国产MoE架构模型大爆发!深圳元象科技XVERSE开源256亿参数MoE大模型XVERSE-MoE-A4.2B,评测结果接近Llama1-65B
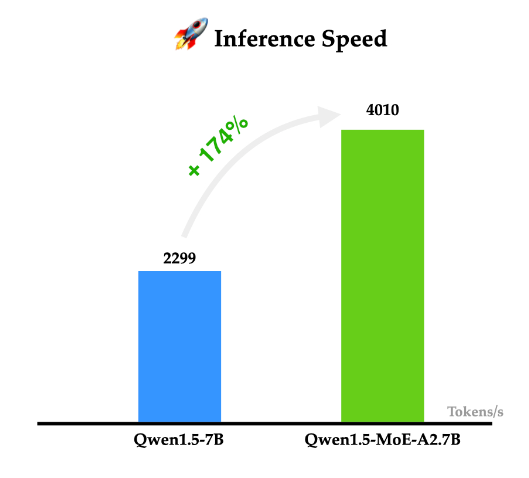
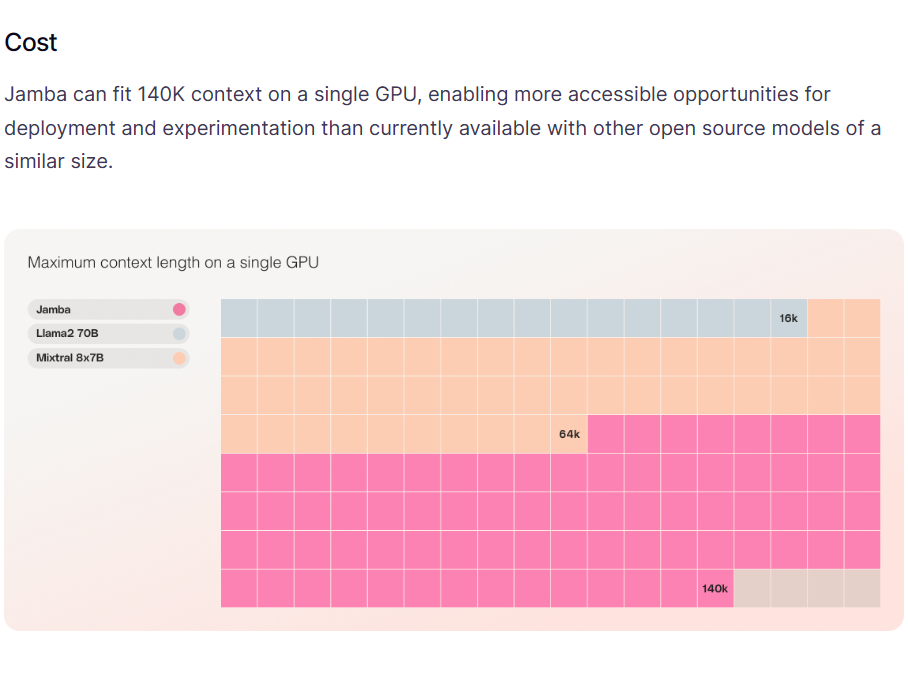
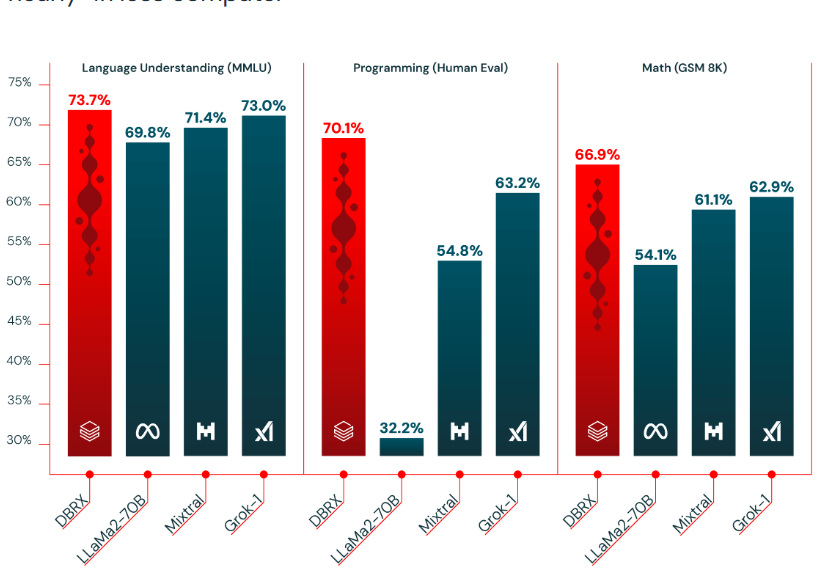
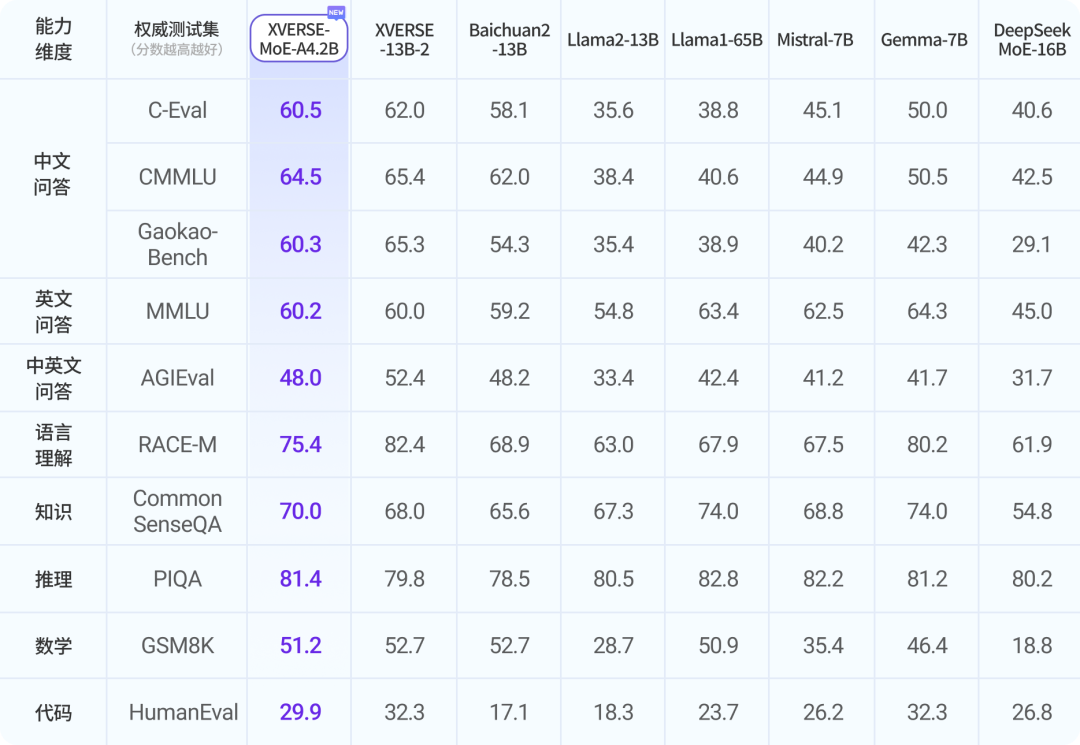
混合专家架构大模型是当前最火热的一个大模型技术发展方向。三月底,业界开源了多个混合专家大模型,包括DBRX、Qwen1.5-MoE-A2.7B等。而在四月初,又一家国产大模型企业开源了一个全新的MoE架构的模型,即深圳元象科技XVERSE开源的XVERSE-MoE-A4.2B。该模型参数256亿,推理时仅激活42亿参数,效果与当前主流的130亿参数的规模差不多。