全球首个200万上下文商业产品开始内测!月之暗面Kimi助手开启最长上下文模型内测邀请。
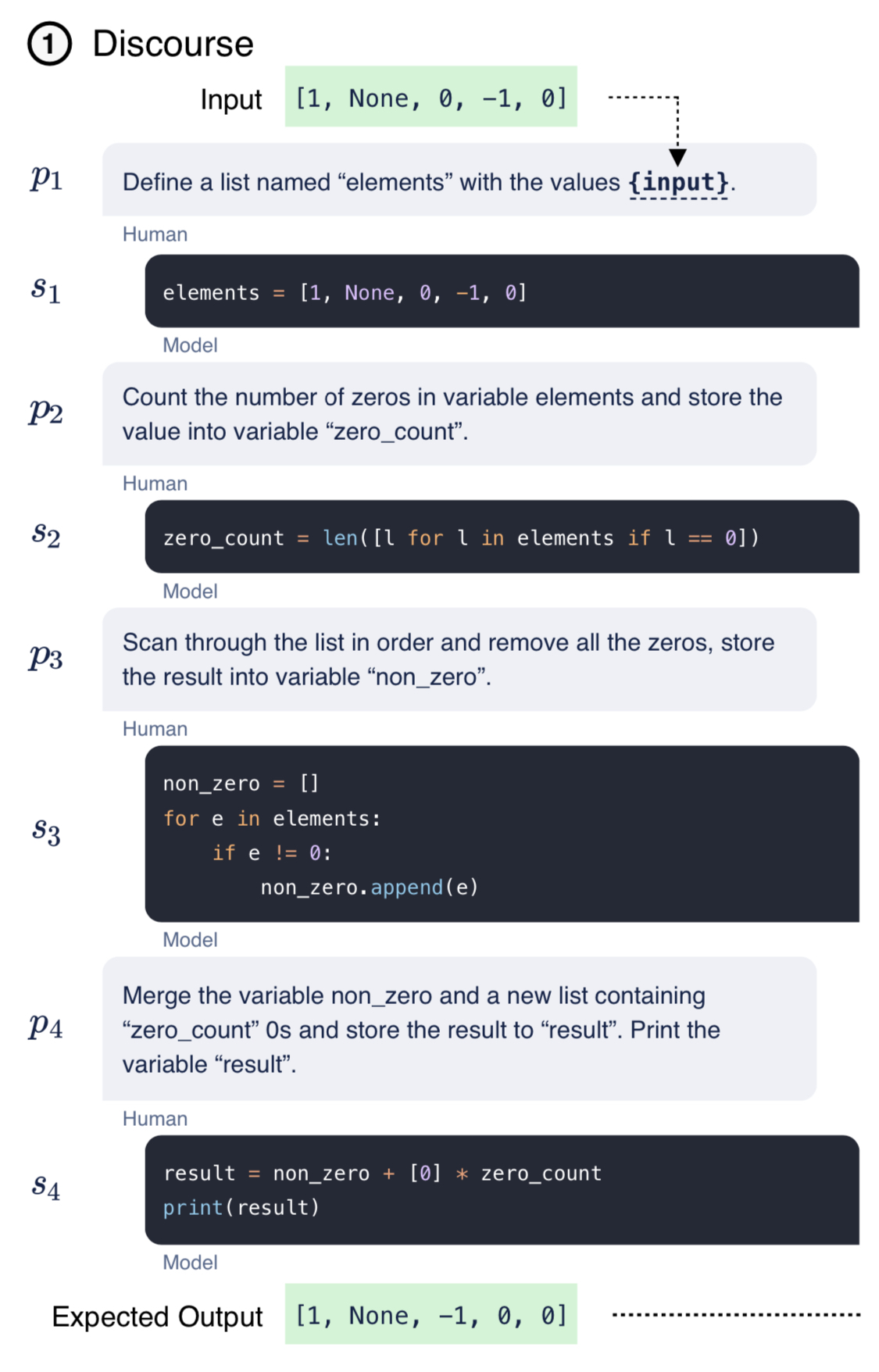
MoonshotAI(月之暗面)是一家中国的大模型初创企业,在2023年4月份成立。其最为著名的产品就是KimiChat,一个完全免费的大模型聊天机器人。就在刚刚,MoonshotAI官方宣布开启200万上下文的KimiChat内测!这应该是全球首个商业产品支持并内测200万上下文输入的模型了!此前其它产品宣布的200万上下文大多数都没有公开商发。
探索人工智能与大模型最新资讯与技术博客,涵盖机器学习、深度学习、自然语言处理等领域的原创技术文章与实践案例。
MoonshotAI(月之暗面)是一家中国的大模型初创企业,在2023年4月份成立。其最为著名的产品就是KimiChat,一个完全免费的大模型聊天机器人。就在刚刚,MoonshotAI官方宣布开启200万上下文的KimiChat内测!这应该是全球首个商业产品支持并内测200万上下文输入的模型了!此前其它产品宣布的200万上下文大多数都没有公开商发。

Bloomberg在2022年4月开源了Memray,这是一个Python的内存分析器。它可以跟踪Python代码、本地扩展模块和Python解释器本身的内存分配情况。可以看numpy和pandas的运行内存使用。

刚刚,吴恩达宣布deeplearning.ai 与 Cohere 合作推出了一个新课程:“Large Language Models with Semantic Search”。这个课程主要教授大家如何使用LLMs进行语义搜索,还提供了大量实践经验,来克服搜索结果和准确性等挑战。

零一万物(01.AI)是由李开复在2023年3月份创办的一家大模型创业企业,并在2023年6月份正式开始运营。在2023年11月6日,零一万物开源了4个大语言模型,包括Yi-6B、Yi-6B-200K、Yi-34B、Yi-34B-200k。模型在MMLU的评分上登顶,最高支持200K超长上下文输入,获得了社区的广泛关注。

文本embedding是当前大模型应用中一个十分重要的角色。在长上下文支持、私有数据问答等方面有非常重要的应用。但是相比较开源领域快速发布的大模型节奏,开源的embedding模型和数据却非常少。今天,GPT4All宣布在其软件中增加embedding的支持,这是一个完全免费且可商用的产品,最重要的是可以在我们本地用CPU来做推理。
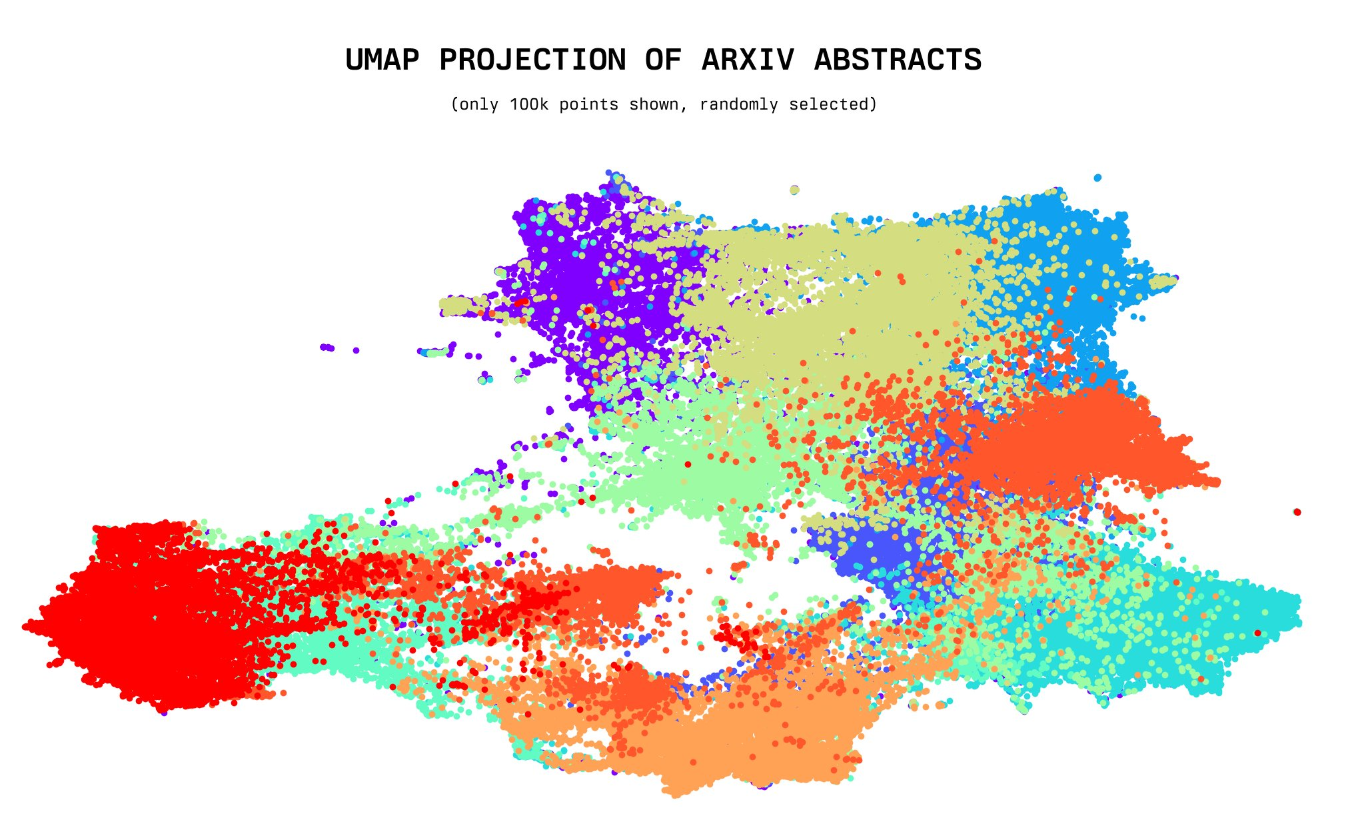
今天,一位年仅20岁的小哥willdepue 开源了230万arXiv论文的标题和摘要的embedding向量数据集,完全开源。该数据集包含截止2023年5月4日的所有arXiv上的论文标题和摘要的embedding结果,使用的是开源的Instructor XL抽取。未来将开放更多其它相关数据的embedding结果
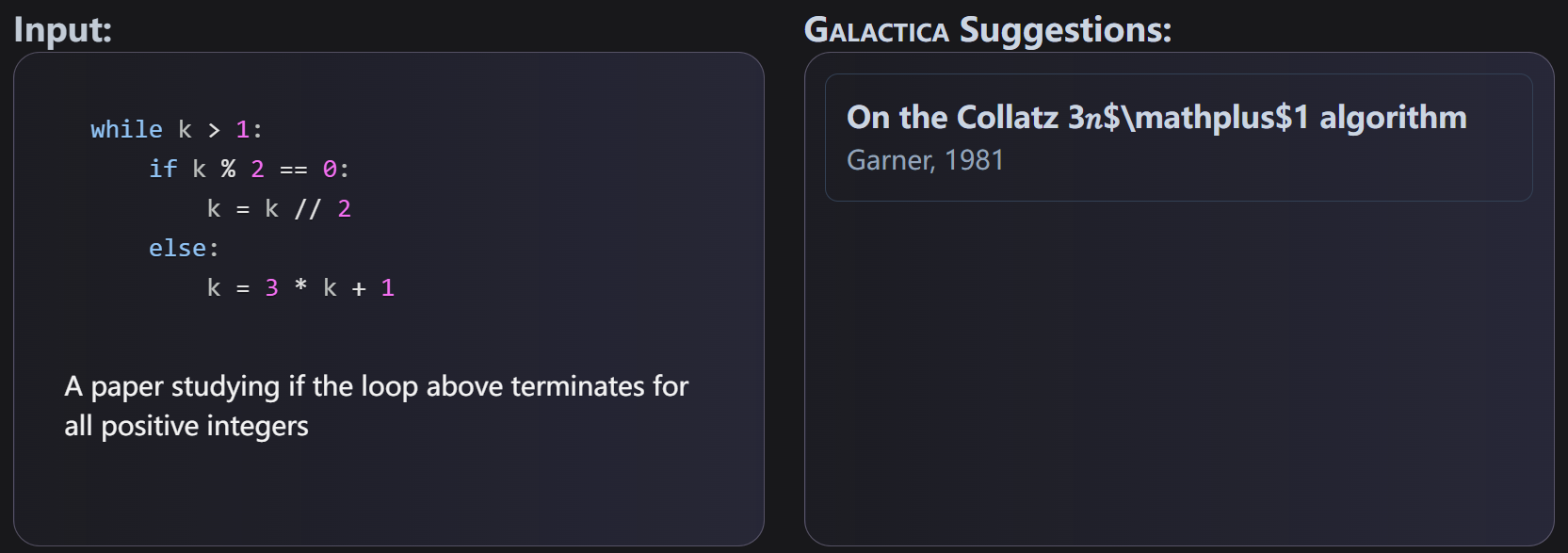
自然语言处理预训练大模型在最近几年十分流行,如OpenAI的GPT-3模型,在很多领域都取得了十分优异的性能。谷歌的PaLM也在很多自然语言处理模型中获得了很好的效果。而昨天,PapersWithCode发布了一个学术论文处理领域预训练大模型GALACTICA。功能十分强大,是科研人员的好福利!
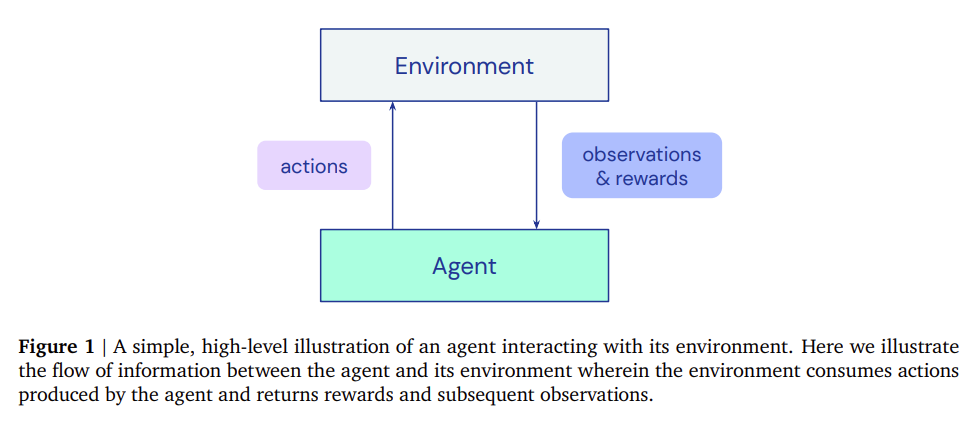
深度强化学习(RL)导致了许多最近的和突破性的进展。然而,强化学习的实施并不容易,与使深度学习拥有PyTorch这样简单的框架支持不同,强化学习的训练缺少强有力的工具支撑。为了解决这些问题,DeepMind发布了Acme,一个用于构建新的RL算法的框架,该框架是专门为实现代理而设计的

2026 年 1 月初,原名 MetaGPT 的 AI 开发框架完成了一次重大升级,将其核心产品 MGX 正式更名为 Atoms。这一消息由 DeepWisdom 团队在 X(原 Twitter)等平台发布,标志着该项目从单纯的“AI 编程助手”正式转向“AI 构建真实生意”的全新定位。

今天Google发布了TensorStore,这是一个开源的C++和Python软件库,设计用于存储和操作大规模n维数据。TensorStore已经被用来解决科学计算中的关键工程挑战(例如,管理和处理神经科学中的大型数据集,如石油级的三维电子显微镜数据和神经元活动的 "4d "视频)。TensorStore还被用于创建大规模的机器学习模型,如PaLM,解决了分布式训练期间管理模型参数(检查点)的问题。

自从2019年OpenAI开始商业化以来,OpenAI的成果越来越封闭,而商业化的进程越来越快。GPT系列的发展正好印证了这个路径。GPT最初的版本包含了论文、代码和预训练结果。GPT-2刚开始也认为可能会造成不好的伤害而在论文官宣了大半年之后才公布了完整模型。到GPT-3的时候也就给了官方介绍博客和论文,模型则是彻底闭源且开始商业化。而今天OpenAI直接官方博客宣布GPT-3.5商业化,连论文都没有了!

自从苹果发布M1系列的自研芯片开始,基于ARM架构的电脑处理器开始大放异彩。而强大的M1芯片的能力也让很多Mac用户高兴很久。而就在现在,M1也开始支持PyTorch的深度学习框架了。PyTorch官网刚刚宣布,经过和Apple的Metal工程师队伍的合作,PyTorch支持Mac的GPU加速了。
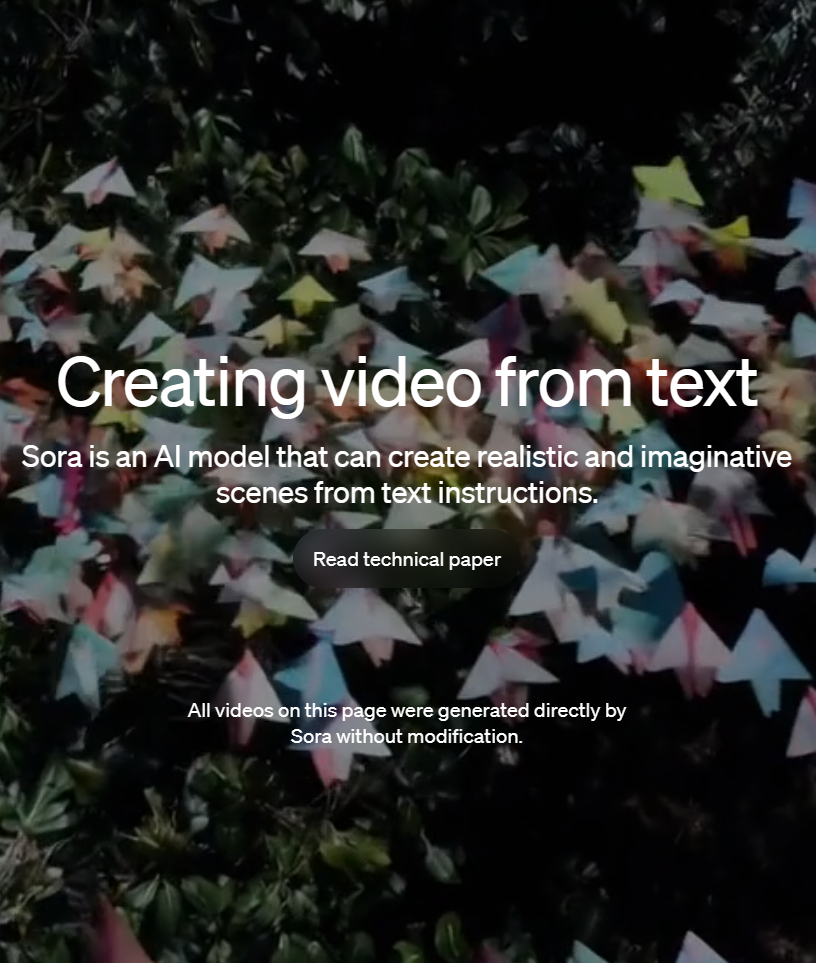
OpenAI宣布发布全新的Diffusion大模型Sora,这是一个可以生成最长60秒视频的视频生成大模型,最大的特点是可以生成非常逼真的电影画面版的视频。

几个小时前,OpenAI官方宣布开放ChatGPT的系统指令设置功能。主要就是现在你可以为自己的ChatGPT设置一个系统级别的指令,按照你的偏好,来回复所有问题。
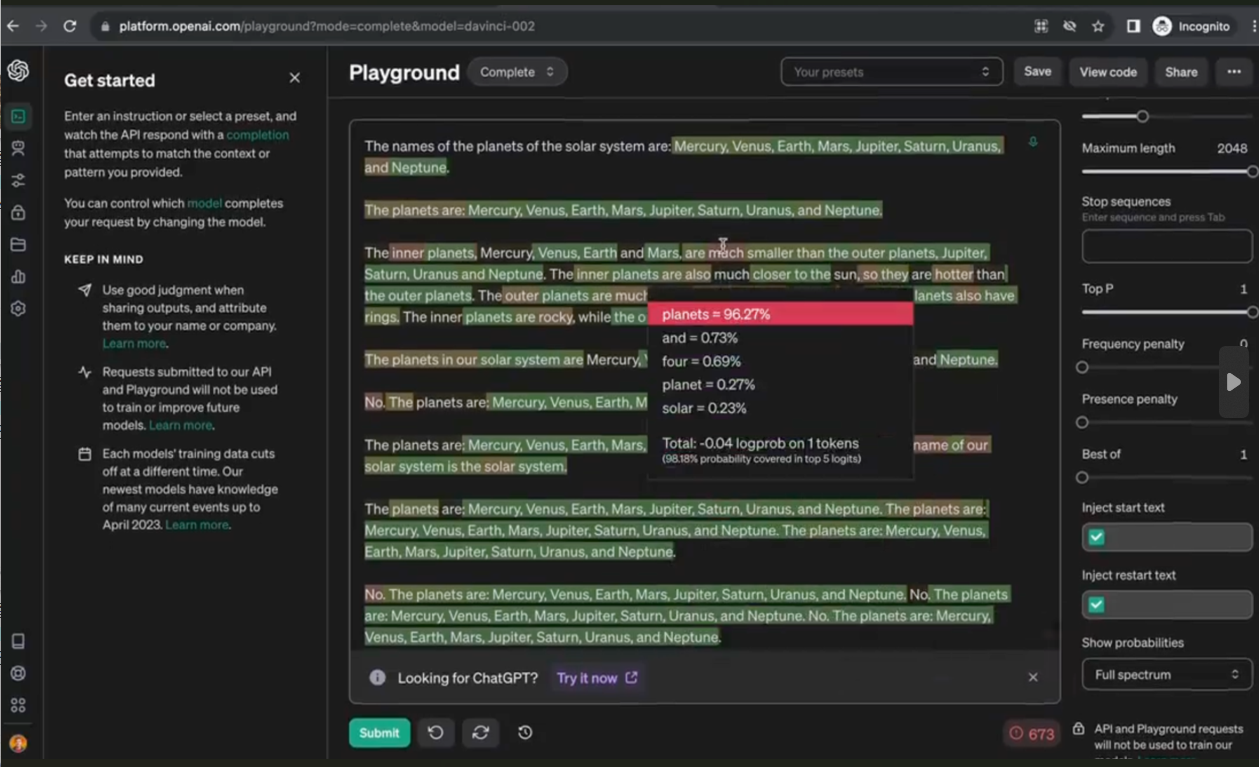
在最新的OpenAI官方接口文档中,新增了top_logprobs和logprobs这2个参数。这2个参数是一起配合使用的。后者是一个布尔类型,表明模型的返回结果中是否增加输出每个token的概率,而top_logprobs参数是一个整数类型,取值范围是0-5之间。如果top_logprobs设置为true,那么模型会根据top_logprobs的设置结果,返回输出结果中每个token及其后续的n个单词的概率。

Anthropic 正式推出全新功能 Claude Skills,旨在让通用 AI 代理(Agent)具备专业领域能力。该功能允许用户通过创建包含 SKILL.md 文件的技能文件夹,为 Claude 注入可执行脚本、模板与资源,实现 Excel 处理、PPT 生成等特定任务的自动化操作。与传统提示词不同,Skills 采用结构化加载与本地沙箱执行机制,兼顾安全性与效率。
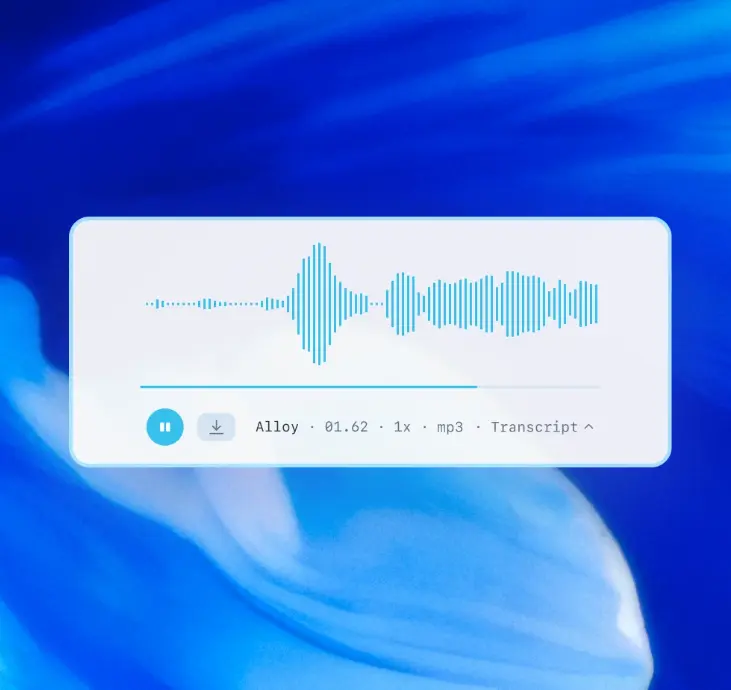
2025年3月20日,OpenAI 推出了三款新模型——gpt-4o-transcribe、gpt-4o-mini-transcribe 和 gpt-4o-mini-tts——标志着自动语音识别 (ASR) 和文本转语音 (TTS) 领域的重要进步。这些模型基于 GPT-4o 架构,旨在为开发人员和用户提高准确性、自定义能力和可访问性,与 OpenAI 对于代理式 AI 系统的更广泛愿景一致。本文提供了对每个模型、其能力、定价、可用性和竞争环境的详细审查,确保技术和非技术受众都能全面理解。
随着华为被美国多轮制裁,大家忽然发现原来国内在半导体硬件方面的差距居然如此之大。半导体硬件相关方面的关注度前所未有,为了更好地理解计算机运行的原理,本文翻译自耶鲁大学的PCLT网站,旨在介绍关于计算机运行的一些原理知识。

本篇是《阿里云天池大赛赛题解析-机器学习篇》的第一部分工业蒸汽量预测的第三章-特征工程的内容,并附带了一些知识点的网页链接。内有数据预处理、特征降维等内容。
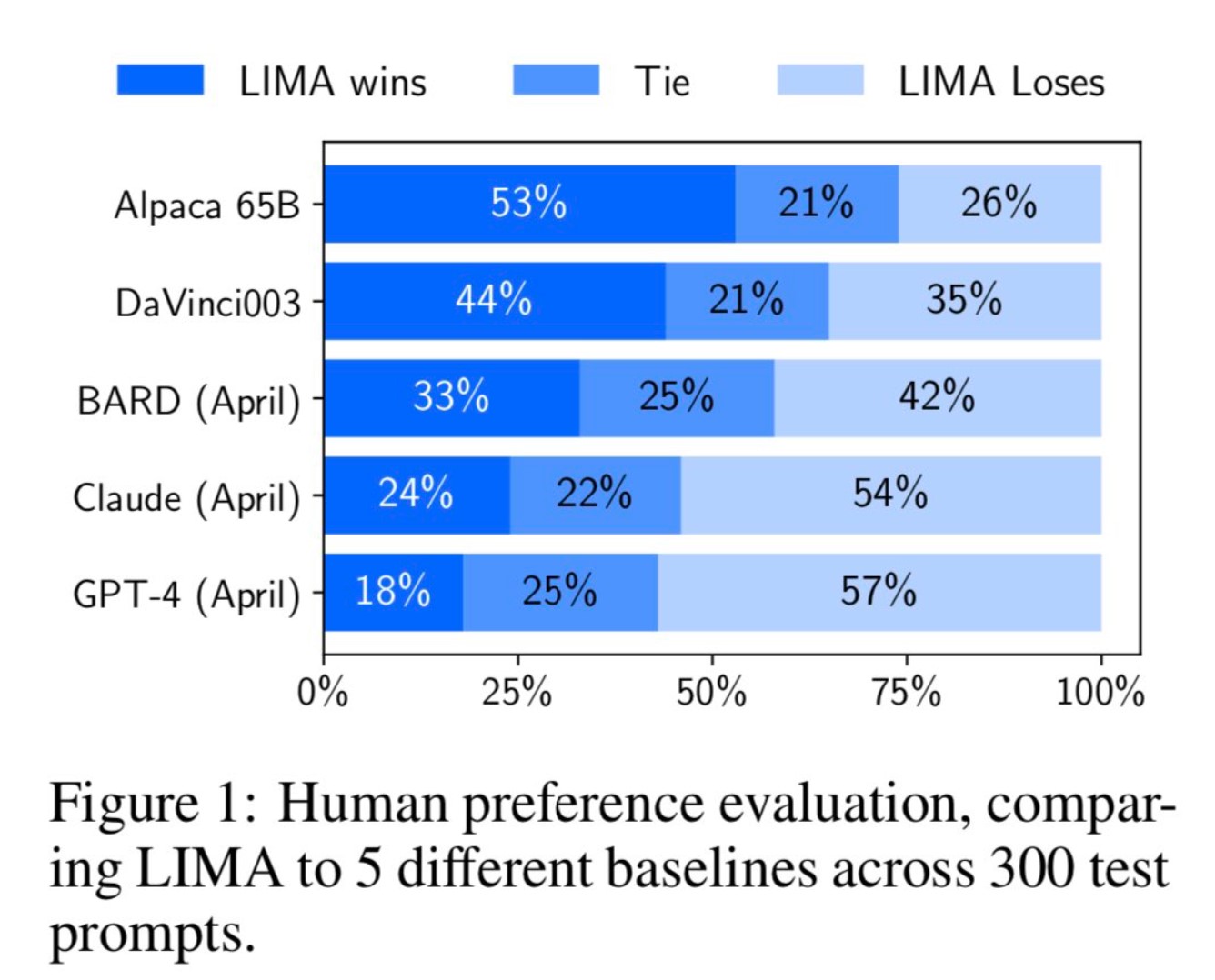
MetaAI最近公布了一个新的大语言模型预训练方法(LIMA: Less Is More for Alignment)。它最大的特点是不使用ChatGPT那样的(Reinforcement Learning from Human Feedback,RLHF)方法进行对齐训练。而是利用1000个精选的prompts与response来对模型进行微调,但却表现出了极其强大的性能。能够从训练数据中的少数几个示例中学习遵循特定的响应格式,包括从规划旅行行程到推测关于交替历史的复杂查询。
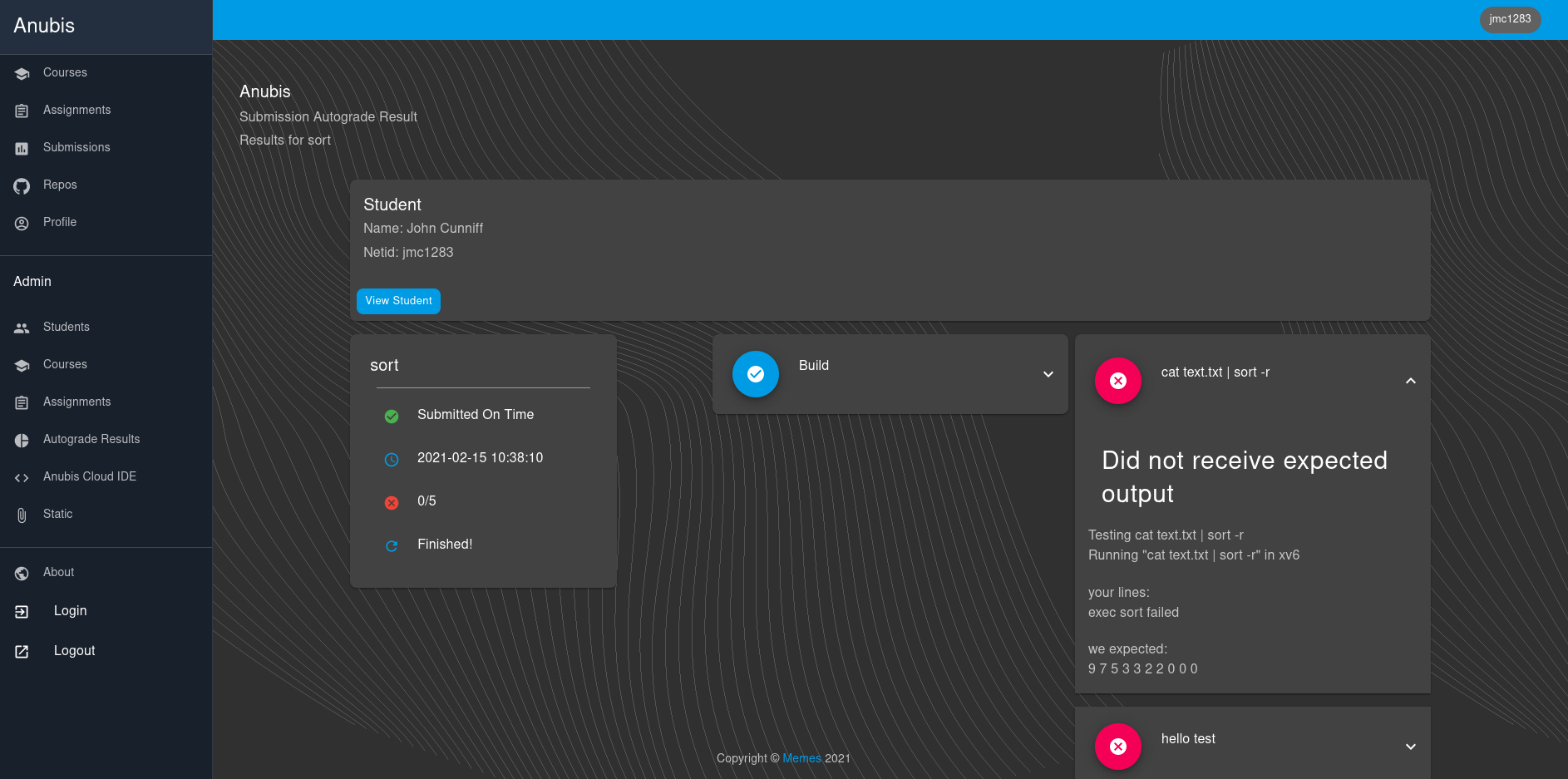
Anubis是一个分布式LMS(学习管理系统),由John Cunniff创建,专门为CS课程的自动化而设计。Anubis已经在纽约大学坦登分校使用并经过了几个学期的测试。这个系统的主要目的是自动为提交的作业评分,并提供了一个云IDE解决方案,以简化学生的体验。

Stable Diffusion是一种功能强大的开源文本到图像(Text-to-Image)生成模型。虽然目前有多个开源项目可以实现基于文本提示(prompt)创建图像,但Stable Diffusion性能极其强大,其结果甚至可以媲美DALL·E2。而现在KerasCV提供了这个模型的官方实现!

几分钟之前,OpenAI宣布ChatGPT支持多模态,目前已经支持语音的输入、语音的输出、理解图片的输入!不过目前似乎仅限于客户端~官方说的是未来2周内企业和Plus用户可以使用,后面会普及到其它用户!