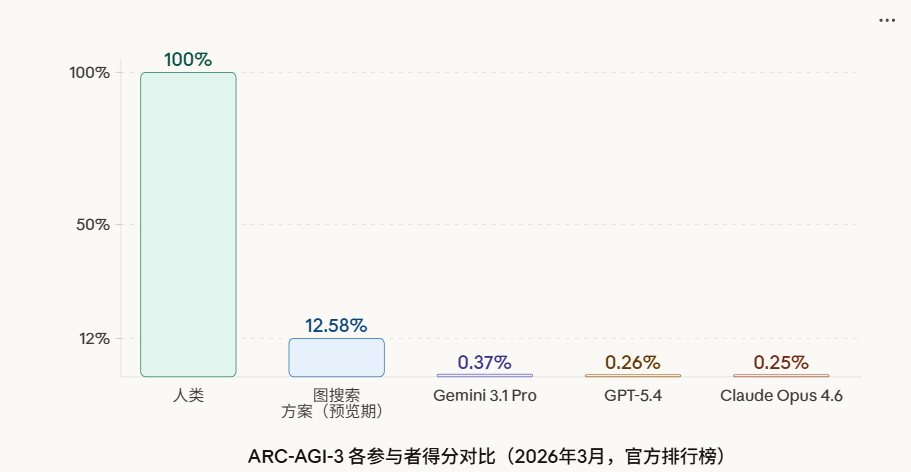
大模型ARC-AGI-3评测基准:首个交互式推理基准
ARC-AGI 系列基准由 ARC Prize Foundation 维护,长期被主要 AI 实验室和学术研究者作为衡量 AI 推理能力的参照。2026年3月25日,该系列第三代版本 ARC-AGI-3 在旧金山 Y Combinator 正式发布,这是自2019年该系列初次推出以来,格式层面改动最大的一次迭代。
聚焦人工智能、大模型与深度学习的精选内容,涵盖技术解析、行业洞察和实践经验,帮助你快速掌握值得关注的AI资讯。
ARC-AGI 系列基准由 ARC Prize Foundation 维护,长期被主要 AI 实验室和学术研究者作为衡量 AI 推理能力的参照。2026年3月25日,该系列第三代版本 ARC-AGI-3 在旧金山 Y Combinator 正式发布,这是自2019年该系列初次推出以来,格式层面改动最大的一次迭代。

几个小时前,Anthropic发生一起信息泄露事件,还没来得及官宣,自家最强新模型就被”意外”公之于众。新模型的能力据称远超Opus 4.6!
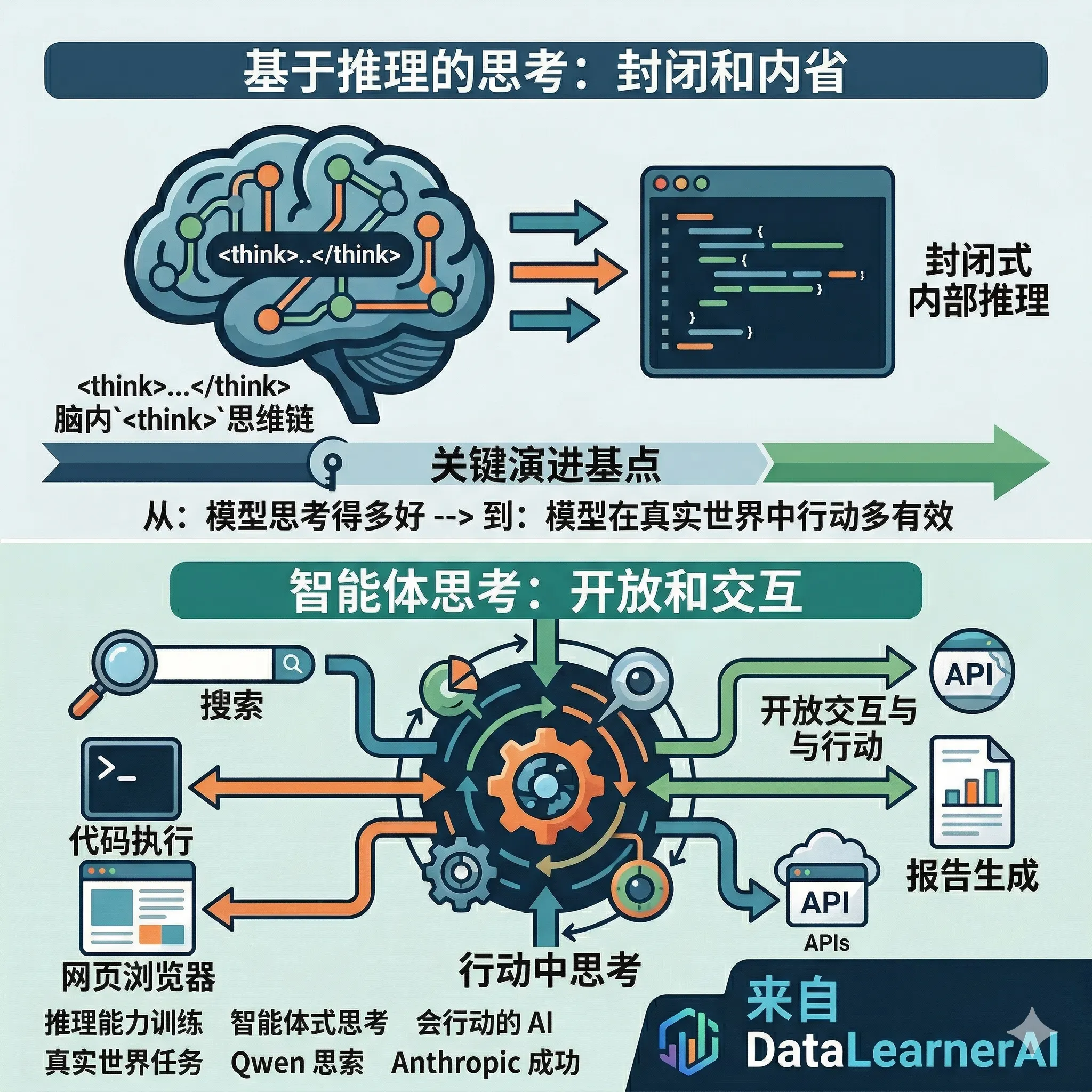
unyang 是前 Qwen(通义千问)负责人,前段时间他的离职造成了许多人的关注。不过他并未沉寂,就在刚才,Junyang 发表了一篇关于如何训练大模型推理能力、以及未来大模型推理能力训练应该走向何方的深度讨论。

SWE-bench Multilingual 是 SWE-bench 基准系列的扩展版本。该基准用于评估大语言模型在软件工程任务上的表现,覆盖多种编程语言。数据集包含 300 个从真实 GitHub 问题与对应拉取请求中提取的任务,涉及 42 个仓库和 9 种编程语言。模型接收问题描述与仓库快照后,需生成代码补丁,并通过失败到通过(F2P)和通过到通过(P2P)测试套件进行验证。
PinchBench 是 Kilo Code 团队开发的开源基准测试系统,用于评估大型语言模型作为 OpenClaw 编码代理核心的表现。该系统运行一组固定真实世界任务,计算代理的任务完成成功率,同时记录执行速度和成本。所有结果通过公开排行榜 https://pinchbench.com 显示,目前包含 50 个模型的 403 次运行记录,最新更新时间为 2026 年 3 月 18 日。基准测试的代码和任务定义全部开源在 GitHub(pinchbench/skill 仓库),任何开发者均可本地复现或添加
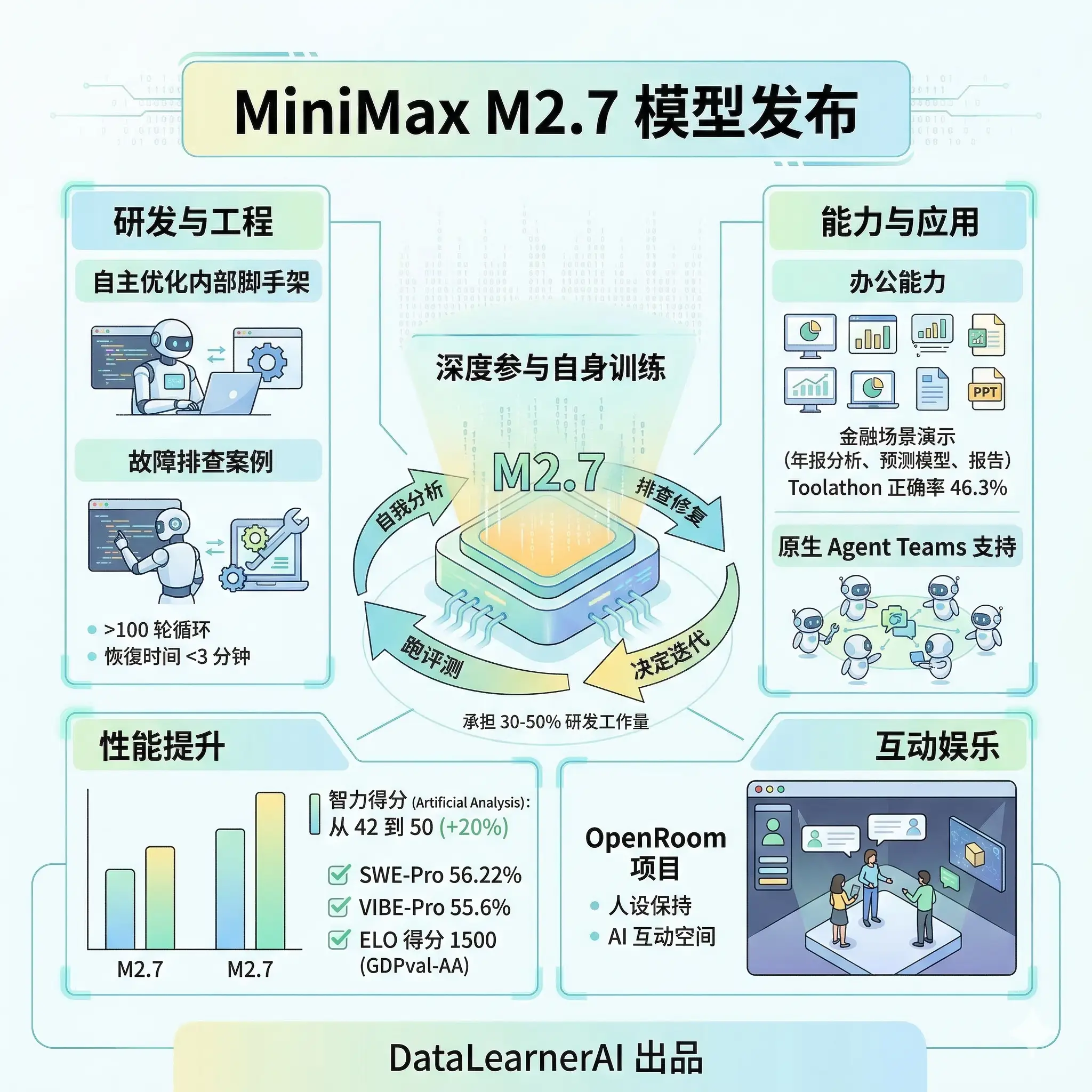
MiniMaxAI 刚刚发布了全新的 M2.7 模型,官方说本次发布的 M2.7 最大的特点是第一个深度参与迭代自身训练流程的模型,也就是说模型在训练过程中进行了自我分析并参与迭代。目前 M2.7 已经可以在官网使用,接口价格不变。不过该模型当前并未宣布开源,还不确定未来情况。

OSWorld 是一个用于测试 AI 代理在真实计算机环境中的基准。这些代理是能处理文字、图片等信息的 AI 系统。基准包括开放式任务,比如操作文件或使用软件。OSWorld Verified 是它的改进版,通过修复问题和提升运行方式,提供更准确的测试结果。它支持不同操作系统,如 Ubuntu、Windows 和 macOS,并允许 AI 通过互动学习来完成任务。

就在刚才,Grok官网出现了Grok 4.2 Beta版本,并且已经可以直接使用。即使是免费用户,目前看也可以使用至少8次的提问。

就在刚才,Moonshot AI(Kimi 团队)推出了 Kimi Claw(目前为 Beta 版)。这项服务让普通用户无需本地安装或维护服务器,就能快速获得一个类似 OpenClaw 的云端 AI 助手,随时在线、具备长期记忆和实际执行能力。
AIME 2026 是基于美国数学邀请赛(American Invitational Mathematics Examination)2026 年问题的评测基准,用于评估大语言模型在高中水平数学推理方面的表现。该基准包含 15 个问题,覆盖代数、几何、数论和组合数学等领域。模型通过生成答案并与标准答案比较来计算准确率。

就在刚才,很多人发现DeepSeek官网已经更新了模型,虽然不确定是DeepSeek-V4,但是目前可以肯定,这不是之前公布的DeepSeek-V3.2而是一个全新的模型。为此,DataLearnerAI实测正式,这个模型的确并非此前的版本。

就在刚刚,阿里宣布发布Qwen-Image-2.O模型,该模型是Qwen Image系列的最新版本,这个模型综合了此前的文本生成图片和图片编辑的能力,在文本渲染、生成PPT图片方面大幅提升。不过相比较之前的Qwen Image系列,该版本的模型并没有开源,目前在官网可以免费使用。

AA-LCR 是由独立 AI 评测机构 Artificial Analysis 开发的基准测试集,旨在真实模拟知识工作者(如分析师、研究员、律师)处理海量文档的场景。
OSWorld(Open Source World)是首个真正基于真实操作系统环境的多模态Agent评测平台。它不同于传统的模拟环境(如MiniWoB或WebArena),而是直接在完整的Ubuntu、Windows和macOS系统中运行,让AI代理通过截图观察、鼠标键盘操作来完成任务。
OpenAI在2025年9月推出的GDPval基准,将焦点转向“具有经济价值的真实任务”,而第三方独立机构Artificial Analysis在此基础上开发的GDPval-AA,进一步引入了agentic(代理)能力评估和ELO排行榜,成为当前最受关注的“实用性”评测基准之一。

OpenAI 发布了一个全新的帮助企业构建AI Agent的平台:OpenAI Frontier。这个平台不再是一个强大的模型或者单体应用,而是一种“基础设施能力”,是旨在改变企业如何使用 AI 的平台。
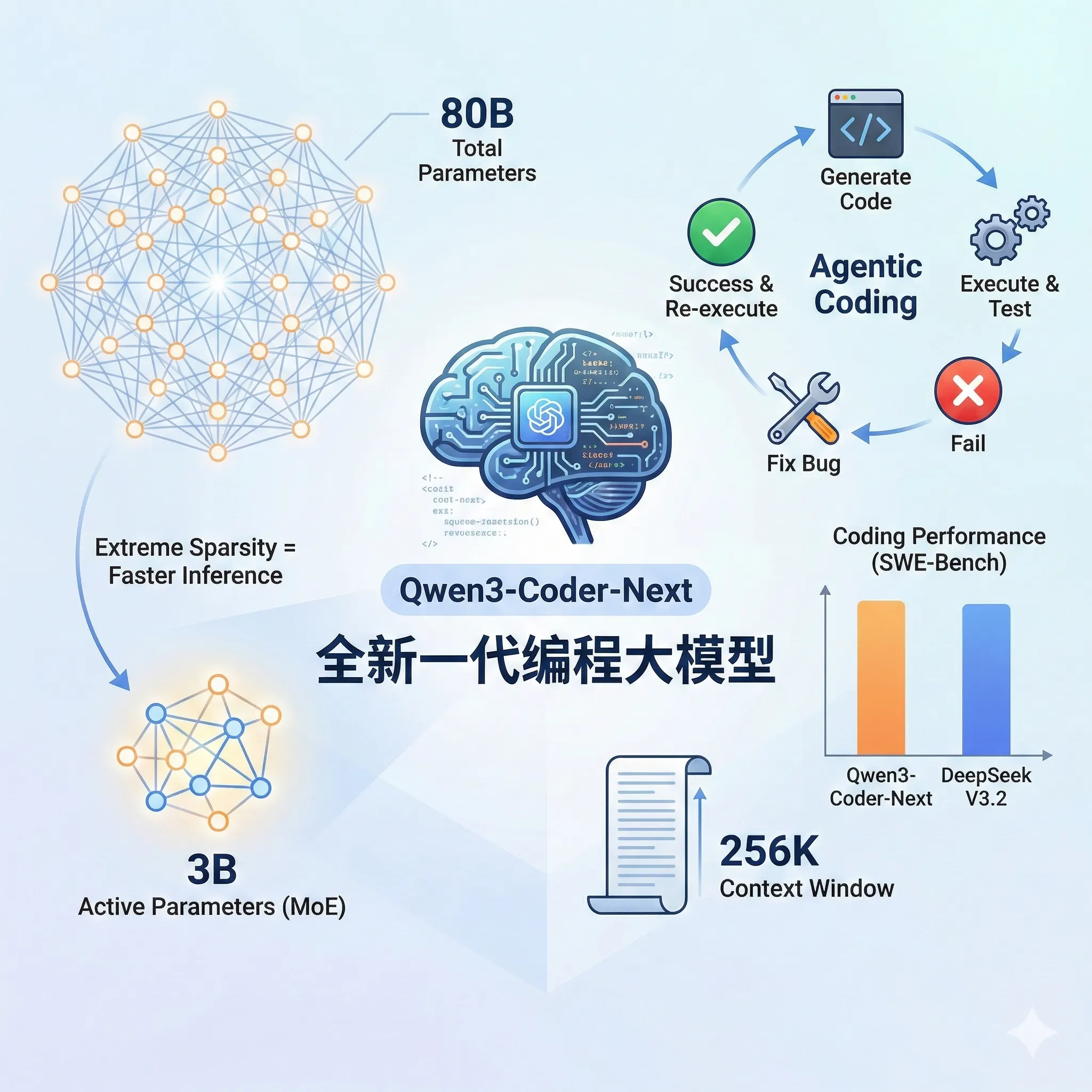
阿里开源了全新一代编程大模型Qwen3-Coder-Next,该模型是基于Qwen3-Next-80B-A3B-Base模型后训练得到,总参数规模800亿,激活参数仅30亿。也就是说,这个模型的推理速度基本和3B这种小规模参数差不多,但是它的评测结果,特别是在编程方面的评测与DeepSeek V3.2的水平差不多。
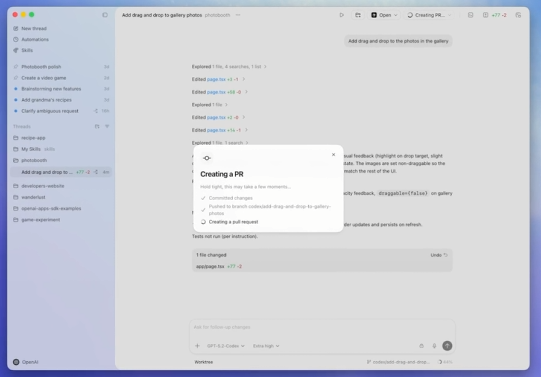
OpenAI 刚刚(2026年2月2日)正式推出了 Codex App (macOS 版)。这款产品被定位为“智能体指挥中心”(A Command Center for Agents),标志着 Codex 从单纯的代码生成工具演进为能够独立执行复杂、长周期任务的开发协作平台。

Stepfun AI(阶跃星辰)正式发布了其最新开源基础模型Step-3.5-Flash。这款模型以“快速、锐利、可靠的agentic智能”为核心设计,采用稀疏混合专家(Sparse MoE)架构,总参数量196B,但每token仅激活11B参数,实现高效推理的同时保持前沿级性能。它支持256K超长上下文、多token并行预测(MTP-3),推理速度可达100-300 token/s,甚至在编码任务中峰值350 token/s。

Moltbook 是一个创新的社交网络平台,专为 AI Agent 设计,在这里它们可以分享内容、参与讨论,并进行投票和点赞活动。人类用户仅限于观察者角色,无法直接互动。这个平台类似于 Reddit 的结构,允许 AI Agent 创建子社区(称为 submolt)、发布帖子、评论,并通过 API 接口进行操作,而不是视觉图形界面。

Andrej Karpathy预测2026年AI将主导软件编码工作流,带来巨大效率提升,但可能引发低质代码泛滥(slopacolypse)。Anthropic的Boris Cherny以Claude Code团队实践回应,展示近100% AI生成代码、通用工程师招聘策略,以及通过模型迭代有效控制质量问题。

2026年1月27日,月之暗面(Moonshot AI)发布新一代模型Kimi K2.5。根据官方说明,这是Kimi K2的后续版本,目前已通过Kimi.com网页端和App向用户推送。该模型同步上线Kimi API开放平台及编程助手Kimi Code,模型权重与相关代码也在Hugging Face开源。

本文整理了 Andrej Karpathy 在 2025 年底关于 AI Agent 编程的核心观点。基于其使用 Claude Code 等大模型的真实工程经验,Karpathy 认为软件工程正从“手动编码”转向“由 AI Agent 执行、人类定义目标与约束”的新范式。文章同时分析了 AI Agent 在效率提升之外带来的工程风险、技能退化与内容质量问题,并指出 2026 年将是行业系统性消化 AI Agent 能力的关键一年。

最近这几天,如果你的 X (Twitter) 首页被 Clawdbot 刷屏了,不用惊讶,主要是太火了。但是这个软件的使用有一定门槛,而且争议比较大。X上有一位博主分享了他对这个东西的看法和使用经验,挺详细的,对于想了解Clawdbot是啥的,这个文章不错。大家看也可以从这个文章看到Clawdbot能做什么,和Cowork对比有啥优点和缺点