Ai2发布全新评测基准SciArena:为科学文献任务而生的大模型评测新基准,o3大幅领先所有大模型
Ai2近日发布的全新评测平台——SciArena,为这一痛点带来了创新解法。此次产品不仅继承了“人类众包对比评测”的理念,更结合科学问题的独特复杂性,构建了开放、透明且可迭代的模型评测生态。
聚焦人工智能、大模型与深度学习的精选内容,涵盖技术解析、行业洞察和实践经验,帮助你快速掌握值得关注的AI资讯。
Ai2近日发布的全新评测平台——SciArena,为这一痛点带来了创新解法。此次产品不仅继承了“人类众包对比评测”的理念,更结合科学问题的独特复杂性,构建了开放、透明且可迭代的模型评测生态。
EmbeddingGemma 是基于 Gemma 3 架构打造的全新开源多语言向量模型,专为移动端/本地离线应用而生。它以约 308M 参数的紧凑体量,在 RAG、语义搜索、分类、聚类等任务上提供高质量表征,同时将隐私与可用性拉满:无需联网即可在本地生成向量。

就在刚才,谷歌推出了 Nano Banana Pro(Gemini 3 Pro Image)。这是基于 Gemini 3 Pro 打造的专业级图像生成与编辑模型,相比几个月前的 Nano Banana,这次升级几乎重构了谷歌图像生成能力的上限。从文本渲染、多图一致性,到世界知识、摄影级控制和信息可视化,Nano Banana Pro 在多个维度显著拉开了与上一代、乃至整个行业同类产品的差距。

随着大型语言模型(LLM)的飞速发展,如何准确、全面地评估它们的能力成为了一个日益重要的课题。在众多评测基准中,Simple Bench 以其独特的定位脱颖而出,它专注于检验模型在日常人类推理方面的能力,而在这些方面,当前最先进的模型往往还不如普通人。本文将详细介绍 Simple Bench 评测基准,探讨其出现的背景、设计理念、评测流程以及当前主流模型的表现。
MiniMax M2发布2周后已经成为OpenRouter上模型tokens使用最多的模型之一。已经成为另一个DeepSeek现象的大模型了。然而,实际使用中,很多人反馈说模型效果并不好。而此时,官方也下场了,说当前大家使用MiniMax M2效果不好的一个很重要的原因是没有正确使用Interleaved Thinking。正确使用Interleaved thinking模式,可以让MiniMax M2模型的效果最多可以提升35%!本文我们主要简单聊聊这个Interleaved thinking。
OpenAI刚刚发布了一个全新的AI Agent产品,称为ChatGPT Agent。这个全新的Agent系统可以控制我们的电脑,然后使用电脑上的浏览器、PPT、Excel等工具帮我们完成一些日常的工作,从头开始帮我们完成一些非常复杂的任务。根据OpenAI的描述,这个Agent系统的目标未来是一个通用的Agent,而这些能力未来将会随着这个产品不定期更新。
随着大型语言模型(LLM)能力的飞速发展,如何科学、准确地评估其性能,特别是深度的逻辑推理和代码生成能力,已成为人工智能领域的一大挑战。传统的评测基准在面对日益强大的模型时,逐渐暴露出数据污染、难度不足、无法有效评估真实推理能力等问题。在这一背景下,一个旨在检验模型竞赛级编程水平的评测基准——Codeforces应运而生,为我们提供了一个更严苛、更接近人类程序员真实水平的竞技场。
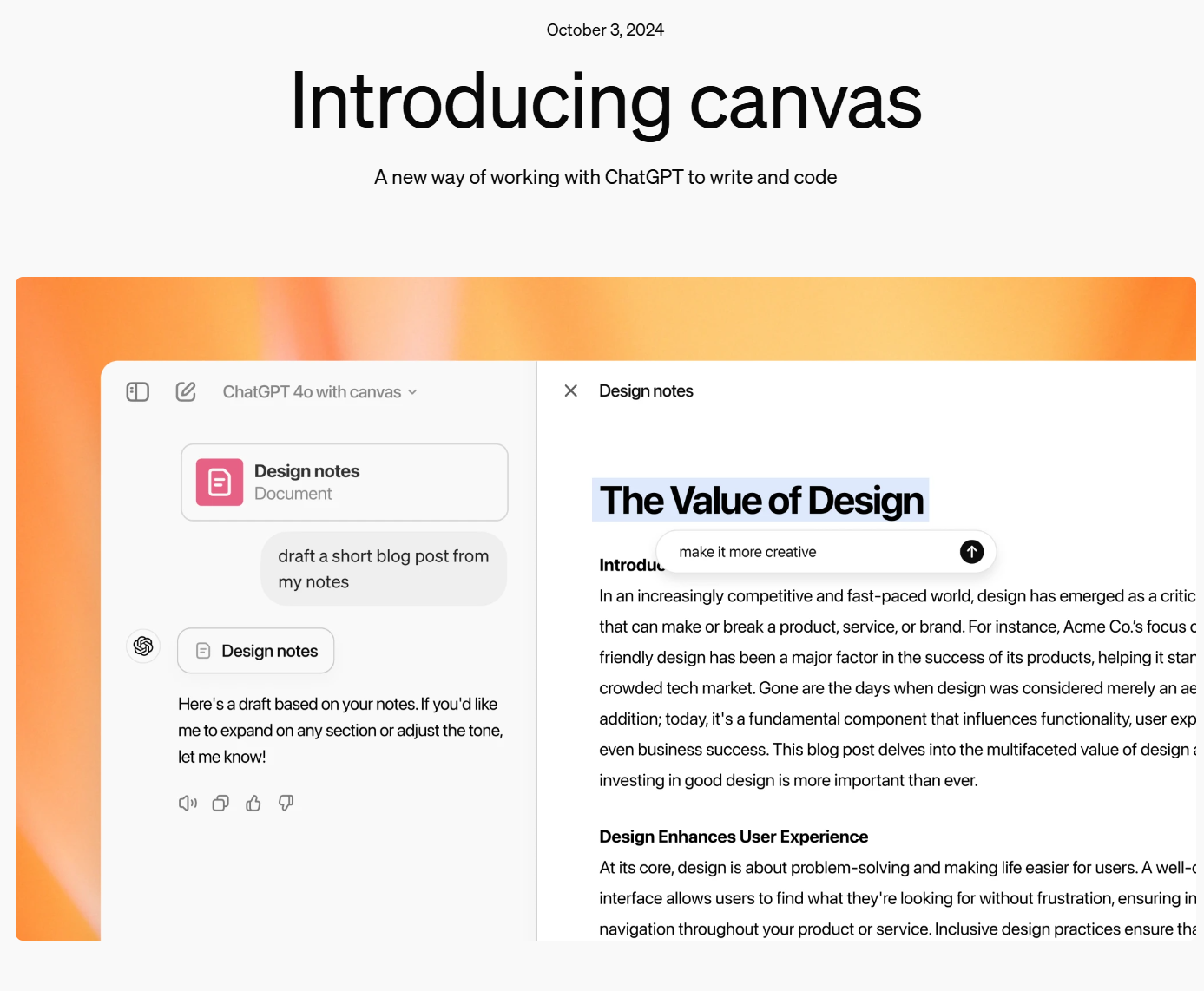
在写作和编程中,使用 ChatGPT 帮助用户处理各种复杂任务已变得越来越普遍。然而,这个过程中仍然存在一些挑战,比如上下文追踪不够连贯、实时反馈不足,以及在编程时难以精确地处理错误或优化代码。为此,OpenAI发布了一个新的特新:Canvas,它是为了解决上述问题而设计的一个全新工具,集成了写作、编程和实时协作的功能。

在AI时代,Hugging Face Hub已成为开源大语言模型(LLM)和预训练模型的宝库。从Qwen到DeepSeek系列,这些模型往往体积庞大(几GB甚至上百GB),下载过程容易受网络波动影响,导致中断、重试或失败。作为一名AI从业者,你可能不止一次遇到过“下载到99%就崩”的尴尬。本文将从客观角度,基于实际使用经验,介绍四种常见下载Hugging Face大模型的方法:从基础的Git克隆,到CLI工具、Transformers库,再到国内镜像加速。每种方法都有其适用场景和优缺点,我们将逐一剖析,帮
就在今日,Moonshot AI 正式推出 Kimi K2 Thinking,这款开源思考代理模型以其革命性的工具集成和长程推理能力,瞬间点燃了开发者社区的热情。Kimi K2能自主执行200-300次连续工具调用,跨越数百步推理,解决PhD级数学难题或实时网络谜题。本次发布的Kimi K2不仅仅是模型升级,更是AI Agent能力的扩展。

近年来,AI 编码助手与 Agent 框架层出不穷,从 Github Copilot 到 Cursor,再到各种基于 LangChain 的多代理方案。然而,真正让开发者普遍感受到“顺手”与“愉快”的,却是 Claude Code(简称 CC)。它的特别之处,并不在于引入了复杂的新架构,而恰恰在于其极简而精心打磨的设计选择。 Claude模型本身的强大毋庸置疑,但是即使是相同的模型,Claude Code体验也比其它的Agent似乎体验更好。本文基于2025年8月21日vivek公开发布的一篇英文博客,
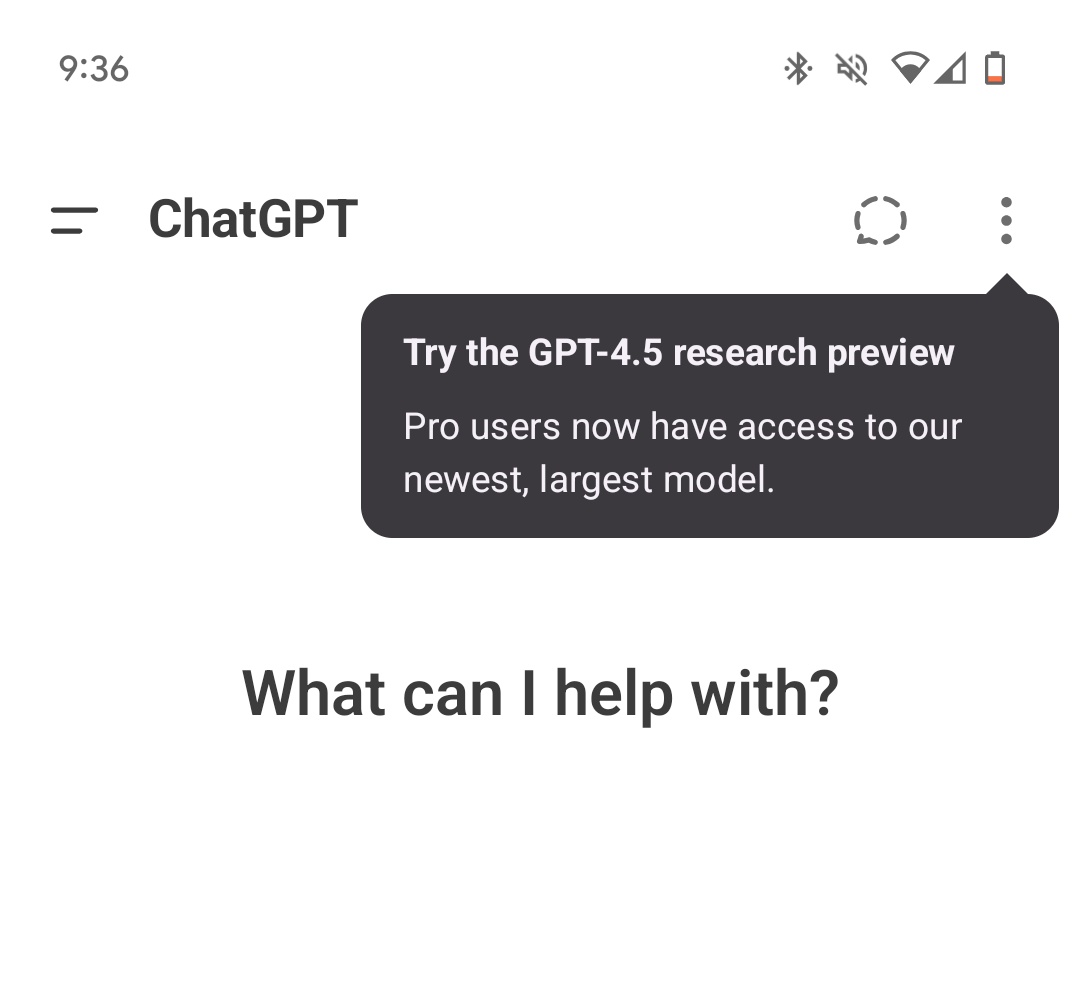
最近,一张截图在网络上流传,显示OpenAI安卓客户端的应用字符串文件(strings.xml)中出现了关于GPT-4.5的相关描述。这一发现引发了广泛关注,暗示OpenAI可能即将推出其最新的大型语言模型——GPT-4.5。该信息最早由开发者 @bitbor91 发现并分享,截图内容似乎来自ChatGPT安卓客户端的应用资源文件。
Aider 是一个在终端里进行结对编程的开源工具。为评估不同大模型在“按照指令对代码进行实际可落地的编辑”上的能力,Aider 提出并维护了公开基准与排行榜,用于比较模型在无人工干预下完成代码修改任务的可靠性与成功率。该评测已被多家模型提供方在技术说明中引用,用作代码编辑与指令遵循能力的对照指标。

就在今日,阿里巴巴Qwen团队重磅推出Qwen3-VL-2B和Qwen3-VL-32B两款视觉语言模型,这些dense架构的创新之作,将多模态AI的强大能力压缩进更紧凑的框架中,显著降低了部署门槛。 作为Qwen3系列的最新扩展,它们在保持顶级性能的同时,支持从边缘设备到云端的无缝应用——想象一下,一款手机App就能实时分析2小时视频,或从模糊手写笔记中提取精确信息。这不仅仅是参数缩减,更是AI普惠化的关键一步,帮助开发者以更低的成本实现视觉智能的突破。

今日,Moonshot AI正式发布了最新旗舰模型 Kimi K2-Instruct-0905。这是一款基于混合专家架构(MoE)的前沿大语言模型,总参数规模达到 1万亿,激活参数为 320亿,不仅在编码智能上实现了断层式提升,更凭借 256K超长上下文 成为当前同类产品中的佼佼者。官方称其在公共基准和真实智能体任务上的表现均有显著突破,已对标并超越部分国际顶尖模型。

2025年7月17日,LMArena的大模型Web能力匿名竞技场出现了一个代号为anonymous-chatbot-0717的模型,而根据ChatGPT网页版的抓包显示,这个模型应该是o3家族系列的一员,其模型的api的id为“o3-alpha-responses-2025-07-17”。

就在刚才,Anthropic 正式推出了 Claude Sonnet 4.5——全球最强的编码模型。这款新模型不仅在软件开发能力上实现了断层领先,更在构建复杂 AI 代理、计算机操控以及数学推理等多个维度展现出革命性突破。

The Information最新消息透露OpenAI正在抓紧准备GPT-4多模态版本的发布,可能称为GPT4-Vision。

xAI 正式发布 Grok 4 Fast —— 一款以 极致性价比与前沿性能 为核心卖点的新一代推理模型。相比前代产品,它不仅在推理准确率上几乎与旗舰模型Grok 4等持平,还凭借 40%更高的推理效率 和 高达98%的成本降低,将高质量智能推理真正带入大众用户和企业应用场景。

就在几个小时前,OpenAI 发布了全新的 GPT Realtime 大模型。这是一个 Speech-to-Speech(S2S)模型,能通过单个模型与 API完成从音频输入到音频输出的全流程,显著降低交互延迟并充分保留语音细节。 GPT Realtime 以“端到端语音理解—推理—合成”为核心路径,解决了传统“识别—推理—合成”多阶段带来的延迟与风格割裂问题。

编程领域大模型一直是进展非常快的大模型领域。因为编程能力更强的模型,通常在逻辑思维、工具调用上有更好的表现,在很多领域,特别是Agent领域有很大的应用价值。今天法国人工智能明星公司MistralAI发布了2个全新的编程大模型,分别是Devstral Medium和 Devstral Small 1.1,后者是一个开源的240亿参数的编程大模型。
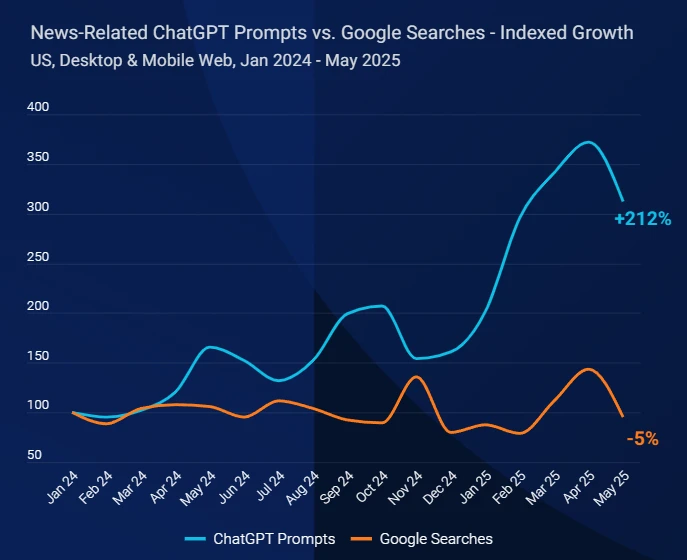
今天,SimilarWeb发布了一个全新的报告,描述了自从ChatGPT这种大模型产品发布之后,新闻出版网站的流量下滑严重,并提供了相关的分析。尽管这是针对新闻网站的报告,但是实际上所有的内容网站或者是内容生产者可能都是有影响的。我们基于这份报告进行解读,为大家提供一个参考。

就在今日,OpenAI正式推出了 Sora 2 ——其旗舰级视频与音频生成模型。相比2024年2月发布的初代 Sora,本次升级带来了断层级的真实感与显著增强的可控性。它不仅能更好地遵循物理规律生成视频,还首次实现了同步对话与环境音效的生成,并通过全新 iOS 应用“Sora”开放给公众使用。