ChatGPT即将可以读取谷歌和微软的云盘数据为你管理私有数据!
ChatGPT的发展速度很快,在前面已经介绍过ChatGPT即将推出的Team订阅计划和新界面,包括对接自定义数据和自定义接口等。此外,DataLearnerAI还发现ChatGPT即将推出关联APP的能力,截图显示,目前已经测试了对接Google Drive和Microsoft 365两个。
汇总「G」相关的原创 AI 技术文章与大模型实践笔记,持续更新。
ChatGPT的发展速度很快,在前面已经介绍过ChatGPT即将推出的Team订阅计划和新界面,包括对接自定义数据和自定义接口等。此外,DataLearnerAI还发现ChatGPT即将推出关联APP的能力,截图显示,目前已经测试了对接Google Drive和Microsoft 365两个。
ChatGPT是当前大模型服务最前沿和风向标,每一次改动都会引起巨大的关注。此前,在ChatGPT的js脚本中就隐藏了即将发布的ChatGPT Team计划。而现在,新的ChatGPT UI代码和功能也被发现。新的GPT除了界面的巨大变化外,还有一个类似自定义AI Agent能力,可以直接接入自己的私有数据和API接口对外提供服务!十分震惊!

ChatGPT是OpenAI提供的最强大的大模型服务。而截止目前为止,OpenAI公开的ChatGPT的订阅计划包含三个:免费版本的ChatGPT-3.5、个人用户付费订阅的ChatGPT Plus以及面向企业的企业版本。而最新的ChatGPT的API接口显示,OpenAI即将推出一个Team版本的计划,是当前ChatGPT Plus版本的升级版!
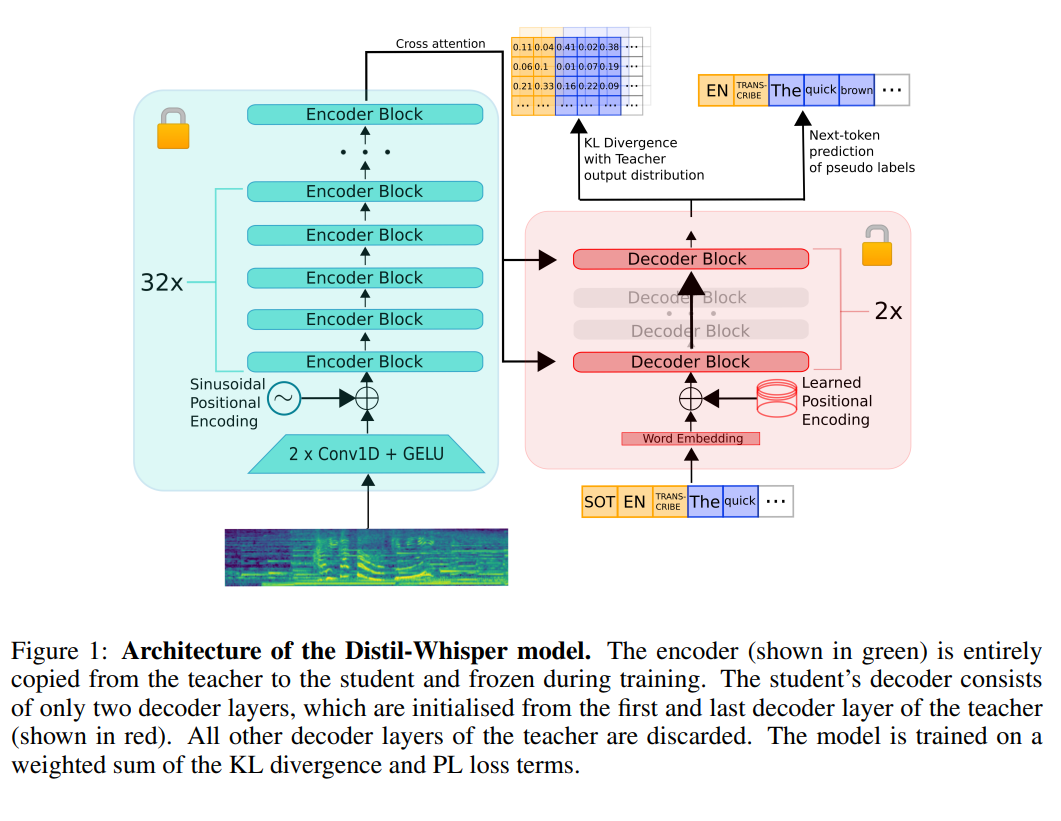
语音识别在实际应用中有非常多的应用。早先,OpenAI发布的Whisper模型是目前语音识别模型中最受关注的一类,也很可能是目前ChatGPT客户端语音识别背后的模型。HuggingFace基于Whisper训练并开源了一个全新的Distil-Whisper,它比Whisper-v2速度快6倍,参数小49%,而实际效果几乎没有区别。

2022年11月底发布的ChatGPT是基于OpenAI的GPT-3优化得到的可以进行对话的一个产品。直到今年更新到3.5和4之后,官方分为两个产品服务,其中ChatGPT 3.5是基于gpt-3.5-turbo打造,免费试用。因此,几乎所有人都自然认为这是一个与GPT-3具有同等规模参数的大模型,也就是说有1750亿参数规模。但是,在10月26日微软公布的CodeFusion论文的对比中,大家发现,微软的表格里面写的ChatGPT 3.5只有200亿参数规模。
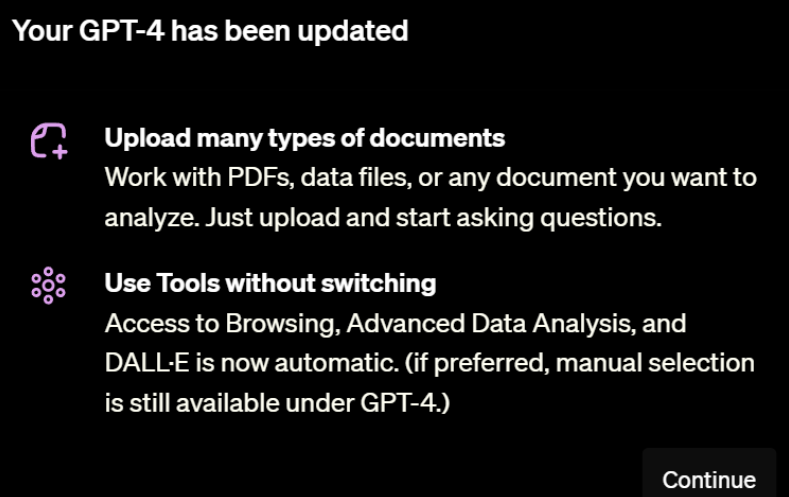
此前OpenAI的ChatGPT Plus版本为GPT-4模型提供了多个强大的插件供大家使用,包括基于Bing的带网络浏览的Browse、文本生成图片的DALL·E3、高级数据分析功能等。就在几个小时前,OpenAI的部分用户收到了官方的一个非常重磅的更新,即上传任意文档的分析以及整合了所有工具后的GPT-4!这个功能被称为GPT-4(All Tools)!这个工具可以在一次对话中自主选择调用多个不同工具完成用户的输入指令,非常接近AI Agent形态!
ChatGLM系列是智谱AI发布的一系列大语言模型,因为其优秀的性能和良好的开源协议,在国产大模型和全球大模型领域都有很高的知名度。今天,智谱AI开源其第三代基座大语言模型ChatGLM3-6B,官方说明该模型的性能较前一代大幅提升,是10B以下最强基础大模型!

检索增强生成(Retrieval-augmented Generation,RAG)是一种结合了检索和大模型生成的方法。它从一个大型知识库中检索与输入相关的信息,然后利用这些信息作为上下文和问题一起输入给大语言模型,并让大语言模型基于这些信息生成答案的方式。检索增强生成可以让大语言模型与最新的外部数据或者知识连接,进而可以基于最新的知识和数据回答问题。尽管检索增强生成是一种很好的补充方法,但是,如果文档切分有问题、检索不准确,结果也是不好的。

检索增强生成(Retrieval-augmented Generation,RAG)可以让大语言模型与最新的外部数据或者知识连接,进而可以基于最新的知识和数据回答问题。尽管检索增强生成是一种很好的补充方法,如果文档切分有问题、检索不准确,结果也是不好的。而检索增强生成也有一些提升方法,本文基于LangChain提供的一些方法给大家总结一下。
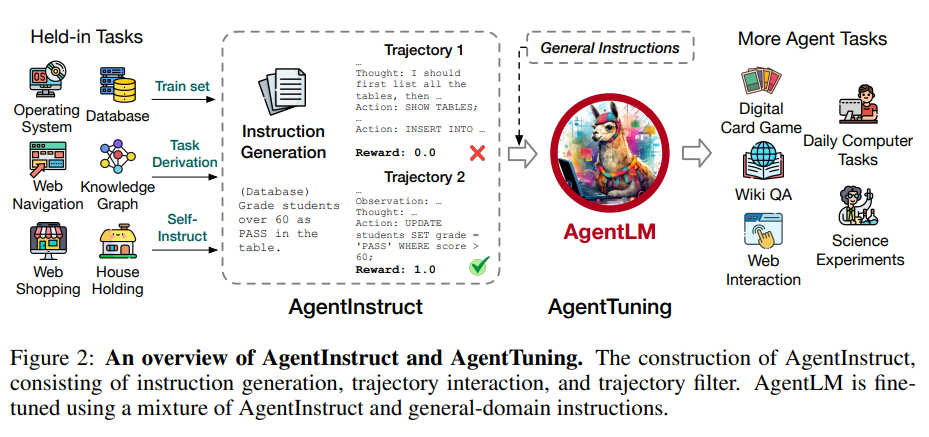
尽管开源的大语言模型发展非常迅速,但是,在以大语言模型作为核心的新一代AI Agent解决方案上,开源大语言模型比商业模型表现要明显地差。为了提高大语言模型作为AI Agent的表现和能力,清华大学和智谱AI推出了一种新的方案,AgentTuning,可以将有效增强开源大语言模型作为AI Agent的能力。
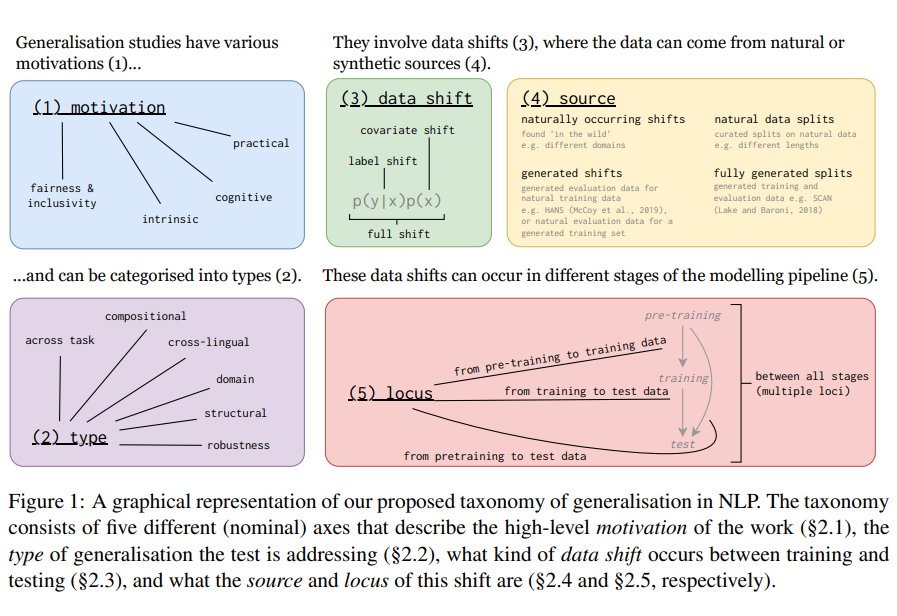
关于什么是好的泛化、存在哪些类型的泛化以及在不同的场景中哪些应该被优先考虑,人们对此了解甚少且意见不一。而MetaAI等机构的研究人员最近发布了一篇关于大模型泛化能力的综述,详细总结了大模型泛化能力的分类等。本篇论文详细总结一下大模型的泛化能力分类以及什么样的泛化是未来的中的重点等问题。

在大语言模型中,上下文长度是指模型可以考虑的输入数据的数量。更长的上下文在大语言模型的实际应用中有非常重要的价值。当前,让大语言模型支持更长的上下文有两种常用的方法,一种是训练支持更长上下文长度的模型,扩展模型的输入,另外一种是检索增强生成的方法(Retrieval Augmentation Generation,RAG)。但二者应该如何选择,这是一个很少能直接比较的问题。为此,英伟达(Nvidia)的研究人员做了一个详细的比较。
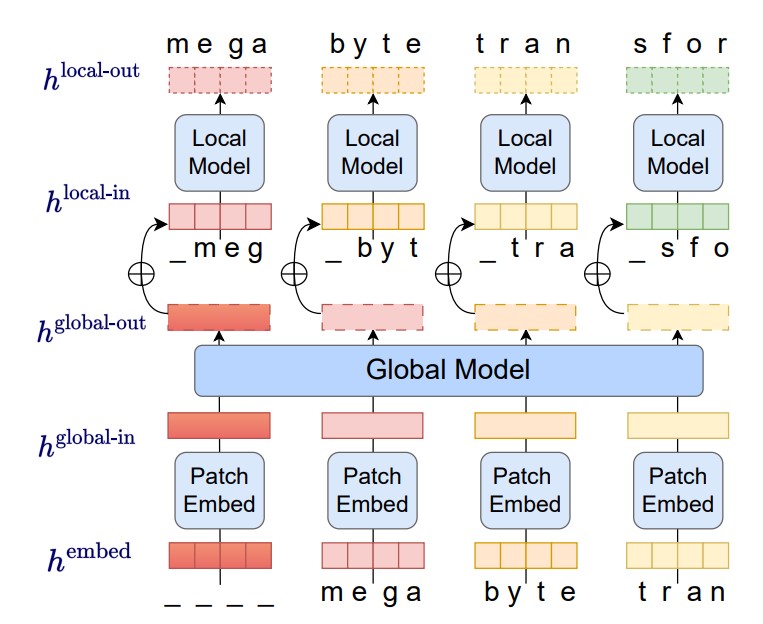
尽管OpenAI的ChatGPT很火爆,但是这类大语言模型有一个非常严重的问题就是对输入的内容长度有着很大的限制。例如,ChatGPT-3.5的输入限制是4096个tokens。MetaAI在前几天提交了一个论文,提出了MegaByte方法,几乎可以让模型接受任意长度的限制!

几分钟之前,OpenAI宣布ChatGPT支持多模态,目前已经支持语音的输入、语音的输出、理解图片的输入!不过目前似乎仅限于客户端~官方说的是未来2周内企业和Plus用户可以使用,后面会普及到其它用户!
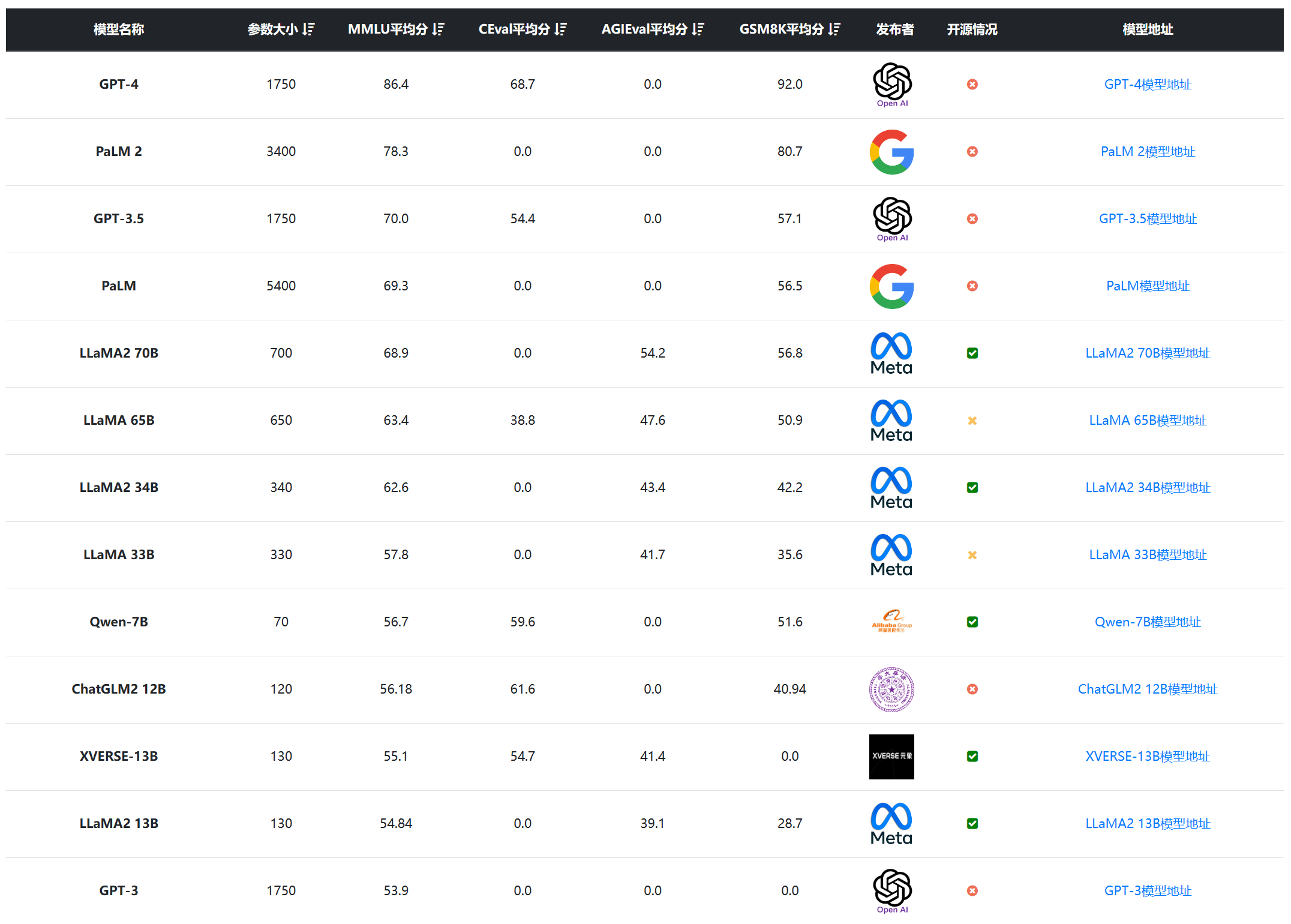
随着各种AI模型的快速发展,选择合适的模型成为了研究和开发的一大挑战。最近一段时间,国产模型不断涌现,让人应接不暇。尽管开源的繁荣提供了更多的选择,实际上也造成了选型的困难,尽管业界提供了很多评测基准,但是,**很多模型在公布的评测结果中对比的模型基准和选择的测试基准都很少,甚至只选择对自己有利的结果**。为了更加方便大家对比相关的结果,DataLearner上线了大模型评测综合排行对比表,给大家提供一个更加清晰的对比结果。我们主要关注的是国内开源大模型和一些全球主流模型的对比结果。

The Information最新消息透露OpenAI正在抓紧准备GPT-4多模态版本的发布,可能称为GPT4-Vision。

OpenAI最新发布了GPT-3.5-Turbo-Instruct,这是一款强大的指令遵循大模型。尽管官方没有发布官方博客介绍,但我们将在本文中详细探讨这一模型的特点以及其在人工智能领域的价值。
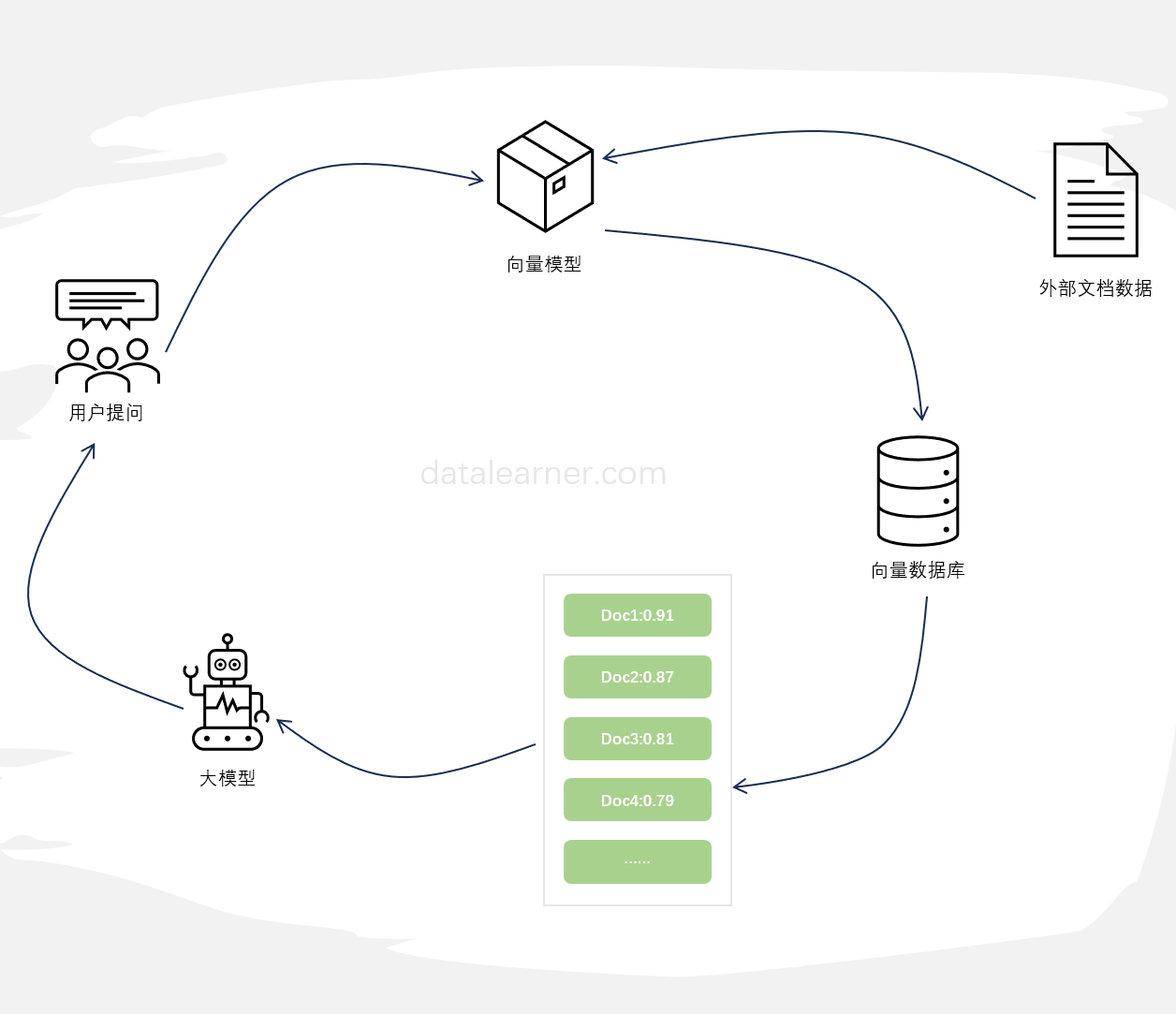
检索增强生成(Retrieval-augmented generation,RAG)是一种将外部知识检索与大型语言模型生成相结合的方法,通常用于问答系统。当前使用大模型基于外部知识检索结果进行问答是当前大模型与外部知识结合最典型的方式,也是检索增强生成最新的应用。然而,近期的研究表明,这种方式并不总是最佳选择,特别是当检索到的文档数量较多时,这种方式很容易出现回答不准确的情况。为此,LangChain最新推出了LongContextReorder,推出了一种新思路解决这个问题。

大模型的长输入在很多场景下都有非常重要的应用,如代码生成、故事续写、文本摘要等场景,支撑更长的输入通常意味着更好的结果。昨天,斯坦福大学、加州伯克利大学和Samaya AI的研究人员联合发布的一个论文中有一个非常有意思的发现:当相关信息出现在输入上下文的开始或结束时,大模型的性能通常最高,而当大模型必须访问长上下文中间的相关信息时,性能显著下降。本文将简单介绍一下这个现象。
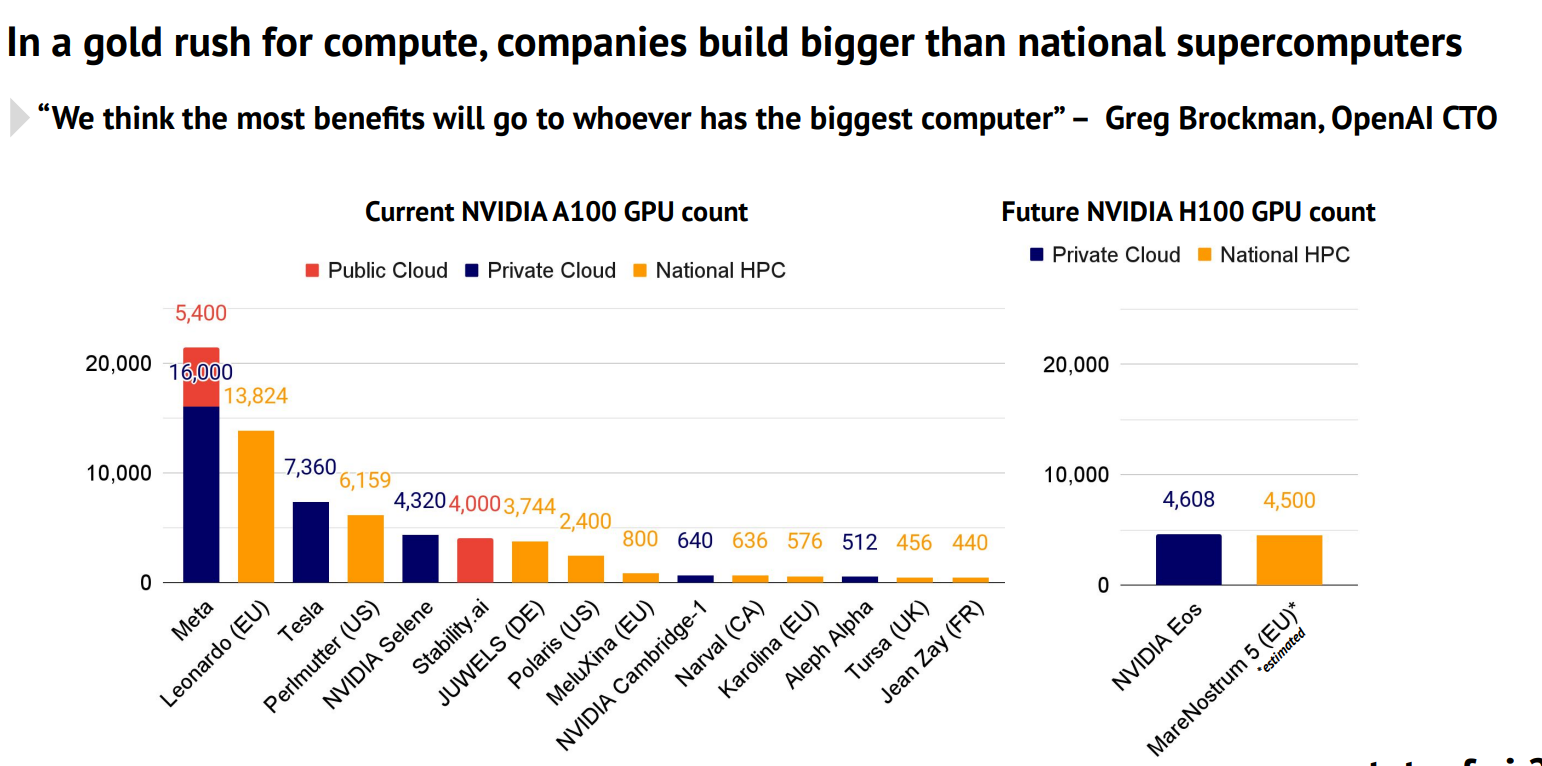
Stateof.AI上周发布了最新的AI的报告中报告了当前各大企业和机构拥有的NVIDIA A100的GPU数量。A100是目前商用的最强大的GPU,对于超级计算机、大规模AI模型的训练和推理来说都十分重要。这里透露的各大企业的GPU数量也让我们可以看到各家的竞争情况。

Prompt技巧一直是提升ChatGPT等大语言模型使用效率的最重要方法之一。为此,OpenAI官方也在不断地分享官方的Prompt技巧。2023年的8月31日,OpenAI官方最新分享了一个教室使用的Prompt来帮助老师授课的案例。尽管这是针对老师的Prompt教程,但是其中的设计思路其实也可以广泛运用在客服、问答系统、编程等领域。
OpenAI发布了ChatGPT的企业版,这是一个专为企业设计的聊天机器人。这个版本不仅提供了企业级的安全和隐私保护,还具有更高的处理速度和更多的自定义选项。相比较个人版的ChatGPT,企业版主要是提升了性能、强调了安全等。

此前,OpenAI的CEO说今年等算力不那么紧张的时候就可以让大家微调OpenAI的GPT模型,现在这个功能已经发布了!OpenAI发布了GPT-3.5 Turbo的微调接口,允许大家用自己的数据微调GPT-3.5模型!

Stable Diffusion XL是StabilityAI最新的开源模型。是目前业界流行的免费开源图像生成大模型。2023年4月份StabilityAI就宣布了SD XL的存在并在2023年7月26日开源。SD XL相比较此前的模型速度更快、提示词更短、生成的图像更加真实。但是,大多数人可能并没有实际运行过,感受过这个模型的魅力。在这篇博客中,我们给大家展示如何利用Google Colab的免费GPU资源,部署一个SD XL模型,并通过prompt生成一些图片。