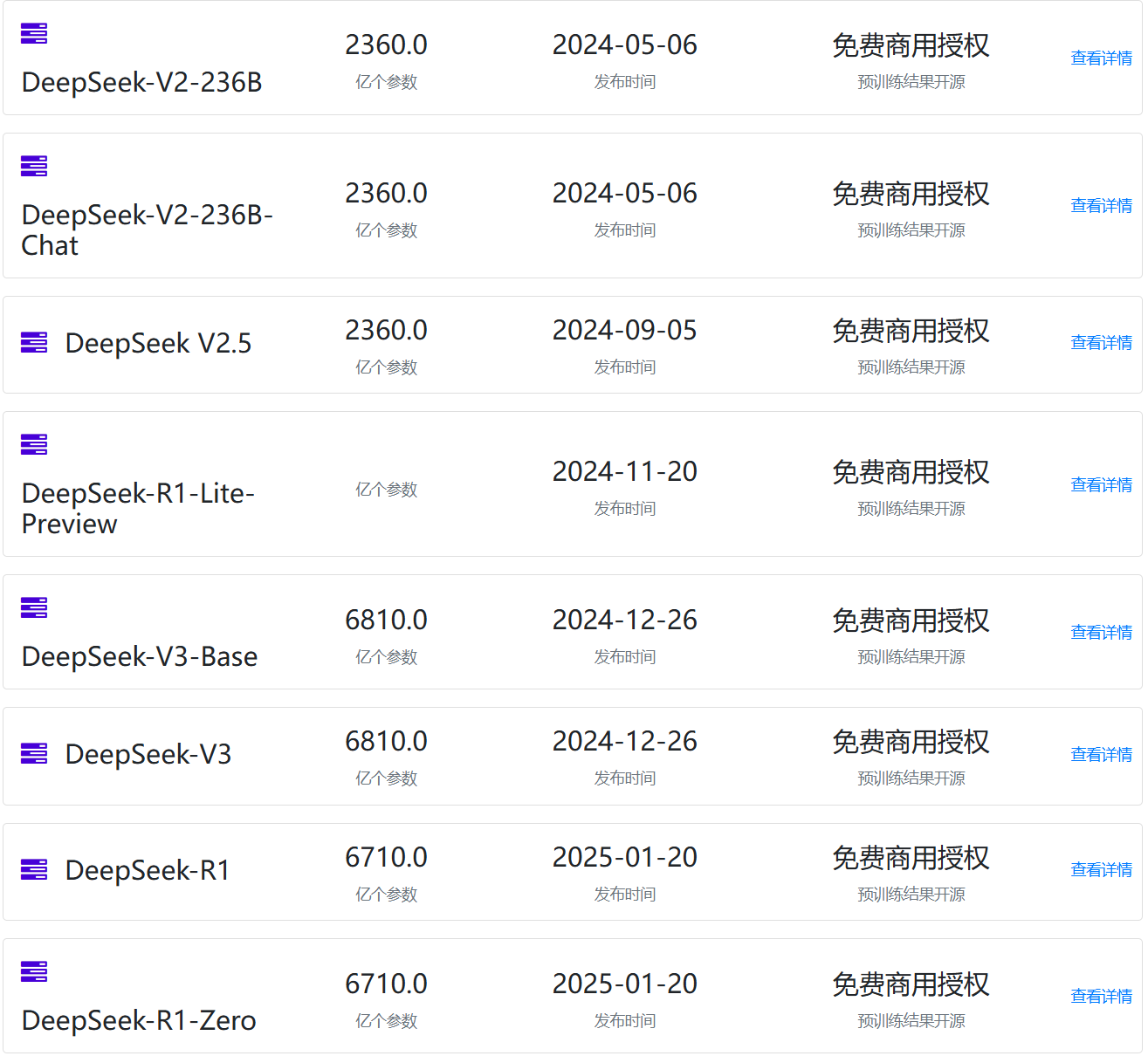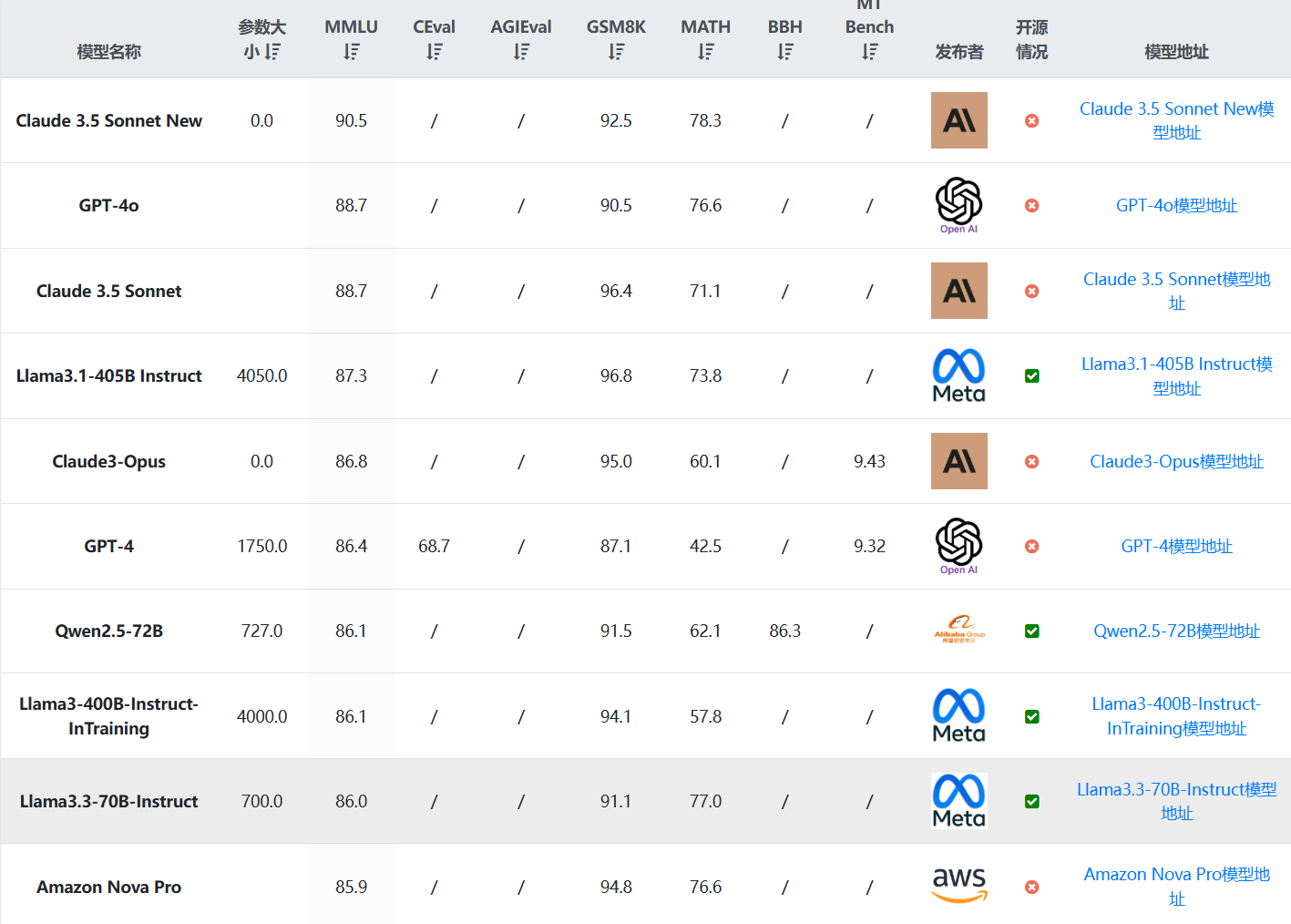
Google发布Gemini 2.0 Pro:MMLU Pro评测超过DeepSeek V3略低于DeepSeek R1,最高上下文长度支持200万tokens!开发者每天免费50次请求!
2025年2月5日,Google官方宣布Gemini 2.0 Pro版本上线,Gemini系列是谷歌最新一代大模型的品牌名称。Google最早在2024年12月中旬发布了Gemini 2.0系列的第一个模型Gemini 2.0 Flash,当时试用的人都普遍反应这个模型速度又快,结果友好,让Google摆脱了此前大模型很落后的印象。今天,Gemini 2.0 Pro上线,其能力更强。