MistralAI可能即将发布新的大语言模型,Mistral Next悄悄登场Chat Arena!
MistralAI又悄悄地上线了另一个模型,即Mistral Next。相比之前的发布预训练种子引起大家猜测的方式,本次MistralAI又把模型发布玩出了花,他们没有公布任何信息,选择直接上架LM-SYS的大模型竞技场Chat Arena,让大家直接体验对比。
聚焦人工智能、大模型与深度学习的精选内容,涵盖技术解析、行业洞察和实践经验,帮助你快速掌握值得关注的AI资讯。
MistralAI又悄悄地上线了另一个模型,即Mistral Next。相比之前的发布预训练种子引起大家猜测的方式,本次MistralAI又把模型发布玩出了花,他们没有公布任何信息,选择直接上架LM-SYS的大模型竞技场Chat Arena,让大家直接体验对比。

盘古大模型是华为自研的大语言模型,基于华为的硬件和技术栈进行训练。此前一直被认为是国产技术占比很高的国产大模型。今天,华为开源了2个盘古大模型,分别是MoE架构的Pangu Pro MoE模型以及70亿参数规模的Pangu Embedded模型。
三个小时前,Sam Altam在推特上说明了OpenAI未来的大模型路线图。比较重磅的消息是即将在未来几周发布GPT-4.5,并且在几个月后发布GPT-5。
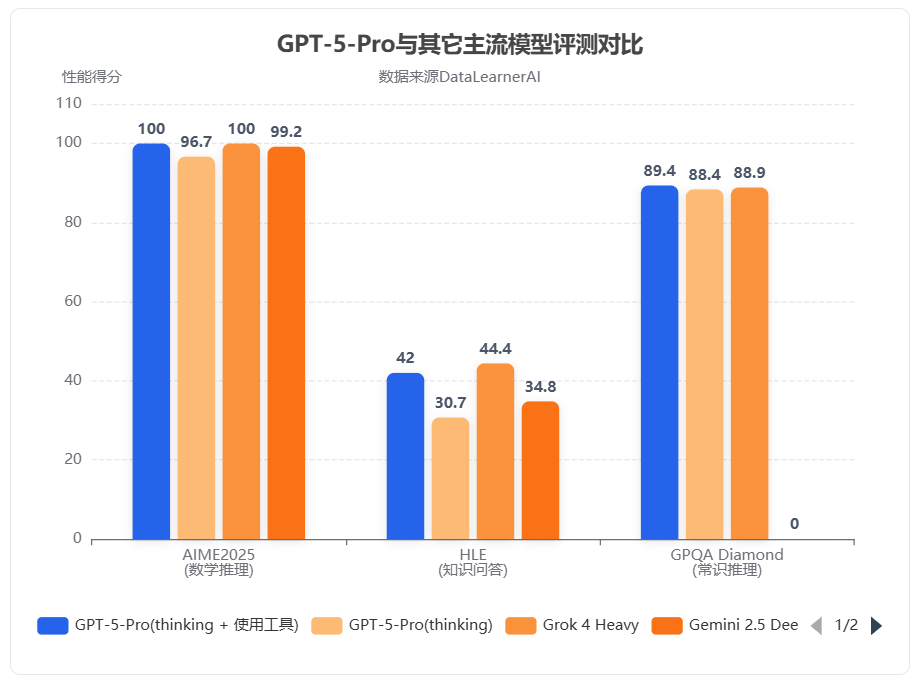
几个小时前,OpenAI发布了全新一代大模型GPT-5系列。本次发布的是一个全新的AI系统,而非一个单独的模型系列。GPT-5背后包含了5个不同的模型系列或者版本,分别是GPT-5-Pro、GPT-5、GPT-5-mini、GPT-5-nano和GPT-5-Chat。
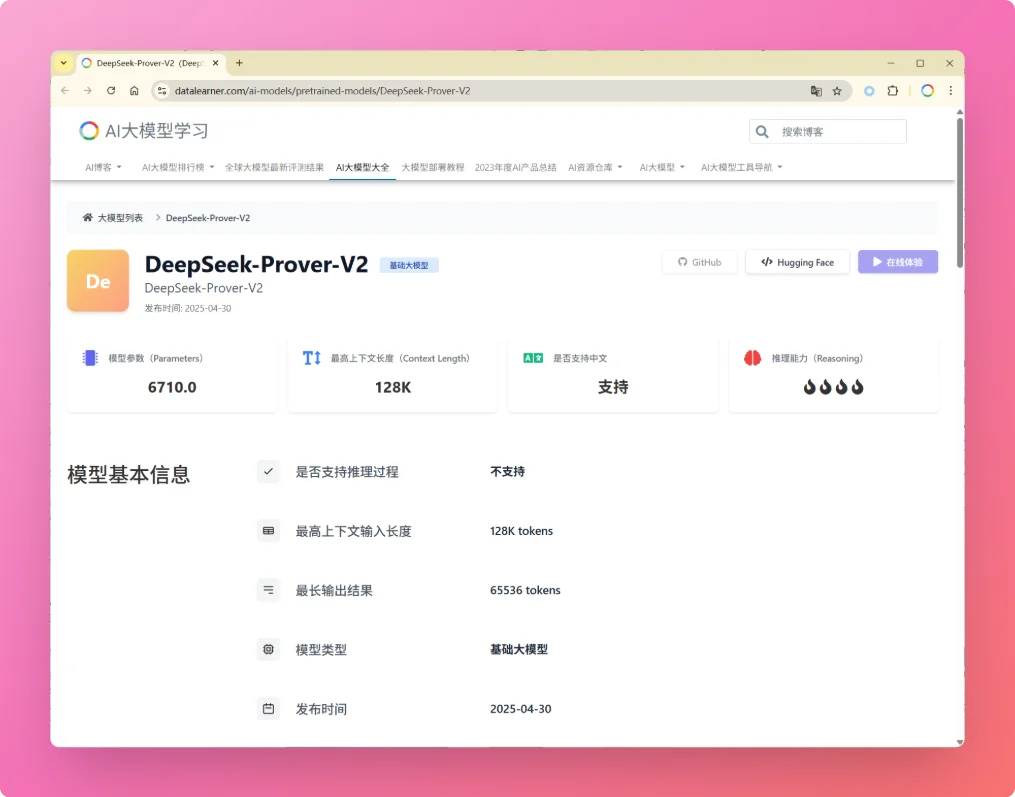
就在刚才,DeepSeek-AI发布了其新一代自动定理证明模型 **DeepSeek-Prover-V2**。尽管官方暂未公开详细报告,但从其前代模型 **DeepSeek-Prover-V1.5** 的技术细节,以及去年底发布的通用推理模型 DeepSeek-R1 的进展来看,V2 很可能在多个关键能力上取得了实质性提升。
Kiro 是一款AWS刚发布的、具有代理(agentic)能力的集成开发环境(IDE),它的目的是希望通过简化的开发者体验,帮助开发者从概念原型无缝过渡到生产级别的应用。它的核心理念是“规格驱动开发”(spec-driven development),以解决当前 AI 编程从有趣的原型到可靠的生产系统之间存在的鸿沟。
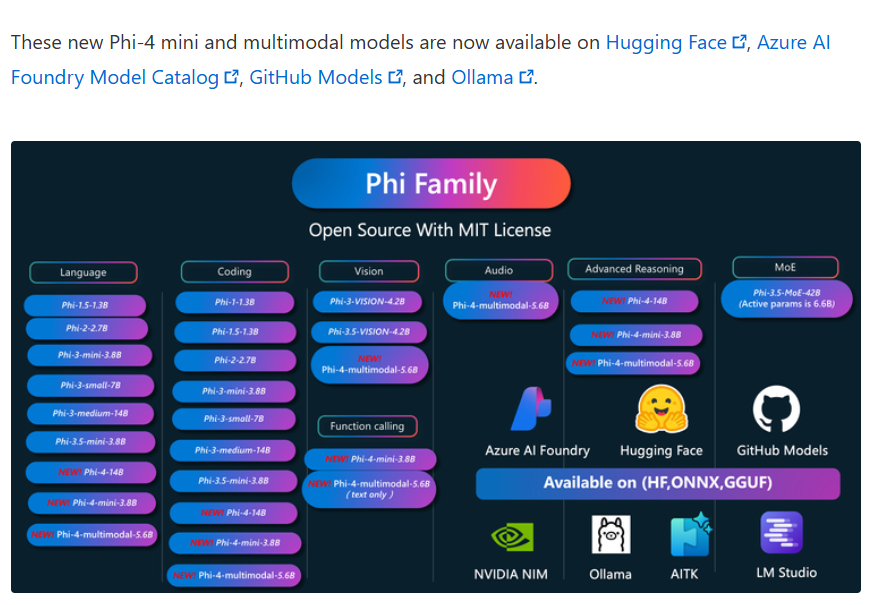
2025年2月27日,微软正式发布了其全新系列的大型语言模型——Phi-4系列。这一系列包含了三个创新性的模型:Phi-4-Mini、Phi-4-Multimodal和一款经过推理优化的Phi-4-Mini。此次发布的模型不仅在性能上展现出色,更在多模态能力与推理任务中实现了显著突破。其中,Phi-4-Multimodal是一个仅仅包含56亿参数规模的多模态大模型,但是支持文本、语音、图片的输入,十分强大。

GLM-4.1V-Thinking是智谱AI(Zhipu AI)与清华大学KEG实验室联合推出的多模态推理大模型。这款模型并非简单的版本迭代,而是通过一个以“推理为中心”的全新训练框架,旨在将多模态模型的能力从基础的视觉感知,推向更复杂的逻辑推理和问题解决层面。多模态理解能力接近720亿的Qwen2.5-VL-72B。
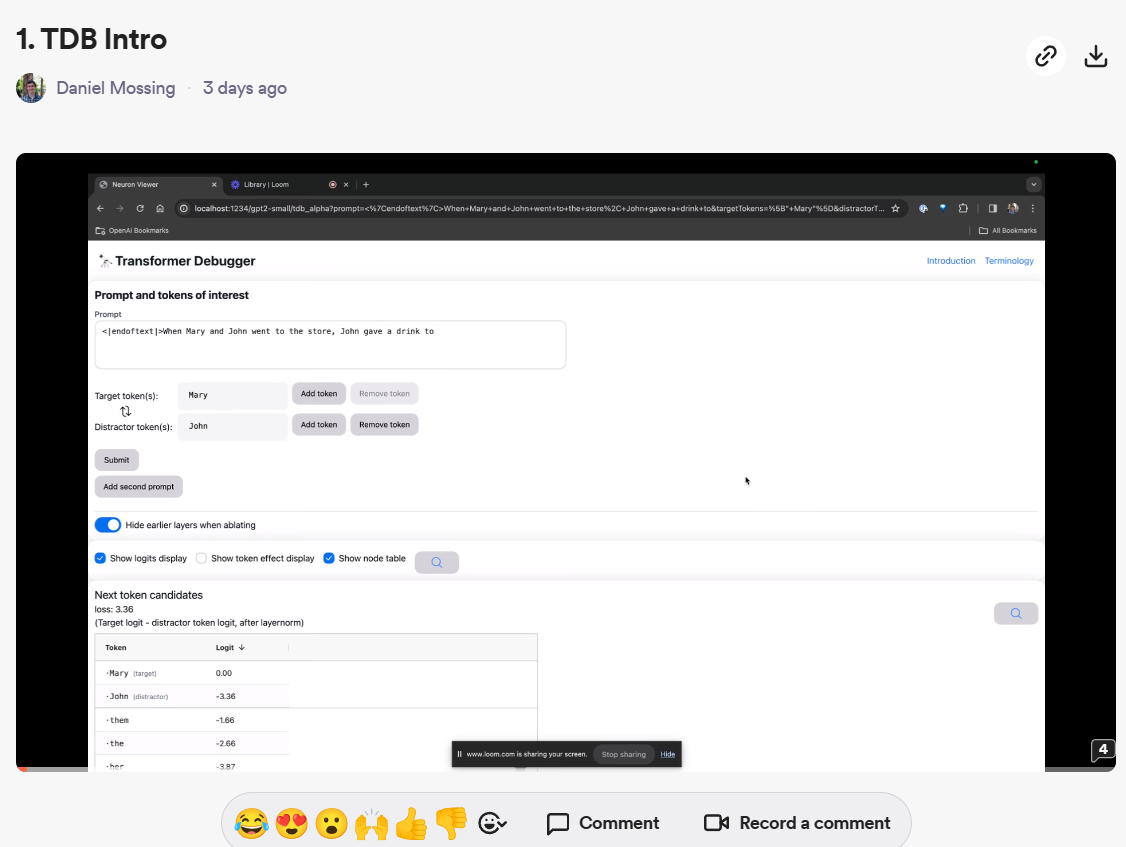
自从OpenAI转向盈利化运营之后,很少再开源自己的技术。但就在刚才,OpenAI开源了一个全新的大模型调测工具:Transformer Debugger。这个工具可以帮助开发者调测大模型的推理情况,帮助我们理解模型的输出并提供一定的解释支持。
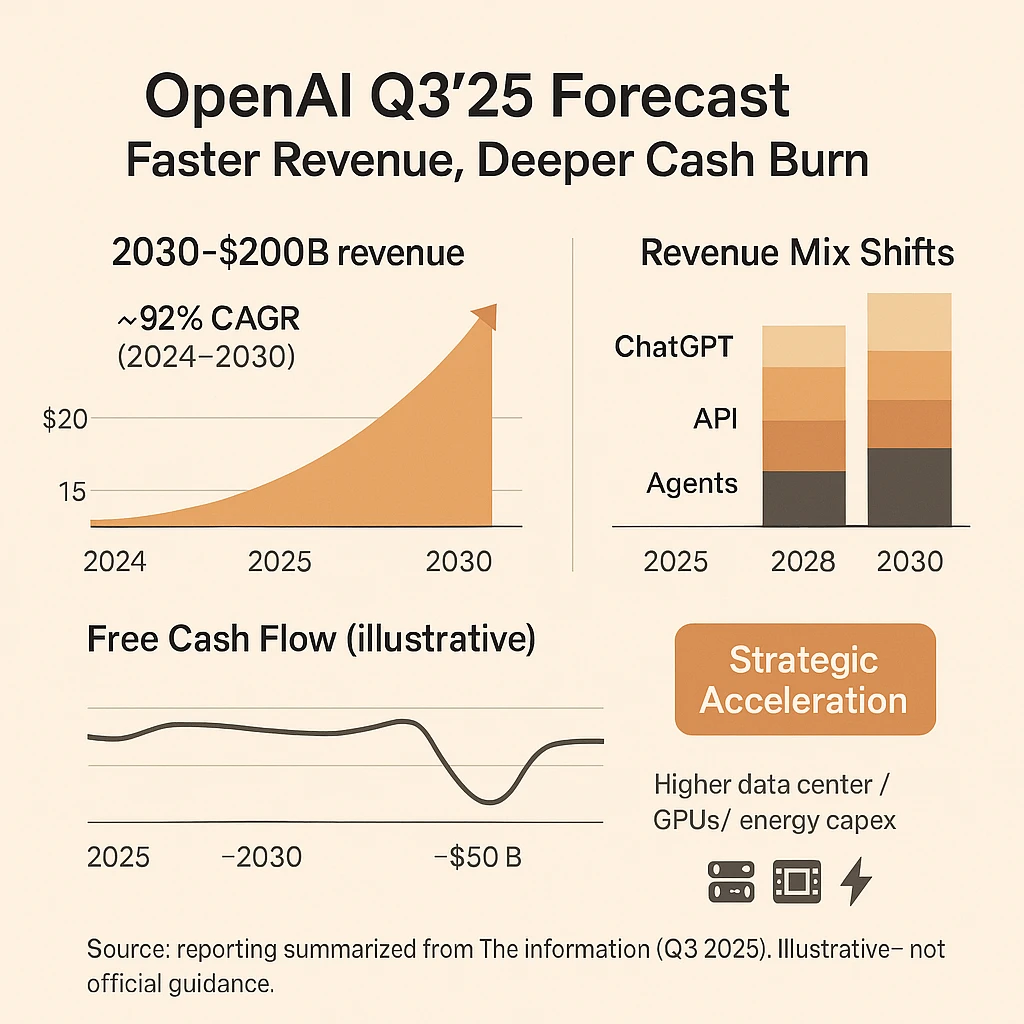
根据TheInformaiton的披露,近期OpenAI更新了他们最新财务预测(截至2025年第三季度)。这份收入预测展示了当前OpenAI的收入情况,并描绘了一幅引人注目的未来图景。与2025年第一季度OpenAI自己的预测相比,新数据不仅上调了收入预期,也揭示了公司因基础设施投入而面临的巨大现金消耗压力。本文将简单解读一下这份数据,包括OpenAI的收入情况,不同产品占比,如ChatGPT的比重等。

阿里巴巴的 Qwen Code 是一款开源的命令行 AI 工具,旨在提升开发者的编程效率,特别适用于处理大型代码库和复杂的开发任务。 2025年8月9日,阿里宣布提供每天2000次的免费Qwen Code服务,应该是满足大多数开发者的日常需求了。

OpenAI 正式发布了其最新模型 OpenAI o3-pro,这是其旗舰模型 o3 的专业增强版。o3-pro 专为需要“更长时间思考”的复杂任务而设计,其核心亮点在于极致的可靠性和准确性,尤其在数学、科学和编程等专业领域表现卓越。根据OpenAI引入的全新“4/4可靠性”评测标准,o3-pro 的性能远超前代,OpenAI官方强调o3-pro在处理高难度、高风险任务的能力上实现了质的飞跃。

就在刚才,Google宣布发布最新的图像生成和编辑大模型Gemini 2.5 Flash Image Preview。该模型就是最近火爆网络的Nana Banana背后真正的模型。该模型在图片生成和编辑方面目前是断层领先,效果非常好。
DALL·E3是OpenAI推出的文本生成图片服务,背后也是一个文生图大模型。此前,该模型只能通过对话的方式让模型生成图片结果。无法通过配置信息控制模型输出的效果,包括风格、比例等。而最新的截图显示,OpenAI可能即将推出DALL·E Controls功能,可以从不同的方面来控制图片生成的效果。

人工智能(AI)的通用智能(AGI)发展一直是研究领域的焦点。近期,由 ARC Prize 基金会推出并由 AI 研究者 François Chollet 联合发起的 ARC-AGI-2 评测基准,为衡量大模型在未知情境下的实时推理能力和学习效率提供了新的视角。

“Vibe Coding”(氛围编程)是一种新兴的编程范式,强调通过自然语言与人工智能(AI)协作开发软件。该概念由前 OpenAI 研究员 Andrej Karpathy 于 2025 年提出,旨在让开发者沉浸于创作氛围中,利用 AI 的能力,将自然语言描述转化为实际源代码,从而简化编程过程。

Mistral AI今天发布了其首个专注于推理能力的系列模型——**Magistral**。这次发布包含两个核心模型:旗舰模型`Magistral Medium`和已开源的`Magistral Small (24B)`。最引人注目的亮点是,Mistral展示了其自研的强化学习(RL)pipeline能够从头开始,仅通过RL训练就将基础模型的推理能力提升到业界顶尖水平,而无需依赖任何其他预先存在的推理模型进行数据蒸馏。这套技术栈非常强大!

DeepSeek AI团队重磅推出DeepSeek-OCR,该模型不仅在文档提取上达到了行业领先水平,更通过创新的视觉压缩技术,将长上下文处理效率提升了 10 倍以上。根据测算,在A100-40G的一个GPU上,它每天可以将20万页的文档图像数据转为Markdown文本!

短短两年间,AI技术的进步为软件工程带来了新的可能性。然而,这些模型在真实世界的软件工程任务中究竟能发挥多大的作用?它们能否通过完成实际的软件工程任务来赚取可观的收入?为了验证大模型解决真实任务的能力和水平,OpenAI发布了一个全新的大模型评测基准SWE-Lancer来评测大模型这方面的能力。

今日,QwenTeam 正式发布了全新一代多模态视觉语言模型 —— Qwen3-VL 系列。这是 Qwen 家族迄今为止最强大的视觉语言模型,在视觉感知、跨模态推理、长上下文理解、空间推理和智能代理交互等多个维度全面提升。旗舰开源模型 Qwen3-VL-235B-A22B 已经上线,并提供 Instruct 和 Thinking 两个版本,前者在视觉感知上全面对标并超过 Gemini 2.5 Pro,后者则在多模态推理基准上创下新纪录,成为开源阵营的最强视觉理解大模型。

就在昨天,2025年10月7日,Google DeepMind 正式发布其最新模型——Gemini 2.5 Computer Use。该模型基于 Gemini 2.5 Pro 的视觉理解与推理能力,新增了“界面交互(UI 控制)”能力,能够在浏览器或移动端界面上像人类那样点击、输入、滚动、选择控件等操作。

智谱AI刚刚开源了新一代视觉-语言模型(Vision-Language Model, VLM)——GLM-4.5V。该模型基于其旗舰文本基础模型GLM-4.5-Air(总参数量1060亿,激活参数量120亿),延续GLM-4.1V-Thinking的技术路线,在42项公开视觉多模态基准测试中,在同规模模型中实现领先性能。GLM-4.5V面向图像、视频、文档理解以及GUI任务等常见多模态场景,采用Mixture-of-Experts(MoE)架构,并保持开源。

MiniMax正式开源MiniMax M2模型,该模型定位是“Mini 模型,Max 编码与代理工作流”。最大的特点是2300亿总参数量,但是每次推理仅激活100亿,类似于10B模型。这款模型非常火爆,原因在于这么小的激活参数数量,推理速度很快,但是其评测结果非常优秀。

尽管人工智能语言模型的能力日益强大,但它们依然面临一个棘手的问题:“幻觉”(Hallucination)。所谓幻觉,指的是模型自信地生成一个事实上错误的答案。OpenAI 的最新研究论文指出,这一现象的根源在于标准的训练和评估方式实际上在鼓励模型“猜测”而非“承认不确定性”。