
截止目前为止最大的国产开源大模型发布:元象科技开源XVERSE-65B大模型,16K上下文,免费商用
国产大语言模型的开源领域一直是很多企业或者科研机构都在卷的领域。最早,智谱AI开源ChatGLM-6B之后,国产大模型的开源就开始不断发展。早期大模型开源的参数规模一直在60-70亿参数规模,随着后续阿里千问系列的140亿参数的模型开源以及智源340亿参数模型开源之后,元象科技开源650亿参数规模的大语言模型XVERSE-65B,将国产开源大模型的参数规模提高到新的台阶。
聚焦人工智能、大模型与深度学习的精选内容,涵盖技术解析、行业洞察和实践经验,帮助你快速掌握值得关注的AI资讯。
国产大语言模型的开源领域一直是很多企业或者科研机构都在卷的领域。最早,智谱AI开源ChatGLM-6B之后,国产大模型的开源就开始不断发展。早期大模型开源的参数规模一直在60-70亿参数规模,随着后续阿里千问系列的140亿参数的模型开源以及智源340亿参数模型开源之后,元象科技开源650亿参数规模的大语言模型XVERSE-65B,将国产开源大模型的参数规模提高到新的台阶。

M3系列芯片是苹果最新发布的芯片。也是当前苹果性能最好的芯片。由于苹果的统一内存架构以及它的超大内存,此前很多人发现可以使用苹果的电脑来运行大语言模型。尽管它的运行速度不如英伟达最先进的显卡,但是由于超大的内存(显存),它可以载入非常大规模的模型。而此次的M3芯片效果如何,本文做一个简单的分析。

在大语言模型的训练和应用中,计算精度是一个非常重要的概念,本文将详细解释关于大语言模型中FP32、FP16等精度概念,并说明为什么大语言模型的训练通常使用FP32精度。
Sebastian Raschka博士是一位深度学习和人工智能研究员、程序员、作者和教育者。他曾是威斯康星大学麦迪逊分校的统计学助理教授,专注于机器学习和深度学习研究。然而,他在2023年辞职,全职投入到他在2022年加入的Lightning AI创业公司,担任首席AI教育者。本文是Sebastian Raschka博士最新的2023年AI进展总结的翻译,大家参考。
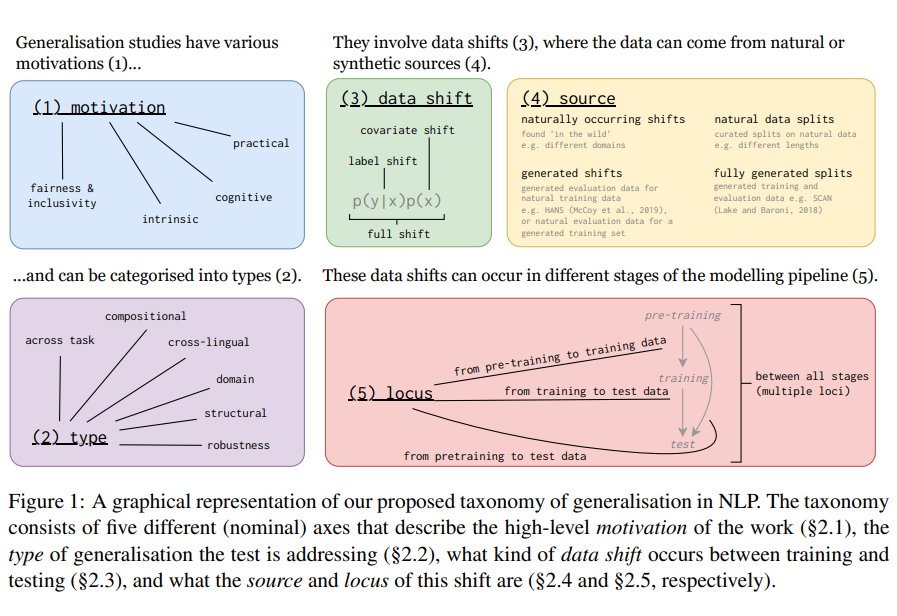
关于什么是好的泛化、存在哪些类型的泛化以及在不同的场景中哪些应该被优先考虑,人们对此了解甚少且意见不一。而MetaAI等机构的研究人员最近发布了一篇关于大模型泛化能力的综述,详细总结了大模型泛化能力的分类等。本篇论文详细总结一下大模型的泛化能力分类以及什么样的泛化是未来的中的重点等问题。

大模型应用中一个非常重要的问题就是大模型的响应速度。尤其是作为聊天应用来说,在用户输入之后,大模型可以在多短的时间内给出回应对于用户体验来说影响巨大。这里有2个问题经常会被大家所关注,一个是大模型每秒输出多少个tokens就可以满足用户的日常聊天使用,另一个问题是单张显卡最多可以支撑多少个用户的聊天需求。在前几天的vllm meetup上,贾扬清给出了一些讨论,他认为我们目前可能高估了大模型的聊天应用成本。
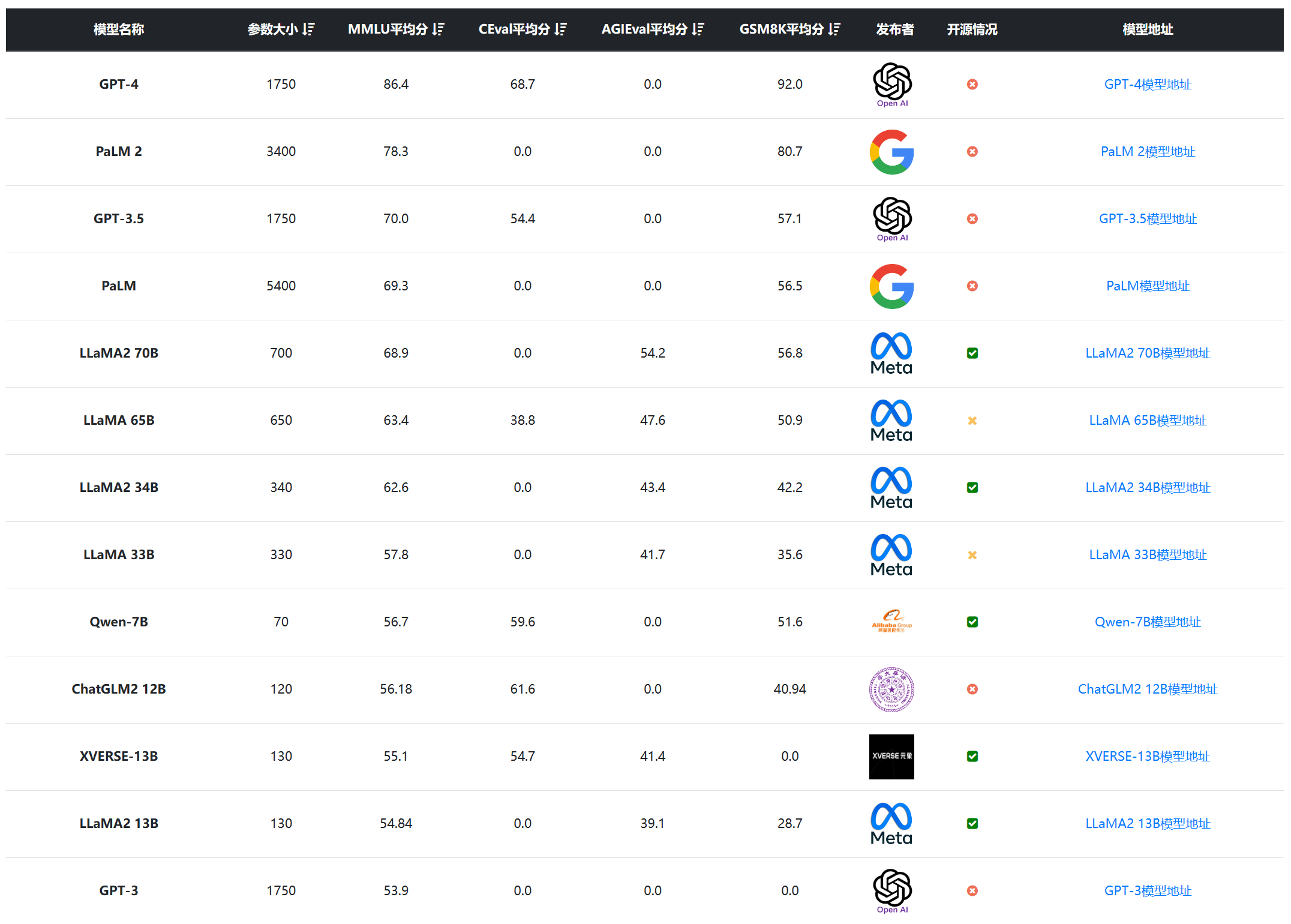
随着各种AI模型的快速发展,选择合适的模型成为了研究和开发的一大挑战。最近一段时间,国产模型不断涌现,让人应接不暇。尽管开源的繁荣提供了更多的选择,实际上也造成了选型的困难,尽管业界提供了很多评测基准,但是,**很多模型在公布的评测结果中对比的模型基准和选择的测试基准都很少,甚至只选择对自己有利的结果**。为了更加方便大家对比相关的结果,DataLearner上线了大模型评测综合排行对比表,给大家提供一个更加清晰的对比结果。我们主要关注的是国内开源大模型和一些全球主流模型的对比结果。
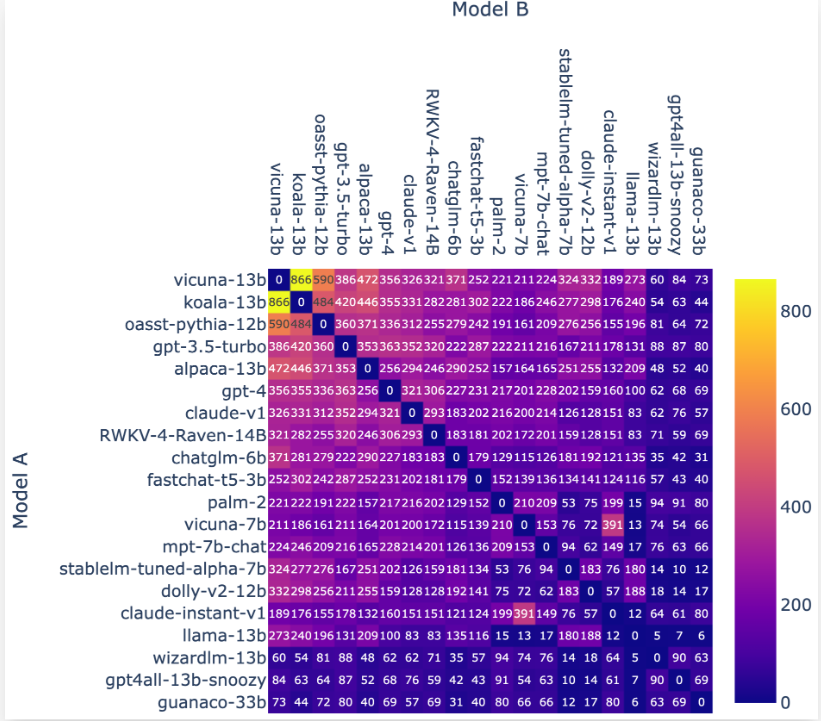
LM-SYS全称Large Model Systems Organization,是由加利福尼亚大学伯克利分校的学生和教师与加州大学圣地亚哥分校以及卡内基梅隆大学合作共同创立的开放式研究组织。该团队在2023年3月份成立,目前的工作是建立大模型的系统,是聊天机器人Vicuna的发布团队。今天开源 了包含3.3万包含真实人类偏好的对话数据集和3000条专家标注的对话数据集:Chatbot Arena Conversation Dataset和MT-bench人工注释对话数据集。

OpenAI最新发布了GPT-3.5-Turbo-Instruct,这是一款强大的指令遵循大模型。尽管官方没有发布官方博客介绍,但我们将在本文中详细探讨这一模型的特点以及其在人工智能领域的价值。
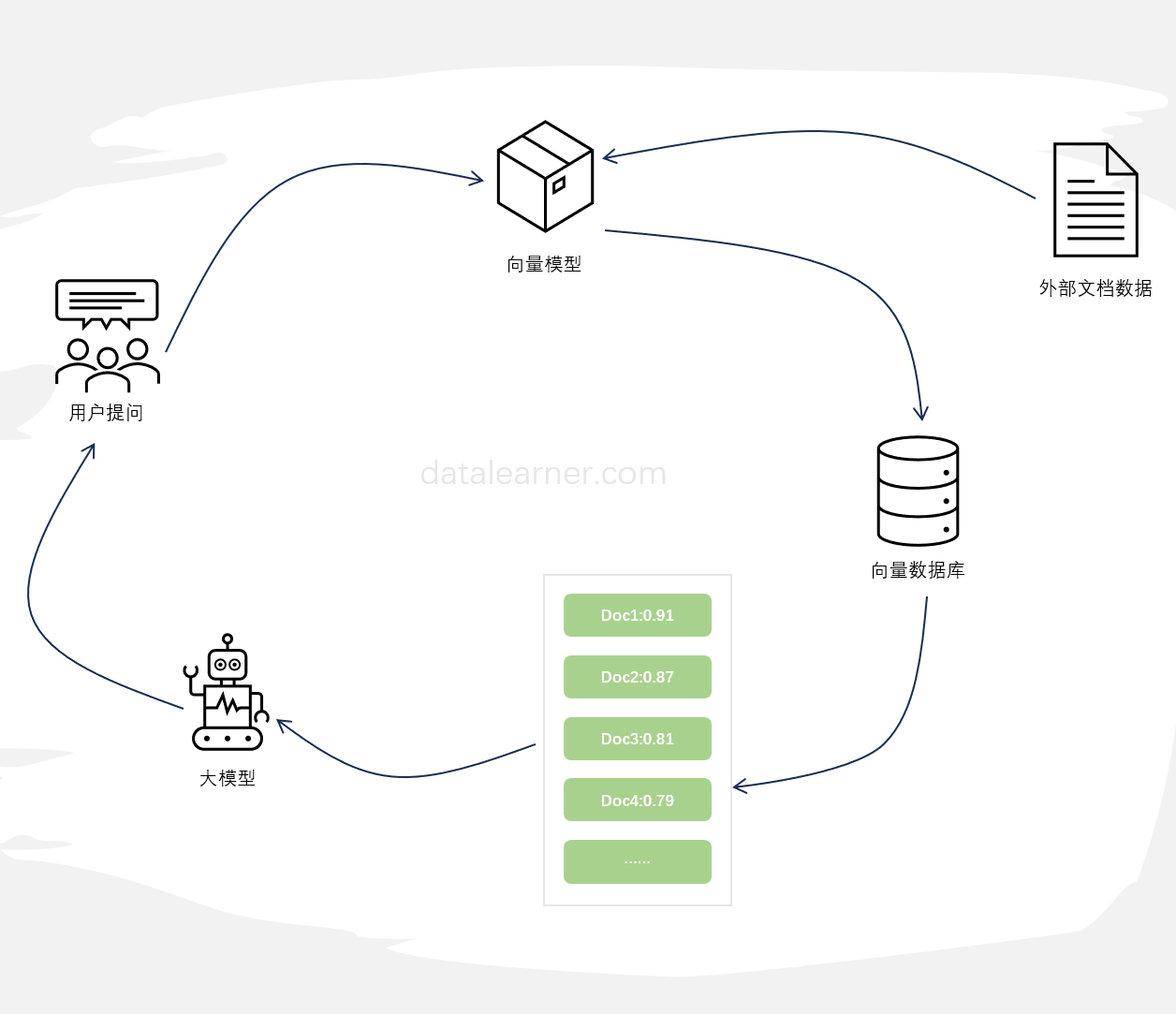
检索增强生成(Retrieval-augmented generation,RAG)是一种将外部知识检索与大型语言模型生成相结合的方法,通常用于问答系统。当前使用大模型基于外部知识检索结果进行问答是当前大模型与外部知识结合最典型的方式,也是检索增强生成最新的应用。然而,近期的研究表明,这种方式并不总是最佳选择,特别是当检索到的文档数量较多时,这种方式很容易出现回答不准确的情况。为此,LangChain最新推出了LongContextReorder,推出了一种新思路解决这个问题。

大模型的长输入在很多场景下都有非常重要的应用,如代码生成、故事续写、文本摘要等场景,支撑更长的输入通常意味着更好的结果。昨天,斯坦福大学、加州伯克利大学和Samaya AI的研究人员联合发布的一个论文中有一个非常有意思的发现:当相关信息出现在输入上下文的开始或结束时,大模型的性能通常最高,而当大模型必须访问长上下文中间的相关信息时,性能显著下降。本文将简单介绍一下这个现象。
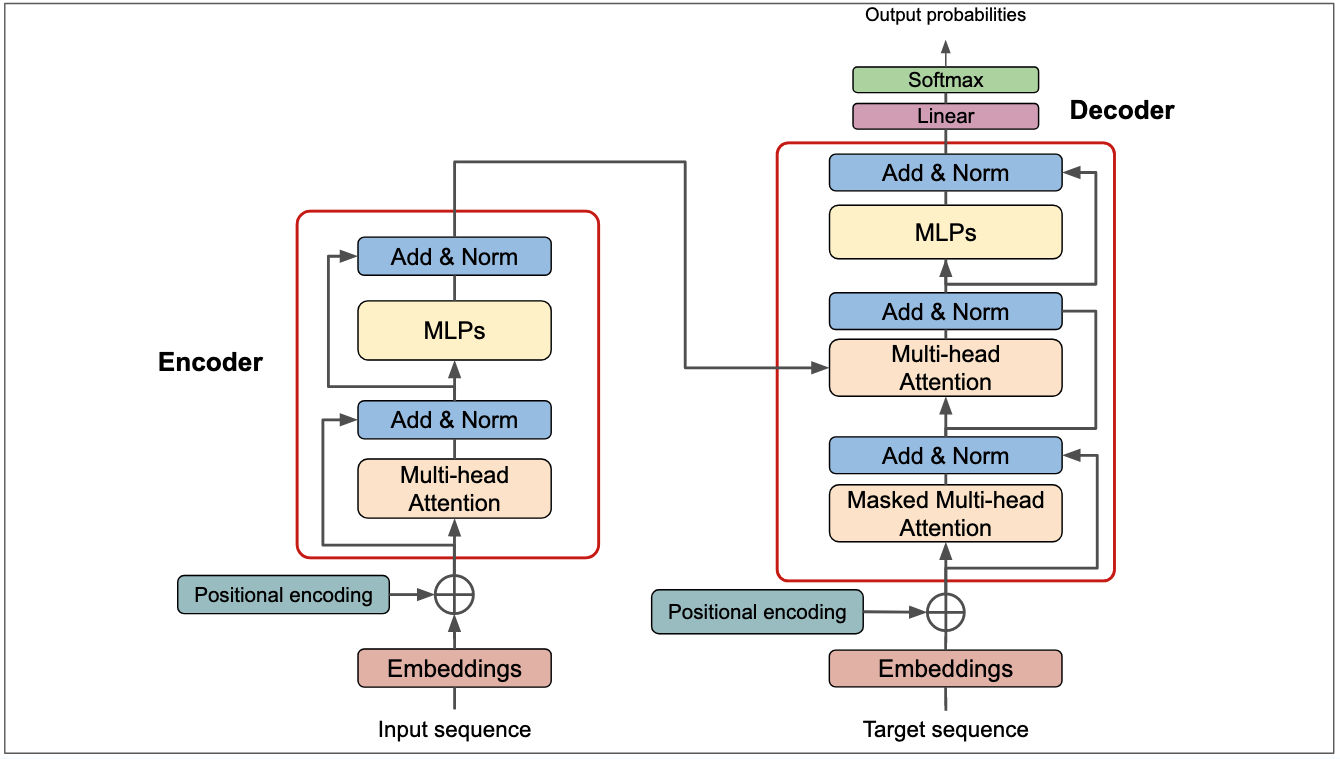
CMU的工程人工智能硕士学位的研究生Jean de Nyandwi近期发表了一篇博客,详细介绍了当前大语言模型主流架构Transformer的历史发展和当前现状。这篇博客非常长,超过了1万字,20多个图,涵盖了Transformer之前的架构和发展。此外,这篇长篇介绍里面的公式内容并不多,所以对于害怕数学的童鞋来说也是十分不错。本文是其翻译版本,欢迎大家仔细学习。

在当今的人工智能领域,大型语言模型(LLM)已成为备受瞩目的研究方向之一。它们能够理解和生成人类语言,为各种自然语言处理任务提供强大的能力。然而,这些模型的训练不仅仅是将数据输入神经网络,还包括一个复杂的管线,其中包括预训练、监督微调和对齐三个关键步骤。本文将详细介绍这三个步骤,特别关注强化学习与人类反馈(RLHF)的作用和重要性。
百川智能是前搜狗创始人王小川创立的一个大模型创业公司,主要的目标是提供大模型底座来提供各种服务。虽然成立很晚(在2023年4月份成立),但是三个月后便发布开源了Baichuan系列开源模型,并上架了Baichun-53B的大模型聊天服务。这些模型受到了广泛的关注和很高的平均。而2个月后,百川智能再次开源第二代baichuan系列大模型,其能力提升明显。

大模型对显卡资源的消耗是很大的。但是,具体每个模型消耗多少显存,需要多少资源大模型才能比较好的运行是很多人关心的问题。此前,DataLearner曾经从理论上给出了大模型显存需求的估算逻辑,详细说明了大模型在预训练阶段、微调阶段和推理阶段所需的显存资源估计,而HuggingFace的官方库Accelerate直接推出了一个在线大模型显存消耗资源估算工具Model Memory Calculator,直接可以估算在HuggingFace上托管的模型的显存需求。

当前的大语言模型主要是预训练大模型,在大规模无监督数据上训练之后,再经过有监督微调和对齐之后就可以完成很多任务。尽管如此,面对垂直领域的应用,大模型依然需要微调才能获得更好地应用结果。而大模型的微调有很多方式,包括指令微调、有监督微调、提示工程等。其中,指令微调(Instruction Tuning)作为改进模型可控性最重要的一类方法,缺少深入的研究。浙江大学研究人员联合Shannon AI等单位发布了一篇最新的关于指令微调的综述,详细描述指令微调的各方面内容。

大语言模型(Large Language Model,LLM)已经在很多领域都产生了巨大的影响。但是其中最为大家所期待的功能之一就是基于idea生成PPT、Word文档等。此前微软Office Copilot已经吸引了很多人的关注,但目前依然没有开放。而今天DataLearnerAI发现了一个类似的产品,来自洛杉矶初创企业Gamma的产品目前已经支持基于文本生成PPT、Word和网页应用了,本文带大家简单体验一下这个产品。

据传,Meta公司即将推出一款名为Code LLaMA的开源AI模型,用于生成编程代码。这一新模型被视为与OpenAI的Codex模型竞争的产品,并建立在Meta最近发布的LLaMA 2上。以下是关于这一新技术的详细分析。

随着近年来GPT-3、ChatGPT等大模型的兴起,高质量的数据集在模型训练中扮演着越来越重要的角色。但是当前领先的预训练模型使用的数据集细节往往不公开,开源数据的匮乏制约着研究社区的进一步发展。特别是大规模中文数据集十分缺乏,对中文大模型以及业界模型的中文支持都有很大的影响。此次,上海人工智能实验室发布的这个数据集包含了丰富的中文,对于大模型的中文能力提升十分有价值。

当谈及人工智能的巨大进步,大模型的崛起无疑是其中的一个重要里程碑。这些大模型,如GPT-3,已经展现出令人惊叹的语言生成和理解能力,但是为了让它们在特定任务上发挥最佳性能,大模型微调(Fine-tuning)是一种非常优秀的方法。微调是一种将预训练的大型模型进一步优化,以适应特定任务或领域的过程。但微调并不是很简单,今天吴恩达联合Lamini推出了全新的大模型微调短课《Finetuning Large Language Models》。

OpenAI在2023年8月份发布了GPT-3.5的微调接口,并表示会在2023年秋天开放16K的gpt-3.5-turbo-16k模型和GPT-4的微调(参考:[重磅!GPT-3.5可以微调了!OpenAI发布GPT-3.5 Turbo微调接口](https://www.datalearner.com/blog/1051692752268726 "重磅!GPT-3.5可以微调了!OpenAI发布GPT-3.5 Turbo微调接口"))。然而,微调并不是一个简单的问题,如何对大模型微调以及如果微调出现问题

SQLCoder 是 Defog 团队推出的一款前沿的语言模型,专门用于将自然语言问题转化为 SQL 查询。这是一个拥有150亿参数的模型,其性能略微超过了 gpt-3.5-turbo 在自然语言到 SQL 生成任务上,并且显著地超越了所有流行的开源模型。更令人震惊的是,尽管 SQLCoder 的大小只有 text-davinci-003 的十分之一,但其性能却远超后者。

开源大语言模型的发展非常迅速,其强大的能力也吸引了很多人的尝试与体验。尽管预训练大语言模型的使用并不复杂,但是,因为其对GPU资源的消耗很大,导致很多人并不能很好地运行加载模型,也做了很多浪费时间的工作。其中一个比较的的问题就是很多人并不知道自己的显卡支持多大参数规模的模型运行。本文将针对这个问题做一个非常简单的介绍和估算。

XVERSE-13B是元象开源的一个大语言模型,发布一周后就登顶HuggingFace流行趋势榜。该模型最大的特点是支持多语言,其中文和英文水平都十分优异,在评测结果上超过了Baichuan-13B,与ChatGLM2-12B差不多,不过ChatGLM2-12B是收费模型,而XVERSE-13B是免费商用授权!