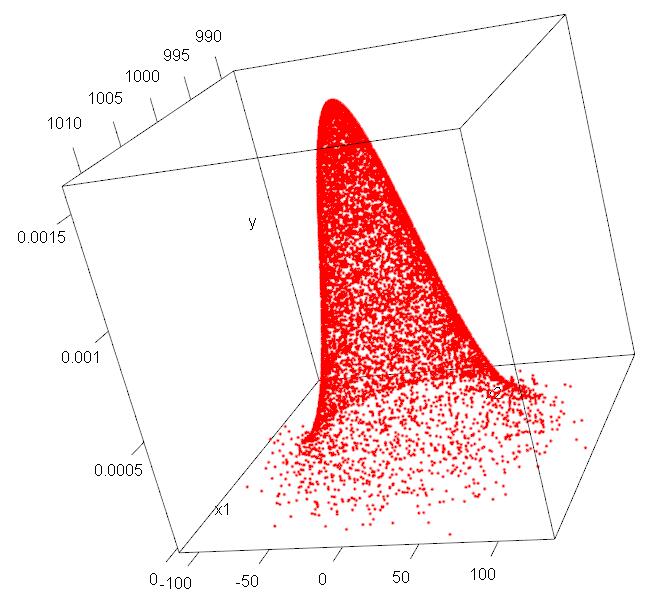
考虑价格和促销影响的销售预测算法实践
这是一篇来自Towards Data Science上面的一篇个人实践分享,主要是针对销量进行预测。一般来说,销量受到价格、季节等因素影响较大。这里就是考虑这些因素进行的一个实践。值得大家一试。这里我们翻译一下,并对其中的某些工作做一些简单的解释。
探索人工智能与大模型最新资讯与技术博客,涵盖机器学习、深度学习、自然语言处理等领域的原创技术文章与实践案例。
这是一篇来自Towards Data Science上面的一篇个人实践分享,主要是针对销量进行预测。一般来说,销量受到价格、季节等因素影响较大。这里就是考虑这些因素进行的一个实践。值得大家一试。这里我们翻译一下,并对其中的某些工作做一些简单的解释。

前几天,北京智源人工智能研究院引入了一个名为WuDaoMM的大规模多模态语料库,总共包含超过6.5亿对图像-文本。具体来说,约有6亿对数据是从图像和标题呈现弱相关的多个网页中收集的,另外5000万对强相关的图像-文本是从一些高质量的图片网站中收集的。
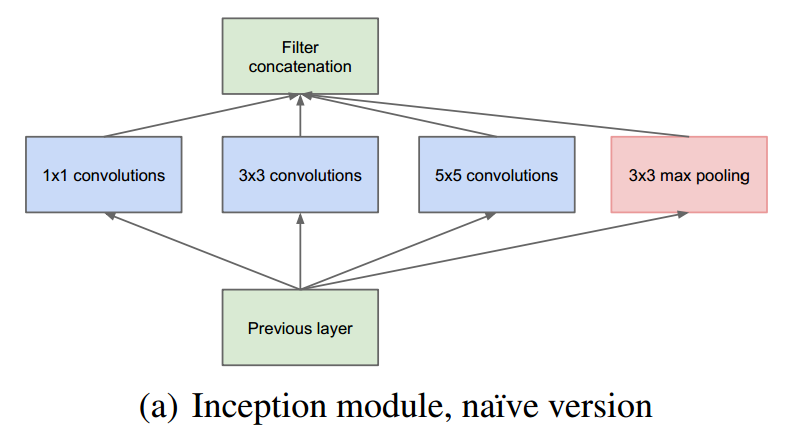
GoogLeNet是谷歌在2014年提出的一种CNN深度学习方法,它赢得了2014年ILSVRC的冠军,其错误率要低于当时的VGGNet。与之前的深度学习网络思路不同,之前的CNN网络的主要目标还是加深网络的深度,而GoogLeNet则提出了一种新的结构,称之为inception。GoogLeNet利用inception结构组成了一个22层的巨大的网络,但是其参数却比之前的如AlexNet网络低很多。是一种非常优秀的CNN结构。

随着近年来GPT-3、ChatGPT等大模型的兴起,高质量的数据集在模型训练中扮演着越来越重要的角色。但是当前领先的预训练模型使用的数据集细节往往不公开,开源数据的匮乏制约着研究社区的进一步发展。特别是大规模中文数据集十分缺乏,对中文大模型以及业界模型的中文支持都有很大的影响。此次,上海人工智能实验室发布的这个数据集包含了丰富的中文,对于大模型的中文能力提升十分有价值。
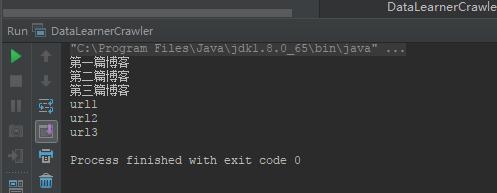
使用爬虫获取数据对科研来说及其重要,本系列博客将讲述如何使用Java编写爬虫工具获取网页数据。在这篇博客里,我们将简单介绍Jsoup解析HTML页面的操作。

去年5月份的时候,Python创始人Guido van Rossum在参加Language Summit时候说他希望Python3.11能在性能上获得巨大的提升,可以实现性能翻倍。目前看,似乎已经有了很大的希望!
Dirichlet Process and Stick-Breaking(DP的Stick-breaking 构造)

机器学习是这几年很热门的学习和工作的方向。但是机器学习相关算法的入门却并不容易。本文参考自MLTUT的博文,列举了2021年适合初学者的十个最佳机器学习网络课程供大家学习参考。
本文介绍了文本领域的相关任务和技术,探讨了循环神经网络在文本领域的优势,并进一步研究了应用在文本领域的卷积网络方法,原文地址:https://medium.com/@TalPerry/convolutional-methods-for-text-d5260fd5675f
今天,THUDM开源了ChatGLM-6B的多模态升级版模型VisualGLM-6B。这是一个多模态对话语言模型,支持图像、中文和英文。VisualGLM-6B的特别之处在于它能够整合视觉和语言信息。可以用来理解图片,解析图片内容。
机器学习的特征工程是将原始的输入数据转换成特征,以便于更好的表示潜在的问题,并有助于提高预测模型准确性的过程。找出合适的特征是很困难且耗时的工作,它需要专家知识,而应用机器学习基本也可以理解成特征工程。

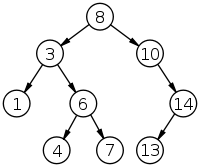
二叉查找树是一种特殊的二叉树结构,它改善了二叉树的查找效率,二叉查找树相比于其他数据结构的优势在于查找、插入的时间复杂度较低。与一般的二叉树的主要区别就是它对子节点的键值排序有一定要求。
字节对编码(Byte Pair Encoder,BPE),又叫digram coding,是一种在自然语言处理领域经常使用的数据压缩算法。在GPT系列模型中都有用到。主要是将数据中最常连续出现的字节(bytes)替换成数据中没有出现的字节的方法。该算法首先由Philip Gage在1994年提出。在这篇博客中我们将简单介绍一下这个方法。

M3系列芯片是苹果最新发布的芯片。也是当前苹果性能最好的芯片。由于苹果的统一内存架构以及它的超大内存,此前很多人发现可以使用苹果的电脑来运行大语言模型。尽管它的运行速度不如英伟达最先进的显卡,但是由于超大的内存(显存),它可以载入非常大规模的模型。而此次的M3芯片效果如何,本文做一个简单的分析。

就在刚才,Moonshot AI(Kimi 团队)推出了 Kimi Claw(目前为 Beta 版)。这项服务让普通用户无需本地安装或维护服务器,就能快速获得一个类似 OpenClaw 的云端 AI 助手,随时在线、具备长期记忆和实际执行能力。
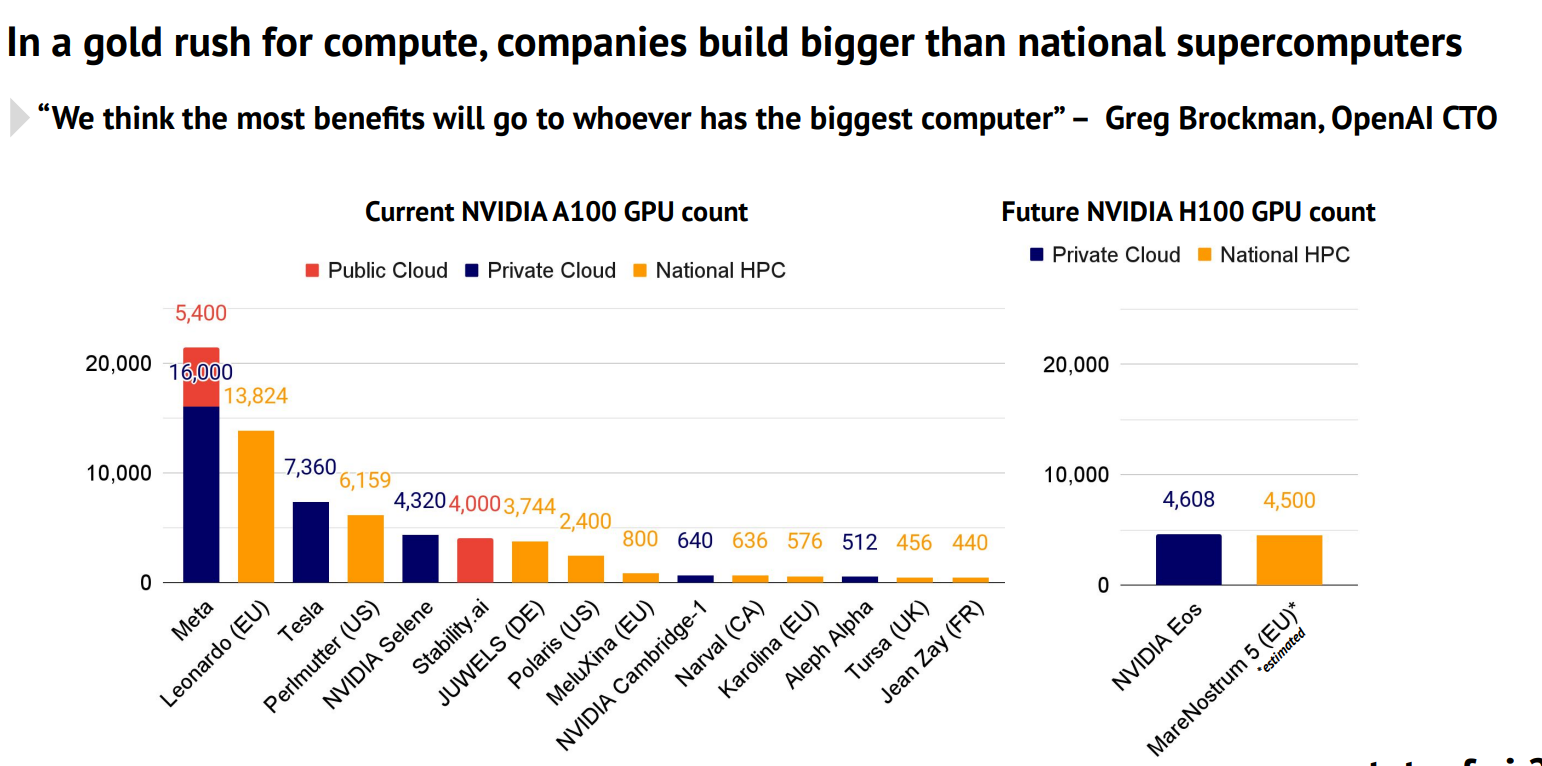
Stateof.AI上周发布了最新的AI的报告中报告了当前各大企业和机构拥有的NVIDIA A100的GPU数量。A100是目前商用的最强大的GPU,对于超级计算机、大规模AI模型的训练和推理来说都十分重要。这里透露的各大企业的GPU数量也让我们可以看到各家的竞争情况。

OpenAI在发布了多模态的GPT-4V(GPT-4 with Vision)的接口,可以实现图像理解的功能(`Image-to-Text`)。这是OpenAI的第一个多模态接口,在以前的接口中,OpenAI都是文本大模型,相关的费用计算都是按照输入输出的tokens计算,虽然与一个单词多少钱有一点差异,但是也算直观。而GPT-4V是一个图像理解的接口,这里的费用计算不像文本的tokens那么直观,那么这个接口的费用计算逻辑是什么?这个计算逻辑透露了什么样的模型架构信息?本文将介绍这个问题。
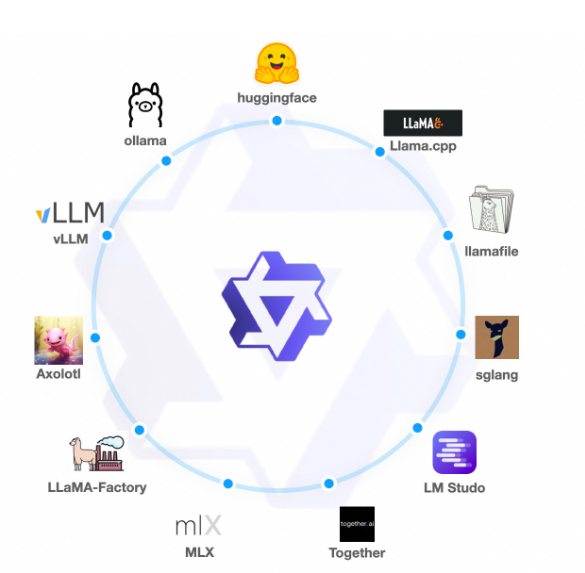
今天阿里巴巴开源了他们家第二代的Qwen系列大语言模型(准确说是1.5代),从官方给出的测评结果看,Qwen1.5系列大模型相比较第一代有非常明显的进步,其中720亿参数规模版本的Qwen1.5-72B-Chat在各项评测结果中都非常接近GPT-4的模型,在MT-Bench的得分中甚至超过了此前最为神秘但最接近GPT-4水平的Mistral-Medium模型。
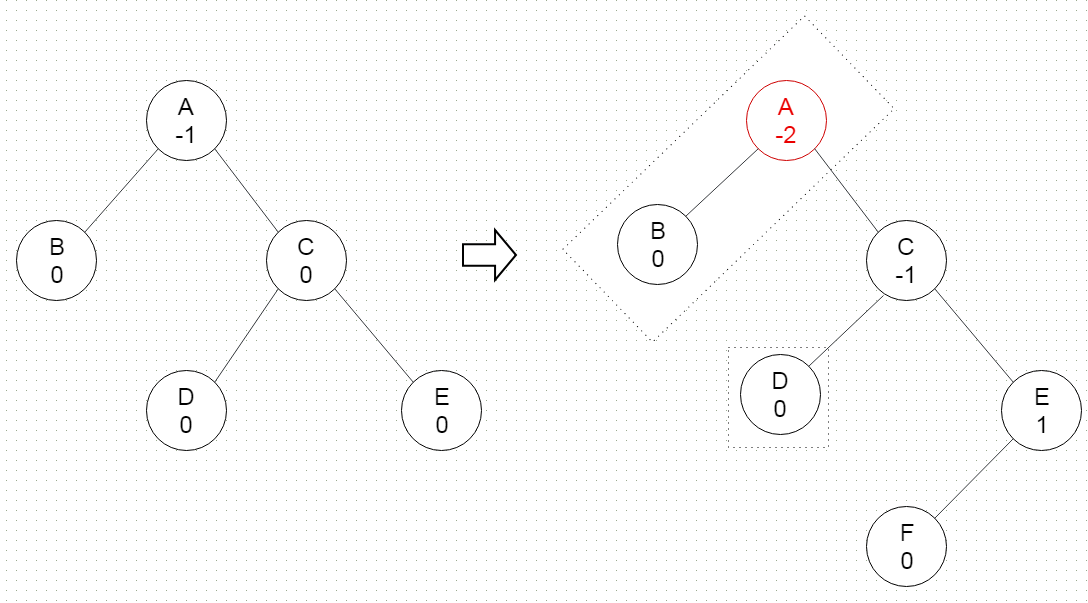
在前面的内容中,我们已经介绍了平衡二叉树。其中提到了AVL树,这是一种非常著名的平衡二叉树。这是第一个发明类似自平衡机制的二叉树数据结构。在AVL树中,任何节点的两个子树的高度最多相差一个。如果在任何时候它们相差多于一个,则重新平衡以恢复此属性。
在进行编程操作的时候,我们常常会遇到很多与编程无关的项目管理工作,如下载依赖、编译源码、单元测试、项目部署等操作。一般的,小型项目我们可以手动实现这些操作,然而大型项目这些工作则相对复杂。构建工具是帮助我们实现一系列项目管理、测试和部署操作的工具。本文将对Java构建工具做简单介绍。