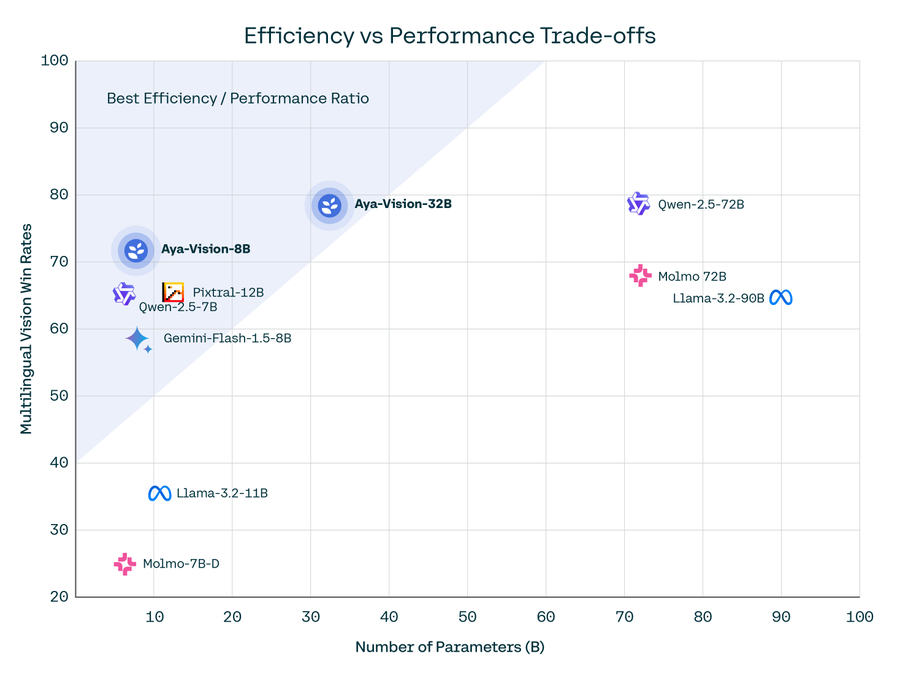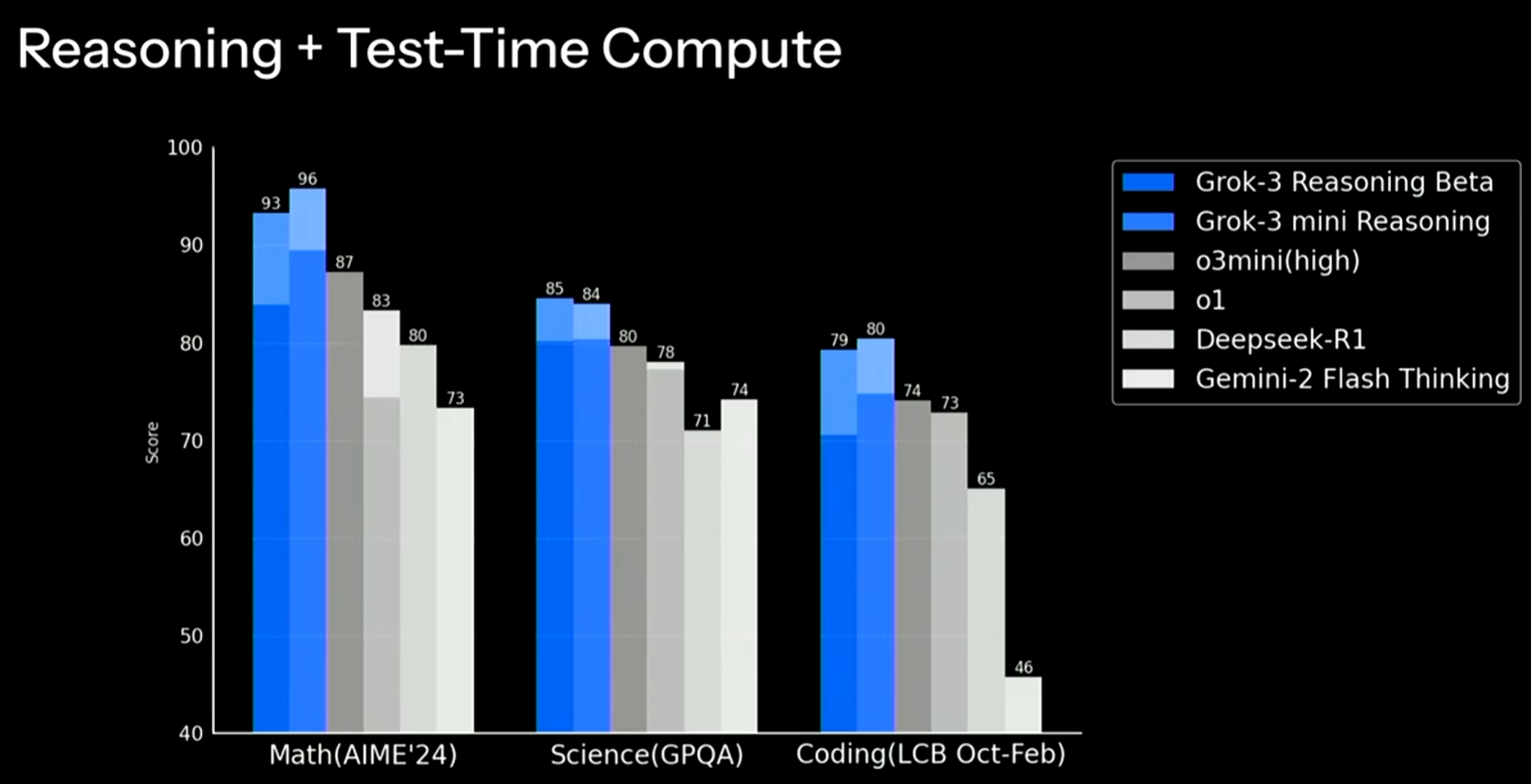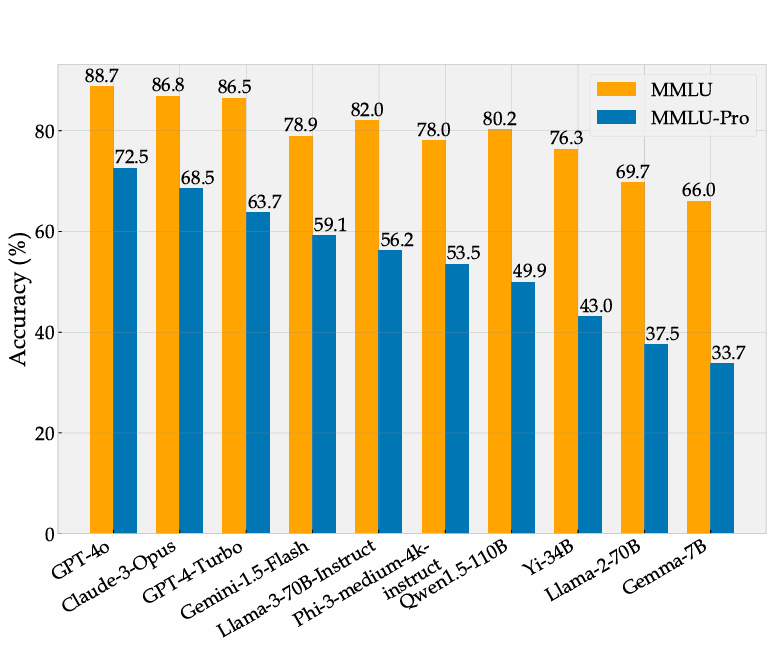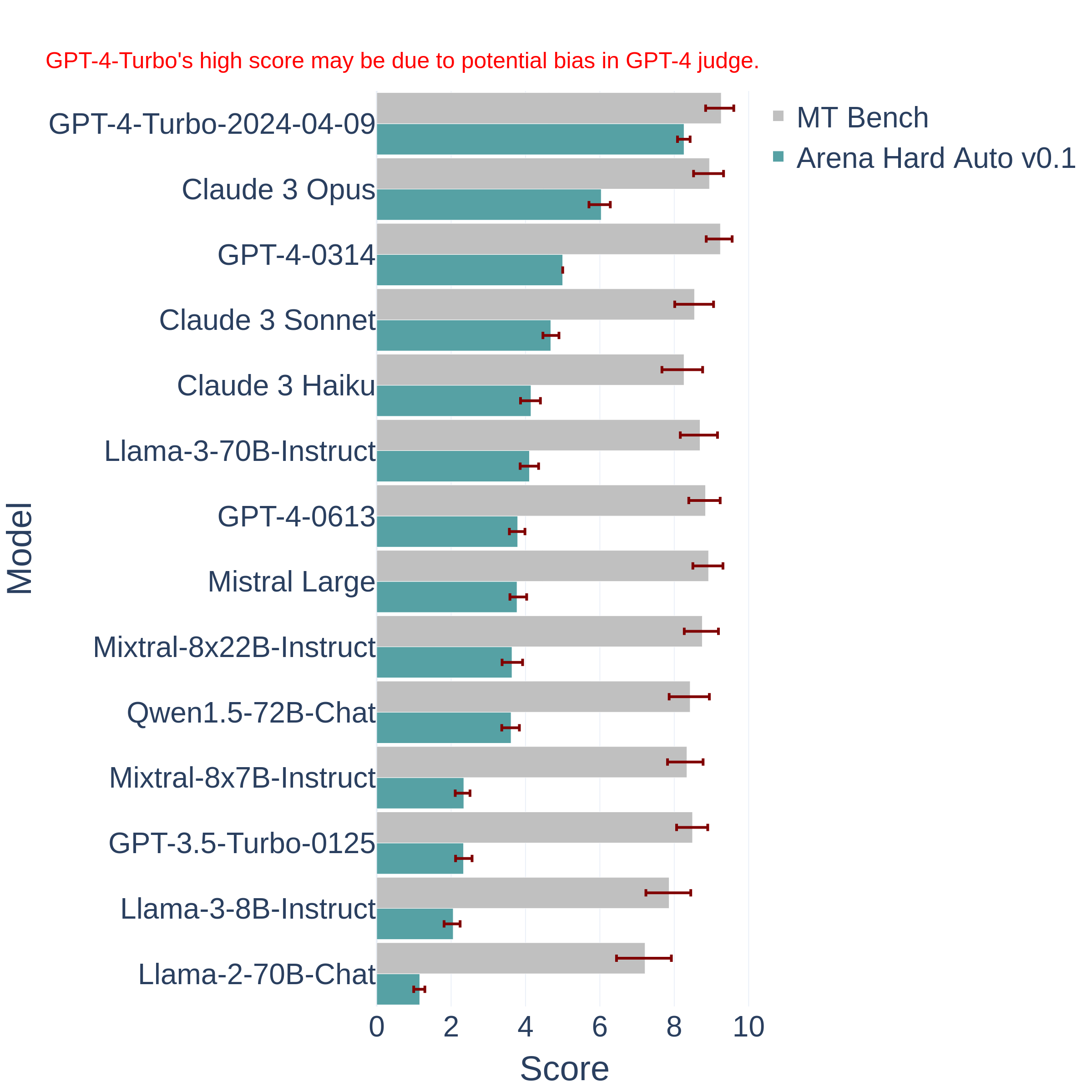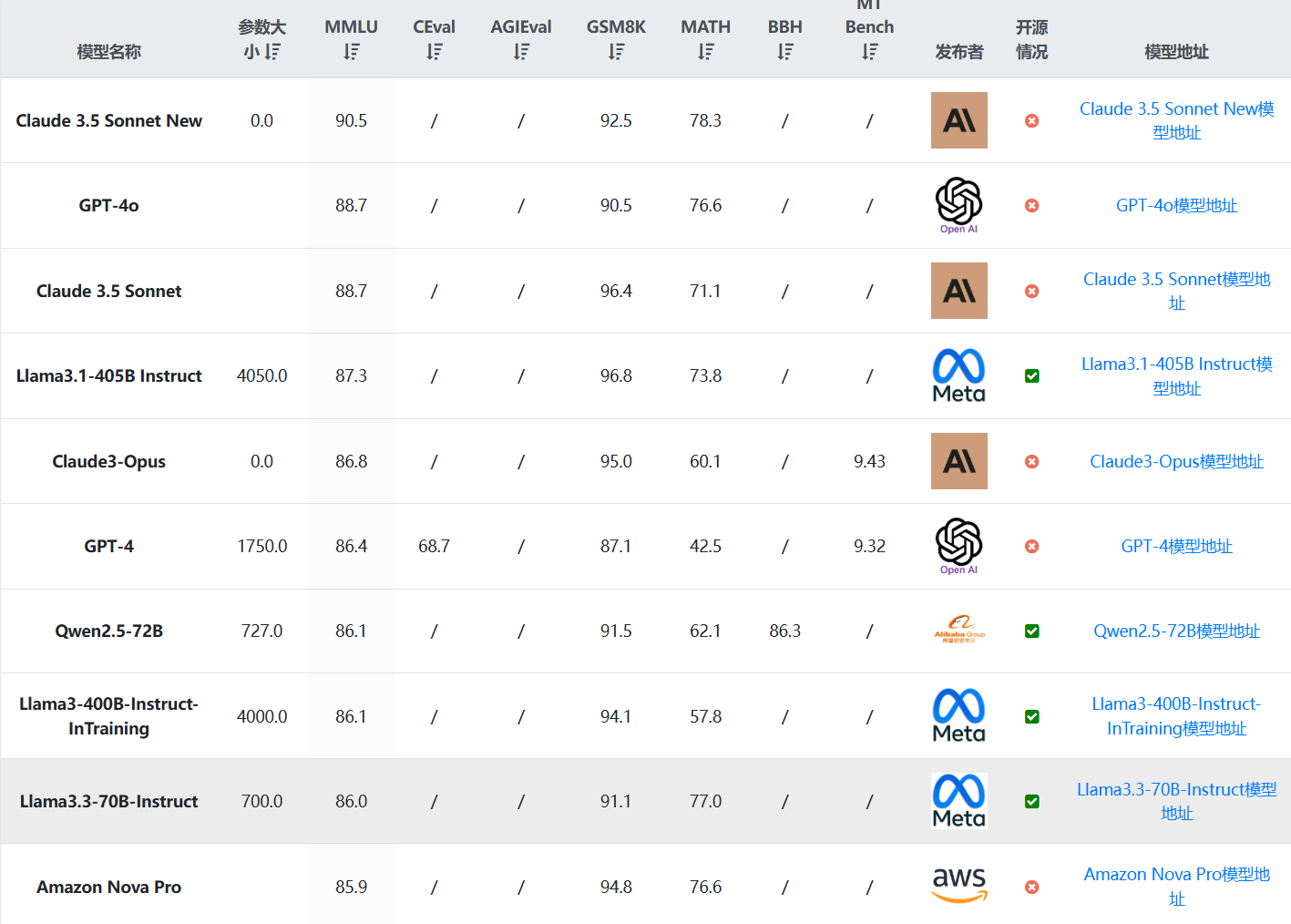
腾讯发布了一个全新的大模型Hunyuan Turbo S:号称评测效果超过GTP-4o和DeepSeek V3等模型,但没有开源或者放开使用
Hunyuan大模型是腾讯训练的大模型品牌名,2022年4月份,某中文语言理解能力排行榜第一名就出现了Hunyuan模型,在2022年11月,Hunyuan大模型就有了1万亿参数的规模,即HunYuan-NLP 1T大模型(比ChatGPT还早发布)。但是最近2年,这个系列的模型几乎没有出现在公众视野上。而昨天(2025年3月10日),Hunyuan官方在X平台上宣布了旗下最新的Hunyuan Turbo S大模型,称其在多个评测基准上超越了GPT-4o的表现。