原创AI技术博客
探索人工智能与大模型最新资讯与技术博客,涵盖机器学习、深度学习、自然语言处理等领域的原创技术文章与实践案例。
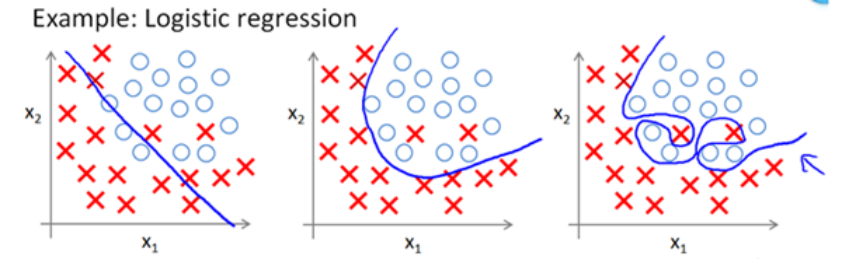
推荐模型:显式反馈模型VS隐式反馈模型
推荐中,有研究explict feedback,有研究implict feedback,今天就来谈谈这两种基本模型是怎么建的?其实,都是套路~

OpenAI官方教程:如何针对大模型微调以及微调后模型出现的常见问题分析和解决思路~以GPT-3.5微调为例
OpenAI在2023年8月份发布了GPT-3.5的微调接口,并表示会在2023年秋天开放16K的gpt-3.5-turbo-16k模型和GPT-4的微调(参考:[重磅!GPT-3.5可以微调了!OpenAI发布GPT-3.5 Turbo微调接口](https://www.datalearner.com/blog/1051692752268726 "重磅!GPT-3.5可以微调了!OpenAI发布GPT-3.5 Turbo微调接口"))。然而,微调并不是一个简单的问题,如何对大模型微调以及如果微调出现问题

开源版本的GPT-3来临!Meta发布OPT大语言模型!
关注深度学习或者NLP的童鞋应该都知道openAI的GPT-3模型,这是一个非常厉害的模型,在很多任务上都取得了极其出色的成绩。然而,OpenAI的有限开放政策让这个模型的应用被限定在很窄的范围内。甚至由于大陆不在OpenAI的API开放国家,大家几乎都无法使用和体验。而五一假期期间,FaceBook的研究人员Susan Zhang等人发布了一个开源的大预言模型,其参数规模1750亿,与GPT-3几乎一样。
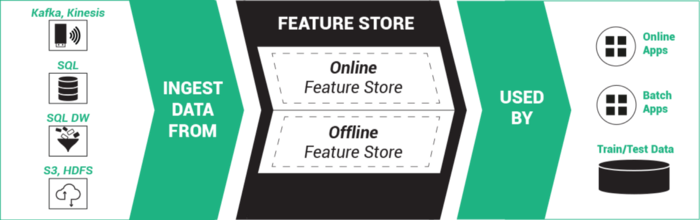
亚马逊最新发布Feature Store简介
在2020年的亚马逊reInvent发布会上,亚马逊正式发布了一项新的服务,即Amazon SageMaker Feature Store,中文简介是适用于机器学习特征的完全托管的存储库。 Feature Store是这两年兴起的另一个关于人工智能系统的基础设施,应该也是未来几年最重要的人工智能基础设施之一。本文将介绍一下Feature Store是什么以及为什么很多企业开始推广这个东西。
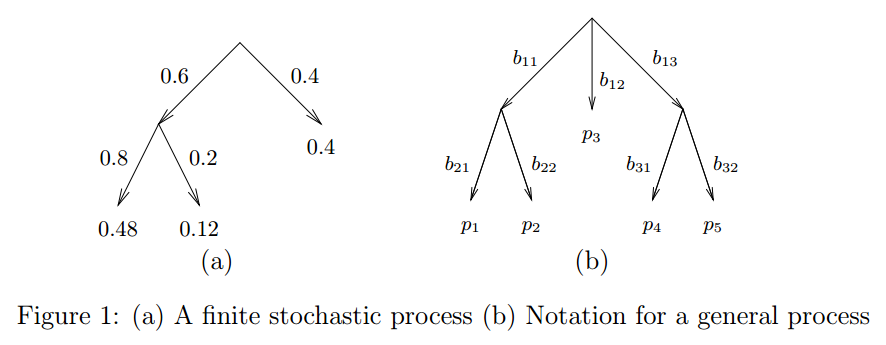
Dirichlet Tree Distribution(狄利克雷树分布)
狄利克雷分布作为多项式分布的先验大家应该比较熟悉了。这里介绍另外一种Dirichlet树结构的分布,也可以作为多项式分布的先验,但却更加灵活


OpenAI最新的推理大模型o1与GPT-4o有什么区别?o1一定比o1 mini更强吗?一文总结OpenAI对o1模型的官方答疑
OpenAI的o1模型是当前最强大的具有超强推理能力的大语言模型。但是,o1模型本身的能力如何,o1版本和o1-mini版本模型的差异在哪等似乎都很不清晰。为此,OpenAI在Twitter上举办了一次AMA(Ask me anything)活动,解答了很多大家关心的问题。在这篇博客中,我们根据这个讨论结果总结了一下其中比较重要的信息供大家参考。

大模型驱动的自动代理(AI Agent):将语言模型的能力变成通用能力的一种方式——来自OpenAI安全团队负责人的解释与观点
当前大模型本质是一种大语言模型(Large Language Models, LLM),其核心能力是对语言的处理。良好的意图识别和文本生成能力让LLM超越了之前的模型,有了巨大的实用价值。但是,现实问题涉及了很多超越语言模型之外的能力,如基于最新数据的文本摘要、向用户提供实时数据分析和可视化结果、为代码提供debugging等。目前,让LLM解决这些问题的一个最有前景的方向就是建立大模型驱动的自动代理。也就是让LLM作为核心控制者来学会使用不同工具,进而完成最终任务。
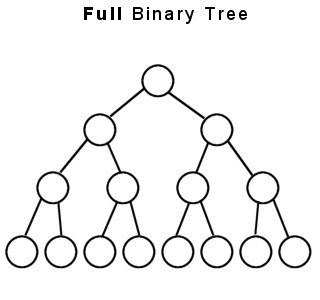
二叉树(Binary Tree)
二叉树数据结构中一类重要的数据结构,也是树表家族最为基础的结构。二叉树每个节点最多具有两个子节点。本篇博客将简述二叉树原理和应用。
平衡二叉树(Balanced Binary Tree)
平衡二叉树(Balanced Binary Tree)是二叉树(Binary Tree)中最重要的一种树结构。由于它保证了一个良好的二叉树形结构,使得其查找、搜索和删除等操作的效率大大提高,是应用最广泛的二叉树。
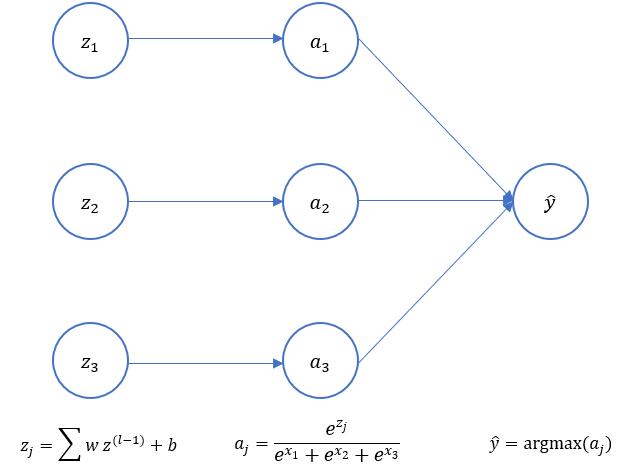
softmax作为输出层激活函数的反向传播推导
softmax作为多标签分类中最常用的激活函数,常常作为最后一层存在,并经常和交叉熵损失函数一起搭配使用。这里描述如何推导交叉熵损失函数的推导问题。


国产代码补全预训练模型——清华大学CodeGeeX发布!
随着NLP预训练模型的发展,大语言模型在各个领域的作用也越来越大。几个月前,GitHub基于OpenAI的GPT-3训练的Copilot效果十分惊艳,可惜现在已经开始收费。而最近,清华大学也发布了一个代码补全神器——CodeGeeX。
Dask的本地集群配置和编程
Dask提供了多种分布式调度器,当缺少多台服务器时候,也可以通过本地集群来实现单机分布式的计算。这篇博客主要就是介绍如何实现Dask的单机分布式调度器。第一小节是简介,第二节是单机调度器的简写版本,第三节是单机调度器的完整版本,第四节是使用的一些示例。
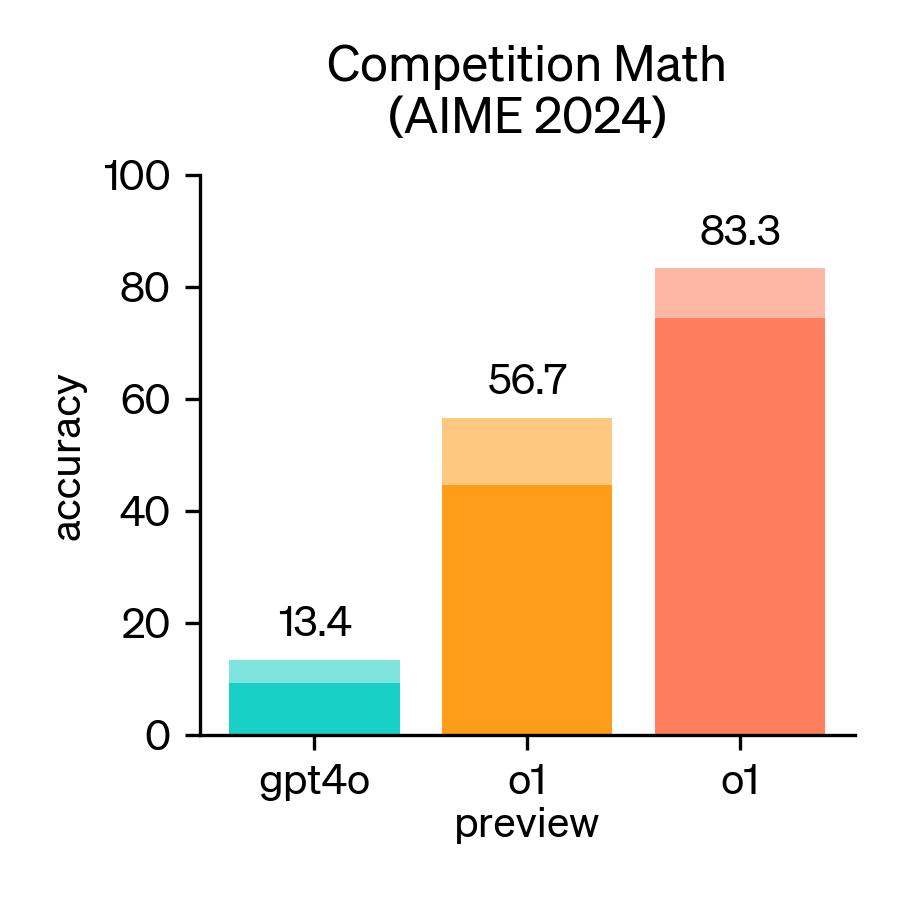
大模型评测基准AIME 2024介绍
2024年,美国数学邀请赛(AIME)成为评估大型语言模型(LLM)数学推理能力的重要基准。AIME是一项备受尊崇的考试,包含15道题,考试时间为3小时,旨在考察美国顶尖高中生在各类数学领域的复杂问题解决能力。

Android开发入门基础知识——Intent详解
Intent是Android中通信的组件。这篇博客将详细讲述什么是Intent及其用法。
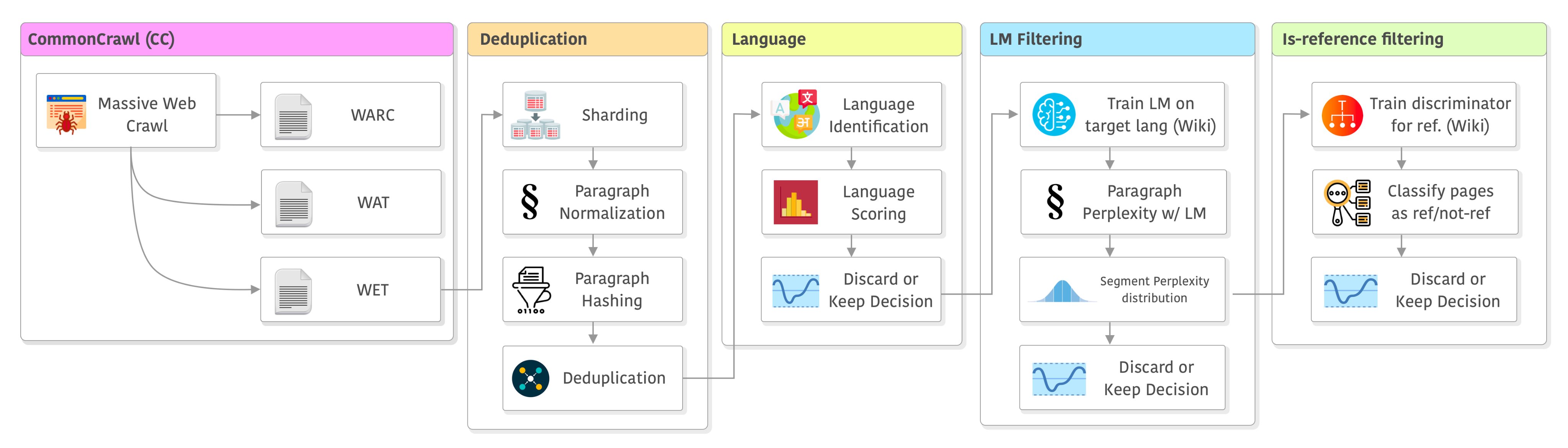
大语言模型训练之前,数据集的处理步骤包含哪些?以LLaMA模型的数据处理pipeline(CCNet)为例
大语言模型的训练是一个十分复杂的技术,不仅涉及到模型的开发与部署,还涉及到数据的获取。与常规的算法模型不同的是,大语言模型通常需要大量的数据处理步骤。本文是根据英国一位自动工程师总结的大语言模型训练之前的数据处理步骤和决策过程。
TFboys:使用Tensorflow搭建深层网络分类器
使用Tensorflow的高级API - tf.contrib.learn 搭建一个DNN分类器
ItemCF--Python
基于项目最近邻的协同过滤算法,面向的是隐偏好数据,数据格式为<userid,itemid>,测试算法的指标为precision和recall
用python生成随机数的几种方法
本篇博客主要讲解如何从给定参数的的正态分布/均匀分布中生成随机数以及如何以给定概率从数字列表抽取某数字或从区间列表的某一区间内生成随机数,按照内容将博客分为3部分,并附上代码。
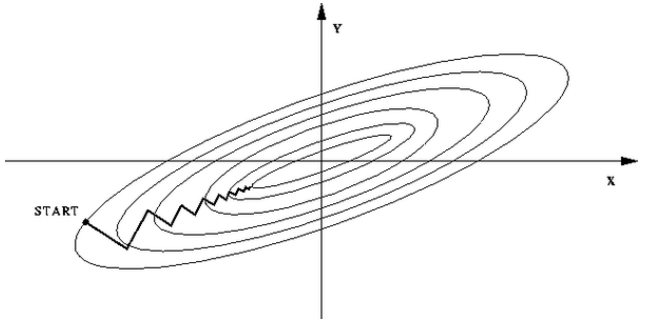
深度学习技巧之Batch Normalization
Batch Normalization是深度学习中最重要的技巧之一。是由Sergey Ioffe和Christian Szeged创建的。Batch Normalization使超参数的搜索更加快速便捷,也使得神经网络鲁棒性更好。本篇博客将简要介绍相关概念和原理。