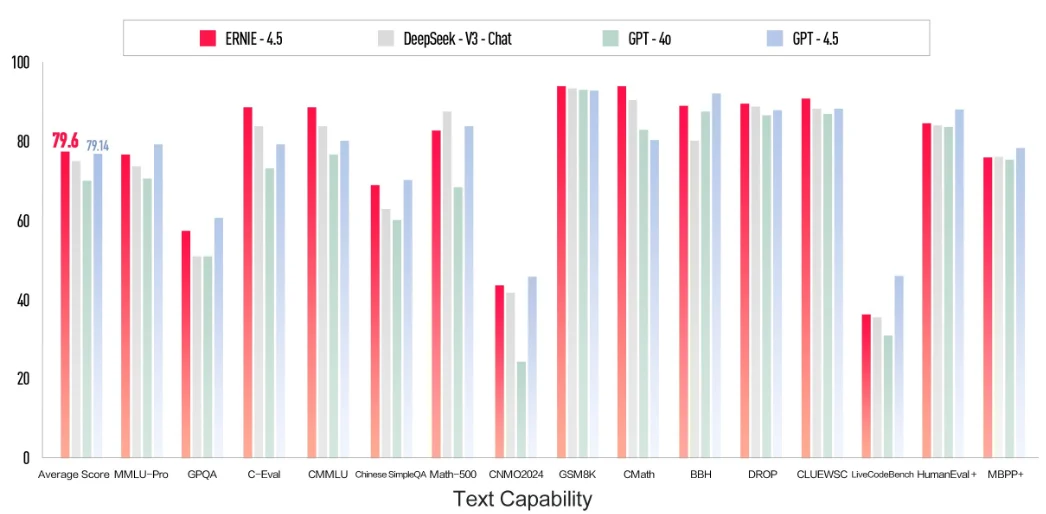
微软开源140亿参数规模的Phi-4推理版本大模型:多项评测结果超过OpenAI o1-mini,单张4090可运行,完全免费开源
微软发布了全新的Phi-4推理模型系列,是小型语言模型(SLM)在复杂推理能力上的一种新的尝试。本次发布包含三个不同规模和性能的推理模型,分别是Phi-4-reasoning(140亿参数)、Phi-4-reasoning-plus(增强版140亿参数)和Phi-4-Mini-Reasoning(38亿参数)。这三款模型尽管参数规模远小于当前主流大型语言模型,却在多项推理基准测试中展现出与甚至超越大型模型的能力。