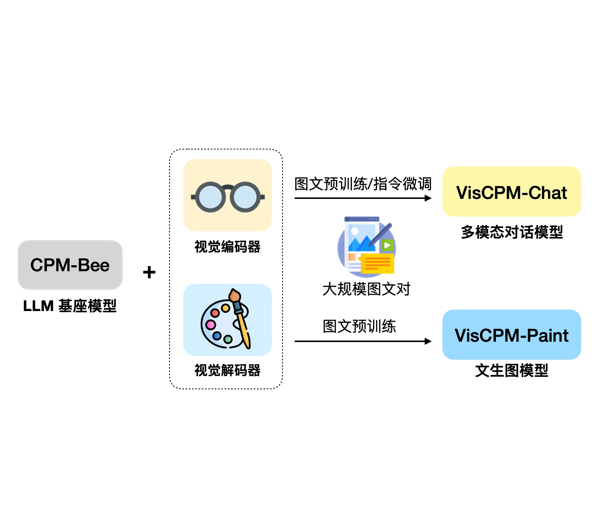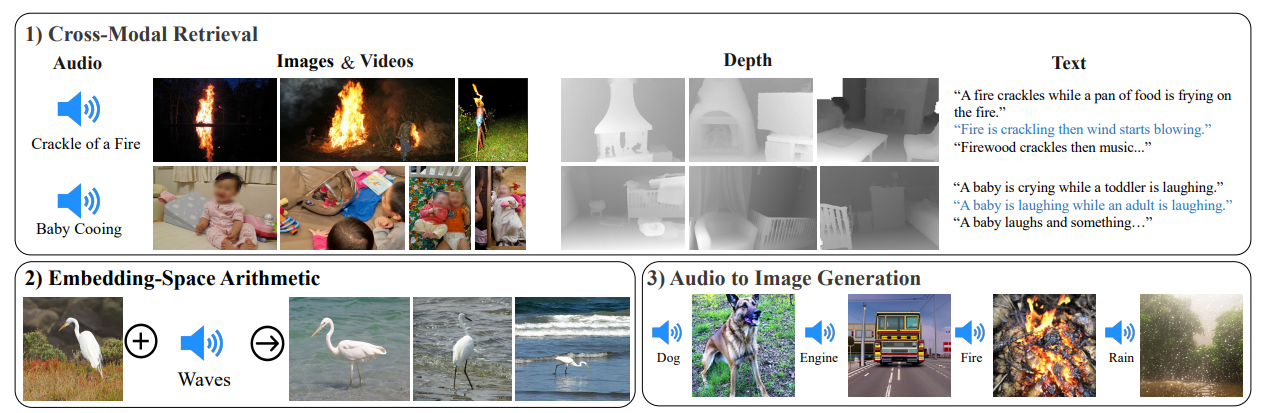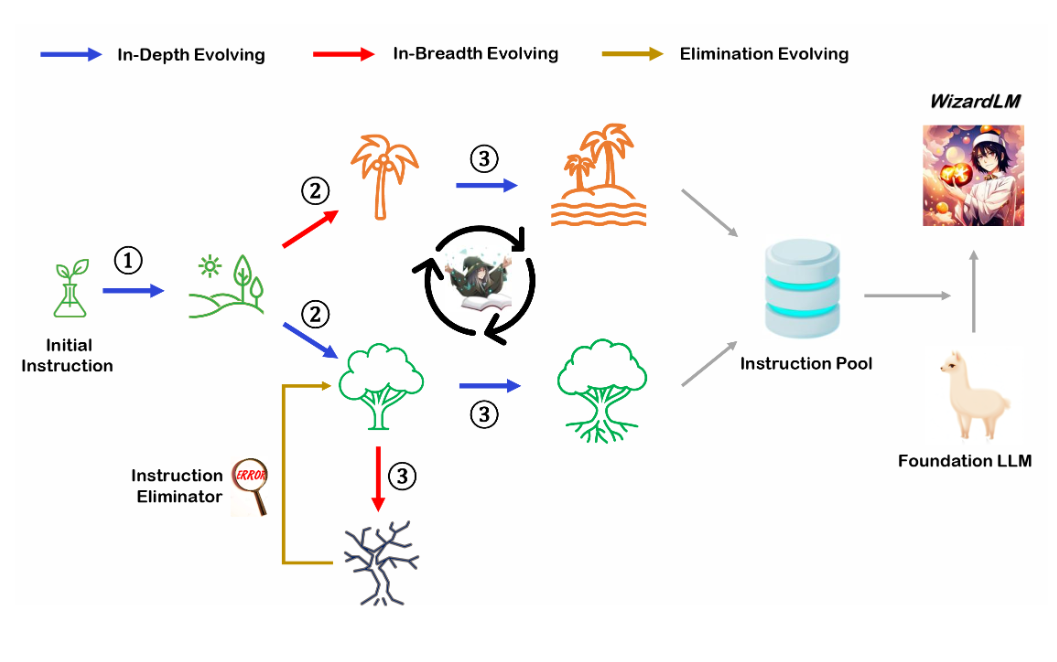
数学推理能力超过ChatGPT-3.5:微软与中科院研究人员合作最新的开源大模型WizardMath发布!开源模型第一,免费商用授权!
WizardLM是微软联合北京大学开源的一个大语言模型。此前,发布的WizardLM和WizardCoder都是业界开源领域最强的大模型。其中,前者是针对指令优化的大模型,而后者则是针对编程优化的大模型。而此次WizardMath则是他们发布的第三个大模型系列,主要是针对数学推理优化的大模型。在GSM8K的评测上,WizardMath得分超过了ChatGPT-3.5、Claude Instant-1等闭源商业模型,得分十分逆天!