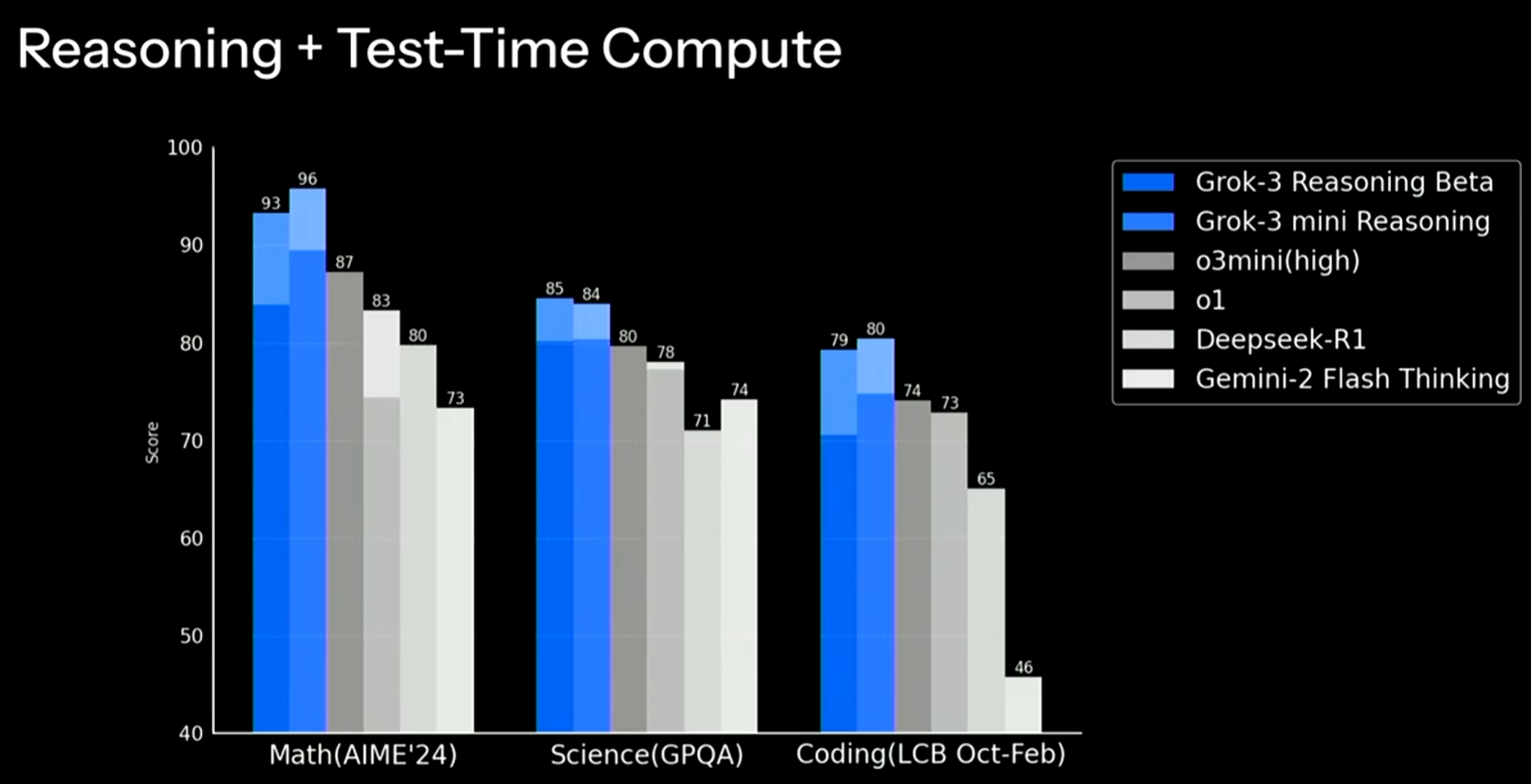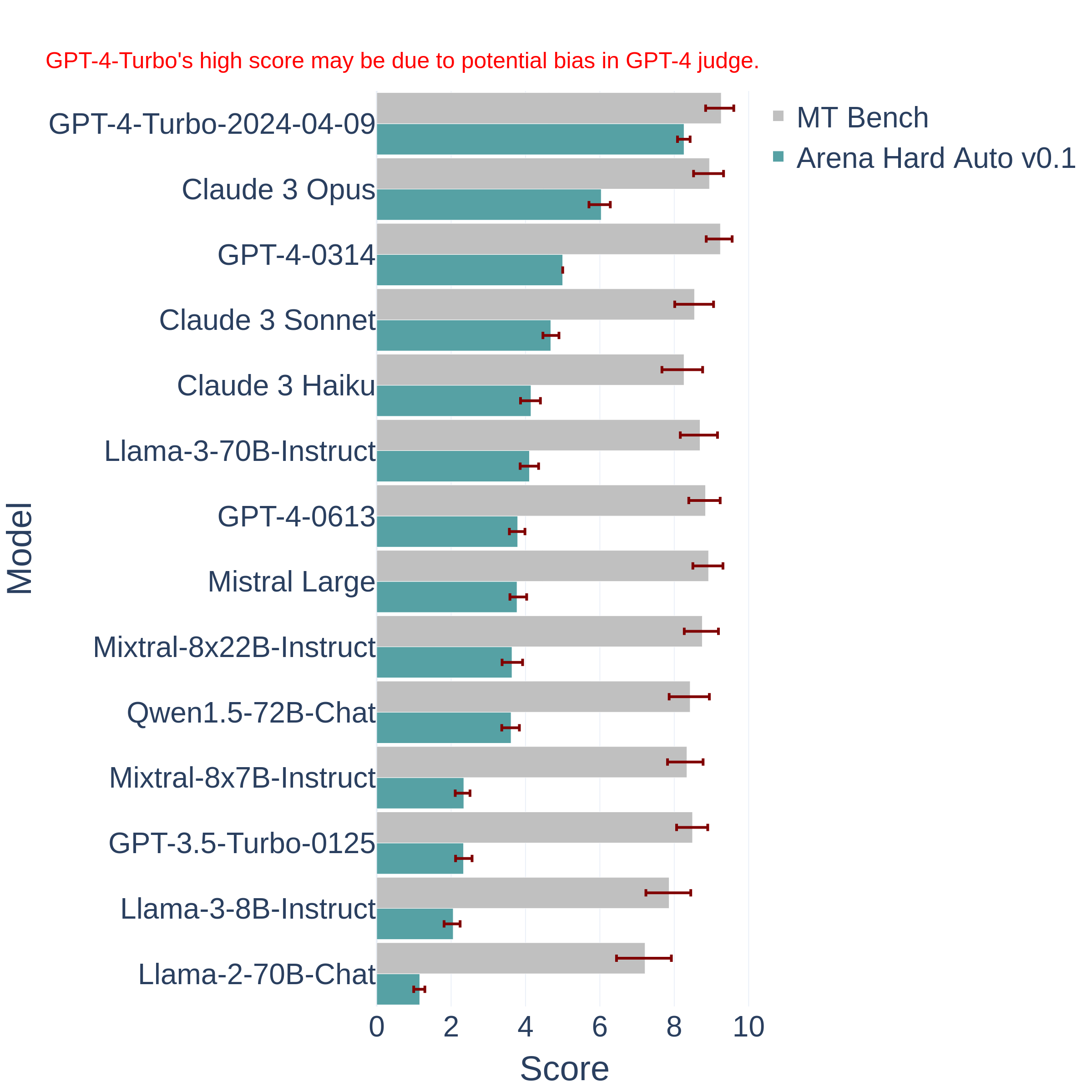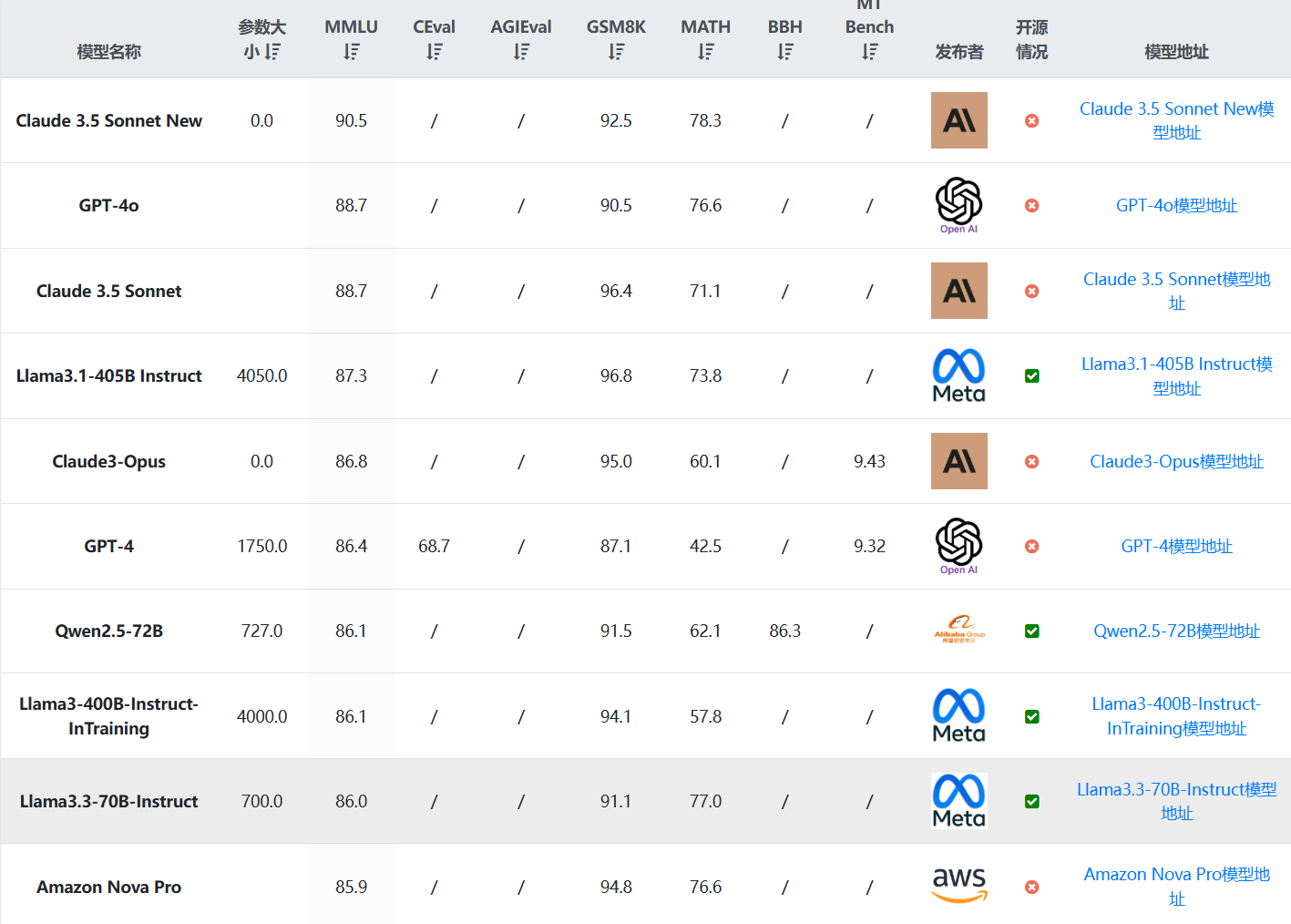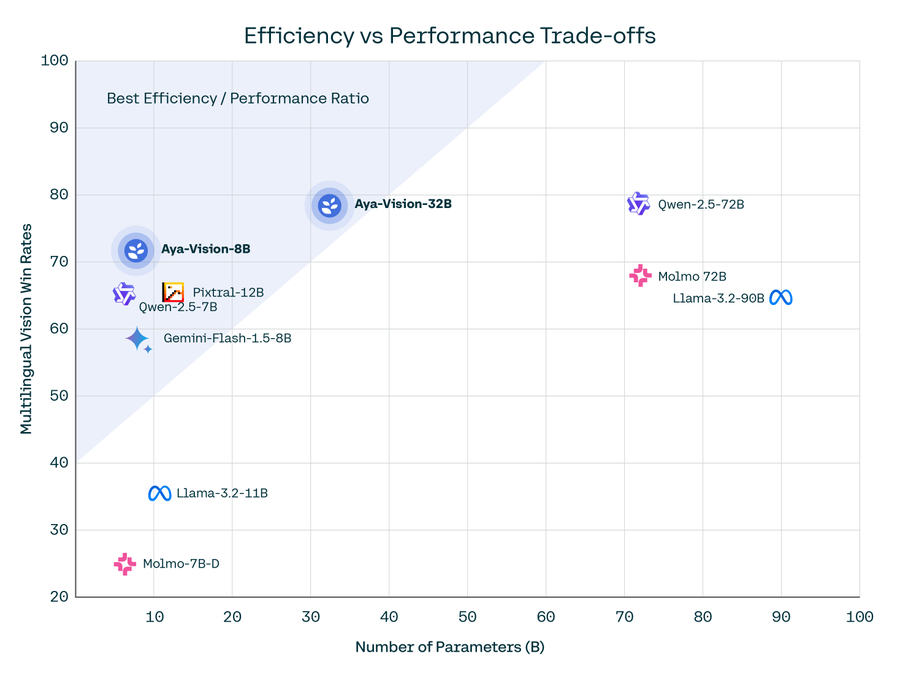
CohereAI开源了2个Aya Vision多模态大模型:80亿和320亿两种规格多模态大模型,评测结果超越Qwen2.5 72B和Llama 3.2 90B,支持23种语言
Cohere For AI 推出了 Aya Vision 系列,这是一组包含 80 亿(8B)和 320 亿(32B)参数的视觉语言模型(VLMs)。这些模型针对多模态AI系统中的多语言性能挑战,支持23种语言。Aya Vision 基于 Aya Expanse 语言模型,并通过引入视觉语言理解扩展了其能力。该系列模型旨在提升同时需要文本和图像理解的任务性能。