检索增强生成中的挑战详解:哪些因素影响了检索增强生成的质量?需要如何应对?
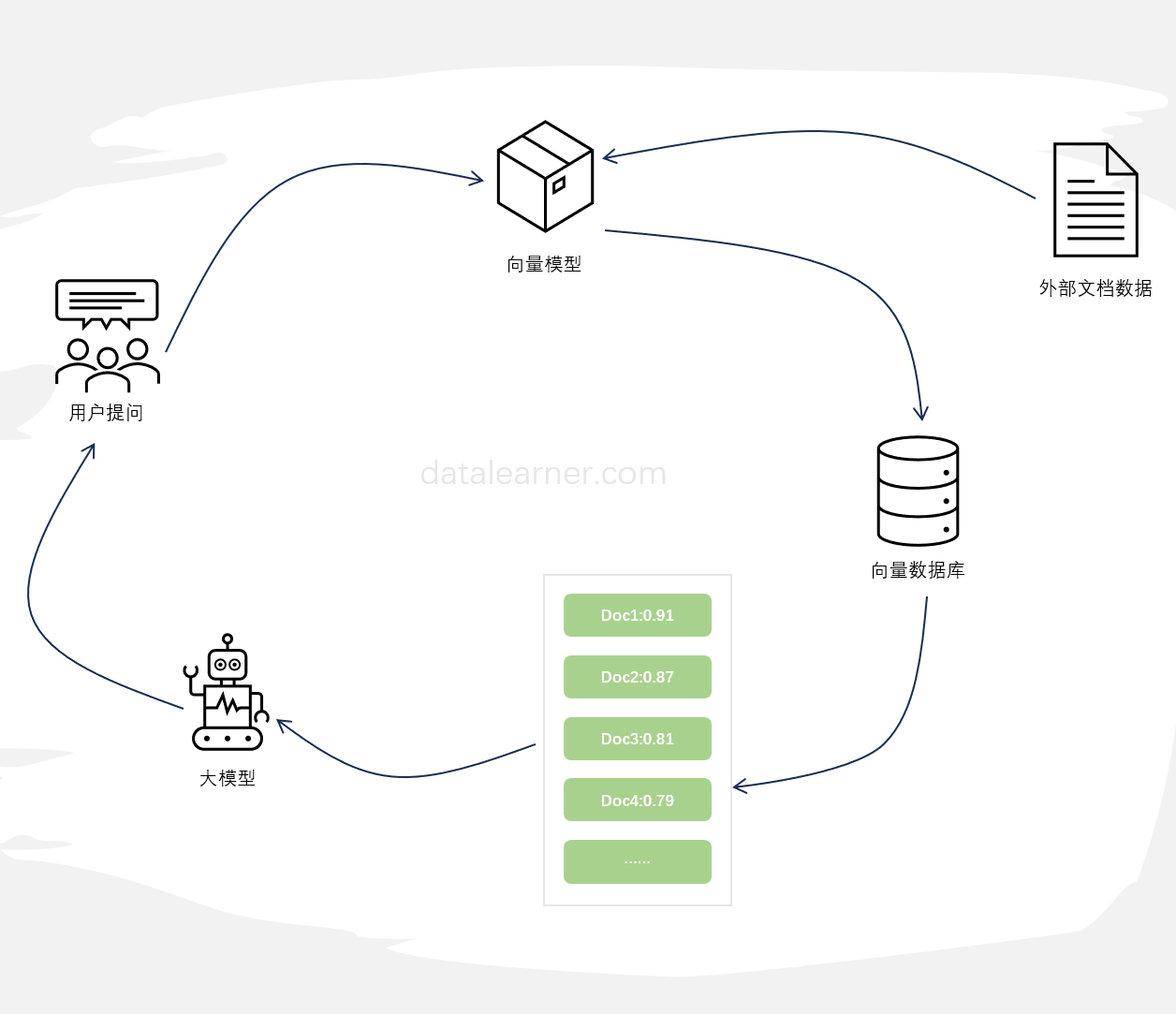
检索增强生成(Retrieval-augmented Generation,RAG)是一种结合了检索和大模型生成的方法。它从一个大型知识库中检索与输入相关的信息,然后利用这些信息作为上下文和问题一起输入给大语言模型,并让大语言模型基于这些信息生成答案的方式。检索增强生成可以让大语言模型与最新的外部数据或者知识连接,进而可以基于最新的知识和数据回答问题。尽管检索增强生成是一种很好的补充方法,但是,如果文档切分有问题、检索不准确,结果也是不好的。