
DeepSeekAI开源全新的DeepSeek-OCR模型:参数规模仅30亿的MoE大模型,图像文本结构化提取成本下降十倍!准确率超过Qwen2.5-VL-7B
DeepSeek AI团队重磅推出DeepSeek-OCR,该模型不仅在文档提取上达到了行业领先水平,更通过创新的视觉压缩技术,将长上下文处理效率提升了 10 倍以上。根据测算,在A100-40G的一个GPU上,它每天可以将20万页的文档图像数据转为Markdown文本!
探索人工智能与大模型最新资讯与技术博客,涵盖机器学习、深度学习、自然语言处理等领域的原创技术文章与实践案例。
DeepSeek AI团队重磅推出DeepSeek-OCR,该模型不仅在文档提取上达到了行业领先水平,更通过创新的视觉压缩技术,将长上下文处理效率提升了 10 倍以上。根据测算,在A100-40G的一个GPU上,它每天可以将20万页的文档图像数据转为Markdown文本!

盘古大模型是华为自研的大语言模型,基于华为的硬件和技术栈进行训练。此前一直被认为是国产技术占比很高的国产大模型。今天,华为开源了2个盘古大模型,分别是MoE架构的Pangu Pro MoE模型以及70亿参数规模的Pangu Embedded模型。

xAI 正式发布 Grok 4 Fast —— 一款以 极致性价比与前沿性能 为核心卖点的新一代推理模型。相比前代产品,它不仅在推理准确率上几乎与旗舰模型Grok 4等持平,还凭借 40%更高的推理效率 和 高达98%的成本降低,将高质量智能推理真正带入大众用户和企业应用场景。
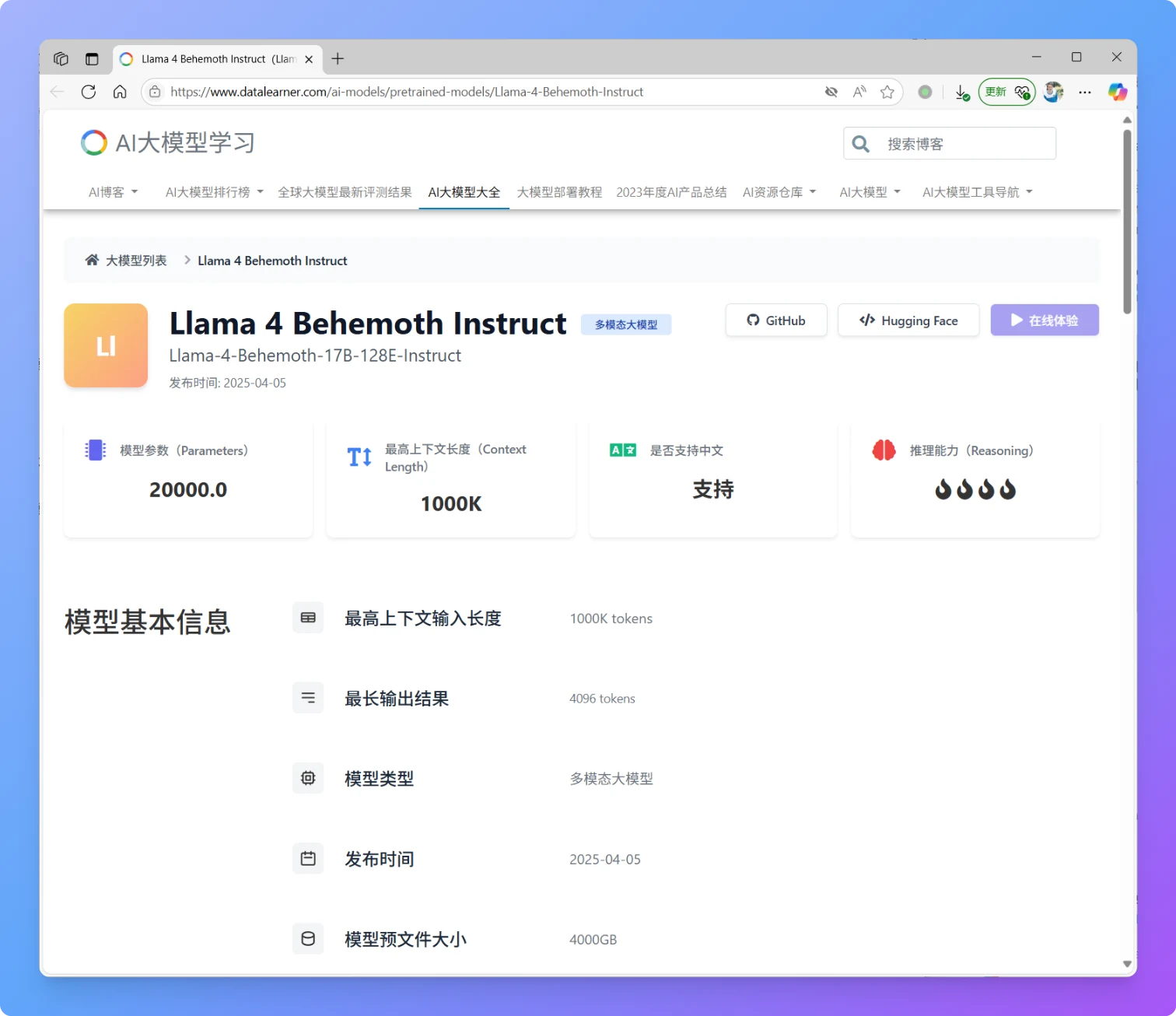
就在刚刚,MetaAI发布了全新一代Llama4大模型,Llama正式进入多模态和MoE架构时代。本次新发布的是Llama4中的2个模型分别是Llama4 Scout和Llama4 Maverick。这两个模型都是170亿激活参数,但是前者共16个专家,后者有128个专家,因此总的参数量分别达到了1090亿和4000亿!不过根据评测的情况看,即使是4000亿规模170亿激活的模型,也和DeepSeek V3.1(即DeepSeek V3 0324)版本差不多。

就在今日,OpenAI正式推出了 Sora 2 ——其旗舰级视频与音频生成模型。相比2024年2月发布的初代 Sora,本次升级带来了断层级的真实感与显著增强的可控性。它不仅能更好地遵循物理规律生成视频,还首次实现了同步对话与环境音效的生成,并通过全新 iOS 应用“Sora”开放给公众使用。
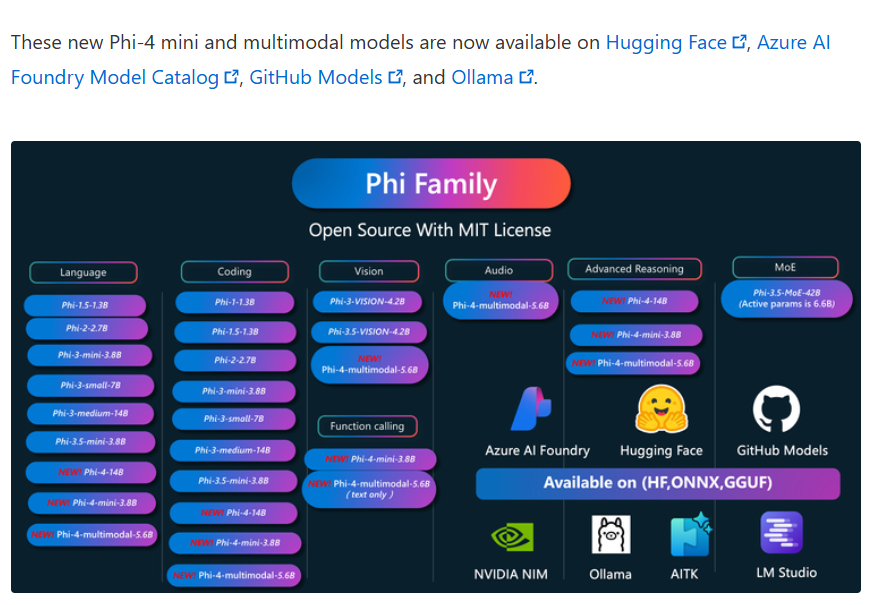
2025年2月27日,微软正式发布了其全新系列的大型语言模型——Phi-4系列。这一系列包含了三个创新性的模型:Phi-4-Mini、Phi-4-Multimodal和一款经过推理优化的Phi-4-Mini。此次发布的模型不仅在性能上展现出色,更在多模态能力与推理任务中实现了显著突破。其中,Phi-4-Multimodal是一个仅仅包含56亿参数规模的多模态大模型,但是支持文本、语音、图片的输入,十分强大。

Anthropic正式发布最新一代入门级模型Claude Haiku 4.5。相较上一代小模型,Haiku 4.5 在编码、推理与“计算机使用/子代理编排”等关键生产力场景上实现逼近甚至局部追平 Sonnet 4,但价格更低、速度更快,定位于“面向规模化落地的高性价比主力”。

万众瞩目的GPT-4即将来临!3月9日晚上在德国举办的一个AI会议。微软德国的员工参与了讨论,在介绍微软云的AI能力的时候,微软德国CTO Andreas Braun透露了GPT-4将在下周发布。
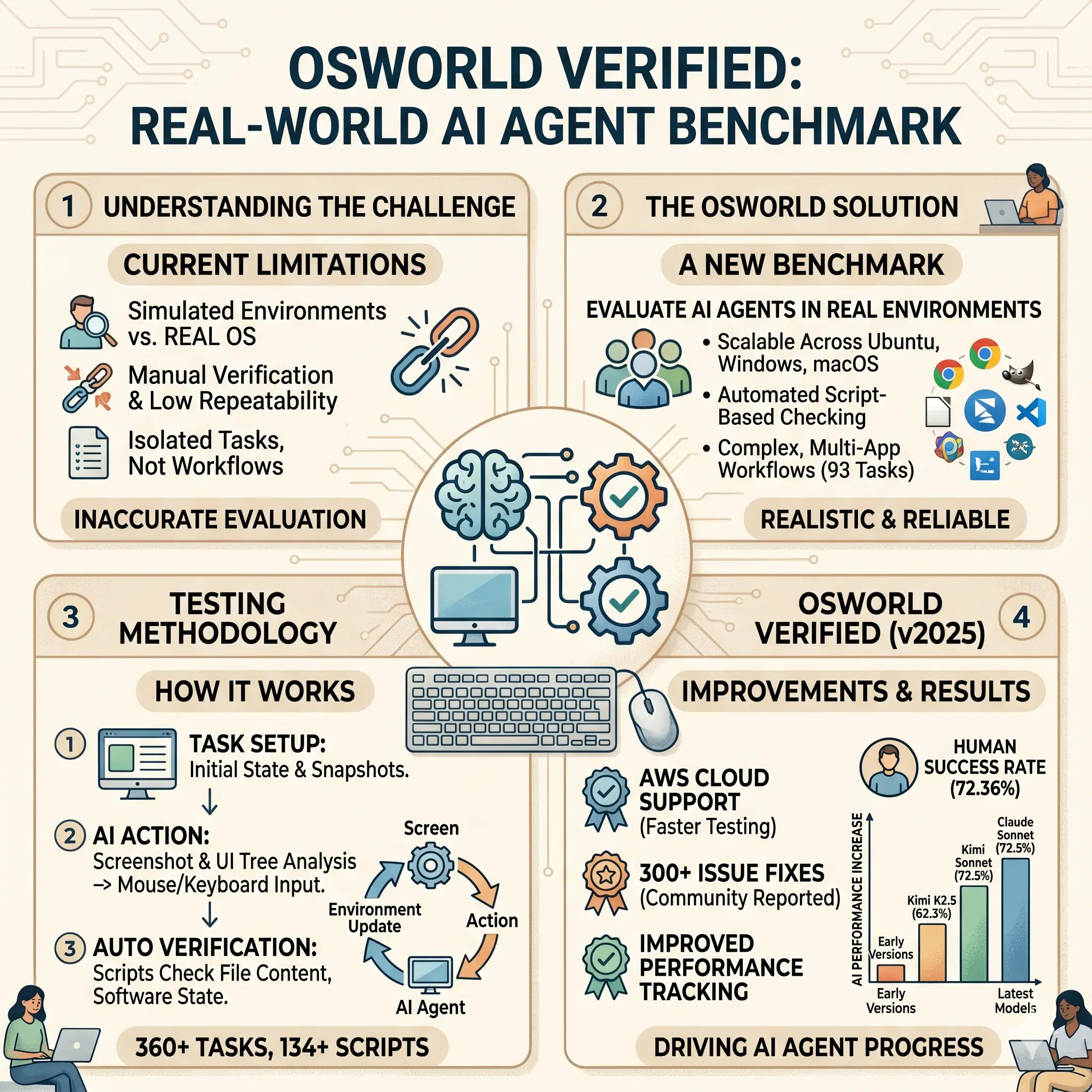
OSWorld 是一个用于测试 AI 代理在真实计算机环境中的基准。这些代理是能处理文字、图片等信息的 AI 系统。基准包括开放式任务,比如操作文件或使用软件。OSWorld Verified 是它的改进版,通过修复问题和提升运行方式,提供更准确的测试结果。它支持不同操作系统,如 Ubuntu、Windows 和 macOS,并允许 AI 通过互动学习来完成任务。
就在今日,Moonshot AI 正式推出 Kimi K2 Thinking,这款开源思考代理模型以其革命性的工具集成和长程推理能力,瞬间点燃了开发者社区的热情。Kimi K2能自主执行200-300次连续工具调用,跨越数百步推理,解决PhD级数学难题或实时网络谜题。本次发布的Kimi K2不仅仅是模型升级,更是AI Agent能力的扩展。

这篇文章基于 Dwarkesh Patel 对 SSI 创始人、前 OpenAI 首席科学家 Ilya Sutskever 的长访谈,系统梳理了他对模型泛化、人类智能结构、持续学习、RL 与预训练局限、超级智能路径、对齐策略,以及 AI 未来经济与治理的整体判断。文章不仅整理了核心观点,也结合具体原文展开解读,呈现 Ilya 如何从“人类为何能泛化”这一根问题出发,重新思考下一代智能系统应当如何构建。

MistralAI开源的混合专家模型Mistral-7B×8-MoE在本周吸引了大量的关注。这个模型不仅是稍有的基于混合专家技术开源的大模型,而且有较高的性能、较低的推理成本、支持法语、德语等特性。昨天MistralAI发布的不仅仅是这个混合专家模型,还有他们的平台服务La plateforme。在这里他们透露了MistralAI还有更加强大的模型。

就在刚刚,马斯克在推特上宣布本周会开源Grok大语言模型。xAI是马斯克在2023年3月份创办的一家大模型初创企业。因为ChatGPT过于火爆,离开OpenAI之后马斯克又再次开始推出大模型,就是这个Grok。
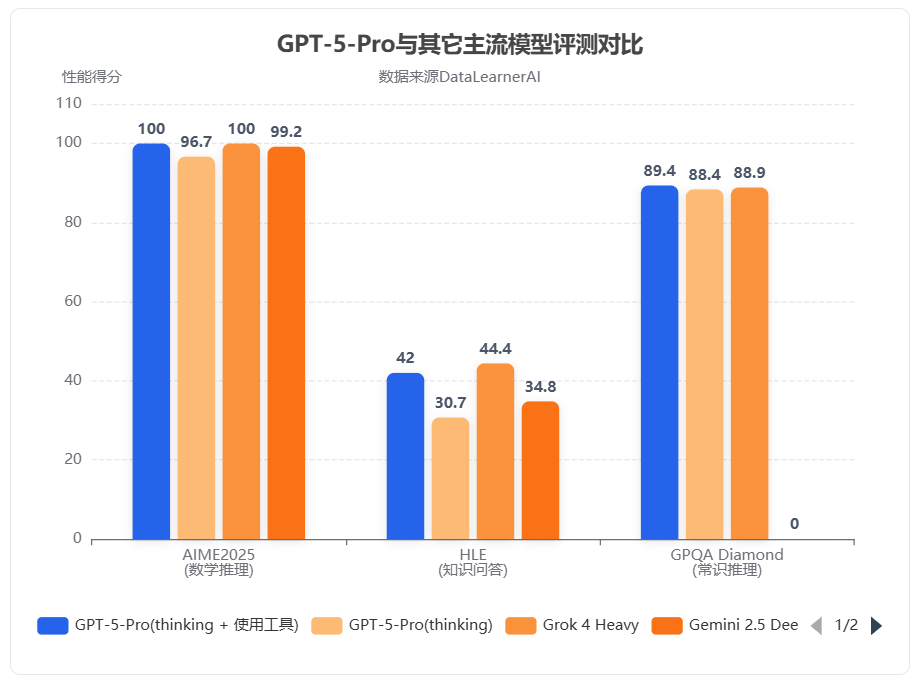
几个小时前,OpenAI发布了全新一代大模型GPT-5系列。本次发布的是一个全新的AI系统,而非一个单独的模型系列。GPT-5背后包含了5个不同的模型系列或者版本,分别是GPT-5-Pro、GPT-5、GPT-5-mini、GPT-5-nano和GPT-5-Chat。

OpenAI 于 2025 年 2 月 27 日发布了 GPT-4.5,作为其语言模型系列的最新版本。尽管具体的技术细节因商业保密而未完全公开,基于现有信息和合理推测,DataLearner提供更具体的数据和分析,同时补充更多来自用户的评价。

昨天,Anthropic公布了一项引人注目的实验——Project Vend。他们让旗下的大模型Claude Sonnet 3.7在一个真实的办公环境中,自主经营一家小型自动化商店,为期约一个月。这个实验的目标是探索,在不久的将来,AI模型在真实经济体中自主运行任务的可行性、潜在的成功模式以及那些出人意料的失败方式。实验结果非常强大,也充满了令人深思的细节!

在人工智能领域,Mistral与NVIDIA的合作带来了一个引人注目的新型大模型——Mistral NeMo。这个拥有120亿参数的模型不仅性能卓越,还为AI的普及和应用创新铺平了道路。MistralAI官方博客介绍说该模型是此前开源的Mistral 7B模型的继承者,因此未来可能7B不会再继续演进了!

就在刚才,Anthropic 正式推出了 Claude Sonnet 4.5——全球最强的编码模型。这款新模型不仅在软件开发能力上实现了断层领先,更在构建复杂 AI 代理、计算机操控以及数学推理等多个维度展现出革命性突破。

尽管各家大模型技术进展神速,但是在复杂任务的推理上,大模型目前依然较弱。在去年底,各方消息透露,OpenAI内部有一个称为Q\*的项目取得了重大的突破,可以大幅提高大模型的推理能力。但是,几个月过去了,这个当时吸引了大量讨论的项目没有任何信息。直到昨天,Reuters披露了Q\*项目的进展,这个项目已经变为Strawberry!并且距离发布时间更近了!

就在刚才,Google宣布发布最新的图像生成和编辑大模型Gemini 2.5 Flash Image Preview。该模型就是最近火爆网络的Nana Banana背后真正的模型。该模型在图片生成和编辑方面目前是断层领先,效果非常好。

几个小时前,DeepSeek 突然发布了两款全新的推理模型:DeepSeek V3.2 正式版与DeepSeek V3.2-Speciale。前者已经全面替换官方网页、App 与 API 成为新的默认模型;后者则以“临时研究 API”的方式开放,被定位为极限推理版本。

AIME 2026 是基于美国数学邀请赛(American Invitational Mathematics Examination)2026 年问题的评测基准,用于评估大语言模型在高中水平数学推理方面的表现。该基准包含 15 个问题,覆盖代数、几何、数论和组合数学等领域。模型通过生成答案并与标准答案比较来计算准确率。

智谱AI于2025年7月发布了Zread。这款产品能够利用其大模型能力,结合类似Deep Research的Agent技术,对GitHub项目进行深度解读和问答。其价值在于将强大的模型能力通过优秀的工程化设计,变成了一个真正“好用”的工具。它解决的正是那种“代码就在那里,但我就是看不懂”的尴尬,这种体验是单纯聊天机器人无法替代的。