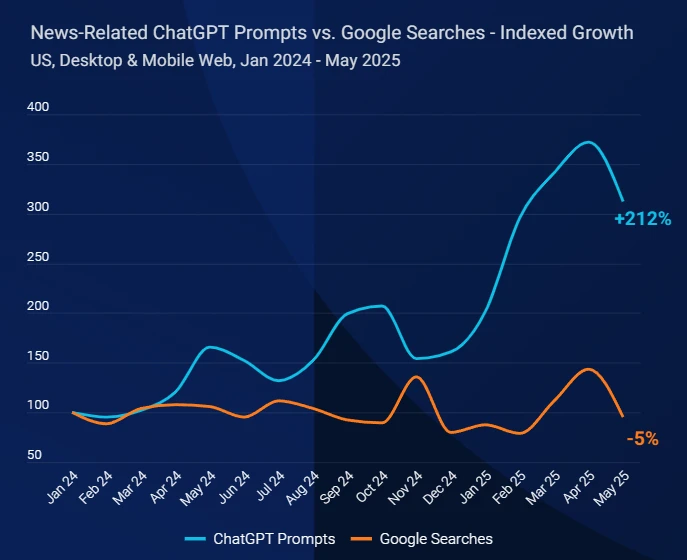
Kimi K2为什么开源?基于Kimi团队成员内容解释Kimi K2模型背后的决策思路与技术细节:继承于DeepSeek V3架构,只为追求模型智能的上限
上周,MoonshotAI 发布了 Kimi K2,并宣布 完全开源、允许商用。发布 24 小时内,社区即完成了 MLX 移植、4-bit 量化等后续工作。外网很多人评价说,Kimi K2是另一个DeepSeek R1时刻。本文尝试以第三方视角,把Kimi开发者公开的技术讨论、社区疑问与公开配置里的数字串成一条完整的技术决策链,解释Kimi K2背后的技术决策以及他们眼中大模型创业企业的方向。