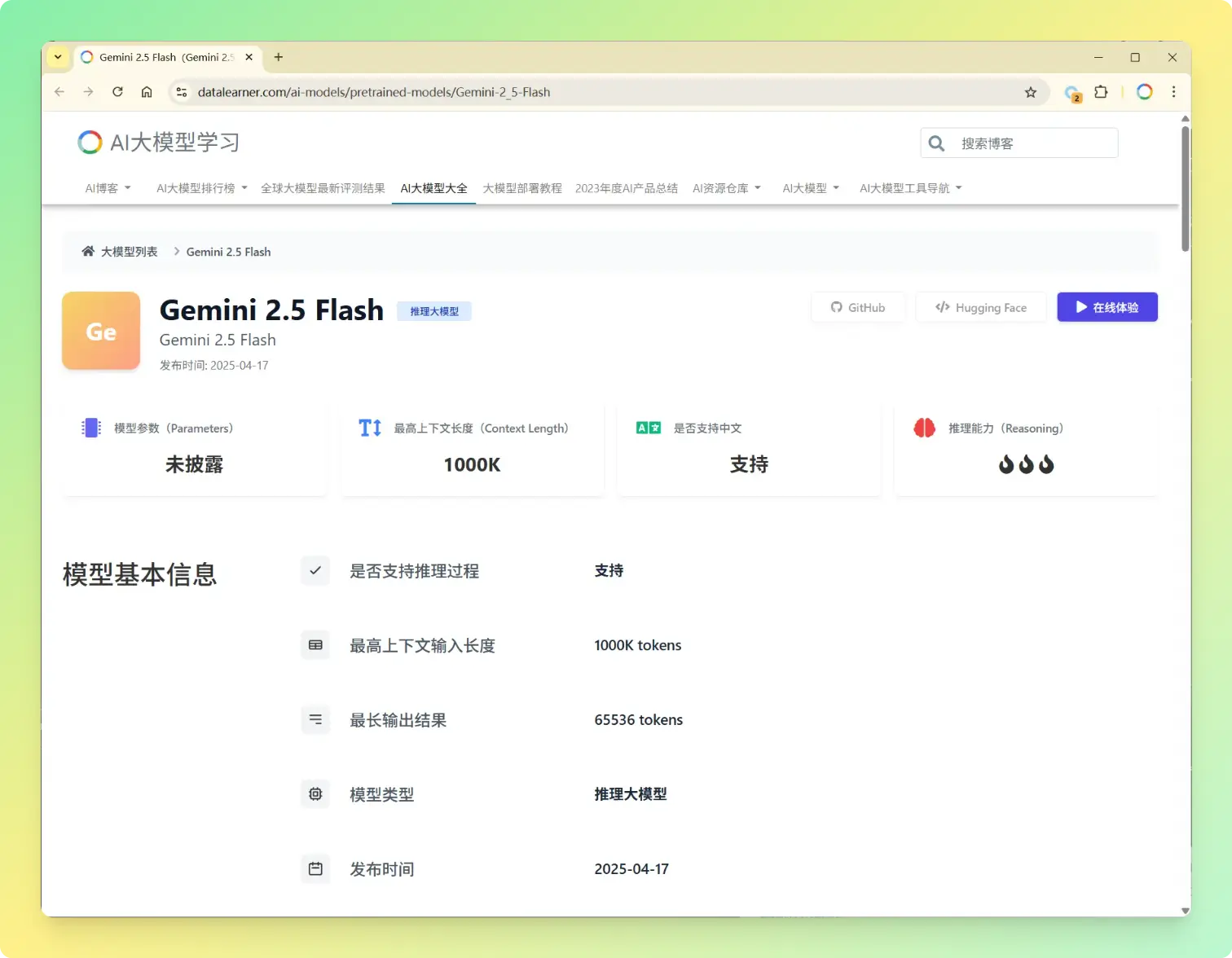
Gemini系列是Google的大模型品牌,2025年3月25日,Google发布了Gemini 2.5 Pro版本,这是谷歌发布的Gemini 2.5系列的第一个模型,参数规模较大,但是在多项评测结果上获得了全球最优的效果,Gemini 2.5 Pro成本比较高,时延也比较大,20天之后,谷歌又发布了Gemini 2.5 Flash模型,是性能、成本和效果的最佳均衡模型。
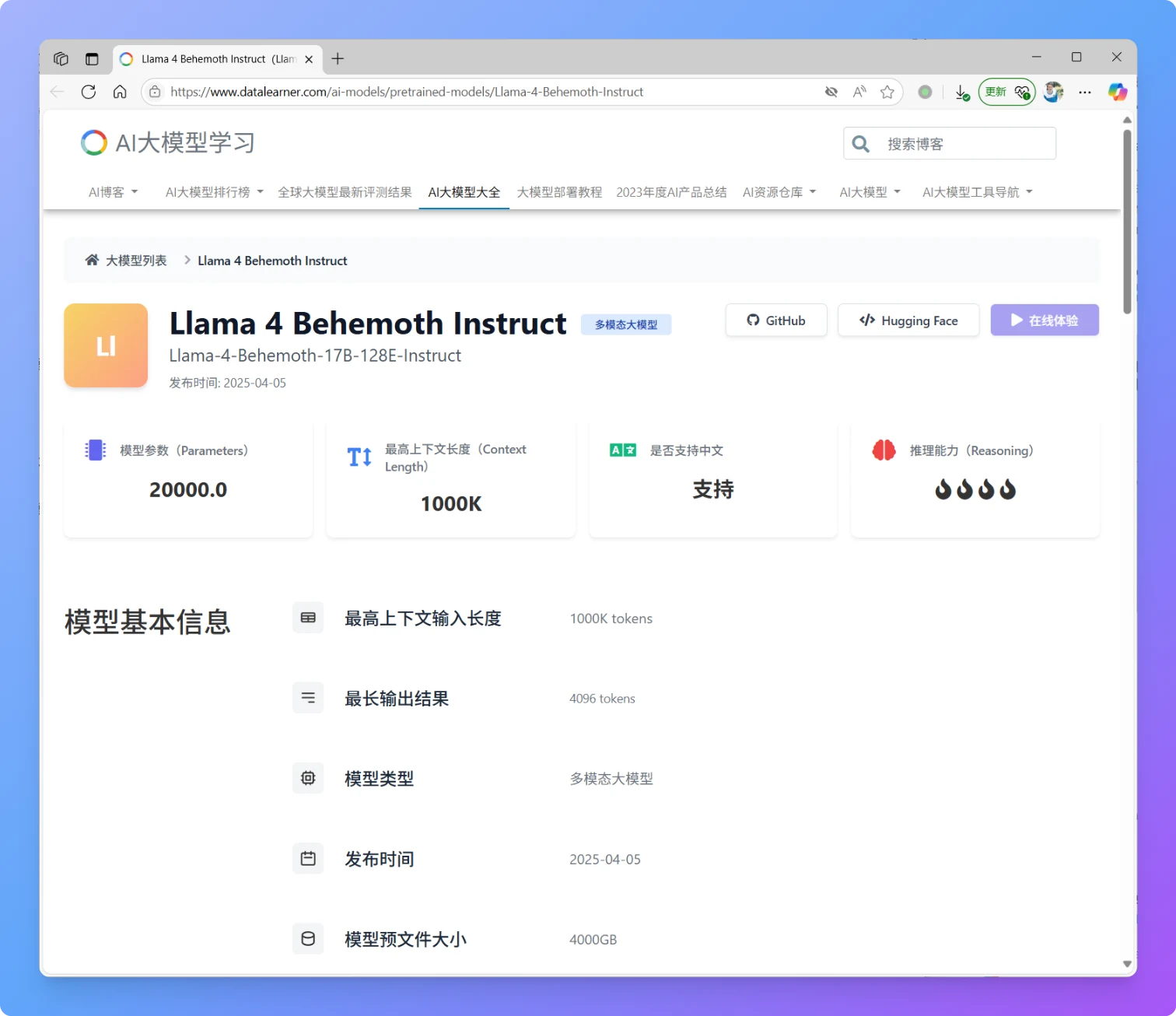
就在刚刚,MetaAI发布了全新一代Llama4大模型,Llama正式进入多模态和MoE架构时代。本次新发布的是Llama4中的2个模型分别是Llama4 Scout和Llama4 Maverick。这两个模型都是170亿激活参数,但是前者共16个专家,后者有128个专家,因此总的参数量分别达到了1090亿和4000亿!不过根据评测的情况看,即使是4000亿规模170亿激活的模型,也和DeepSeek V3.1(即DeepSeek V3 0324)版本差不多。
最近,Anthropic研究人员通过观察大模型内部运作机制发现了大模型内部可能存在一种与特定语言无关的内部共享区域,它可以把不同语种的输入,在同样的区域进行内部推理,并最终根据语种输出答案。这个现象让我们发现大模型本身理解语言的时候可能与人类类似,拥有高度抽象的内部表示,能够跨越多种语言统一相同的概念。
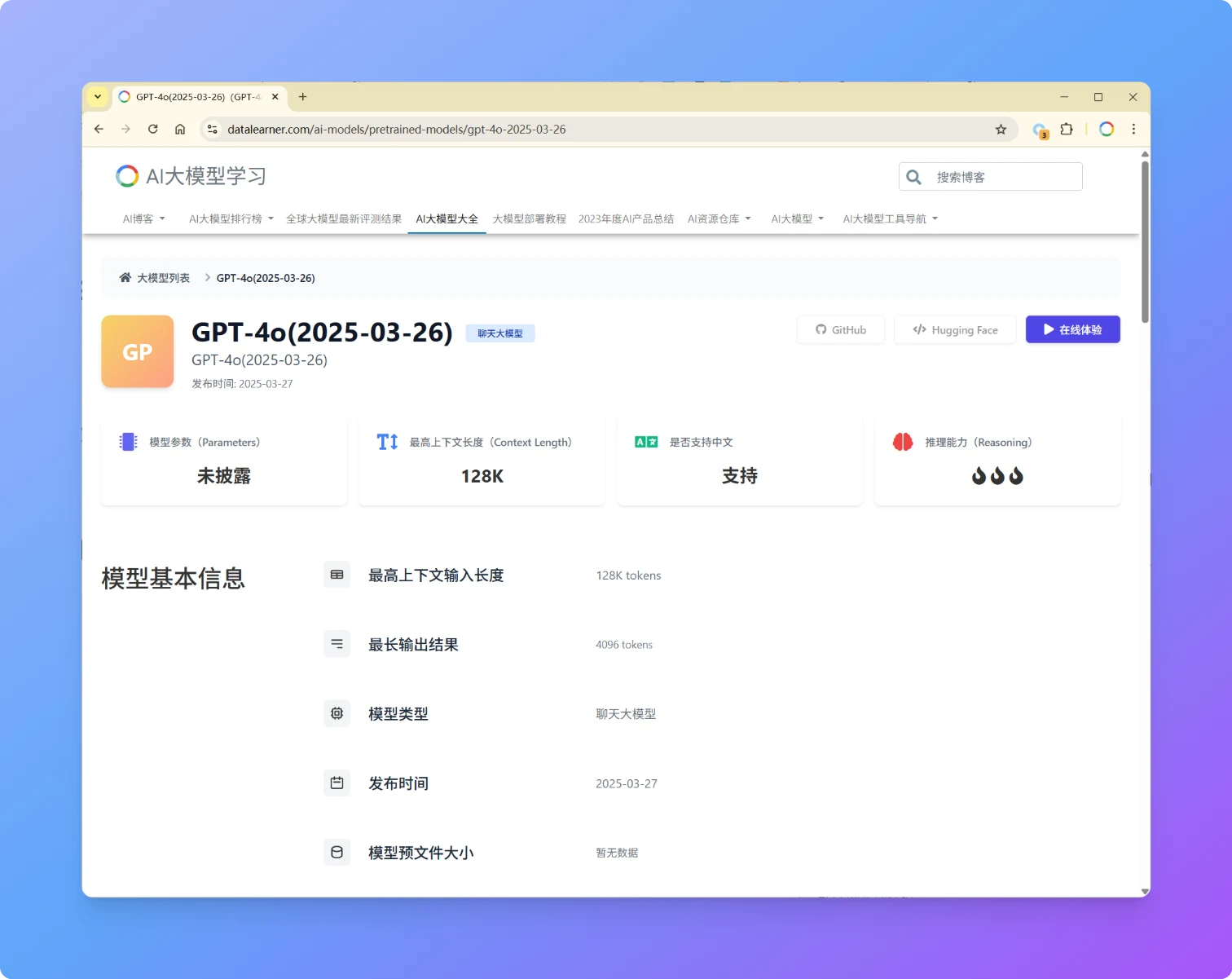
OpenAI再次发布GPT-4o更新版本,版本号为GPT-4o(2025-03-26),本次发布的GPT-4o模型在性能、易用性和协作能力上迎来多项优化,进一步提升了模型的直觉性、创造力和任务执行能力。此次更新聚焦于 STEM 与编程问题解决、指令遵循精度以及自然交互体验,各方面评测进步明显,超过了GPT-4.5。
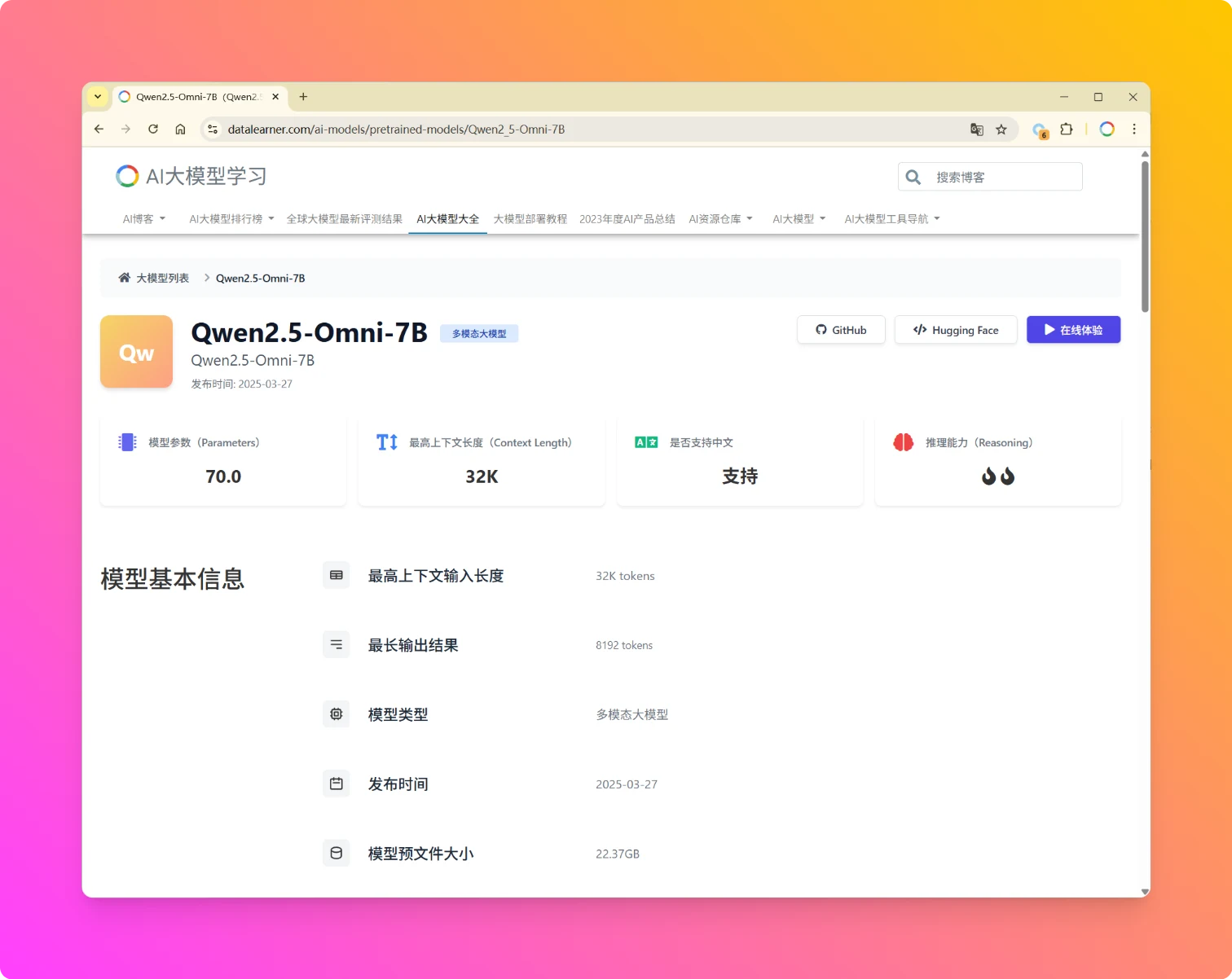
Qwen2.5-Omni-7B是阿里巴巴发布的一款端到端全模态大模型,支持文本、图像、音频、视频(无音频轨)的多模态输入与实时生成能力,可同步输出文本与自然语音的流式响应。目前,该模型在HuggingFace以Apache2.0协议开源,可以免费商用授权。
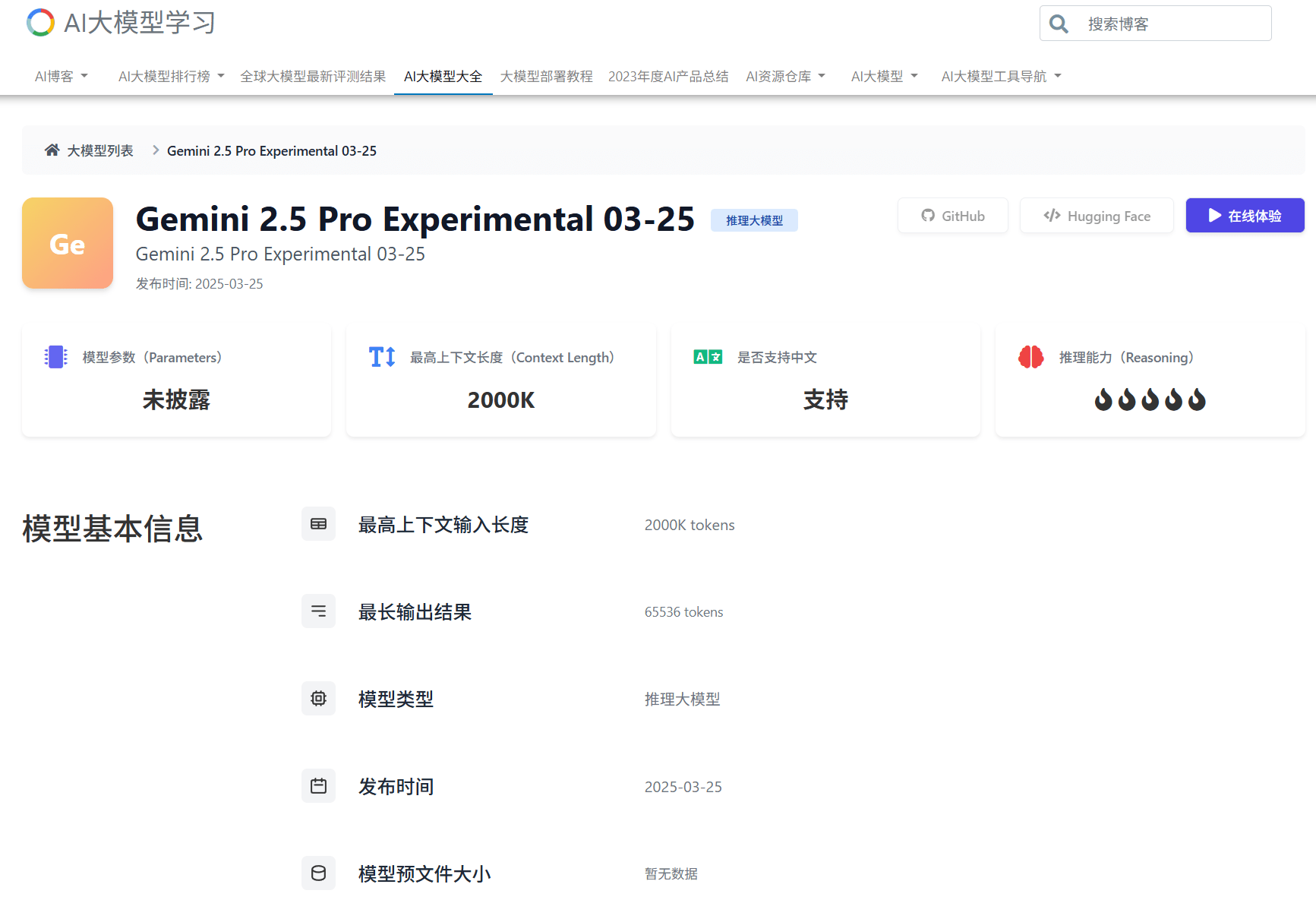
Gemini 2.5 Pro是Google发布的一个新一代大模型,Gemini 2.5 Pro是一个推理大模型,在数学和编程方面有了非常强大的能力,该模型最高支持200万tokens的上下文输入,非常强大!
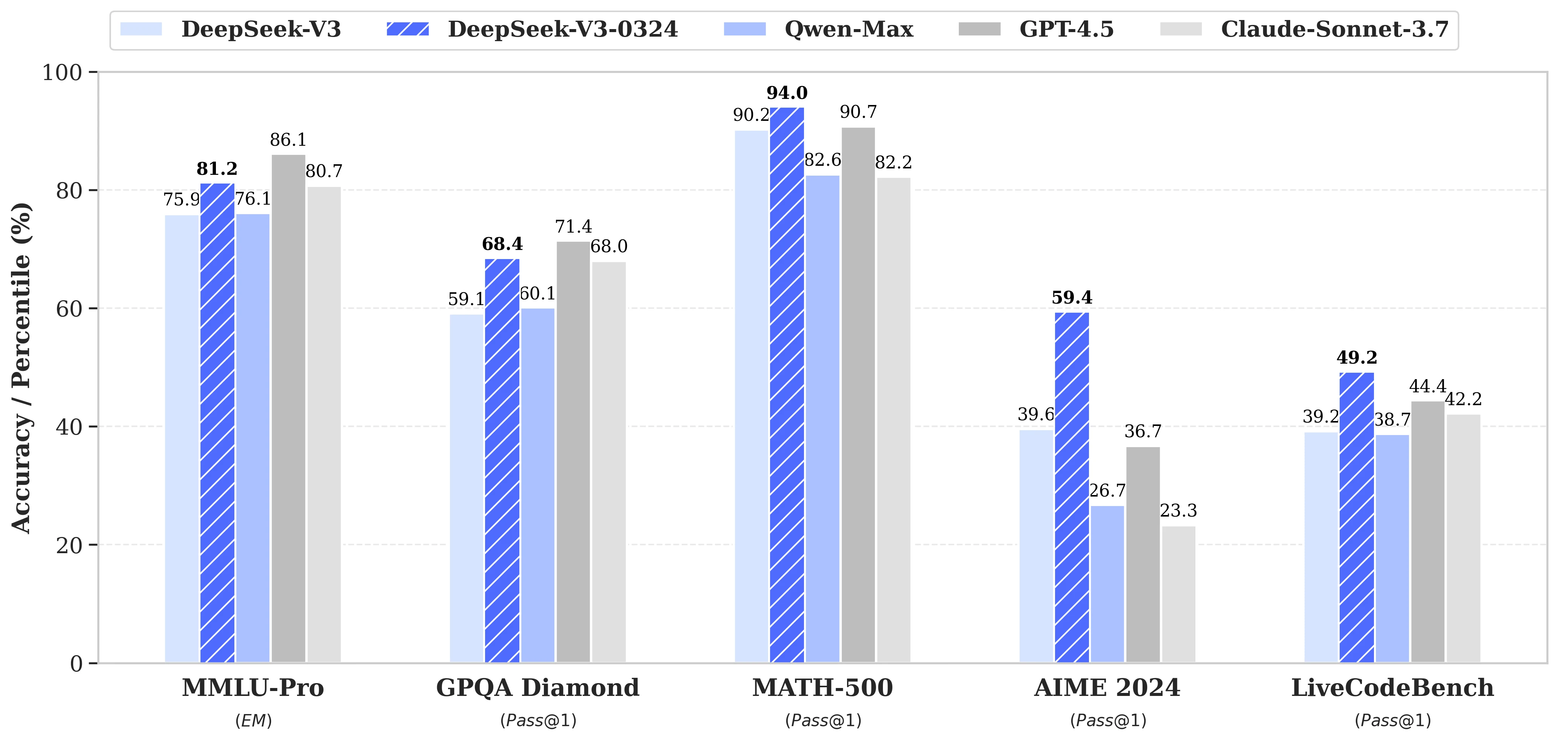
2025年3月25日,DeepSeekAI低调开源了DeepSeek-V3-0324大模型。作为DeepSeek-V3的重要升级版本,该模型在推理能力、中文写作、前端开发以及功能调用等多个关键领域实现了显著提升。在MMLU Pro等评测上,已经成为了非推理大模型中最强的模型,部分评测结果超过GPT-4.5模型。
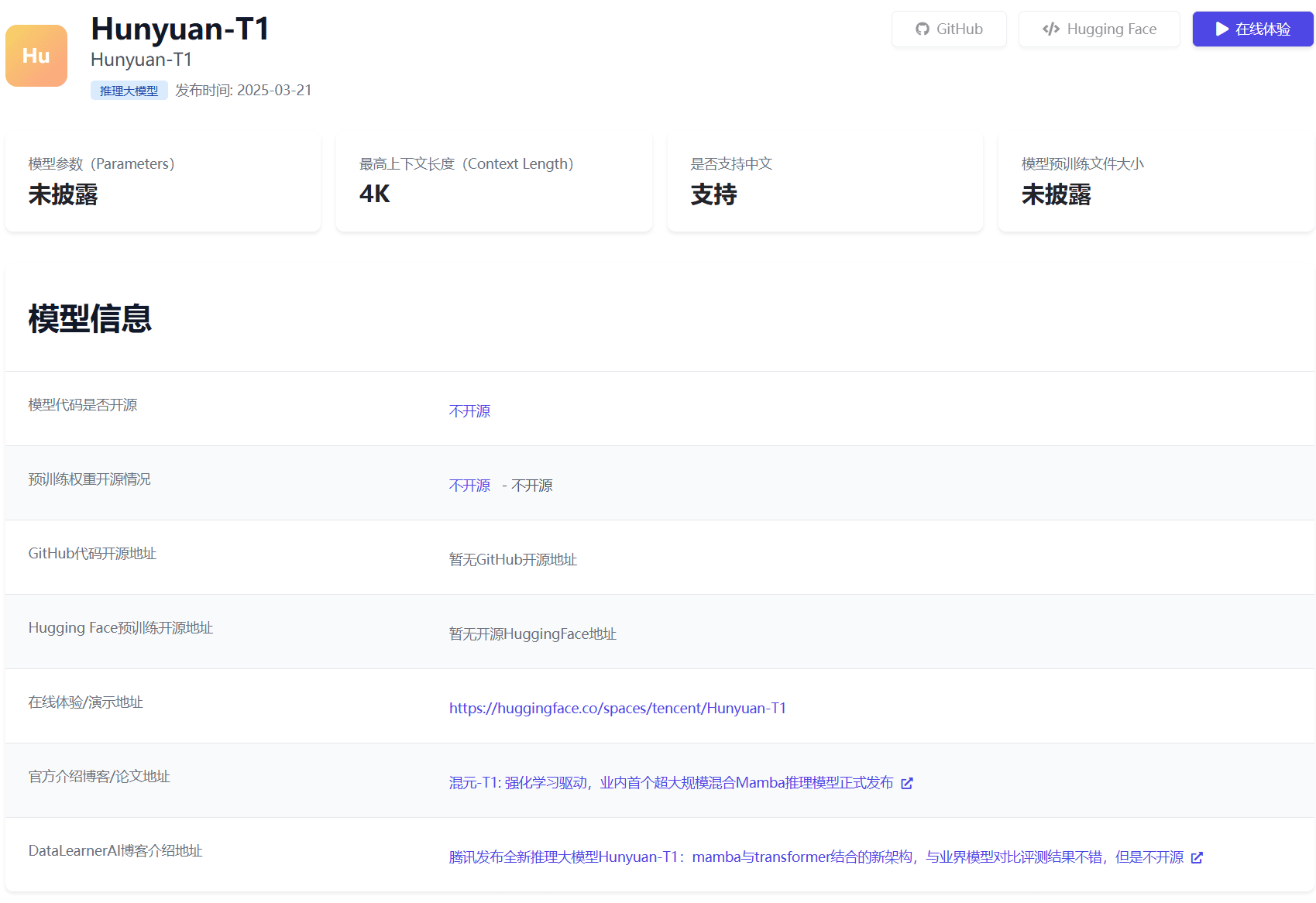
2025年3月21日,腾讯正式推出其全新大模型**Hunyuan-T1**,该模型基于此前发布的TurboS快速思维基座,首次采用**Hybrid-Transformer-Mamba混合专家架构(MoE)**,在推理效率、长文本处理及资源消耗优化等方面表现还不错。此外,这个新架构也使得Hunyuan-T1速度非常快,模型支持首字符1秒内响应,生成速度达60-80 token/秒,适用于实时交互场景。
2025年3月20日,OpenAI 推出了三款新模型——gpt-4o-transcribe、gpt-4o-mini-transcribe 和 gpt-4o-mini-tts——标志着自动语音识别 (ASR) 和文本转语音 (TTS) 领域的重要进步。这些模型基于 GPT-4o 架构,旨在为开发人员和用户提高准确性、自定义能力和可访问性,与 OpenAI 对于代理式 AI 系统的更广泛愿景一致。本文提供了对每个模型、其能力、定价、可用性和竞争环境的详细审查,确保技术和非技术受众都能全面理解。
今日推荐
疑似GPT-4.5的定价截图泄露,但真假未知,不过GPT-4微调的功能已经推出,只能说非常贵!
HuggingFace宣布在transformers库中引入首个RNN模型:RWKV,一个结合了RNN与Transformer双重优点的模型
MistralAI正式官宣开源全球最大的混合专家大模型Mixtral 8x22B,官方模型上架HuggingFace,包含指令微调后的版本!
来自OpenAI的官方解释:ChatGPT中的GPTs与Assistants API的区别是什么?有什么差异?
好消息!吴恩达再发大模型精品课程:Generative AI with Large Language Models,一个面向中级人员的生成式AI课程
LM-SYS开源包含人类偏好的3.3万条真实对话语料:可用于RLHF的训练过程!
除了Mistral-7B-MoE外,MistralAI还有更强大的模型,未宣布的Mistral-medium比混合专家模型更强!
20条关于DeepSeek的FAQ解释DeepSeek发布了什么样的模型?为什么大家如此关注这些发布的模型?他们真的绕过CUDA限制,打破了Nvidia的护城河了吗?
腾讯发布了一个全新的大模型Hunyuan Turbo S:号称评测效果超过GTP-4o和DeepSeek V3等模型,但没有开源或者放开使用